



一、优化的思路和原则有哪些
1、 优化更需要优化的查询
2、 定位优化对象的性能瓶颈
3、 明确优化的目标
4、 从Explain入手
5、 多使用 profile
6、 永远用小结果集驱动大结果集
7、 尽可能在索引中完成排序
8、 只取出自己需要的字段(Columns)
9、 仅仅使用最有效的过滤条件
10、尽可能避免复杂的join
相关免费学习推荐:mysql视频教程
1、优化更需要优化的查询
高并发的低消耗(相对)的查询 对整个系统影响远大于低并发高消耗的查询。
2、定位优化对象的性能瓶颈
在拿到一条需要优化的查询时,我们首先要判断出这个查询的瓶颈到底是IO还是CPU。到底是数据库访问消耗多还是数据的运算(如分组排序)消耗多。
3、明确优化的目标
了解数据库目前整体状态,就能知道数据库所能承受的最大压力,也就是我们知道最悲观状况;
要把握该查询相关的数据库对象信息,我们就能知道最理想和最糟糕状态下需要消耗多少资源;
要知道该查询在应用系统中的地位,我们可以分析出改查询可以占用系统资源的比例,也能够知道该查询的效率对客户的体验影响有多大。
4、从Explain入手
Explain能够告诉你这个查询在数据库中是一个什么样的执行计划来实现的。首先我们需要有个目标,通过不断调整尝试,再借助Explain来验证结果是否满足自己的需求,直到得到预期的结果。
5、永远用小结果集驱动大结果集
很多人喜欢在SQL优化的时候说用“小表驱动大表”,这个说法是不严谨的。因为大表经过where条件过滤后返回的结果集并不一定就比小表所返回的结果集大,这个时候还用大表驱动小表,就会得到相反的性能效果。
这样的结果也非常容易理解,在 MySQL 中的 Join,只有 Nested Loop 一种 Join 方式,也就是MySQL 的 Join 都是通过嵌套循环来实现的。驱动结果集越大,所需要循环的此时就越多,那么被驱动表的访问次数自然也就越多,而每次访问被驱动表,即使需要的逻辑 IO 很少,循环次数多了,总量自然也不可能很小,而且每次循环都不能避免的需要消耗CPU,所以 CPU 运算量也会跟着增加。所以,如果我们仅仅以表的大小来作为驱动表的判断依据,假若小表过滤后所剩下的结果集比大表多很多,结果就是需要的嵌套循环中带来更多的循环次数,反之,所需要的循环次数就会更少,总体 IO 量和 CPU 运算量也会少。而且,就算是非 Nested Loop 的 Join 算法,如 Oracle 中的 Hash Join,同样是小结果集驱动大的结果集是最优的选择。
所以,在优化 Join Query 的时候,最基本的原则就是“小结果集驱动大结果集”,通过这个原则来减少嵌套循环中的循环次数,达到减少 IO 总量以及 CPU 运算的次数。尽可能在索引中完成排序
6、只取出自己需要的字段(Columns)
对于任何查询,返回的数据都是需要通过网络数据包传输给客户端,如果取出的Column越多,需要传输的数据量自然会越大,不论从网络带宽还是网络传输缓冲区来看,都是一种浪费。
7、仅仅使用最有效的过滤条件
举个例子一个用户表user有id和nick_name等字段,索引是id和nike_name两个索引,下面是两个查询语句
#1 select * from user where id = 1 and nick_name = 'zs'; #2 selet * from user where id = 1
两个查询得到结果是一样的,但是第一个语句用到的索引占用空间是比第二个语句大很多的。占用空间大也代表着要读取的数据量也更多。,也就是说2的查询语句才是最优查询。
8、避免复杂的join查询
我们的查询语句所涉及到的表越多,所需要锁定的资源就越多。也就是说,越复杂的 Join 语句,所需要锁定的资源也就越多,所阻塞的其他线程也就越多。相反,如果我们将比较复杂的查询语句分拆成多个较为简单的查询语句分步执行,每次锁定的资源也就会少很多,所阻塞的其他线程也要少一些。
可能很多人会有疑问,将复杂 Join 语句分拆成多个简单的查询语句之后,那不是我们的网络交互就会更多了吗?网络延时方面的总体消耗也就更大了啊,完成整个查询的时间不是反而更长了吗?是的,这种情况是可能存在,但也并不是肯定就会如此。我们可以再分析一下,一个复杂的查询语句在执行的时候,所需要锁定的资源比较多,可能被别人阻塞的概率也就更大,如果是一个简单的查询,由于需要锁定的资源较少,被阻塞的概率也会小很多。所以 较为复杂的连接查询也有可能在执行之前被阻塞而浪费更多的时间。而且我们的数据库所服务的并不是单单这一个查询请求,还有很多很多其他的请求,在高并发的系统中,牺牲单个查询的短暂响应时间而提高整体处理能力也是非常值得的。优化本身就是一门平衡与取舍的艺术,只有懂得取舍,平衡整体,才能让系统更优。
二、利用 Explain和Profiling
1、Explain使用
各种信息展示
| 字段 | 说明 |
|---|---|
| ID | 执行计划中查询的序列号 |
| Select_type | 查询类型: DEPENDENT SUBQUERY : 子查询中内层的第一个SELECT,依赖于外部查询结果集; DEPENDENT UNION:子查询中的UNION中从第二个SELECT 开始的后面所有SELECT,同样依赖于外部查询结果集; PRIMARY: 子查询中的最外层查询,不是主键查询; SUBQUERY:子查询内层查询的第一个SELECT,结果不依赖于外部结果集; UNCACHEABLE SUBQUERY:结果集无法缓存的子查询; UNION:UNION语句中第二个SELECT开始的后面所有SELECT,第一个SELECT为PRIMARY UNION RESULT:UNION中的合并结果 |
| Table | 所访问的数据库中表名称 |
| TYPE | 访问方式: ALL: 全表扫描 const: 常量,最多只有一条记录匹配,由于是常量,所以实际上只需要读一次 eq_ref: 最多只有一条匹配结果,一般是主键或者唯一索引来访问的 index: 全索引扫描 range: 索引范围扫描 ref: jion语句中被驱动表索引的引用查询 system: 系统表,表中只有一行数据 |
| Possible_keys | 可能用到的索引 |
| Key | 使用的索引 |
| Key_len | 索引长度 |
| Rows | 估算出来的结果集记录条数 |
| Extra | 额外信息 |
2、Profiling使用
该工具可以获取一条Query在整个执行过程中多种资源消耗情况,如CPU,IO,IPC,SWAP等,以及发生PAGE FAULTS, CONTEXT SWITCHE等等,同时还能得到该Query执行过程中MySQL所调用的各个函数在源文件中的位置。
1、开启profiling参数 1-开启,0-关闭
#开启profiling参数 1-开启,0-关闭set profiling=1;SHOW VARIABLES LIKE '%profiling%';
2、然后执行一条Query
3、获取系统保存的profiling信息
show PROFILES;
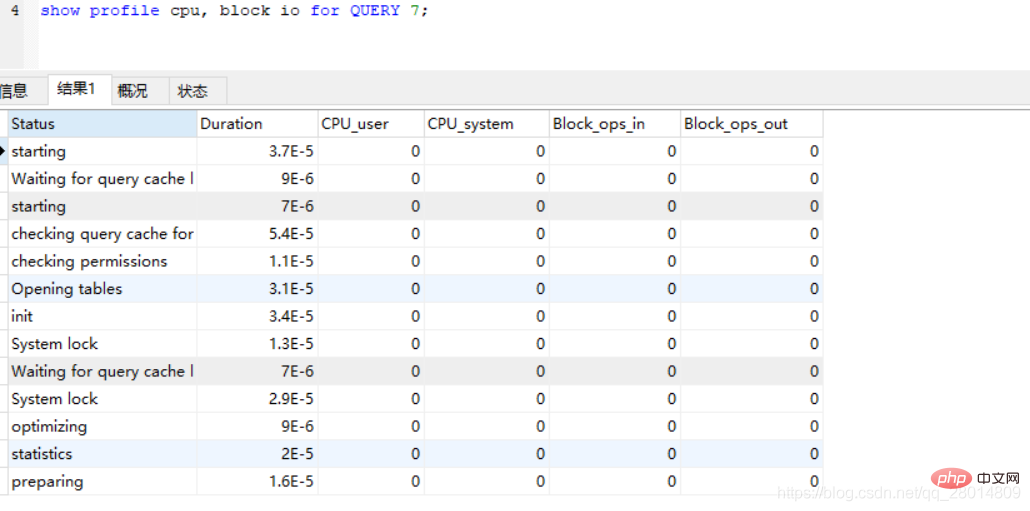
 4、通过QUERY_ID获取profile的详细信息(下面以获取CPU和IO为例)
4、通过QUERY_ID获取profile的详细信息(下面以获取CPU和IO为例)
show profile cpu, block io for QUERY 7;
三、合理利用索引
1、什么是索引
简单来说,在关系型数据库中,索引是一种单独的,物理的对数据库表中一列或者多列的值进行排序的一种存储结构。就像书的目录,可以根据目录中的页码快速找到需要的内容。
在MySQL中主要有四种类型索引,分别是:B-Tree索引,Hash索引,FullText索引,R-Tree索引,下面主要说一下我们常用的B-Tree索引,其他索引可以自行查找资料。
2、索引的数据结构
一般来说,MySQL中的B-Tree索引的物理文件大多数都是以平衡树的结构来存储的,也就是所有实际需要存储的数据都存储于树的叶子节点,二到任何一个叶子节点的最短路径的长度都是完全相同的。MySQL中的存储引擎也会稍作改造,比如Innodb存储引擎的B-Tree索引实际上使用的存储结构是B+Tree,在每个叶子节点存储了索引键相关信息之外,还存储了指向相邻的叶子节点的指针信息,这是为了加快检索多个相邻的叶子节点的效率。
在Innodb中,存在两种形式的索引,一种是聚簇形式的主键索引,另外一种形式是和其他存储引擎(如MyISAM)存放形式基本相同的普通B-Tree索引,这种索引在Innodb存储引擎中被称作二级索引。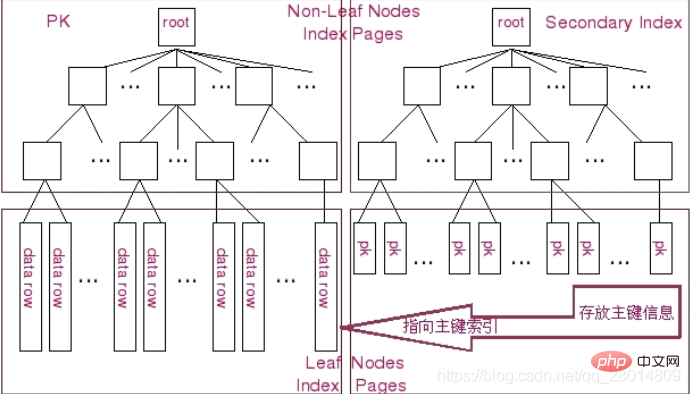
图示中左边为 Clustered 形式存放的 Primary Key,右侧则为普通的 B-Tree 索引。两种索引在根节点和 分支节点方面都还是完全一样的。而 叶子节点就出现差异了。在主键索引中,叶子结点存放的是表的实际数据,不仅仅包括主键字段的数据,还包括其他字段的数据,整个数据以主键值有序的排列。而二级索引则和其他普通的 B-Tree 索引没有太大的差异,只是在叶子结点除了存放索引键的相关信息外,还存放了 Innodb 的主键值。
所以,在 Innodb 中如果通过主键来访问数据效率是非常高的,而如果是通过二级索引来访问数据的话,Innodb 首先通过二级索引的相关信息,通过相应的索引键检索到叶子节点之后,需要再通过叶子节点中存放的主键值再通过主键索引来获取相应的数据行。
MyISAM 存储引擎的主键索引和非主键索引差别很小,只不过是主键索引的索引键是一个唯一且非空的键而已。而且 MyISAM 存储引擎的索引和 Innodb 的二级索引的存储结构也基本相同,主要的区别只是 MyISAM 存储引擎在叶子节点上面除了存放索引键信息之外,再存放能直接定位MyISAM 数据文件中相应的数据行的信息(如 Row Number),但并不会存放主键的键值信息。
3、索引的利弊
优点: 提高数据的检索速度,降低数据库的IO成本;
缺点:查询需要更新索引信息带来额外的资源消耗,索引还会占用额外的存储空间
4、如何判断是否需要建立索引
上面说了索引的利弊,我们知道索引并不是越多越好,索引也会带来副作用。那么我们该怎么判断是否需要建立索引呢?
1、 较频繁的作为查询条件的字段应该创建索引;
2、更新频繁的字段不适合建立索引;
3、唯一性太差的不适合创建索引,如状态字段;
4、不出现在where中的字段不适合创建索引;
5、单索引还是组合索引?
在一般的应用场景,只要不是其中某个过滤字段在大多数场景下都能过滤90%以上的数据,而且其他的过滤字段会频繁更新,我一般更倾向于创建组合索引,尤其是在并发量较高的场景下更是如此。因为并发量搞的时候,即使我们为每个查询节省很少IO消耗,但因为执行量非常大,所节省的资源总量还是很大的。
但是我们创建组合索引并不是说查询条件中的所有字段都要放在一个索引中,我们应该让一个索引被多个查询所利用,尽量减少索引的数量,以此来减少更新的成本和存储成本。
MySQL为我们提供了一个减少优化索引自身的功能,那就是“前缀索引”。也就是我们可以仅仅使用某个字段的前面部分内容作为索引键来索引该字段,减少索引所占用的空间和提高索引的访问效率。当然前缀索引只适合前缀比较随机重复很少的字段。
6、索引的选择
1、对于单键索引 ,尽量针对当前查询过滤最好的索引;
2、在选择组合索引的时候,当前查询中过滤性最好的字段在索引字段顺序中排列越靠前越好;
3、在选择组合索引的时候,尽量选择可以能够包含当前查询的where字句中更多字段的索引;
4、尽可能通过分析统计信息和调整查询的写法来达到选择合适的的索引来减少通过人为Hint控制索引的选择,以为这样后期维护成本会很高。
7、MySQL索引的限制
1、MyISAM存储引擎索引键长总和不能超过1000字节;
2、BLOB和TEXT类型字段只能创建前缀索引;
3、MySQL不支持函数索引;
4、使用 != 或者<>时候,MySQL索引无法使用;
5、过滤字段使用函数运算后,MySQL索引无法使用;
6、jion语句中近字段类型不一致的时候,MySQL索引无法使用;
7、使用like如果是前匹配(如:’%aaa’),MySQL索引无法使用;
8、使用非等值查询的时候,MySQL无法使用HASH索引;
9、字符类型是数字的时候要使用 =‘1’ 不可以直接使用 = 1;
10、不要使用or可以用in代替或者 union all;
8、Join原理以及优化
Join原理:在MySQL中,只有一种join算法,就是大名鼎鼎的嵌套循环,实际上就是通过驱动表的结果集作为循环基础数据,然后一条一条的通过该结果集中的数据作为过滤条件到下一个表中查询数据,然后合并结果。如果还有近参与,再通过前面的近结果集作为循环基础数据,再循环遍历,如此往复。
优化:
1、尽可能减少Join语句中的循环总次数(还记得前面说过的小结果集驱动大结果集吗);
2、优先优化内层循环;
3、保证Join语句中被驱动表上的Join条件字段已经被索引;
4、当无法保证被驱动表的Join条件字段被索引且内存资源充足条件下,不要吝啬Join buffer的设置(join buffer只会在 All,index,range才能够用的上);
9、ORDER BY优化
在MySQL中,ORDER BY的实现只有两种类型:
1、通过有序的索引直接取得有序的数据,这样不用进行任何排序操作即可得到客户端要求的有序数据;
2、通过MySQL排序算法将存储的引擎中返回的数据进行排序然后再将排序后的数据返回给客户端。
利用索引排序是最佳的方法,但是如果没有索引林勇的时候,MySQL主要两种算法实现:
1、取出满足过滤条件的用于排序条件的字段以及可以直接定位到行数据的行指针信息,在 Sort Buffer 中进行实际的排序操作,然后利用排好序之后的数据根据行指针信息返回表中取得客户端请求的其他字段的数据,再返回给客户端;
2、根据过滤条件一次取出排序字段以及客户端请求的所有其他字段的数据,并将不需要排序的字段存放在一块内存区域中,然后在 Sort Buffer 中将排序字段和行指针信息进行排序,最后再利用排序后的行指针与存放在内存区域中和其他字段一起的行指针信息进行匹配合并结果集,再按照顺序返回给客户端。
第二种算法相较于第一种算法,主要就是减少了数据的二次访问。在排序好后,不需要再次回到表中取数据,节省了IO操作。当然第二种算法会消耗更多的内存,一种典型的以空间换取时间的优化方式。
对于多表Join排序是先通过一个临时表将之前 Join 的结果集存放入临时表之后再将临时表的数据取到 Sort Buffer 中进行操作。
对于非索引排序的时候,尽量选择第二种算法来进行排序,手段有:
1、加大max_length_for_sort_data参数设置:
MySQL决定使用哪个算法是通过参数max_length_for_sort_data来决定的,当我们返回字段的最大长度小于这个参数时候,MySQL就会选择第二中算法,相反则第一种算法。所以在有充足内存情况下,加大这个参数值可以让MySQL选择第二种算法;
2、减少不必要的返回字段
上面一样的道理,字段少了,就会尽量小于max_length_for_sort_data参数;
3、增大sort_buffer_size参数设置:
增大 sort_buffer_size 并不是为了让 MySQL 可以选择改进版的排序算法,而是为了让 MySQL可以尽量减少在排序过程中对需要排序的数据进行分段,因为这样会造成 MySQL 不得不使用临时表来进行交换排序。
四、最后
调优其实是件很难的事情,调优也不限于上面的查询调优。诸如表的设计优化,数据库参数的调优,应用程序调优(减少循环操作数据库,批量新增;数据库连接池;缓存;)等等。当然还有很多调优技巧只有在实际实践中才能真正体会。只有自己以理论为基础,事实为依据,不断尝试去提升自己,才能成为一个真正的调优高手。
相关免费学习推荐:mysql数据库(视频)
以上是MySQL查询优化详解的详细内容。更多信息请关注PHP中文网其他相关文章!

 MySQL与Sqlite有何不同?Apr 24, 2025 am 12:12 AM
MySQL与Sqlite有何不同?Apr 24, 2025 am 12:12 AMMySQL和SQLite的主要区别在于设计理念和使用场景:1.MySQL适用于大型应用和企业级解决方案,支持高性能和高并发;2.SQLite适合移动应用和桌面软件,轻量级且易于嵌入。
 MySQL中的索引是什么?它们如何提高性能?Apr 24, 2025 am 12:09 AM
MySQL中的索引是什么?它们如何提高性能?Apr 24, 2025 am 12:09 AMMySQL中的索引是数据库表中一列或多列的有序结构,用于加速数据检索。1)索引通过减少扫描数据量提升查询速度。2)B-Tree索引利用平衡树结构,适合范围查询和排序。3)创建索引使用CREATEINDEX语句,如CREATEINDEXidx_customer_idONorders(customer_id)。4)复合索引可优化多列查询,如CREATEINDEXidx_customer_orderONorders(customer_id,order_date)。5)使用EXPLAIN分析查询计划,避
 说明如何使用MySQL中的交易来确保数据一致性。Apr 24, 2025 am 12:09 AM
说明如何使用MySQL中的交易来确保数据一致性。Apr 24, 2025 am 12:09 AM在MySQL中使用事务可以确保数据一致性。1)通过STARTTRANSACTION开始事务,执行SQL操作后用COMMIT提交或ROLLBACK回滚。2)使用SAVEPOINT可以设置保存点,允许部分回滚。3)性能优化建议包括缩短事务时间、避免大规模查询和合理使用隔离级别。
 在哪些情况下,您可以选择PostgreSQL而不是MySQL?Apr 24, 2025 am 12:07 AM
在哪些情况下,您可以选择PostgreSQL而不是MySQL?Apr 24, 2025 am 12:07 AM选择PostgreSQL而非MySQL的场景包括:1)需要复杂查询和高级SQL功能,2)要求严格的数据完整性和ACID遵从性,3)需要高级空间功能,4)处理大数据集时需要高性能。PostgreSQL在这些方面表现出色,适合需要复杂数据处理和高数据完整性的项目。
 如何保护MySQL数据库?Apr 24, 2025 am 12:04 AM
如何保护MySQL数据库?Apr 24, 2025 am 12:04 AMMySQL数据库的安全可以通过以下措施实现:1.用户权限管理:通过CREATEUSER和GRANT命令严格控制访问权限。2.加密传输:配置SSL/TLS确保数据传输安全。3.数据库备份和恢复:使用mysqldump或mysqlpump定期备份数据。4.高级安全策略:使用防火墙限制访问,并启用审计日志记录操作。5.性能优化与最佳实践:通过索引和查询优化以及定期维护兼顾安全和性能。
 您可以使用哪些工具来监视MySQL性能?Apr 23, 2025 am 12:21 AM
您可以使用哪些工具来监视MySQL性能?Apr 23, 2025 am 12:21 AM如何有效监控MySQL性能?使用mysqladmin、SHOWGLOBALSTATUS、PerconaMonitoringandManagement(PMM)和MySQLEnterpriseMonitor等工具。1.使用mysqladmin查看连接数。2.用SHOWGLOBALSTATUS查看查询数。3.PMM提供详细性能数据和图形化界面。4.MySQLEnterpriseMonitor提供丰富的监控功能和报警机制。
 MySQL与SQL Server有何不同?Apr 23, 2025 am 12:20 AM
MySQL与SQL Server有何不同?Apr 23, 2025 am 12:20 AMMySQL和SQLServer的区别在于:1)MySQL是开源的,适用于Web和嵌入式系统,2)SQLServer是微软的商业产品,适用于企业级应用。两者在存储引擎、性能优化和应用场景上有显着差异,选择时需考虑项目规模和未来扩展性。
 在哪些情况下,您可以选择SQL Server而不是MySQL?Apr 23, 2025 am 12:20 AM
在哪些情况下,您可以选择SQL Server而不是MySQL?Apr 23, 2025 am 12:20 AM在需要高可用性、高级安全性和良好集成性的企业级应用场景下,应选择SQLServer而不是MySQL。1)SQLServer提供企业级功能,如高可用性和高级安全性。2)它与微软生态系统如VisualStudio和PowerBI紧密集成。3)SQLServer在性能优化方面表现出色,支持内存优化表和列存储索引。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

Atom编辑器mac版下载
最流行的的开源编辑器

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

SublimeText3汉化版
中文版,非常好用

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

