



本篇文章给大家带来了关于python的相关知识,其中主要介绍了数据结构的相关问题,包括了数字、字符串、列表、元组、字典等等的相关内容,希望对大家有帮助。

推荐学习:python视频教程
数字 Number
整型(int) - 通常被称为是整型或整数,是正或负整数,不带小数点。Python3 整型是没有限制大小的,可以当作 Long 类型使用。布尔(bool)是整型的子类型。
浮点型(float) - 浮点型由整数部分与小数部分组成,浮点型也可以使用科学计数法表示(2.5e2 = 2.5 x 102 = 250)
复数( (complex)) - 复数由实数部分和虚数部分构成,可以用a + bj,或者complex(a,b)表示, 复数的实部a和虚部b都是浮点型。
数字类型转换
int(x) 将x转换为一个整数。
float(x) 将x转换到一个浮点数。
complex(x) 将x转换到一个复数,实数部分为 x,虚数部分为 0。
complex(x, y) 将 x 和 y 转换到一个复数,实数部分为 x,虚数部分为 y。x 和 y 是数字表达式。
数字运算
# + - * / %(取余) **(幂运算) # 整数除法中,除法 / 总是返回一个浮点数, # 如果只想得到整数的结果,丢弃可能的分数部分,可以使用运算符 // print(8 / 5) # 1.6 print(8 // 5) # 1 # 注意:// 得到的并不一定是整数类型的数,它与分母分子的数据类型有关系 print(8 // 5.0) # 1.0 # 使用 ** 操作来进行幂运算 print(5 ** 2) # 5的平方 25
字符串 str
字符串的查询
index():查找子串substr第一次出现的位置,如果查找的子串不存在时,则抛出ValueErrorrindex()异常
rindex():查找子串substr最后一次出现的位置,如果查找的子串不存在时,则抛出ValueError()异常
find():查找子串substr第一次出现的位置,如果查找的子串不存在时,则返回-1
rfind():查找子串substr最后一次出现的位置,如果查找的子串不存在时,则返回-1
s = 'hello, hello'
print(s.index('lo')) # 3
print(s.find('lo')) # 3
print(s.find('k')) # -1
print(s.rindex('lo')) # 10
print(s.rfind('lo')) # 10
字符串大小写转换
upper():把字符串中所有字符都转成大写字母
lower():把字符串中所有字符都转成小写字母
swapcase():把字符串中所有大写字母转成小写字母,把所有小写字母都转成大写字母
capitalize():把第一个字符转换为大写,把其余字符转换为小写
title():把每个单词的第一个字符转换为大写,把每个单词的剩余字符转换为小写
s = 'hello, Python' print(s.upper()) # HELLO, PYTHON print(s.lower()) # hello, python print(s.swapcase()) # HELLO, pYTHON print(s.capitalize()) # Hello, python print(s.title()) # Hello, Python
字符串对齐
center():居中对齐,第1个参数指定宽度,第2个参数指定填充符,默认是空格,如果设置宽度小于实际宽度则返回原字符串
ljust():左对齐,第1个参数指定宽度,第2个参数指定填充符,默认是空格,如果设置宽度小于实际宽度则返回原字符串
rjust():右对齐,第1个参数指定宽度,第2个参数指定填充符,默认是空格,如果设置宽度小于实际宽度则返回原字符串
zfill():右对齐,左边用0填充,该方法只接收一个参数,用于指定字符串的宽度,如果指定的宽度小于等于字符串的长度,返回字符串本身
s = 'hello,Python'
'''居中对齐'''
print(s.center(20, '*')) # ****hello,Python****
'''左对齐 '''
print(s.ljust(20, '*')) # hello,Python********
print(s.ljust(5, '*')) # hello,Python
'''右对齐'''
print(s.rjust(20, '*')) # ********hello,Python
'''右对齐,使用0进行填充'''
print(s.zfill(20)) # 00000000hello,Python
print('-1005'.zfill(8)) # -0001005
字符串拆分、切片
拆分
- split(): 从字符串的左边开始拆分
- rsplit():从字符串的右边开始拆分
- 默认的拆分字符是空格,返回值是一个列表
- 通过参数 sep 指定拆分字符串的拆分符
- 通过参数 maxsplit 指定拆分宇符串时的最大拆分次数,在经过最大次数拆分之后,剩余的子串会单独做为一部分
s = 'hello word Python'
print(s.split()) # ['hello', 'word', 'Python']
s1 = 'hello|word|Python'
print(s1.split(sep='|')) # ['hello', 'word', 'Python']
print(s1.split('|', 1)) # ['hello', 'word|Python'] # 左侧开始
print(s1.rsplit('|', 1)) # ['hello|word', 'Python'] # 右侧开始
切片
s = 'hello,world' print(s[:5]) # hello 从索引0开始,到4结束 print(s[6:]) # world 从索引6开始,到最后一个元素 print(s[1:5:1]) # ello 从索引1开始,到4结束,步长为1 print(s[::2]) # hlowrd 从开始到结束,步长为2 print(s[::-1]) # dlrow,olleh 步长为负数,从最后一个元素(索引-1)开始,到第一个元素结束 print(s[-6::1]) # ,world 从索引-6开始,到最后一个结束
字符串判断相关
- isidentifier():判断指定的字符串是不是合法的标识符
- isspace():判断指定的字符串是否全部由空白字符组成(回车、换行,水平制表符)
- isalpha():判断指定的字符串是否全部由字母组成
- isdecimal():判断指定字符串是否全部由十进制的数字组成
- isnumeric():判断指定的字符串是否全部由数字组成
- isalnum():判断指定字符串是否全部由字母和数字组成
字符串其他操作
字符串替换
- replace()
s = 'hello,Python,Python,Python'
print(s.replace('Python', 'Java')) # 默认全部替换 hello,Java,Java,Java
print(s.replace('Python', 'Java', 2)) # 设置替换个数 hello,Java,Java,Python
字符串连接
- join()
lst = ['hello', 'java', 'Python']
print(','.join(lst)) # hello,java,Python
print('|'.join(lst)) # hello|java|Python
格式化字符串输出
- %占位符:输出前加%,多个参数用小括号和逗号
- %s 字符串
- %i 或%d 整数
- -%f 浮点数
- {}占位符: 调用format()方法
- f-string:把变量写在{}中
name = '张三'
age = 20
print('我叫%s, 今年%d岁' % (name, age))
print('我叫{0}, 今年{1}岁,小名也叫{0}'.format(name, age))
print(f'我叫{name}, 今年{age}岁')
# 我叫张三, 今年20岁
# 我叫张三, 今年20岁,小名也叫张三
# 我叫张三, 今年20岁
设置数字的宽度和精度
# 设置数字的宽度和精度
'''%占位'''
print('%10d' % 99) # 10表示宽度
print('%.3f' % 3.1415926) # .3f表示小数点后3位
print('%10.3f' % 3.1415926) # 同时设置宽度和精度
'''{}占位 需要使用:开始'''
print('{:.3}'.format(3.1415926)) # .3表示3位有效数字
print('{:.3f}'.format(3.1415926)) # .3f表示小数点后3位
print('{:10.3f}'.format(3.1415926)) # .3f表示小数点后3位
# 99
#3.142
# 3.142
#3.14
#3.142
# 3.142
字符串编码
s = '但愿人长久' # 编码 将字符串转换成byte(二进制)数据 print(s.encode(encoding='gbk')) #gbk,中文占用2个字节 print(s.encode(encoding='utf-8')) #utf-8,中文占用3个字节 # 解码 将byte(二进制)转换成字符串数据 # 编码与解码中,encoding方式需要一致 byte = s.encode(encoding='gbk') print(byte.decode(encoding='gbk')) # b'\xb5\xab\xd4\xb8\xc8\xcb\xb3\xa4\xbe\xc3' # b'\xe4\xbd\x86\xe6\x84\xbf\xe4\xba\xba\xe9\x95\xbf\xe4\xb9\x85' # 但愿人长久
列表 list
列表的特点
有序序列
索引映射唯一个数据
可以存储重复数据
任意数据类型混存
根据需要动态分配和回收内存
列表的创建
- []:使用中括号
- list():使用内置函数list()
- 列表生成式
语法格式:[i*i for i in range(i, 10)]
-
解释:i表示自定义变量,i*i表示列表元素的表达式,range(i, 10)表示可迭代对象
print([i * i for i in range(1, 10)])# [1, 4, 9, 16, 25, 36, 49, 64, 81]
列表元素的查询
- 判断指定元素在列表中是否存在
in / not in
- 列表元素的遍历
for item in list: print(item)
- 查询元素索引
list.index(item)
- 获取元素
list = [1, 4, 9, 16, 25, 36, 49, 64, 81]print(list[3]) # 16print(list[3:6]) # [16, 25, 36]
列表元素的增加
append():在列表的末尾添加一个元素
extend():在列表的末尾至少添加一个元素
insert0:在列表的指定位置添加一个元素
切片:在列表的指定位置添加至少一个元素
列表元素的删除
rerove():一次删除一个元素,
重复元素只删除第一个,
元素不存在抛出ValceError异常pop():删除一个指定索引位置上的元素,
指定索引不存在抛出IndexError异常,
不指定索引,删除列表中最后一个元素切片:一次至少删除一个元素
clear0:清空列表
del:删除列表
列表元素的排序
- sort(),列表中的所有元素默认按照从小到大的顺序进行排序,可以指定reverse= True,进行降序排序,是对原列表的操作。
list.sort()
- sorted(),可以指定reverse—True,进行降序排序,原列表不发生改变,产生新的列表。
sorted(list)
知识点总结
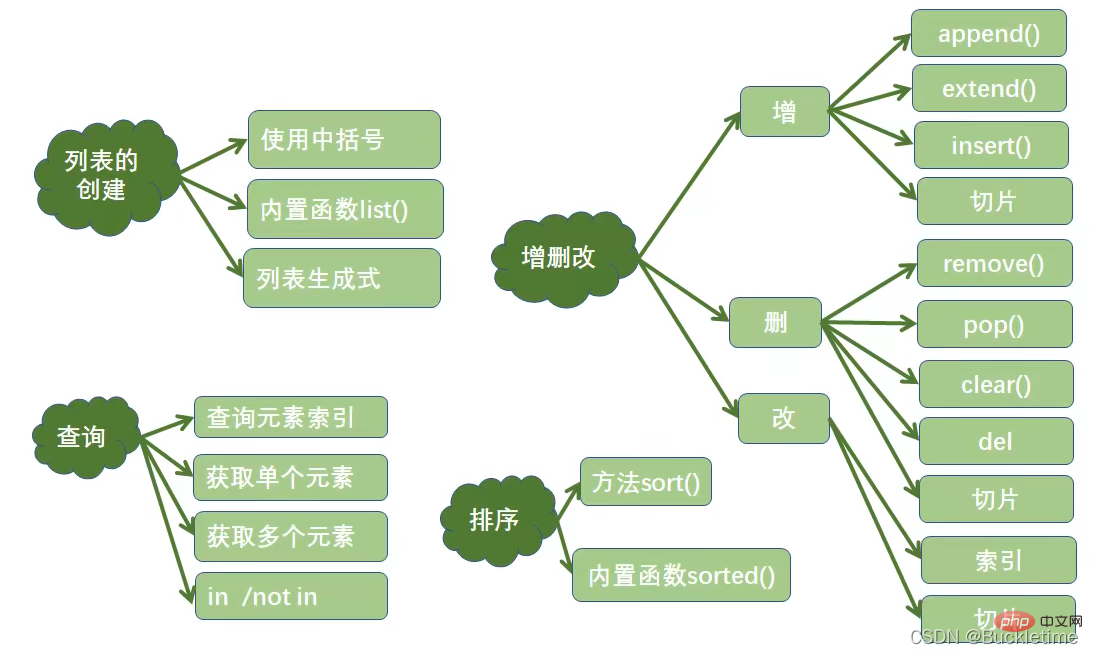
元组 tuple
元组的特点
Python的元组与列表类似,不同之处在于元组的元素不能修改。
元组使用小括号,列表使用方括号
元组的创建
- 直接使用小括号(), 小括号可以省略
t = ('Python', 'hello', 90)
- 使用内置函数tuple(), 若有多个元素必须加小括号
tuple(('Python', 'hello', 90))
- 只包含一个元素的元组,需要使用小括号和逗号
t = (10,)
知识点总结
字典 dict
字典的特点
- 以键值对的方式存储,key唯一
- key必须是不可变对象
- 字典是可变序列
- 字典是无序序列 (注意:自Python3.7本后,dict 对象的插入顺序保留性质已被声明为 Python 语言规范的正式部分。即,Python3.7之后,字典是有序序列,顺序为字典的插入顺序)
字典的创建
- {}:使用花括号
- 使用内置函数dict()
- zip():字典生成式
items = ['fruits', 'Books', 'Others']
prices = [12, 36, 44]
d = {item.upper(): price for item, price in zip(items, prices)}
print(d) # {'FRUITS': 12, 'BOOKS': 36, 'OTHERS': 44}
字典元素的获取
- []:[]取值
scores[‘张三’],若key不存在,抛出keyError异常 - get():get()方法取值,若key不存在,返回None,还可以设置默认返回值
字典元素的新增
user = {"id": 1, "name": "zhangsan"}
user["age"] = 25
print(user) # {'id': 1, 'name': 'zhangsan', 'age': 25}
字典元素的修改
user = {"id": 1, "name": "zhangsan", "age": 25}
user["age"] = 18
print(user) # {'id': 1, 'name': 'zhangsan', 'age': 18}
字典元素的删除
- del :删除指定的键值对或者删除字典
user = {"id": 1, "name": "zhangsan"}del user["id"]print(user) # {'name': 'zhangsan'}del user
- claer():清空字典中的元素
user = {"id": 1, "name": "zhangsan"}user.clear()print(user) # {}
获取字典视图
- keys():获取字典中所有key
- values():获取字典中所有value
- items():获取字典中所有key,value键值对
字典元素的遍历
- 遍历key,再通过key获取value
scores = {'张三': 100, '李四': 95, '王五': 88}for name in scores:
print(name, scores[name])
- 通过items()方法,同时遍历key,value
scores = {'张三': 100, '李四': 95, '王五': 88}for name, score in scores.items():
print(name, score)
知识点总结

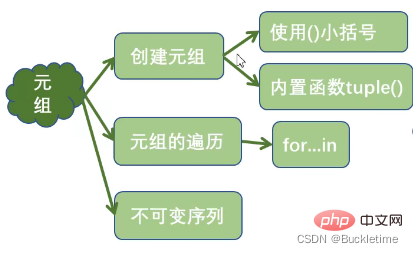
集合 set
集合的特点
- 集合是可变序列
- 集合是没有value的字典
- 集合中元素不重复
- 集合中元素是无序的
集合的创建
- {}
s = {'Python', 'hello', 90}
- 内置函数set()
print(set("Python"))print(set(range(1,6)))print(set([3, 4, 7]))print(set((3, 2, 0)))print(set({"a", "b", "c"}))# 定义空集合:set()print(set())
- 集合生成式
print({i * i for i in range(1, 10)})# {64, 1, 4, 36, 9, 16, 49, 81, 25}
集合的操作
- 集合元素的判断操作
- in / not in
- 集合元素的新增操作
- add():一次添中一个元素
- update(:)添加多个元素
- 集合元素的删除操作
- remove():删除一个指定元素,如果指定的元素不存在抛出KeyError
- discard(:)删除一个指定元素,如果指定的元素不存在不抛异常
- pop():随机删除一个元素
- clear():清空集合
集合间的关系
两个集合是否相等:可以使用运算符 == 或 != 进行判断,只要元素相同就相等
一个集合是否是另一个集合的子集:issubset()
s1 = {10, 20, 30, 40, 50, 60}s2 = {10, 30, 40}s3 = {10, 70}print(s2.issubset(s1))
# Trueprint(s3.issubset(s1)) # False
- 一个集合是否是另一个集合的超集:issuperset()
print(s1.issuperset(s2)) # Trueprint(s1.issuperset(s3)) # False
- 两个集合是否无交集:isdisjoint()
s1 = {10, 20, 30, 40, 50, 60}s2 = {10, 30, 40}s3 = {20, 70}print(s1.isdisjoint(s2))
# False 有交集print(s3.isdisjoint(s2)) # True 无交集
集合的数学操作
- 交集: intersection() 与 &等价,两个集合的交集
s1 = {10, 20, 30, 40}s2 = {20, 30, 40, 50, 60}print(s1.intersection(s2)) # {40, 20, 30}print(s1 & s2) # {40, 20, 30}
- 并集: union() 与 | 等价,两个集合的并集
print(s1.union(s2)) # {40, 10, 50, 20, 60, 30}print(s1 | s2) # {40, 10, 50, 20, 60, 30}
- 差集: difference() 与 - 等价
print(s2.difference(s1)) # {50, 60}print(s2 - s1) # {50, 60}
- 对称差集:symmetric_difference() 与 ^ 等价
print(s2.symmetric_difference(s1)) # {10, 50, 60}print(s2 ^ s1) # {10, 50, 60}
知识点总结
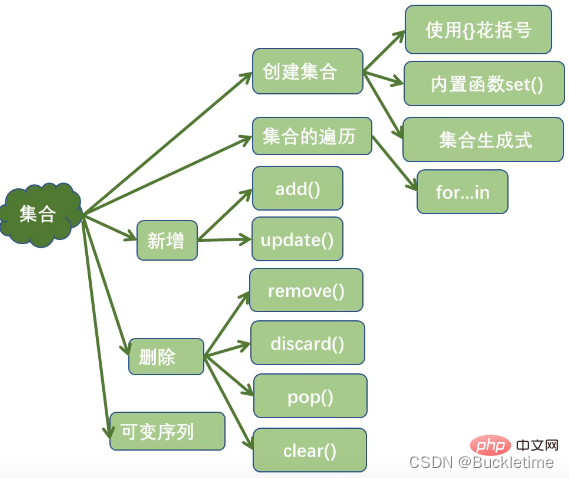
列表、元组、字典、集合总结
推荐学习:python教程
以上是详细介绍Python3数据结构知识点的详细内容。更多信息请关注PHP中文网其他相关文章!

 如何使用numpy创建多维数组?Apr 29, 2025 am 12:27 AM
如何使用numpy创建多维数组?Apr 29, 2025 am 12:27 AM使用NumPy创建多维数组可以通过以下步骤实现:1)使用numpy.array()函数创建数组,例如np.array([[1,2,3],[4,5,6]])创建2D数组;2)使用np.zeros(),np.ones(),np.random.random()等函数创建特定值填充的数组;3)理解数组的shape和size属性,确保子数组长度一致,避免错误;4)使用np.reshape()函数改变数组形状;5)注意内存使用,确保代码清晰高效。
 说明Numpy阵列中'广播”的概念。Apr 29, 2025 am 12:23 AM
说明Numpy阵列中'广播”的概念。Apr 29, 2025 am 12:23 AM播放innumpyisamethodtoperformoperationsonArraySofDifferentsHapesbyAutapityallate AligningThem.itSimplifififiesCode,增强可读性,和Boostsperformance.Shere'shore'showitworks:1)较小的ArraySaraySaraysAraySaraySaraySaraySarePaddedDedWiteWithOnestOmatchDimentions.2)
 说明如何在列表,Array.Array和用于数据存储的Numpy数组之间进行选择。Apr 29, 2025 am 12:20 AM
说明如何在列表,Array.Array和用于数据存储的Numpy数组之间进行选择。Apr 29, 2025 am 12:20 AMforpythondataTastorage,choselistsforflexibilityWithMixedDatatypes,array.ArrayFormeMory-effficityHomogeneousnumericalData,andnumpyArraysForAdvancedNumericalComputing.listsareversareversareversareversArversatilebutlessEbutlesseftlesseftlesseftlessforefforefforefforefforefforefforefforefforefforlargenumerdataSets; arrayoffray.array.array.array.array.array.ersersamiddreddregro
 举一个场景的示例,其中使用Python列表比使用数组更合适。Apr 29, 2025 am 12:17 AM
举一个场景的示例,其中使用Python列表比使用数组更合适。Apr 29, 2025 am 12:17 AMPythonlistsarebetterthanarraysformanagingdiversedatatypes.1)Listscanholdelementsofdifferenttypes,2)theyaredynamic,allowingeasyadditionsandremovals,3)theyofferintuitiveoperationslikeslicing,but4)theyarelessmemory-efficientandslowerforlargedatasets.
 您如何在Python数组中访问元素?Apr 29, 2025 am 12:11 AM
您如何在Python数组中访问元素?Apr 29, 2025 am 12:11 AMtoAccesselementsInapyThonArray,useIndIndexing:my_array [2] accessEsthethEthErlement,returning.3.pythonosezero opitedEndexing.1)usepositiveandnegativeIndexing:my_list [0] fortefirstElment,fortefirstelement,my_list,my_list [-1] fornelast.2] forselast.2)
 Python中有可能理解吗?如果是,为什么以及如果不是为什么?Apr 28, 2025 pm 04:34 PM
Python中有可能理解吗?如果是,为什么以及如果不是为什么?Apr 28, 2025 pm 04:34 PM文章讨论了由于语法歧义而导致的Python中元组理解的不可能。建议使用tuple()与发电机表达式使用tuple()有效地创建元组。(159个字符)
 Python中的模块和包装是什么?Apr 28, 2025 pm 04:33 PM
Python中的模块和包装是什么?Apr 28, 2025 pm 04:33 PM本文解释了Python中的模块和包装,它们的差异和用法。模块是单个文件,而软件包是带有__init__.py文件的目录,在层次上组织相关模块。
 Python中的Docstring是什么?Apr 28, 2025 pm 04:30 PM
Python中的Docstring是什么?Apr 28, 2025 pm 04:30 PM文章讨论了Python中的Docstrings,其用法和收益。主要问题:Docstrings对于代码文档和可访问性的重要性。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

WebStorm Mac版
好用的JavaScript开发工具

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

记事本++7.3.1
好用且免费的代码编辑器

