



有些表的数据量增长很快,对应SQL扫描了很多无效数据,导致SQL慢了下来,通过确认之后,这些大表都是一些流水、记录、日志类型数据,只需要保留1到3个月,此时需要对表做数据清理实现瘦身。

这篇文章我会从InnoDB存储空间分布,delete对性能的影响,以及优化建议方面解释为什么不建议delete删除数据。
InnoDB存储架构
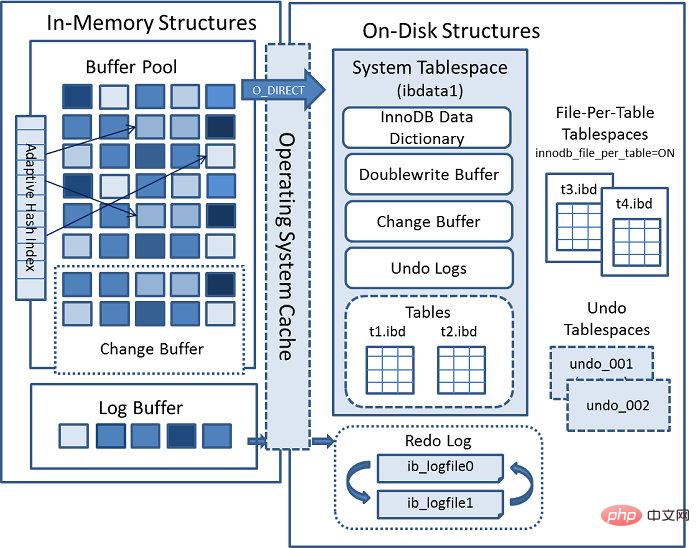
从这张图可以看到,InnoDB存储结构主要包括两部分:逻辑存储结构和物理存储结构。
逻辑上是由表空间tablespace —> 段segment或者inode —> 区Extent ——>数据页Page构成,Innodb逻辑管理单位是segment,空间分配的最小单位是extent,每个segment都会从表空间FREE_PAGE中分配32个page,当这32个page不够用时,会按照以下原则进行扩展:如果当前小于1个extent,则扩展到1个extent;当表空间小于32MB时,每次扩展一个extent;表空间大于32MB,每次扩展4个extent。
物理上主要由系统用户数据文件,日志文件组成,数据文件主要存储MySQL字典数据和用户数据,日志文件记录的是data page的变更记录,用于MySQL Crash时的恢复。
Innodb表空间
InnoDB存储包括三类表空间:系统表空间,用户表空间,Undo表空间。
系统表空间: 主要存储MySQL内部的数据字典数据,如information_schema下的数据。
用户表空间: 当开启innodb_file_per_table=1时,数据表从系统表空间独立出来存储在以table_name.ibd命令的数据文件中,结构信息存储在table_name.frm文件中。
Undo表空间: 存储Undo信息,如快照一致读和flashback都是利用undo信息。
从MySQL 8.0开始允许用户自定义表空间,具体语法如下:
CREATE TABLESPACE tablespace_name
ADD DATAFILE 'file_name' #数据文件名
USE LOGFILE GROUP logfile_group #自定义日志文件组,一般每组2个logfile。
[EXTENT_SIZE [=] extent_size] #区大小
[INITIAL_SIZE [=] initial_size] #初始化大小
[AUTOEXTEND_SIZE [=] autoextend_size] #自动扩宽尺寸
[MAX_SIZE [=] max_size] #单个文件最大size,最大是32G。
[NODEGROUP [=] nodegroup_id] #节点组
[WAIT]
[COMMENT [=] comment_text]
ENGINE [=] engine_name这样的好处是可以做到数据的冷热分离,分别用HDD和SSD来存储,既能实现数据的高效访问,又能节约成本,比如可以添加两块500G硬盘,经过创建卷组vg,划分逻辑卷lv,创建数据目录并mount相应的lv,假设划分的两个目录分别是/hot_data 和 /cold_data。
这样就可以将核心的业务表如用户表,订单表存储在高性能SSD盘上,一些日志,流水表存储在普通的HDD上,主要的操作步骤如下:
#创建热数据表空间 create tablespace tbs_data_hot add datafile '/hot_data/tbs_data_hot01.dbf' max_size 20G; #创建核心业务表存储在热数据表空间 create table booking(id bigint not null primary key auto_increment, …… ) tablespace tbs_data_hot; #创建冷数据表空间 create tablespace tbs_data_cold add datafile '/hot_data/tbs_data_cold01.dbf' max_size 20G; #创建日志,流水,备份类的表存储在冷数据表空间 create table payment_log(id bigint not null primary key auto_increment, …… ) tablespace tbs_data_cold; #可以移动表到另一个表空间 alter table payment_log tablespace tbs_data_hot;
Inndob存储分布
创建空表查看空间变化
mysql> create table user(id bigint not null primary key auto_increment,
-> name varchar(20) not null default '' comment '姓名',
-> age tinyint not null default 0 comment 'age',
-> gender char(1) not null default 'M' comment '性别',
-> phone varchar(16) not null default '' comment '手机号',
-> create_time datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
-> update_time datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间'
-> ) engine = InnoDB DEFAULT CHARSET=utf8mb4 COMMENT '用户信息表';
Query OK, 0 rows affected (0.26 sec)# ls -lh user1.ibd -rw-r----- 1 mysql mysql 96K Nov 6 12:48 user.ibd
设置参数innodb_file_per_table=1时,创建表时会自动创建一个segment,同时分配一个extent,包含32个data page的来存储数据,这样创建的空表默认大小就是96KB,extent使用完之后会申请64个连接页,这样对于一些小表,或者undo segment,可以在开始时申请较少的空间,节省磁盘容量的开销。
# python2 py_innodb_page_info.py -v /data2/mysql/test/user.ibd page offset 00000000, page type <File Space Header> page offset 00000001, page type <Insert Buffer Bitmap> page offset 00000002, page type <File Segment inode> page offset 00000003, page type <B-tree Node>, page level <0000> page offset 00000000, page type <Freshly Allocated Page> page offset 00000000, page type <Freshly Allocated Page> Total number of page: 6: #总共分配的页数 Freshly Allocated Page: 2 #可用的数据页 Insert Buffer Bitmap: 1 #插入缓冲页 File Space Header: 1 #文件空间头 B-tree Node: 1 #数据页 File Segment inode: 1 #文件端inonde,如果是在ibdata1.ibd上会有多个inode。
插入数据后的空间变化
mysql> DELIMITER $$
mysql> CREATE PROCEDURE insert_user_data(num INTEGER)
-> BEGIN
-> DECLARE v_i int unsigned DEFAULT 0;
-> set autocommit= 0;
-> WHILE v_i < num DO
-> insert into user(`name`, age, gender, phone) values (CONCAT('lyn',v_i), mod(v_i,120), 'M', CONCAT('152',ROUND(RAND(1)*100000000)));
-> SET v_i = v_i+1;
-> END WHILE;
-> commit;
-> END $$
Query OK, 0 rows affected (0.01 sec)
mysql> DELIMITER ;
#插入10w数据
mysql> call insert_user_data(100000);
Query OK, 0 rows affected (6.69 sec)# ls -lh user.ibd -rw-r----- 1 mysql mysql 14M Nov 6 10:58 /data2/mysql/test/user.ibd # python2 py_innodb_page_info.py -v /data2/mysql/test/user.ibd page offset 00000000, page type <File Space Header> page offset 00000001, page type <Insert Buffer Bitmap> page offset 00000002, page type <File Segment inode> page offset 00000003, page type <B-tree Node>, page level <0001> #增加了一个非叶子节点,树的高度从1变为2. ........................................................ page offset 00000000, page type <Freshly Allocated Page> Total number of page: 896: Freshly Allocated Page: 493 Insert Buffer Bitmap: 1 File Space Header: 1 B-tree Node: 400 File Segment inode: 1
delete数据后的空间变化
mysql> select min(id),max(id),count(*) from user; +---------+---------+----------+ | min(id) | max(id) | count(*) | +---------+---------+----------+ | 1 | 100000 | 100000 | +---------+---------+----------+ 1 row in set (0.05 sec) #删除50000条数据,理论上空间应该从14MB变长7MB左右。 mysql> delete from user limit 50000; Query OK, 50000 rows affected (0.25 sec) #数据文件大小依然是14MB,没有缩小。 # ls -lh /data2/mysql/test/user1.ibd -rw-r----- 1 mysql mysql 14M Nov 6 13:22 /data2/mysql/test/user.ibd #数据页没有被回收。 # python2 py_innodb_page_info.py -v /data2/mysql/test/user.ibd page offset 00000000, page type <File Space Header> page offset 00000001, page type <Insert Buffer Bitmap> page offset 00000002, page type <File Segment inode> page offset 00000003, page type <B-tree Node>, page level <0001> ........................................................ page offset 00000000, page type <Freshly Allocated Page> Total number of page: 896: Freshly Allocated Page: 493 Insert Buffer Bitmap: 1 File Space Header: 1 B-tree Node: 400 File Segment inode: 1 #在MySQL内部是标记删除,
mysql> use information_schema; Database changed mysql> SELECT A.SPACE AS TBL_SPACEID, A.TABLE_ID, A.NAME AS TABLE_NAME, FILE_FORMAT, ROW_FORMAT, SPACE_TYPE, B.INDEX_ID , B.NAME AS INDEX_NAME, PAGE_NO, B.TYPE AS INDEX_TYPE FROM INNODB_SYS_TABLES A LEFT JOIN INNODB_SYS_INDEXES B ON A.TABLE_ID =B.TABLE_ID WHERE A.NAME = 'test/user1'; +-------------+----------+------------+-------------+------------+------------+----------+------------+---------+------------+ | TBL_SPACEID | TABLE_ID | TABLE_NAME | FILE_FORMAT | ROW_FORMAT | SPACE_TYPE | INDEX_ID | INDEX_NAME | PAGE_NO | INDEX_TYPE | +-------------+----------+------------+-------------+------------+------------+----------+------------+---------+------------+ | 1283 | 1207 | test/user | Barracuda | Dynamic | Single | 2236 | PRIMARY | 3 | 3 | +-------------+----------+------------+-------------+------------+------------+----------+------------+---------+------------+ 1 row in set (0.01 sec) PAGE_NO = 3 标识B-tree的root page是3号页,INDEX_TYPE = 3是聚集索引。 INDEX_TYPE取值如下: 0 = nonunique secondary index; 1 = automatically generated clustered index (GEN_CLUST_INDEX); 2 = unique nonclustered index; 3 = clustered index; 32 = full-text index; #收缩空间再后进行观察
MySQL内部不会真正删除空间,而且做标记删除,即将delflag:N修改为delflag:Y,commit之后会会被purge进入删除链表,如果下一次insert更大的记录,delete之后的空间不会被重用,如果插入的记录小于等于delete的记录空会被重用,这块内容可以通过知数堂的innblock工具进行分析。
Innodb中的碎片
碎片的产生
我们知道数据存储在文件系统上的,总是不能100%利用分配给它的物理空间,删除数据会在页面上留下一些”空洞”,或者随机写入(聚集索引非线性增加)会导致页分裂,页分裂导致页面的利用空间少于50%,另外对表进行增删改会引起对应的二级索引值的随机的增删改,也会导致索引结构中的数据页面上留下一些"空洞",虽然这些空洞有可能会被重复利用,但终究会导致部分物理空间未被使用,也就是碎片。
同时,即便是设置了填充因子为100%,Innodb也会主动留下page页面1/16的空间作为预留使用(An innodb_fill_factor setting of 100 leaves 1/16 of the space in clustered index pages free for future index growth)防止update带来的行溢出。
mysql> select table_schema,
-> table_name,ENGINE,
-> round(DATA_LENGTH/1024/1024+ INDEX_LENGTH/1024/1024) total_mb,TABLE_ROWS,
-> round(DATA_LENGTH/1024/1024) data_mb, round(INDEX_LENGTH/1024/1024) index_mb, round(DATA_FREE/1024/1024) free_mb, round(DATA_FREE/DATA_LENGTH*100,2) free_ratio
-> from information_schema.TABLES where TABLE_SCHEMA= 'test'
-> and TABLE_NAME= 'user';
+--------------+------------+--------+----------+------------+---------+----------+---------+------------+
| table_schema | table_name | ENGINE | total_mb | TABLE_ROWS | data_mb | index_mb | free_mb | free_ratio |
+--------------+------------+--------+----------+------------+---------+----------+---------+------------+
| test | user | InnoDB | 4 | 50000 | 4 | 0 | 6 | 149.42 |
+--------------+------------+--------+----------+------------+---------+----------+---------+------------+
1 row in set (0.00 sec)其中data_free是分配了未使用的字节数,并不能说明完全是碎片空间。
碎片的回收
对于InnoDB的表,可以通过以下命令来回收碎片,释放空间,这个是随机读IO操作,会比较耗时,也会阻塞表上正常的DML运行,同时需要占用额外更多的磁盘空间,对于RDS来说,可能会导致磁盘空间瞬间爆满,实例瞬间被锁定,应用无法做DML操作,所以禁止在线上环境去执行。
#执行InnoDB的碎片回收 mysql> alter table user engine=InnoDB; Query OK, 0 rows affected (9.00 sec) Records: 0 Duplicates: 0 Warnings: 0 ##执行完之后,数据文件大小从14MB降低到10M。 # ls -lh /data2/mysql/test/user1.ibd -rw-r----- 1 mysql mysql 10M Nov 6 16:18 /data2/mysql/test/user.ibd
mysql> select table_schema,
->table_name,ENGINE,
->round(DATA_LENGTH/1024/1024+ INDEX_LENGTH/1024/1024) total_mb,TABLE_ROWS,
->round(DATA_LENGTH/1024/1024) data_mb,
->round(INDEX_LENGTH/1024/1024) index_mb,
->round(DATA_FREE/1024/1024) free_mb,
->round(DATA_FREE/DATA_LENGTH*100,2) free_ratio from information_schema.TABLES where TABLE_SCHEMA= 'test' and TABLE_NAME= 'user';
+--------------+------------+--------+----------+------------+---------+----------+---------+------------+
| table_schema | table_name | ENGINE | total_mb | TABLE_ROWS | data_mb | index_mb | free_mb | free_ratio |
+--------------+------------+--------+----------+------------+---------+----------+---------+------------+
| test | user | InnoDB | 5 | 50000 | 5 | 0 | 2 | 44.29 |
+--------------+------------+--------+----------+------------+---------+----------+---------+------------+
1 row in set (0.00 sec)delete对SQL的影响
未删除前的SQL执行情况
#插入100W数据 mysql> call insert_user_data(1000000); Query OK, 0 rows affected (35.99 sec) #添加相关索引 mysql> alter table user add index idx_name(name), add index idx_phone(phone); Query OK, 0 rows affected (6.00 sec) Records: 0 Duplicates: 0 Warnings: 0 #表上索引统计信息 mysql> show index from user; +-------+------------+-----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | +-------+------------+-----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ | user | 0 | PRIMARY | 1 | id | A | 996757 | NULL | NULL | | BTREE | | | | user | 1 | idx_name | 1 | name | A | 996757 | NULL | NULL | | BTREE | | | | user | 1 | idx_phone | 1 | phone | A | 2 | NULL | NULL | | BTREE | | | +-------+------------+-----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+ 3 rows in set (0.00 sec) #重置状态变量计数 mysql> flush status; Query OK, 0 rows affected (0.00 sec) #执行SQL语句 mysql> select id, age ,phone from user where name like 'lyn12%'; +--------+-----+-------------+ | id | age | phone | +--------+-----+-------------+ | 124 | 3 | 15240540354 | | 1231 | 30 | 15240540354 | | 12301 | 60 | 15240540354 | ............................. | 129998 | 37 | 15240540354 | | 129999 | 38 | 15240540354 | | 130000 | 39 | 15240540354 | +--------+-----+-------------+ 11111 rows in set (0.03 sec) mysql> explain select id, age ,phone from user where name like 'lyn12%'; +----+-------------+-------+-------+---------------+----------+---------+------+-------+-----------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+-------+---------------+----------+---------+------+-------+-----------------------+ | 1 | SIMPLE | user | range | idx_name | idx_name | 82 | NULL | 22226 | Using index condition | +----+-------------+-------+-------+---------------+----------+---------+------+-------+-----------------------+ 1 row in set (0.00 sec) #查看相关状态呢变量 mysql> select * from information_schema.session_status where variable_name in('Last_query_cost','Handler_read_next','Innodb_pages_read','Innodb_data_reads','Innodb_pages_read'); +-------------------+----------------+ | VARIABLE_NAME | VARIABLE_VALUE | +-------------------+----------------+ | HANDLER_READ_NEXT | 11111 | #请求读的行数 | INNODB_DATA_READS | 7868409 | #数据物理读的总数 | INNODB_PAGES_READ | 7855239 | #逻辑读的总数 | LAST_QUERY_COST | 10.499000 | #SQL语句的成本COST,主要包括IO_COST和CPU_COST。 +-------------------+----------------+ 4 rows in set (0.00 sec)
删除后的SQL执行情况
#删除50w数据 mysql> delete from user limit 500000; Query OK, 500000 rows affected (3.70 sec) #分析表统计信息 mysql> analyze table user; +-----------+---------+----------+----------+ | Table | Op | Msg_type | Msg_text | +-----------+---------+----------+----------+ | test.user | analyze | status | OK | +-----------+---------+----------+----------+ 1 row in set (0.01 sec) #重置状态变量计数 mysql> flush status; Query OK, 0 rows affected (0.01 sec) mysql> select id, age ,phone from user where name like 'lyn12%'; Empty set (0.05 sec) mysql> explain select id, age ,phone from user where name like 'lyn12%'; +----+-------------+-------+-------+---------------+----------+---------+------+-------+-----------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+-------+---------------+----------+---------+------+-------+-----------------------+ | 1 | SIMPLE | user | range | idx_name | idx_name | 82 | NULL | 22226 | Using index condition | +----+-------------+-------+-------+---------------+----------+---------+------+-------+-----------------------+ 1 row in set (0.00 sec) mysql> select * from information_schema.session_status where variable_name in('Last_query_cost','Handler_read_next','Innodb_pages_read','Innodb_data_reads','Innodb_pages_read'); +-------------------+----------------+ | VARIABLE_NAME | VARIABLE_VALUE | +-------------------+----------------+ | HANDLER_READ_NEXT | 0 | | INNODB_DATA_READS | 7868409 | | INNODB_PAGES_READ | 7855239 | | LAST_QUERY_COST | 10.499000 | +-------------------+----------------+ 4 rows in set (0.00 sec)
结果统计分析
| 操作 | COST | 物理读次数 | 逻辑读次数 | 扫描行数 | 返回行数 | 执行时间 |
|---|---|---|---|---|---|---|
| 初始化插入100W | 10.499000 | 7868409 | 7855239 | 22226 | 11111 | 30ms |
| 100W随机删除50W | 10.499000 | 7868409 | 7855239 | 22226 | 0 | 50ms |
这也说明对普通的大表,想要通过delete数据来对表进行瘦身是不现实的,所以在任何时候不要用delete去删除数据,应该使用优雅的标记删除。
delete优化建议
控制业务账号权限
对于一个大的系统来说,需要根据业务特点去拆分子系统,每个子系统可以看做是一个service,例如美团APP,上面有很多服务,核心的服务有用户服务user-service,搜索服务search-service,商品product-service,位置服务location-service,价格服务price-service等。每个服务对应一个数据库,为该数据库创建单独账号,同时只授予DML权限且没有delete权限,同时禁止跨库访问。
#创建用户数据库并授权 create database mt_user charset utf8mb4; grant USAGE, SELECT, INSERT, UPDATE ON mt_user.* to 'w_user'@'%' identified by 't$W*g@gaHTGi123456'; flush privileges;
delete改为标记删除
在MySQL数据库建模规范中有4个公共字段,基本上每个表必须有的,同时在create_time列要创建索引,有两方面的好处:
一些查询业务场景都会有一个默认的时间段,比如7天或者一个月,都是通过create_time去过滤,走索引扫描更快。
一些核心的业务表需要以T +1的方式抽取数据仓库中,比如每天晚上00:30抽取前一天的数据,都是通过create_time过滤的。
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键id', `is_deleted` tinyint(4) NOT NULL DEFAULT '0' COMMENT '是否逻辑删除:0:未删除,1:已删除', `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间' #有了删除标记,业务接口的delete操作就可以转换为update update user set is_deleted = 1 where user_id = 1213; #查询的时候需要带上is_deleted过滤 select id, age ,phone from user where is_deleted = 0 and name like 'lyn12%';
数据归档方式
通用数据归档方法
#1. 创建归档表,一般在原表名后面添加_bak。 CREATE TABLE `ota_order_bak` ( `id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '主键', `order_id` varchar(255) DEFAULT NULL COMMENT '订单id', `ota_id` varchar(255) DEFAULT NULL COMMENT 'ota', `check_in_date` varchar(255) DEFAULT NULL COMMENT '入住日期', `check_out_date` varchar(255) DEFAULT NULL COMMENT '离店日期', `hotel_id` varchar(255) DEFAULT NULL COMMENT '酒店ID', `guest_name` varchar(255) DEFAULT NULL COMMENT '顾客', `purcharse_time` timestamp NULL DEFAULT NULL COMMENT '购买时间', `create_time` datetime DEFAULT NULL, `update_time` datetime DEFAULT NULL, `create_user` varchar(255) DEFAULT NULL, `update_user` varchar(255) DEFAULT NULL, `status` int(4) DEFAULT '1' COMMENT '状态 : 1 正常 , 0 删除', `hotel_name` varchar(255) DEFAULT NULL, `price` decimal(10,0) DEFAULT NULL, `remark` longtext, PRIMARY KEY (`id`), KEY `IDX_order_id` (`order_id`) USING BTREE, KEY `hotel_name` (`hotel_name`) USING BTREE, KEY `ota_id` (`ota_id`) USING BTREE, KEY `IDX_purcharse_time` (`purcharse_time`) USING BTREE, KEY `IDX_create_time` (`create_time`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8 PARTITION BY RANGE (to_days(create_time)) ( PARTITION p201808 VALUES LESS THAN (to_days('2018-09-01')), PARTITION p201809 VALUES LESS THAN (to_days('2018-10-01')), PARTITION p201810 VALUES LESS THAN (to_days('2018-11-01')), PARTITION p201811 VALUES LESS THAN (to_days('2018-12-01')), PARTITION p201812 VALUES LESS THAN (to_days('2019-01-01')), PARTITION p201901 VALUES LESS THAN (to_days('2019-02-01')), PARTITION p201902 VALUES LESS THAN (to_days('2019-03-01')), PARTITION p201903 VALUES LESS THAN (to_days('2019-04-01')), PARTITION p201904 VALUES LESS THAN (to_days('2019-05-01')), PARTITION p201905 VALUES LESS THAN (to_days('2019-06-01')), PARTITION p201906 VALUES LESS THAN (to_days('2019-07-01')), PARTITION p201907 VALUES LESS THAN (to_days('2019-08-01')), PARTITION p201908 VALUES LESS THAN (to_days('2019-09-01')), PARTITION p201909 VALUES LESS THAN (to_days('2019-10-01')), PARTITION p201910 VALUES LESS THAN (to_days('2019-11-01')), PARTITION p201911 VALUES LESS THAN (to_days('2019-12-01')), PARTITION p201912 VALUES LESS THAN (to_days('2020-01-01'))); #2. 插入原表中无效的数据(需要跟开发同学确认数据保留范围) create table tbl_p201808 as select * from ota_order where create_time between '2018-08-01 00:00:00' and '2018-08-31 23:59:59'; #3. 跟归档表分区做分区交换 alter table ota_order_bak exchange partition p201808 with table tbl_p201808; #4. 删除原表中已经规范的数据 delete from ota_order where create_time between '2018-08-01 00:00:00' and '2018-08-31 23:59:59' limit 3000;
优化后的归档方式
#1. 创建中间表 CREATE TABLE `ota_order_2020` (........) ENGINE=InnoDB DEFAULT CHARSET=utf8 PARTITION BY RANGE (to_days(create_time)) ( PARTITION p201808 VALUES LESS THAN (to_days('2018-09-01')), PARTITION p201809 VALUES LESS THAN (to_days('2018-10-01')), PARTITION p201810 VALUES LESS THAN (to_days('2018-11-01')), PARTITION p201811 VALUES LESS THAN (to_days('2018-12-01')), PARTITION p201812 VALUES LESS THAN (to_days('2019-01-01')), PARTITION p201901 VALUES LESS THAN (to_days('2019-02-01')), PARTITION p201902 VALUES LESS THAN (to_days('2019-03-01')), PARTITION p201903 VALUES LESS THAN (to_days('2019-04-01')), PARTITION p201904 VALUES LESS THAN (to_days('2019-05-01')), PARTITION p201905 VALUES LESS THAN (to_days('2019-06-01')), PARTITION p201906 VALUES LESS THAN (to_days('2019-07-01')), PARTITION p201907 VALUES LESS THAN (to_days('2019-08-01')), PARTITION p201908 VALUES LESS THAN (to_days('2019-09-01')), PARTITION p201909 VALUES LESS THAN (to_days('2019-10-01')), PARTITION p201910 VALUES LESS THAN (to_days('2019-11-01')), PARTITION p201911 VALUES LESS THAN (to_days('2019-12-01')), PARTITION p201912 VALUES LESS THAN (to_days('2020-01-01'))); #2. 插入原表中有效的数据,如果数据量在100W左右可以在业务低峰期直接插入,如果比较大,建议采用dataX来做,可以控制频率和大小,之前我这边用Go封装了dataX可以实现自动生成json文件,自定义大小去执行。 insert into ota_order_2020 select * from ota_order where create_time between '2020-08-01 00:00:00' and '2020-08-31 23:59:59'; #3. 表重命名 alter table ota_order rename to ota_order_bak; alter table ota_order_2020 rename to ota_order; #4. 插入差异数据 insert into ota_order select * from ota_order_bak a where not exists (select 1 from ota_order b where a.id = b.id); #5. ota_order_bak改造成分区表,如果表比较大不建议直接改造,可以先创建好分区表,通过dataX把导入进去即可。 #6. 后续的归档方法 #创建中间普遍表 create table ota_order_mid like ota_order; #交换原表无效数据分区到普通表 alter table ota_order exchange partition p201808 with table ota_order_mid; ##交换普通表数据到归档表的相应分区 alter table ota_order_bak exchange partition p201808 with table ota_order_mid;
这样原表和归档表都是按月的分区表,只需要创建一个中间普通表,在业务低峰期做两次分区交换,既可以删除无效数据,又能回收空,而且没有空间碎片,不会影响表上的索引及SQL的执行计划。
总结
通过从InnoDB存储空间分布,delete对性能的影响可以看到,delete物理删除既不能释放磁盘空间,而且会产生大量的碎片,导致索引频繁分裂,影响SQL执行计划的稳定性;
同时在碎片回收时,会耗用大量的CPU,磁盘空间,影响表上正常的DML操作。
在业务代码层面,应该做逻辑标记删除,避免物理删除;为了实现数据归档需求,可以用采用MySQL分区表特性来实现,都是DDL操作,没有碎片产生。
另外一个比较好的方案采用Clickhouse,对有生命周期的数据表可以使用Clickhouse存储,利用其TTL特性实现无效数据自动清理。
相关推荐:《mysql教程》
以上是mysql删除数据时为什么不使用delete的详细内容。更多信息请关注PHP中文网其他相关文章!

 图文详解mysql架构原理May 17, 2022 pm 05:54 PM
图文详解mysql架构原理May 17, 2022 pm 05:54 PM本篇文章给大家带来了关于mysql的相关知识,其中主要介绍了关于架构原理的相关内容,MySQL Server架构自顶向下大致可以分网络连接层、服务层、存储引擎层和系统文件层,下面一起来看一下,希望对大家有帮助。
 mysql的msi与zip版本有什么区别May 16, 2022 pm 04:33 PM
mysql的msi与zip版本有什么区别May 16, 2022 pm 04:33 PMmysql的msi与zip版本的区别:1、zip包含的安装程序是一种主动安装,而msi包含的是被installer所用的安装文件以提交请求的方式安装;2、zip是一种数据压缩和文档存储的文件格式,msi是微软格式的安装包。
 mysql怎么去掉第一个字符May 19, 2022 am 10:21 AM
mysql怎么去掉第一个字符May 19, 2022 am 10:21 AM方法:1、利用right函数,语法为“update 表名 set 指定字段 = right(指定字段, length(指定字段)-1)...”;2、利用substring函数,语法为“select substring(指定字段,2)..”。
 mysql怎么替换换行符Apr 18, 2022 pm 03:14 PM
mysql怎么替换换行符Apr 18, 2022 pm 03:14 PM在mysql中,可以利用char()和REPLACE()函数来替换换行符;REPLACE()函数可以用新字符串替换列中的换行符,而换行符可使用“char(13)”来表示,语法为“replace(字段名,char(13),'新字符串') ”。
 mysql怎么将varchar转换为int类型May 12, 2022 pm 04:51 PM
mysql怎么将varchar转换为int类型May 12, 2022 pm 04:51 PM转换方法:1、利用cast函数,语法“select * from 表名 order by cast(字段名 as SIGNED)”;2、利用“select * from 表名 order by CONVERT(字段名,SIGNED)”语句。
 MySQL复制技术之异步复制和半同步复制Apr 25, 2022 pm 07:21 PM
MySQL复制技术之异步复制和半同步复制Apr 25, 2022 pm 07:21 PM本篇文章给大家带来了关于mysql的相关知识,其中主要介绍了关于MySQL复制技术的相关问题,包括了异步复制、半同步复制等等内容,下面一起来看一下,希望对大家有帮助。
 mysql怎么判断是否是数字类型May 16, 2022 am 10:09 AM
mysql怎么判断是否是数字类型May 16, 2022 am 10:09 AM在mysql中,可以利用REGEXP运算符判断数据是否是数字类型,语法为“String REGEXP '[^0-9.]'”;该运算符是正则表达式的缩写,若数据字符中含有数字时,返回的结果是true,反之返回的结果是false。
 mysql怎么删除unique keyMay 12, 2022 pm 03:01 PM
mysql怎么删除unique keyMay 12, 2022 pm 03:01 PM在mysql中,可利用“ALTER TABLE 表名 DROP INDEX unique key名”语句来删除unique key;ALTER TABLE语句用于对数据进行添加、删除或修改操作,DROP INDEX语句用于表示删除约束操作。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

MinGW - 适用于 Windows 的极简 GNU
这个项目正在迁移到osdn.net/projects/mingw的过程中,你可以继续在那里关注我们。MinGW:GNU编译器集合(GCC)的本地Windows移植版本,可自由分发的导入库和用于构建本地Windows应用程序的头文件;包括对MSVC运行时的扩展,以支持C99功能。MinGW的所有软件都可以在64位Windows平台上运行。

Dreamweaver CS6
视觉化网页开发工具

WebStorm Mac版
好用的JavaScript开发工具

