
python实例详解之xpath解析

- WBOY转载
- 2022-03-31 12:18:452797浏览
本篇文章给大家带来了关于python的相关知识,其中主要介绍了xpath的相关问题,XPath,全称XML Path Language,即XML路径语言,它是一门在XML文档中查找信息的语言,希望对大家有帮助。

推荐学习:python教程
XPath,全称XML Path Language,即XML路径语言,它是一门在XML文档中查找信息的语言,它最初是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索
XPath的选择功能十分强大,它提供了非常简明的路径选择表达式,另外,它还提供了超过100个内建函数,用于字符串、数值、时间的匹配以及节点、序列的处理等,几乎所有我们想要定位的节点,都可以用XPath来选择
xpath解析原理:
实现标签的定位:实例化一个etree的对象,且需要将被解析的页面源码数据加载到该对象中。
调用etree对象中的xpath方法结合着xpath表达式实现标签的定位和内容的捕获。
环境的安装
pip install lxml
lxml是python的一个解析库,支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高
如何实例化一个etree对象
1.将本地的html文档中的源码数据加载到etree对象中:
etree. parse(filePath)#你的文件路径
2.可以将从互联网上获取的源码数据加载到该对象中
etree.HtML('page_ text')#page_ text互联网中响应的数据
xpath 表达式
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 表示的是从根节点开始定位。表示的是一个层级。 |
| // | 表示的是多个层级。可以表示从任意位置开始定位。 |
| . | 选取当前节点 |
| … | 选取当前节点的父节点 |
| @ | 选取属性 |
| * | 通配符,选择所有元素节点与元素名 |
| @* | 选取所有属性 |
| [@attrib] | 选取具有给定属性的所有元素 |
| [@attrib=‘value’] | 选取给定属性具有给定值的所有元素 |
| [tag] | 选取所有具有指定元素的直接子节点 |
| [tag=‘text’] | 选取所有具有指定元素并且文本内容是text节点 |
对上面表达式的实例详解
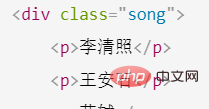
这是一个HTML的文档
<html lang="en"><head> <meta charset="UTF-8" /> <title>测试bs4</title></head><body> <p> <p>百里守约</p> </p> <p class="song"> <p>李清照</p> <p>王安石</p> <p>苏轼</p> <p>柳宗元</p> <a href="http://www.song.com/" title="赵匡胤" target="_self"> <span>this is span</span> 宋朝是最强大的王朝,不是军队的强大,而是经济很强大,国民都很有钱</a> <a href="" class="du">总为浮云能蔽日,长安不见使人愁</a> <img src="http://www.baidu.com/meinv.jpg" alt="" /> </p> <p class="tang"> <ul> <li><a href="http://www.baidu.com" title="qing">清明时节雨纷纷,路上行人欲断魂,借问酒家何处有,牧童遥指杏花村</a></li> <li><a href="http://www.163.com" title="qin">秦时明月汉时关,万里长征人未还,但使龙城飞将在,不教胡马度阴山</a></li> <li><a href="http://www.126.com" alt="qi">岐王宅里寻常见,崔九堂前几度闻,正是江南好风景,落花时节又逢君</a></li> <li><a href="http://www.sina.com" class="du">杜甫</a></li> <li><a href="http://www.dudu.com" class="du">杜牧</a></li> <li><b>杜小月</b></li> <li><i>度蜜月</i></li> <li><a href="http://www.haha.com" id="feng">凤凰台上凤凰游,凤去台空江自流,吴宫花草埋幽径,晋代衣冠成古丘</a></li> </ul> </p></body></html>
从浏览器中打开是这样的
为了方便直观,我们对写个HTML文件进行本地读取进行测试
子节点和子孙节点的定位 / 和 //
先来看子节点和子孙节点,我们从上往下找p这个节点,可以看到p的父节点是body,body父节点是html
定位到这个HTML的p对象中,看上面html源码,可以知道有三个p对象

我们通过三种不同的方法来输出这个节点的信息,可以看到输出的是三个一样的Element,也就是这三种方法实现的功能是一样的。
import requestsfrom lxml import etree
tree = etree.parse('test.html')r1=tree.xpath('/html/body/p') #直接从上往下挨着找节点r2=tree.xpath('/html//p')#跳跃了一个节点来找到这个p节点的对象r3=tree.xpath('//p')##跳跃上面所有节点来寻找p节点的对象r1,r2,r3>>([<Element p at 0x19d44765108>,
<Element p at 0x19d447658c8>,
<Element p at 0x19d44765588>],
[<Element p at 0x19d44765108>,
<Element p at 0x19d447658c8>,
<Element p at 0x19d44765588>],
[<Element p at 0x19d44765108>,
<Element p at 0x19d447658c8>,
<Element p at 0x19d44765588>])
属性定位
如果我只想要p里面song这一个标签,就可以对其属性定位
当然返回的还是一个element
r4=tree.xpath('//p[@class="song"]')r4>>>[<Element p at 0x19d447658c8>]
索引定位
如果我只想获得song里面的苏轼的这个标签
我们找到了song,/p可以返回里面的所有标签,
tree.xpath('//p[@class="song"]/p')>>[<Element p at 0x19d4469a648>,
<Element p at 0x19d4469a4c8>,
<Element p at 0x19d4469af88>,
<Element p at 0x19d4469a148>]
这个单独返回的苏轼的p标签,要注意的是这里的索引不是从0开始的,而是1
tree.xpath('//p[@class="song"]/p[3]')[<Element p at 0x19d4469af88>]
取文本
比如我想取杜牧这个文本内容
和上面一样,我们要定位到杜牧的这个a标签,首先要找到他的上一级 li ,这是第五个 li 里面的a所以就有了下面的写法,text()是把element转化为文本,当然上面的在后面加个text()都可以展示文本内容。
tree.xpath('//p[@class="tang"]//li[5]/a/text()')>>['杜牧']
可以看到这个返回的是一个列表,如果我们想取里面的字符串,可以这样
tree.xpath('//p[@class="tang"]//li[5]/a/text()')[0]杜牧
看一个更直接的,//li 直接定位到 li这个标签,//text()直接将这个标签下的文本提取出来。但要注意,这样会把所有的li标签下面的文本提取出来,有时候你并不想要的文本也会提取出来,所以最好还是写详细一点,如具体到哪个p里的li。
tree.xpath('//li//text()')['清明时节雨纷纷,路上行人欲断魂,借问酒家何处有,牧童遥指杏花村',
'秦时明月汉时关,万里长征人未还,但使龙城飞将在,不教胡马度阴山',
'岐王宅里寻常见,崔九堂前几度闻,正是江南好风景,落花时节又逢君',
'杜甫',
'杜牧',
'杜小月',
'度蜜月',
'凤凰台上凤凰游,凤去台空江自流,吴宫花草埋幽径,晋代衣冠成古丘']
取属性
比如我想取下面这个属性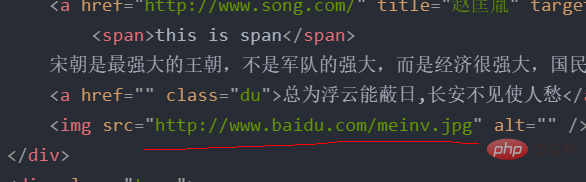
可以直接用@取属性
tree.xpath('//p[@class="song"]/img/@src')['http://www.baidu.com/meinv.jpg']
或者如果我想取所有的href这个属性,可以看到tang和song的所有href属性
tree.xpath('//@href')['http://www.song.com/',
'',
'http://www.baidu.com',
'http://www.163.com',
'http://www.126.com',
'http://www.sina.com',
'http://www.dudu.com',
'http://www.haha.com']
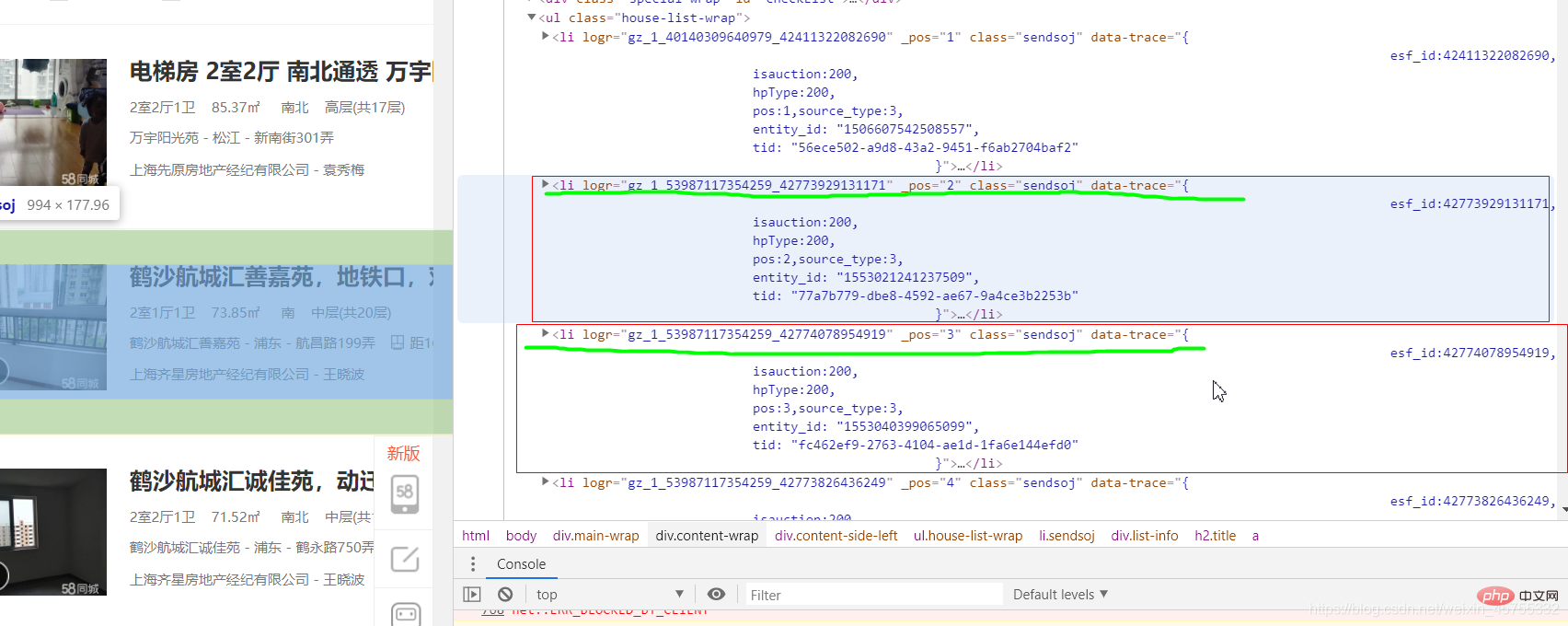
爬虫实战之58同城房源信息
#导入必要的库import requestsfrom lxml import etree#URL就是网址,headers看图一url='https://sh.58.com/ershoufang/'headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.7 Safari/537.36'}#对网站发起请求page_test=requests.get(url=url,headers=headers).text# 这里是将从互联网上获取的源码数据加载到该对象中tree=etree.HTML(page_test)#先看图二的解释,这里li有多个,所里返回的li_list是一个列表li_list=tree.xpath('//ul[@class="house-list-wrap"]/li')#这里我们打开一个58.txt文件来保存我们的信息fp=open('58.txt','w',encoding='utf-8')#li遍历li_listfor li in li_list:
#这里 ./是对前面li的继承,相当于li/p...
title=li.xpath('./p[2]/h2/a/text()')[0]
print(title+'\n')
#把文件写入文件
fp.write(title+'\n')fp.close()
图一: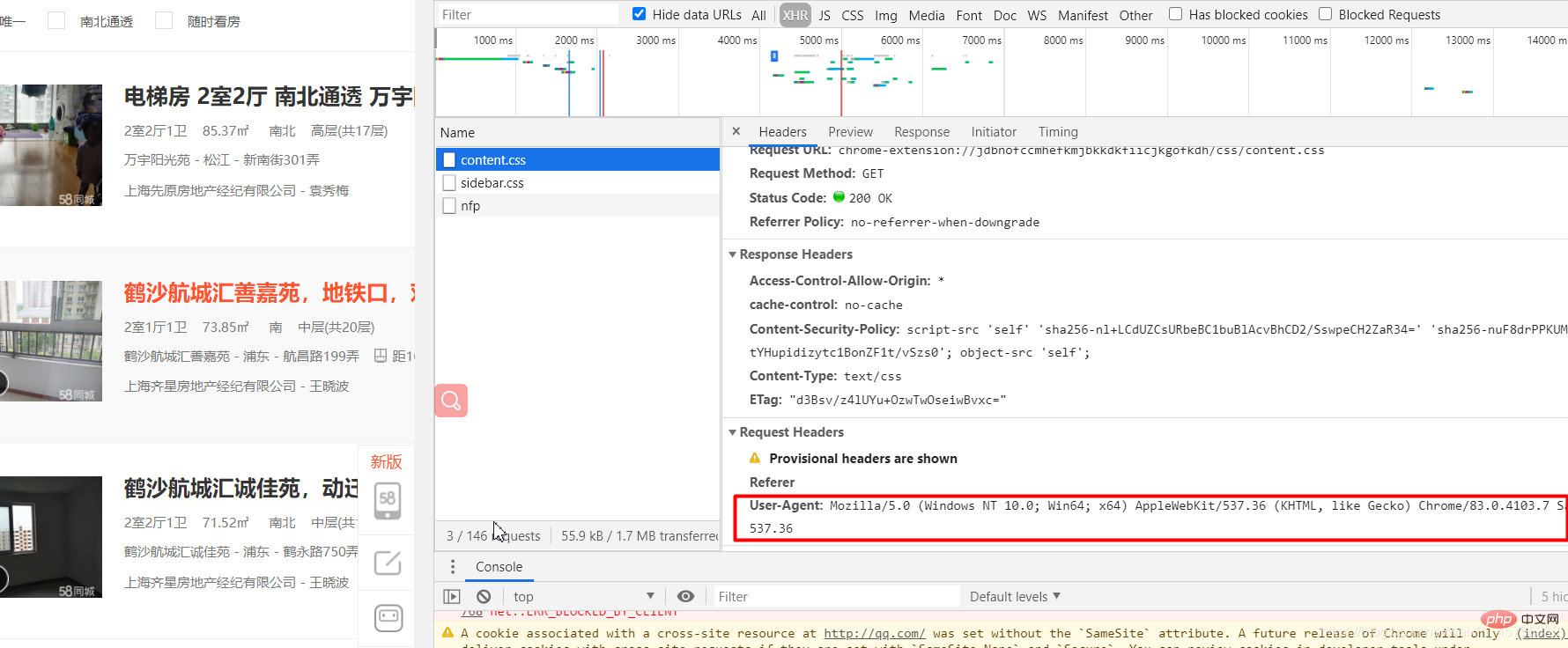
图二:.
这里我们要提取所有的房源信息,可以看到每个小节点的上一个节点都是一样的,我们要提取的是h2节点a里的房源信息,看图三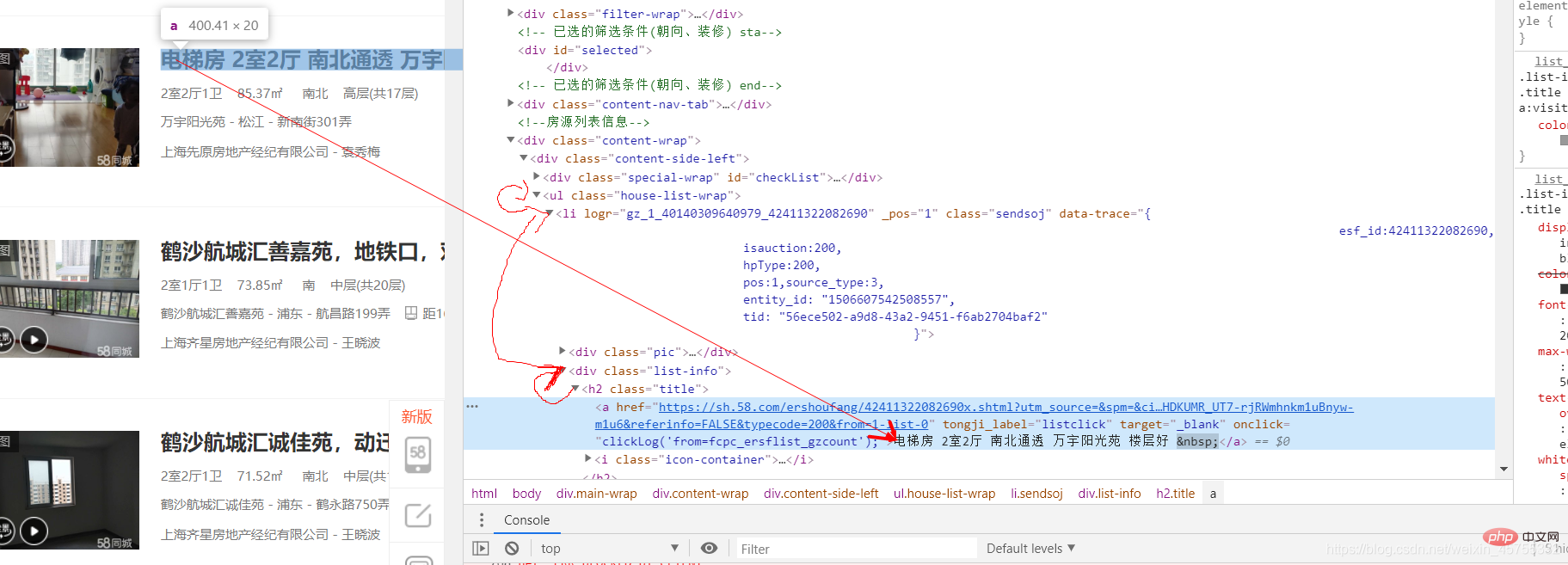
这里每个 /li 节点里面的子节点都是一样的,所以我们可以先找到所有的li节点,再往下找我们想要的信息
推荐学习:python教程
以上是python实例详解之xpath解析的详细内容。更多信息请关注PHP中文网其他相关文章!