



本篇文章给大家带来了关于Redis教程中的相关知识,其中主要介绍了Redis的LRU缓存淘汰算法实现相关问题,LRU会使用一个链表维护缓存中每个数据的访问情况,并根据数据的实时访问,调整数据在链表中的位置,希望对大家有帮助。

推荐学习:Redis学习教程
1 标准LRU的实现原理
LRU,最近最少使用(Least Recently Used,LRU),经典缓存算法。
LRU会使用一个链表维护缓存中每个数据的访问情况,并根据数据的实时访问,调整数据在链表中的位置,然后通过数据在链表中的位置,表示数据是最近刚访问的,还是已有段时间未访问。
LRU会把链头、尾分别设为MRU端和LRU端:
- MRU,Most Recently Used 缩写,表示此处数据刚被访问
- LRU端,此处数据最近最少被访问的数据
LRU可分成如下情况:
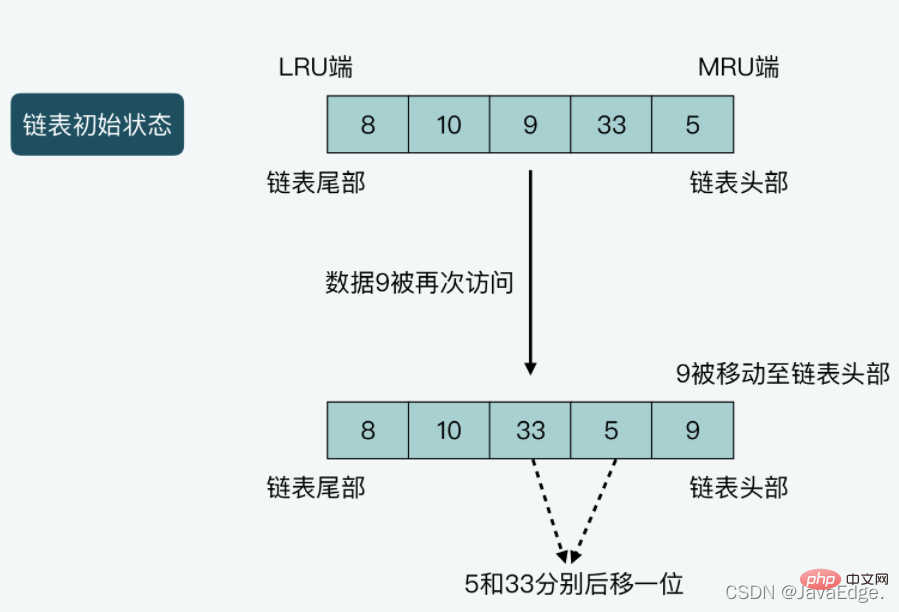
- case1:当有新数据插入,LRU会把该数据插入到链首,同时把原来链表头部的数据及其之后的数据,都向尾部移动一位
- case2:当有数据刚被访问一次后,LRU会把该数据从它在链表中当前位置,移动到链首。把从链表头部到它当前位置的其他数据,都向尾部移动一位
- case3:当链表长度无法再容纳更多数据,再有新数据插入,LRU去除链表尾部的数据,这也相当于将数据从缓存中淘汰掉
case2图解:链表长度为5,从链表头部到尾部保存的数据分别是5,33,9,10,8。假设数据9被访问一次,则9就会被移动到链表头部,同时,数据5和33都要向链表尾部移动一位。
所以若严格按LRU实现,假设Redis保存的数据较多,还要在代码中实现:
-
为Redis使用最大内存时,可容纳的所有数据维护一个链表
需额外内存空间来保存链表
-
每当有新数据插入或现有数据被再次访问,需执行多次链表操作
在访问数据的过程中,让Redis受到数据移动和链表操作的开销影响
最终导致降低Redis访问性能。
所以,无论是为节省内存 or 保持Redis高性能,Redis并未严格按LRU基本原理实现,而是提供了一个近似LRU算法实现。
2 Redis的近似LRU算法实现
Redis的内存淘汰机制是如何启用近似LRU算法的?redis.conf中的如下配置参数:
maxmemory,设定Redis server可使用的最大内存容量,一旦server使用实际内存量超出该阈值,server会根据maxmemory-policy配置策略,执行内存淘汰操作
maxmemory-policy,设定Redis server内存淘汰策略,包括近似LRU、LFU、按TTL值淘汰和随机淘汰等

所以,一旦设定maxmemory选项,且将maxmemory-policy配为allkeys-lru或volatile-lru,近似LRU就被启用。allkeys-lru和volatile-lru都会使用近似LRU淘汰数据,区别在于:
- allkeys-lru是在所有的KV对中筛选将被淘汰的数据
- volatile-lru在设置了TTL的KV对中筛选将被淘汰数据
Redis如何实现近似LRU算法的呢?
-
全局LRU时钟值的计算
如何计算全局LRU时钟值的,以用来判断数据访问的时效性
-
键值对LRU时钟值的初始化与更新
哪些函数中对每个键值对对应的LRU时钟值,进行初始化与更新
-
近似LRU算法的实际执行
如何执行近似LRU算法,即何时触发数据淘汰,以及实际淘汰的机制实现
2.1 全局LRU时钟值的计算
近似LRU算法仍需区分不同数据的访问时效性,即Redis需知道数据的最近一次访问时间。因此,有了LRU时钟:记录数据每次访问的时间戳。
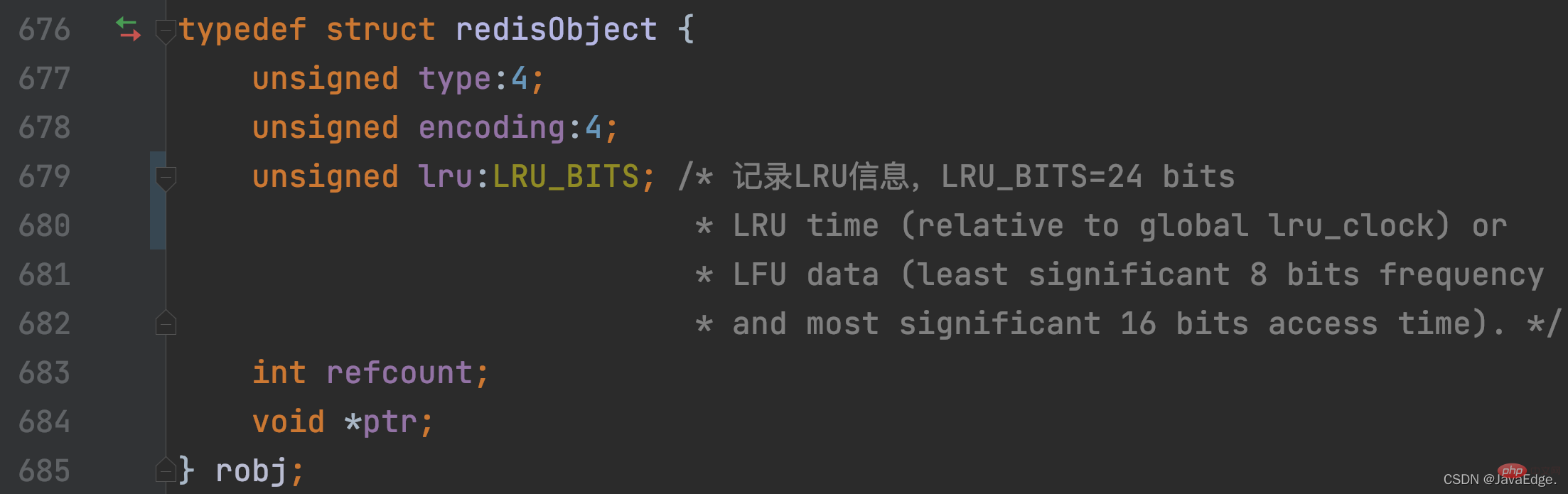
Redis对每个KV对中的V,会使用个redisObject结构体保存指向V的指针。那redisObject除记录值的指针,还会使用24 bits保存LRU时钟信息,对应的是lru成员变量。这样,每个KV对都会把它最近一次被访问的时间戳,记录在lru变量。
redisObject定义包含lru成员变量的定义:
每个KV对的LRU时钟值是如何计算的?Redis Server使用一个实例级别的全局LRU时钟,每个KV对的LRU time会根据全局LRU时钟进行设置。
这全局LRU时钟保存在Redis全局变量server的成员变量lruclock

当Redis Server启动后,调用initServerConfig初始化各项参数时,会调用getLRUClock设置lruclock的值:

于是,就得注意,**若一个数据前后两次访问的时间间隔<1s,那这两次访问的时间戳就是一样的!**因为LRU时钟精度就是1s,它无法区分间隔小于1秒的不同时间戳!
getLRUClock函数将获得的UNIX时间戳,除以LRU_CLOCK_RESOLUTION后,就得到了以LRU时钟精度来计算的UNIX时间戳,也就是当前的LRU时钟值。
getLRUClock会把LRU时钟值和宏定义LRU_CLOCK_MAX(LRU时钟能表示的最大值)做与运算。

所以默认情况下,全局LRU时钟值是以1s为精度计算得UNIX时间戳,且是在initServerConfig中进行的初始化。
那Redis Server运行过程中,全局LRU时钟值是如何更新的?和Redis Server在事件驱动框架中,定期运行的时间事件所对应的serverCron有关。
serverCron作为时间事件的回调函数,本身会周期性执行,其频率值由redis.conf的hz配置项决定,默认值10,即serverCron函数会每100ms(1s/10 = 100ms)运行一次。serverCron中,全局LRU时钟值就会按该函数执行频率,定期调用getLRUClock进行更新:

这样,每个KV对就能从全局LRU时钟获取最新访问时间戳。
对于每个KV对,它对应的redisObject.lru在哪些函数进行初始化和更新的呢?
2.2 键值对LRU时钟值的初始化与更新
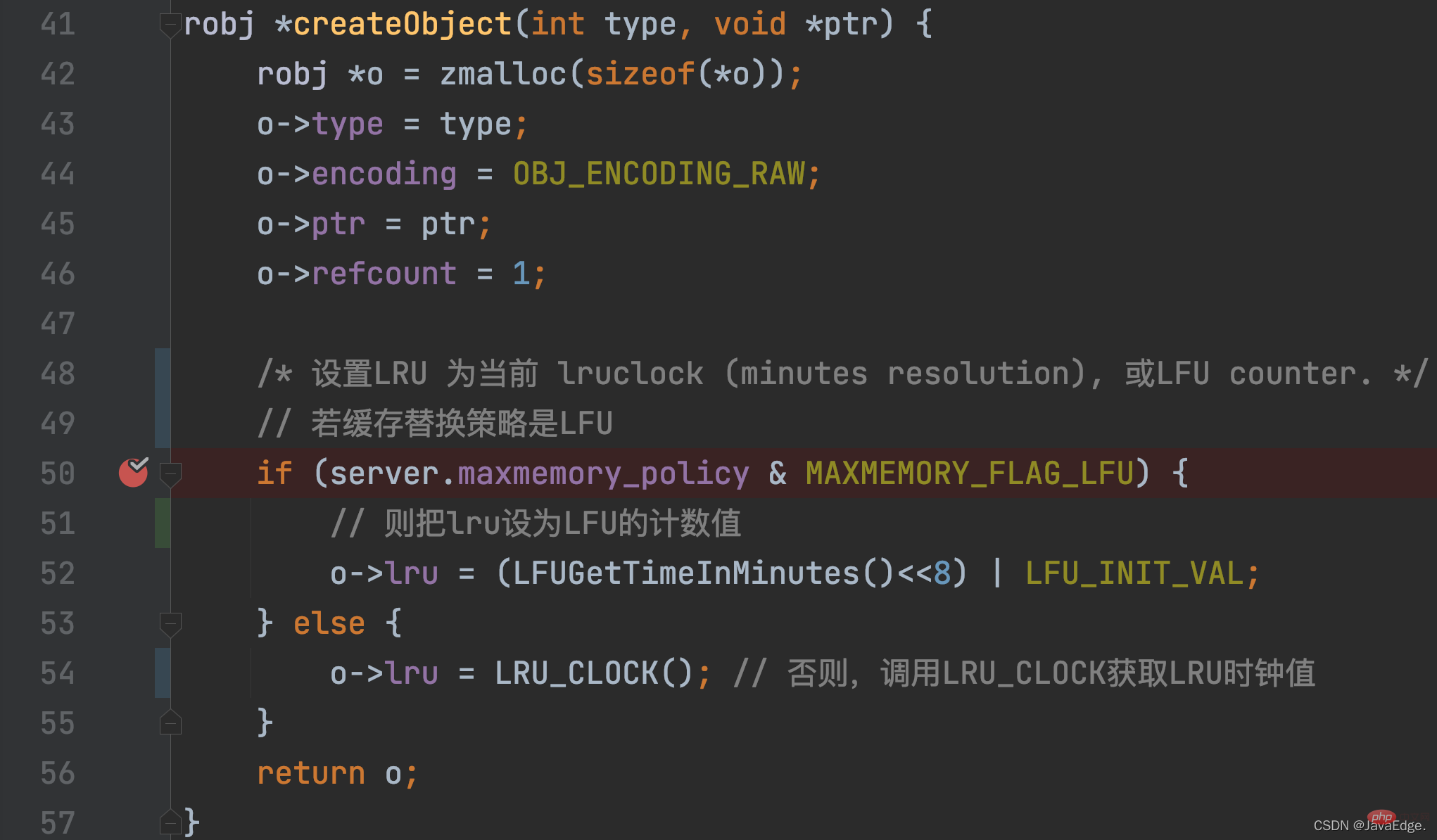
对于一个KV对,其LRU时钟值最初是在这KV对被创建时,进行初始化设置的,这初始化操作在createObject函数中调用,当Redis要创建一个KV对,就会调用该函数。
createObject除了会给redisObject分配内存空间,还会根据maxmemory_policy配置,初始化设置redisObject.lru。
- 若maxmemory_policy=LFU,则lru变量值会被初始化设置为LFU算法的计算值
- maxmemory_policy≠LFU,则createObject调用LRU_CLOCK设置lru值,即KV对对应的LRU时钟值。
LRU_CLOCK返回当前全局LRU时钟值。因为一个KV对一旦被创建,就相当于有了次访问,其对应LRU时钟值就表示了它的访问时间戳:
那一个KV对的LRU时钟值又是何时再被更新?
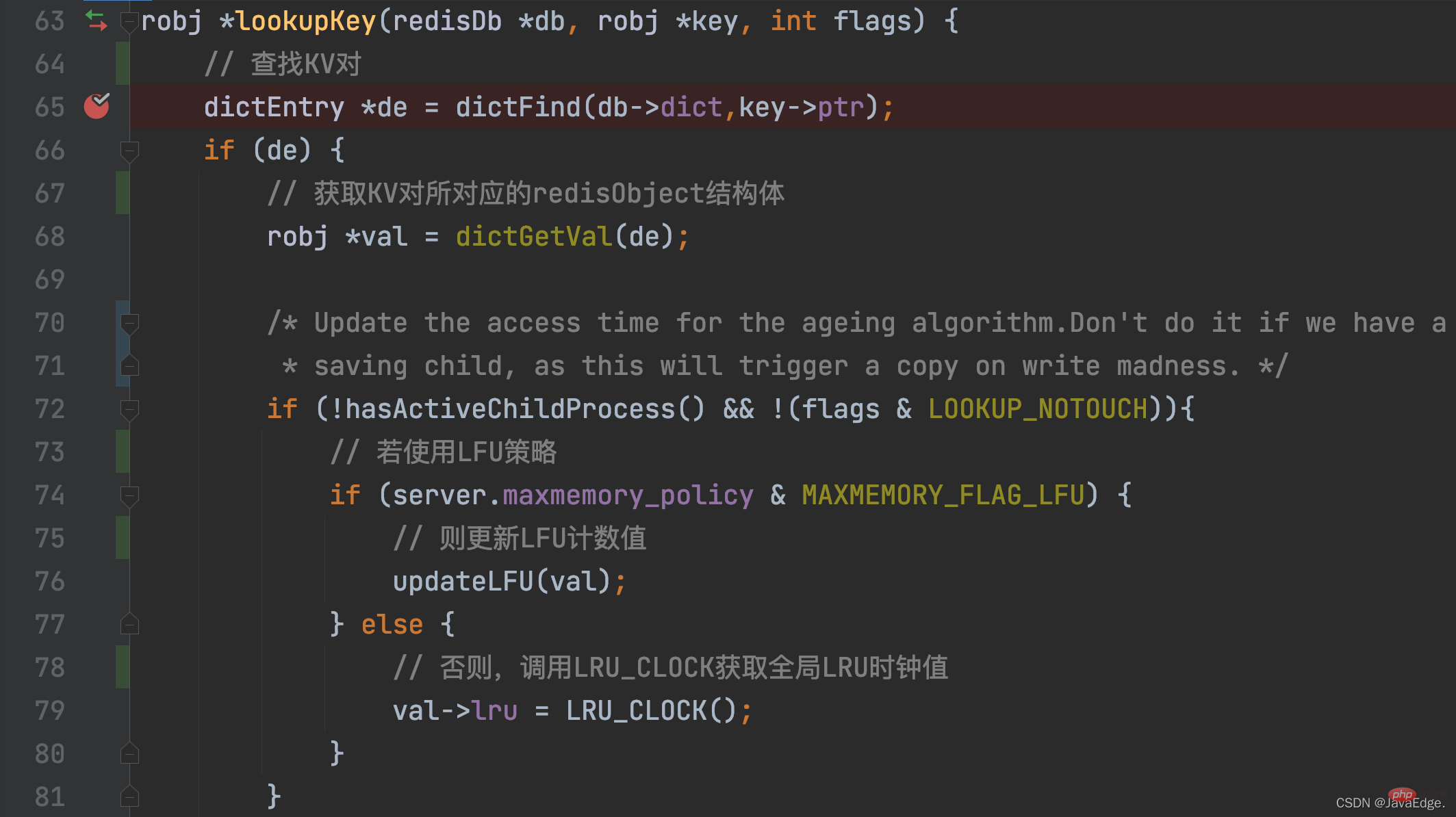
只要一个KV对被访问,其LRU时钟值就会被更新!而当一个KV对被访问时,访问操作最终都会调用lookupKey。
lookupKey会从全局哈希表中查找要访问的KV对。若该KV对存在,则lookupKey会根据maxmemory_policy的配置值,来更新键值对的LRU时钟值,也就是它的访问时间戳。
而当maxmemory_policy没有配置为LFU策略时,lookupKey函数就会调用LRU_CLOCK函数,来获取当前的全局LRU时钟值,并将其赋值给键值对的redisObject结构体中的lru变量
这样,每个KV对一旦被访问,就能获得最新的访问时间戳。但你可能好奇:这些访问时间戳最终是如何被用于近似LRU算法进行数据淘汰的?
2.3 近似LRU算法的实际执行
Redis之所以实现近似LRU,是为减少内存资源和操作时间上的开销。
2.3.1 何时触发算法执行?
近似LRU主要逻辑在performEvictions。
performEvictions被evictionTimeProc调用,而evictionTimeProc函数又是被processCommand调用。
processCommand,Redis处理每个命令时都会调用:
 然后,isSafeToPerformEvictions还会再次根据如下条件判断是否继续执行performEvictions:
然后,isSafeToPerformEvictions还会再次根据如下条件判断是否继续执行performEvictions:


一旦performEvictions被调用,且maxmemory-policy被设置为allkeys-lru或volatile-lru,近似LRU就被触发执行了。
2.3.2 近似LRU具体执行过程
执行可分成如下步骤:
2.3.2.1 判断当前内存使用情况
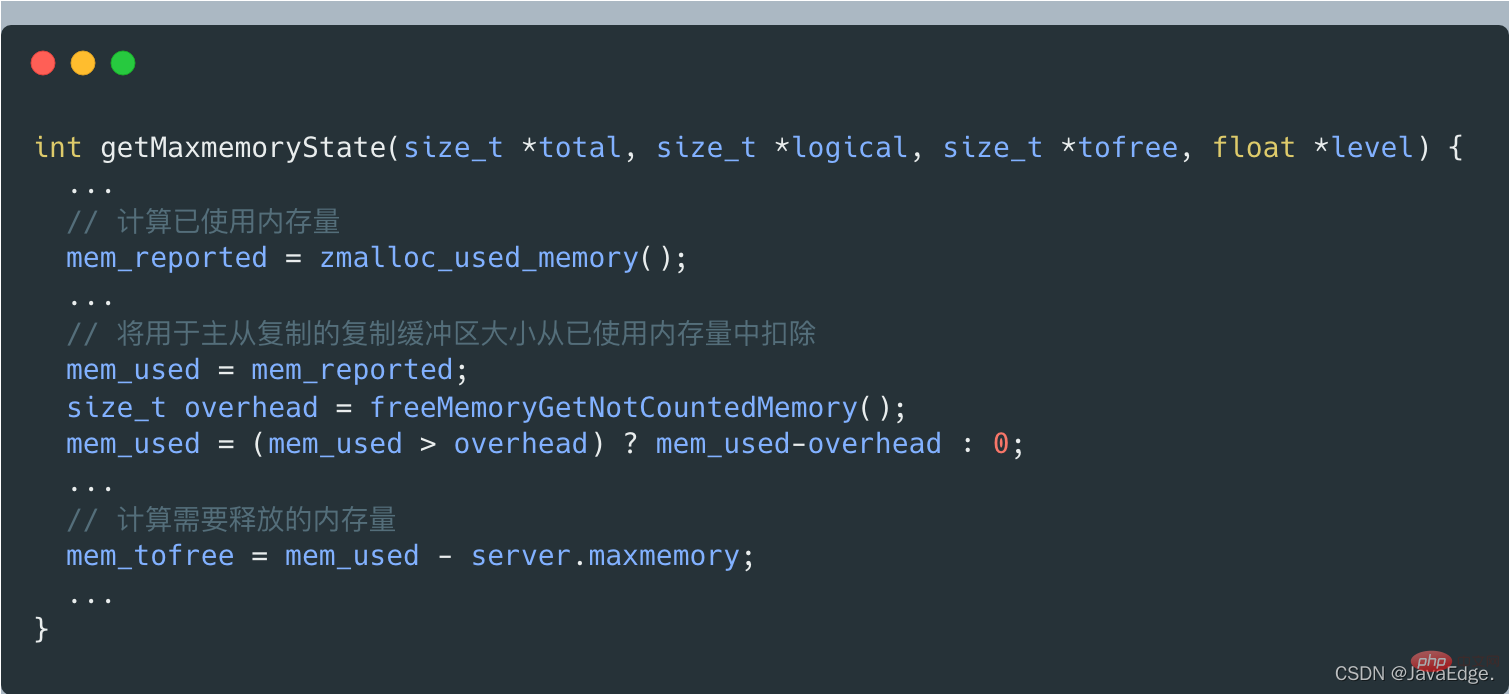
调用getMaxmemoryState评估当前内存使用情况,判断当前Redis Server使用内存容量是否超过maxmemory配置值。
若未超过maxmemory,则返回C_OK,performEvictions也会直接返回。

getMaxmemoryState评估当前内存使用情况的时候,若发现已用内存超出maxmemory,会计算需释放的内存量。这个释放内存大小=已使用内存量-maxmemory。
但已使用内存量并不包括用于主从复制的复制缓冲区大小,这是getMaxmemoryState通过调用freeMemoryGetNotCountedMemory计算的。
而若当前Server使用的内存量超出maxmemory上限,则performEvictions会执行while循环淘汰数据释放内存。
为淘汰数据,Redis定义数组EvictionPoolLRU,保存待淘汰的候选KV对,元素类型是evictionPoolEntry结构体,保存了待淘汰KV对的空闲时间idle、对应K等信息:


这样,Redis Server在执行initSever进行初始化时,会调用evictionPoolAlloc为EvictionPoolLRU数组分配内存空间,该数组大小由EVPOOL_SIZE决定,默认可保存16个待淘汰的候选KV对。
performEvictions在淘汰数据的循环流程中,就会更新这个待淘汰的候选KV对集合,即EvictionPoolLRU数组。
2.3.2.2 更新待淘汰的候选KV对集合
performEvictions调用evictionPoolPopulate,其会先调用dictGetSomeKeys,从待采样哈希表随机获取一定数量K:
- dictGetSomeKeys采样的哈希表,由maxmemory_policy配置项决定:
- 若maxmemory_policy=allkeys_lru,则待采样哈希表是Redis Server的全局哈希表,即在所有KV对中采样
- 否则,待采样哈希表就是保存着设置了TTL的K的哈希表。
- dictGetSomeKeys采样的K的数量由配置项maxmemory-samples决定,默认5:

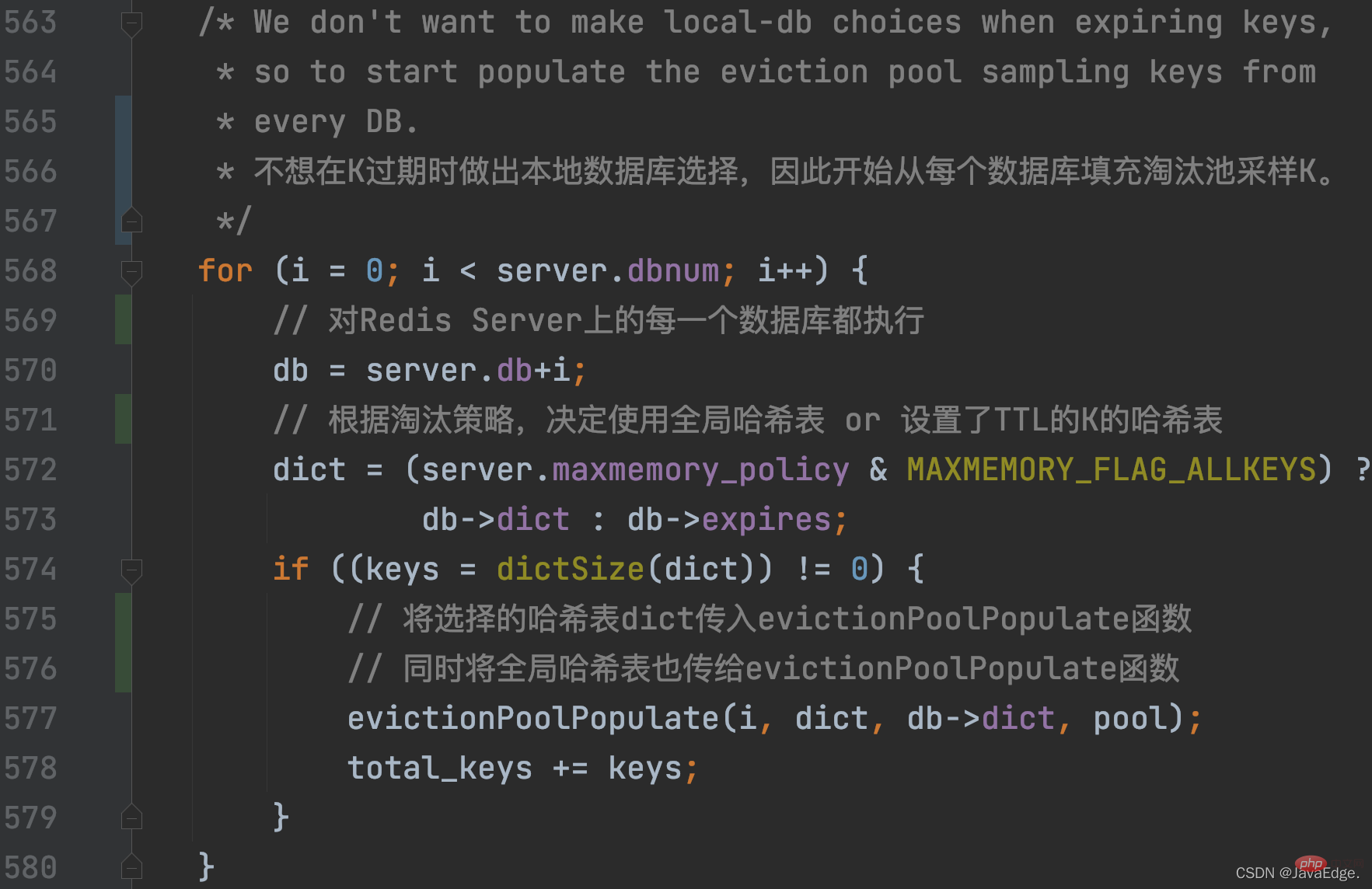
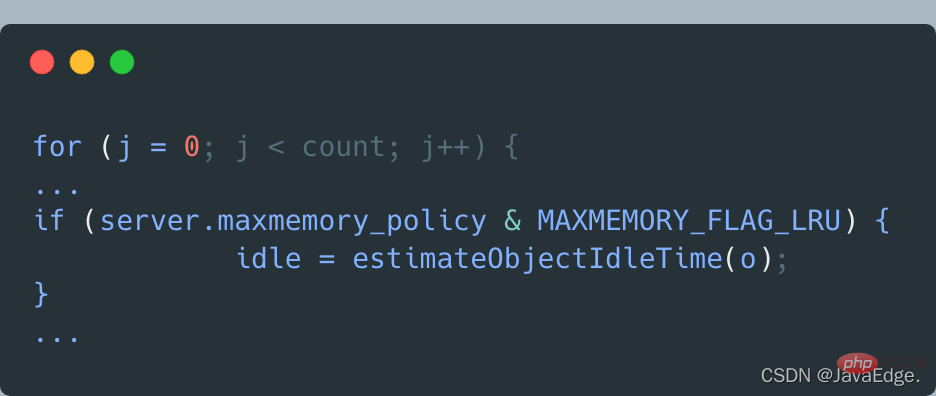
于是,dictGetSomeKeys返回采样的KV对集合。evictionPoolPopulate根据实际采样到的KV对数量count,执行循环:调用estimateObjectIdleTime计算在采样集合中的每一个KV对的空闲时间:
接着,evictionPoolPopulate遍历待淘汰的候选KV对集合,即EvictionPoolLRU数组,尝试把采样的每个KV对插入EvictionPoolLRU数组,取决于如下条件之一:
- 能在数组中找到一个尚未插入KV对的空位
- 能在数组中找到一个KV对的空闲时间<采样KV对的空闲时间
有一成立,evictionPoolPopulate就能把采样KV对插入EvictionPoolLRU数组。等所有采样键值对都处理完后,evictionPoolPopulate函数就完成对待淘汰候选键值对集合的更新了。
接下来,performEvictions开始选择最终被淘汰的KV对。
2.3.2.3 选择被淘汰的KV对并删除
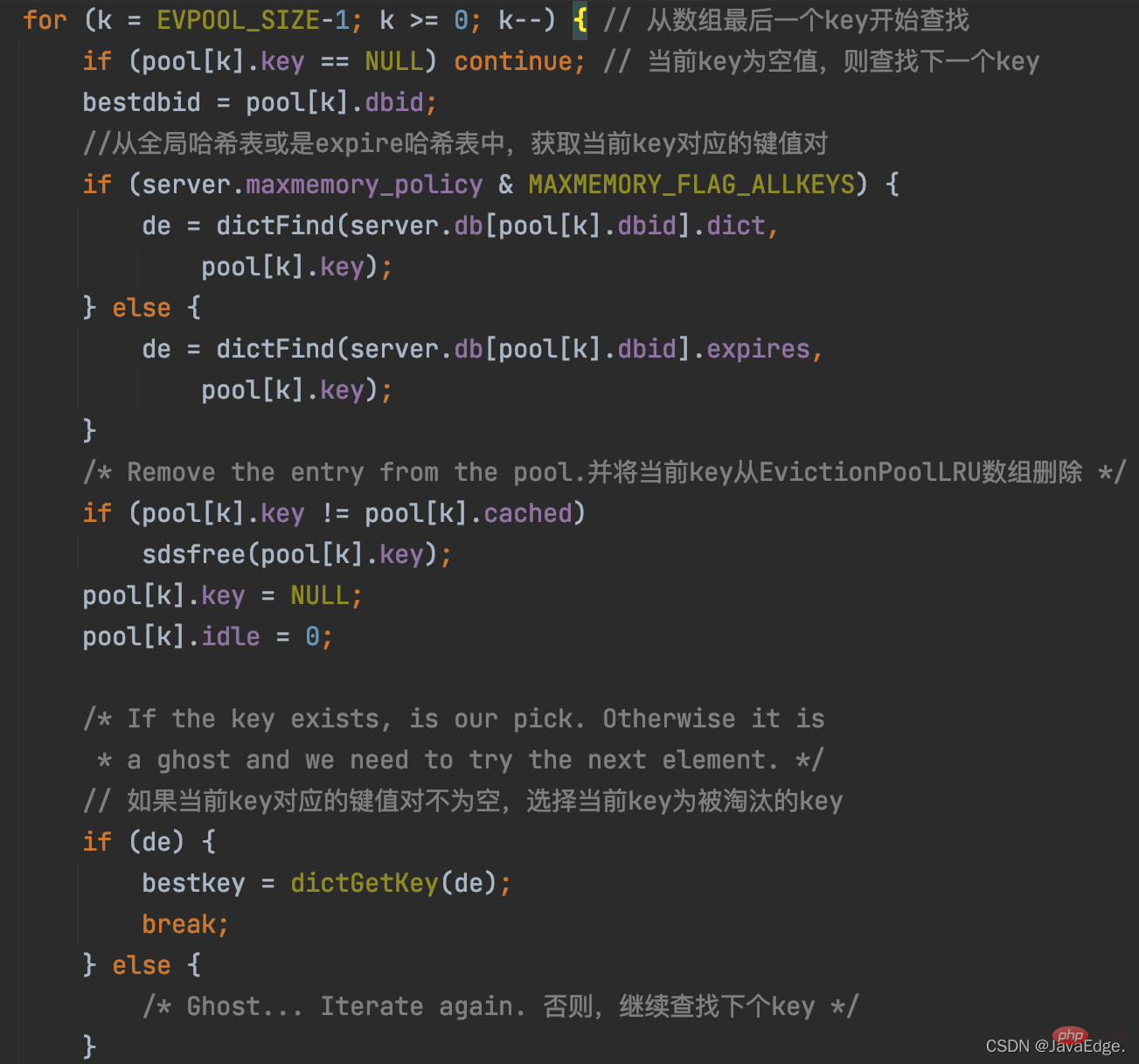
因evictionPoolPopulate已更新EvictionPoolLRU数组,且该数组里的K,是按空闲时间从小到大排好序了。所以,performEvictions遍历一次EvictionPoolLRU数组,从数组的最后一个K开始选择,若选到的K非空,就把它作为最终淘汰的K。
该过程执行逻辑:
一旦选到被淘汰的K,performEvictions就会根据Redis server的惰性删除配置,执行同步删除或异步删除:
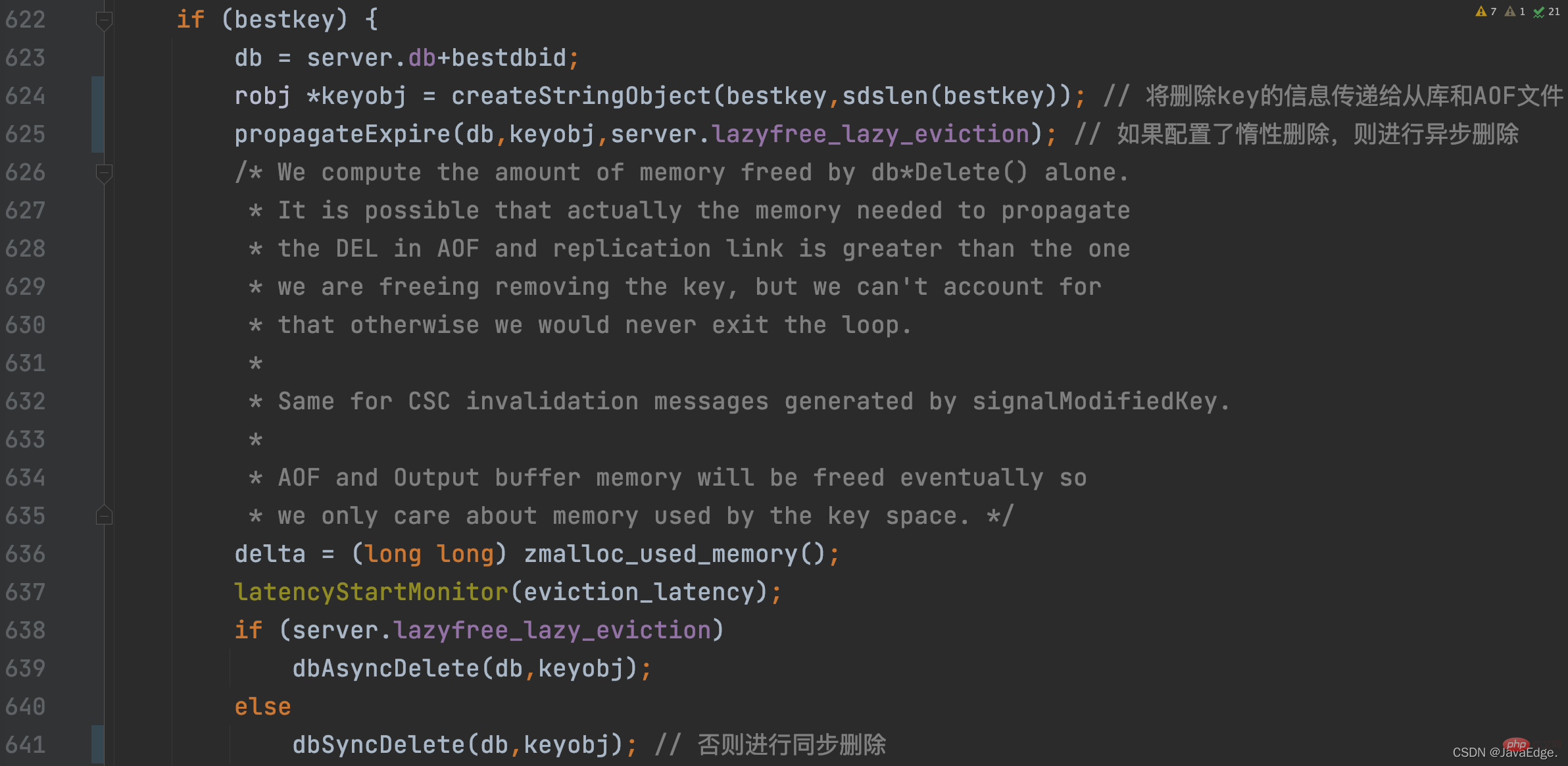
至此,performEvictions就淘汰了一个K。若此时释放的内存空间还不够,即没有达到待释放空间,则performEvictions还会重复执行前面所说的更新待淘汰候选KV对集合、选择最终淘汰K的过程,直到满足待释放空间的大小要求。
performEvictions流程:
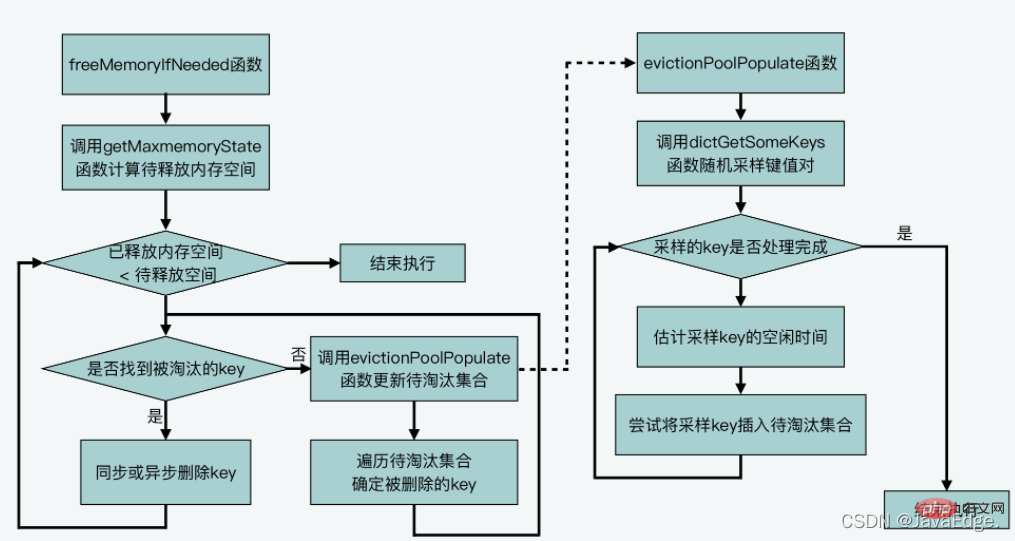
近似LRU算法并未使用耗时且耗空间的链表,而使用固定大小的待淘汰数据集合,每次随机选择一些K加入待淘汰数据集合。
最后,按待淘汰集合中K的空闲时间长度,删除空闲时间最长的K。
总结
根据LRU算法的基本原理,发现若严格按基本原理实现LRU算法,则开发的系统就需要额外内存空间保存LRU链表,系统运行时也会受到LRU链表操作的开销影响。
而Redis的内存资源和性能都很重要,所以Redis实现近似LRU算法:
- 首先是设置了全局LRU时钟,并在KV对创建时获取全局LRU时钟值作为访问时间戳,及在每次访问时获取全局LRU时钟值,更新访问时间戳
- 然后,当Redis每处理一个命令,都调用performEvictions判断是否需释放内存。若已使用内存超出maxmemory,则随机选择一些KV对,组成待淘汰候选集合,并根据它们的访问时间戳,选出最旧数据淘汰
一个算法的基本原理和算法的实际执行,在系统开发中会有一定折中,需综合考虑所开发的系统,在资源和性能方面的要求,以避免严格按照算法实现带来的资源和性能开销。
推荐学习:Redis教程
以上是简单理解Redis的LRU缓存淘汰算法实现的详细内容。更多信息请关注PHP中文网其他相关文章!

 es和redis区别Jul 06, 2019 pm 01:45 PM
es和redis区别Jul 06, 2019 pm 01:45 PMRedis是现在最热门的key-value数据库,Redis的最大特点是key-value存储所带来的简单和高性能;相较于MongoDB和Redis,晚一年发布的ES可能知名度要低一些,ES的特点是搜索,ES是围绕搜索设计的。
 一起来聊聊Redis有什么优势和特点May 16, 2022 pm 06:04 PM
一起来聊聊Redis有什么优势和特点May 16, 2022 pm 06:04 PM本篇文章给大家带来了关于redis的相关知识,其中主要介绍了关于redis的一些优势和特点,Redis 是一个开源的使用ANSI C语言编写、遵守 BSD 协议、支持网络、可基于内存、分布式存储数据库,下面一起来看一下,希望对大家有帮助。
 实例详解Redis Cluster集群收缩主从节点Apr 21, 2022 pm 06:23 PM
实例详解Redis Cluster集群收缩主从节点Apr 21, 2022 pm 06:23 PM本篇文章给大家带来了关于redis的相关知识,其中主要介绍了Redis Cluster集群收缩主从节点的相关问题,包括了Cluster集群收缩概念、将6390主节点从集群中收缩、验证数据迁移过程是否导致数据异常等,希望对大家有帮助。
 Redis实现排行榜及相同积分按时间排序功能的实现Aug 22, 2022 pm 05:51 PM
Redis实现排行榜及相同积分按时间排序功能的实现Aug 22, 2022 pm 05:51 PM本篇文章给大家带来了关于redis的相关知识,其中主要介绍了Redis实现排行榜及相同积分按时间排序,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,希望对大家有帮助。
 详细解析Redis中命令的原子性Jun 01, 2022 am 11:58 AM
详细解析Redis中命令的原子性Jun 01, 2022 am 11:58 AM本篇文章给大家带来了关于redis的相关知识,其中主要介绍了关于原子操作中命令原子性的相关问题,包括了处理并发的方案、编程模型、多IO线程以及单命令的相关内容,下面一起看一下,希望对大家有帮助。
 一文搞懂redis的bitmapApr 27, 2022 pm 07:48 PM
一文搞懂redis的bitmapApr 27, 2022 pm 07:48 PM本篇文章给大家带来了关于redis的相关知识,其中主要介绍了bitmap问题,Redis 为我们提供了位图这一数据结构,位图数据结构其实并不是一个全新的玩意,我们可以简单的认为就是个数组,只是里面的内容只能为0或1而已,希望对大家有帮助。
 实例详解Redis实现排行榜及相同积分按时间排序功能的实现Aug 26, 2022 pm 02:09 PM
实例详解Redis实现排行榜及相同积分按时间排序功能的实现Aug 26, 2022 pm 02:09 PM本篇文章给大家带来了关于redis的相关知识,其中主要介绍了Redis实现排行榜及相同积分按时间排序,本文通过实例代码给大家介绍的非常详细,下面一起来看一下,希望对大家有帮助。
 一起聊聊Redis实现秒杀的问题May 27, 2022 am 11:40 AM
一起聊聊Redis实现秒杀的问题May 27, 2022 am 11:40 AM本篇文章给大家带来了关于redis的相关知识,其中主要介绍了关于实现秒杀的相关内容,包括了秒杀逻辑、存在的链接超时、超卖和库存遗留的问题,下面一起来看一下,希望对大家有帮助。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

WebStorm Mac版
好用的JavaScript开发工具

SublimeText3 Linux新版
SublimeText3 Linux最新版

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

