


免费学习推荐:mysql视频教程
目录
- 模糊查询
- 表的约束
- 表之间的关联
- 多对一关联
- 多对多关联
- 一对一关联
模糊查询
可以根据大致提供的内容,找到我们想要的数据,它与=查询不同,拿char类型数据和varchar类型数据举例:
create table c1(x char(10));create table c2(x varchar(10));insert c1 values('io');insert c2 values('io');
模糊查询使用到的是like
select * from c1 where x like 'io';select * from c2 where x like 'io';
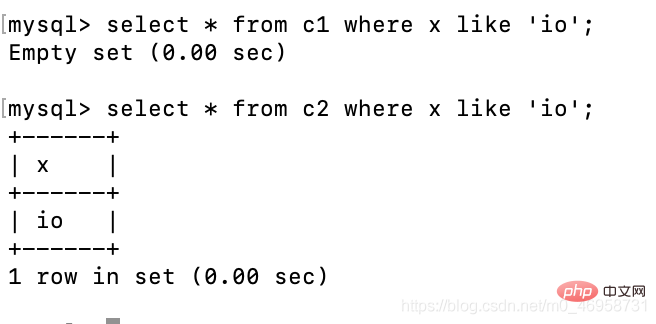
可以发现,c1里面的x为char类型,我们通过模糊查询是否有io这个数据,无法显示出来,而我们通过=却可以查询出来

模糊查询比较精准,这种方式查询,必须要输入这个字段的全部内容,才可以查询出来,而这里char类型存储的数据,长度不满10为,所以使用了空格补充,所以查询的时候,需要把空格带上才可以;
我们也可以使用模糊查询提供给我们的查询方式,% 表示任意0个或多个字符。
select * from c1 where x like 'io%';

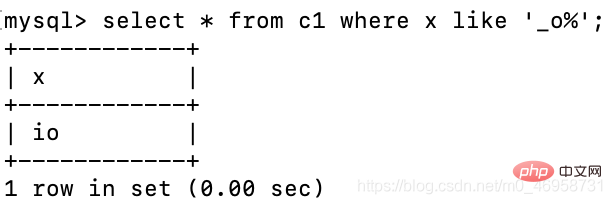
如果我们只知道第二位是一个o,不知道开头和结尾,可以使用:_ 表示任意单个字符,再配合%匹配后面的多个字符
select * from c1 where x like '_o%';
SQL模糊查询的语法为
“SELECT column FROM table WHERE column LIKE ‘;pattern’;”。
SQL提供了四种匹配模式:
- % 表示任意0个或多个bai字符。如下语句:
SELECT * FROM user WHERE name LIKE ‘;%三%’;
将会把name为“张三”,“三脚猫”,“唐三藏”等等有“三”的全找出来;- _ 表示任意单个字符。语句:
SELECT * FROM user WHERE name LIKE ‘;三’;
只找出“唐三藏”这样name为三个字且中间一个字是“三”的;
SELECT * FROM user WHERE name LIKE ‘;三__’;
只找出“三脚猫”这样name为三个字且第一个字是“三”的;- []表示括号内所列字符中的一个(类似与正则表达式)。语句:
SELECT * FROM user WHERE name LIKE ‘;[张李王]三’;
将找出“张三”、“李三”、“王三”(而不是“张李王三”);
如 [ ] 内有一系列字符(01234、abcde之类的)则可略写为“0-4”、“a-e”
SELECT * FROM user WHERE name LIKE ‘;老[1-9]’;
将找出“老1”、“老2”、……、“老9”;
如要找“-”字符请将其放在首位:’;张三[-1-9]’;- [^ ] 表示不在括号所列之内的单个字符。语句:
SELECT * FROM user WHERE name LIKE ‘;[^张李王]三’;
将找出不姓“张”、“李”、“王”的“赵三”、“孙三”等;
SELECT * FROM user WHERE name LIKE ‘;老[^1-4]’;
将排除“老1”到“老4”寻找“老5”、“老6”、……、“老9”。
表的约束
介绍:
约束条件与数据类型的宽度一样,都是可选参数
作用:用于保证数据的完整性和一致性
主要分为:
PRIMARY KEY (PK) 标识该字段为该表的主键,可以唯一的标识记录FOREIGN KEY (FK) 标识该字段为该表的外键NOT NULL 标识该字段不能为空UNIQUE KEY (UK) 标识该字段的值是唯一的AUTO_INCREMENT 标识该字段的值自动增长(整数类型,而且为主键)DEFAULT 为该字段设置默认值UNSIGNED 无符号 ZEROFILL 使用0填充
not null:字面意思就说明了,设置后,每次插入值时,必须为该字段设置值
default:如果没有为该字段设置值,则使用我们定义在default后面的一个默认值
UNIQUE KEY:某个字段设置这个约束后,那么它设置的值,在整个表中这个字段只能存在一个(唯一)
PRIMARY KEY:主键primary key是innodb存储引擎组织数据的依据,innodb称之为索引组织表,一张表中必须有且只有一个主键。主键是能确定一条记录的唯一标识
AUTO_INCREMENT:当设置以后,每次向表插入值时,这个字段会自动增长一个数字,但是这个字段必须是整数类型,而且还要是主键
FOREIGN KEY:外键,将该表的某个字段关联另一张表的某个字段,关联后这个字段的值必须对应关联字段的值。
我们创建表,通常会有一个id字段作为索引标识作用,并且会将它设置为主键和自增。
实例:
create table test(
id int primary key auto_increment,
identity varchar(18) not null unique key, --身份证必须唯一
gender varchar(18) default '男');insert test(identity) values('123456789012345678');
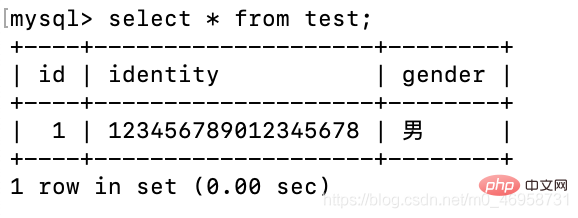
当身份字段插入相同值,则会报错,因为字段设置了唯一值
insert test(identity,gender) values('0123456789012345678','女');

我们会发现,id不对劲啊,那是因为笔者之前进行两次插入值操作,但是值并没有成功插入进去,但是这个自增却受到了影响.
这个时候,我们进行两部操作就可以解决这个问题。
alter table test drop id;alter table test add id int primary key auto_increment first;
删除id字段,再重新设置。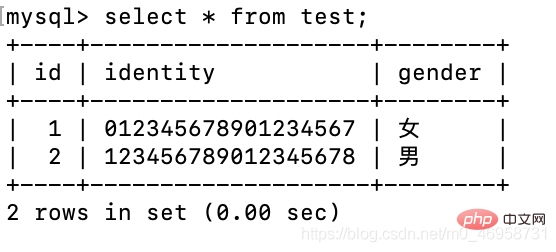
很神奇是不是,这个MySQL的底层机制。vary 良心
还需要注意的是:我们使用delete删除一条记录时,并不会影响自增
delete from test where id = 2;insert test(identity,gender) values('111111111111111111','男');
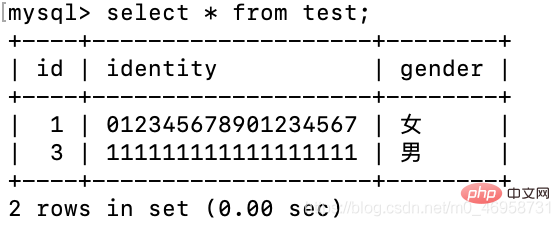
关于这个操作,如果我们只是删除单条记录的话,可以使用上序提供的方法还调整自增的值,而如果是删除整个表记录的话,使用以下方法:
truncate test;
效果演示:delete删除整个表记录
效果演示:truncate删除整个表记录
联合主键
确保设置为主键的某几个字段的数据相同
主键的一个目的就是确定数据的唯一性,它跟唯一约束的区别就是,唯一约束可以有一个NULL值,但是主键不能有NULL值,再说联合主键,联合主键就是说,当一个字段可能存在重复值,无法确定这条数据的唯一性时,再加上一个字,两个字段联合起来确定这条数据的唯一性。比如你提到的id和name为联合主键,在插入数据时,当id相同,name不同,或者id不同,name相同时数据是允许被插入的,但是当id和name都相同时,数据是不允许被插入的。
实例:
create table test( id int, name varchar(10), primary key(id,name)); insert test values(1,1);

如果再次插入两个主键相同的数据,则会报错
只要设置主键的两个字段,在一条记录内,数据不完全相同就没有问题。
外键的话,我们在表之间的关联进行演示
表之间的关联
我们这里先介绍表之间的关联,后面再学习联表查询
通过某一个字段,或者通过某一张表,将多个表关联起来。
我们一张表处理好不行吗,为什么要关联,像这样?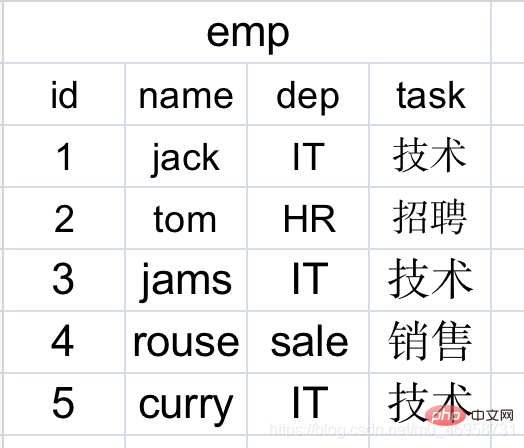
有没有发现一个问题,有些员工它们对应的是相同部门,一张表就重复了很多次记录,随着员工数量的增加,就会出现越来越多个重复记录,相对更占用空间了。
那么我们需要将部门单独使用一张表,再将员工这个使用一个字段关联到另一个表内,我们可以使用外键,也可以不使用外键,先来演示外键的好处吧
多对一关联
如:多个员工对应一个部门。
员工表,先别急着创建,请向下看
create table emp( id int primary key auto_increment, name varchar(10) not null, dep_id int, foreign key(dep_id) references dep(id) on update cascade # 级联更新 on delete cascade); # 级联删除
上面外键的作用就是:
dep_id字段关联了dep表的id字段:
当dep表的id字段值修改后,该表的dep_id字段下面如果有和dep表id相同值的则会一起更改。
如果dep表删除了某一条记录,当emp表的dep_id与dep表删除记录的id值对上以后,emp表这条记录也会被随之删除。
注意:必须是外键已存在,所以需要先创建部门表,再创建员工表
部门表
create table dep( id int primary key auto_increment, name varchar(16) not null unique key, task varchar(16) not null);
emp表的dep_id字段设置的数据必须是dep表已存在的id
所以我们需要先向dep表插入记录
insert dep(name,task) values('IT','技术'),('HR','招聘'),('sale','销售');
员工表插入记录
insert emp(name,dep_id) values
('jack',1),
('tom',2),
('jams',1),
('rouse',3),
('curry',2);
# ('go',4) 报错,在关联外键的id字段中找不到
注意:如果我们emp表的dep_id字段插入的数据,在dep表中的id字段不存在该数据时,就会报错。
查询我们创建后的效果
这样就把这两个表关联起来了,目前我们先不了解多表查询,这个先了解的是,表之间的关联。
我们再来看一下同步更新以及删除,外键的改动被关联表会受到影响
update dep set id=33333 where id = 3;
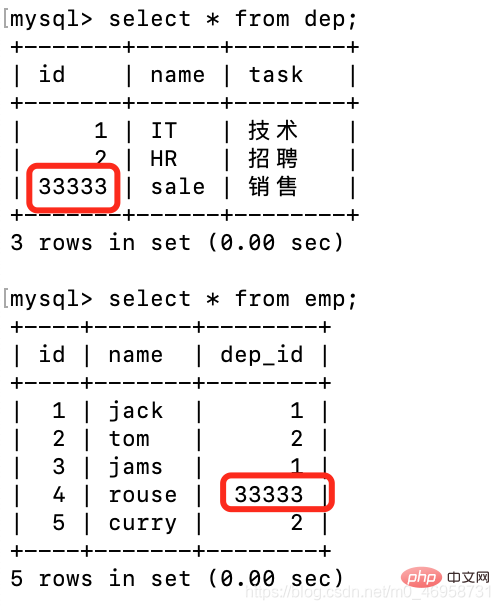
再来体验一下同步删除
delete from dep where id = 33333;

这就是外键带给我们的效果,有利也有弊:
- 优点:关联性强,只能设置已存在的内容,并且同步更新与删除
- 缺点:当删除外键表的某一条记录,关联表中有关联性的记录会被全部删除
多对多关联
多张表互相关联
如:一个作者可以写多本书,一本书也可以有多个作者,双向的一对多,即多对多
这时使用外键会出现一个弊端,那就是先创建哪张表呢?它们都互相对应,是不是很矛盾呢?解决办法:第三张表,关联书的id与作者的id
book表
create table book( id int primary key auto_increment, name varchar(30));
author表
create table author( id int primary key auto_increment, name varchar(30));
中间表:负责将两张表进行关联
create table authorRbook( id int primary key auto_increment, author_id int, book_id int, foreign key(book_id) references book(id) on update cascade on delete cascade, foreign key(author_id) references author(id) on update cascade on delete cascade);
多名作者关联一本书,或者一名作者关联多本书,书也要体现出谁关联了它
book表插入数据:
insert book(name) values
('斗破苍穹'),
('斗罗大陆'),
('武动乾坤');
author表插入数据:
insert author(name) values
('jack'),
('tom'),
('jams'),
('rouse'),
('curry'),
('john');
关联表插入数据:
insert authorRbook(author_id,book_id) values (1,1), (1,2), (1,3), (2,1), (2,3), (3,2), (4,1), (5,1), (5,3), (6,2);
目前的对应关系就是:
jack:斗破苍穹、斗罗大陆、武动乾坤
tom:斗破苍穹、武动乾坤
jams:斗罗大陆
rouse:斗破苍穹
curry:斗破苍穹、武动乾坤
jhon:斗罗大陆
一个作者可以产于多本书的编写,同时,每本书都会标明产于的作者
一对一关联
路人有可能变成某个学校的学生,即一对一关系。
在这之前,路人不属于学校。
原理就是:学校通过广告,或者通过电话邀请,将路人变成了学生。
路人表
create table passers_by(
id int primary key auto_increment,
name varchar(10),
age int);
insert passers_by(name,age) values
('jack',18),
('tom',19),
('jams',23);
学校表
create table school(
id int primary key auto_increment,
class varchar(10),
student_id int unique key,
foreign key(student_id) references passers_by(id)
on update cascade
on delete cascade);insert school(class,student_id) values
('Mysql入门到放弃',1),
('Python入门到运维',3),
('Java从入门到音乐',2);
数据存储的设计,需要提前设计好表的关联 关系,将关系全部设计好以后,剩下的只是往里存数据了,后续我们会了解到联表查询相关内容,将有关联性的内容,以虚拟表的形式查询出来,查询出来的数据可能来自多个表。
表的关联,建议使用以下方式
- 多对多 > 多对一 > 一对一
相关免费学习推荐:mysql数据库(视频)
以上是一起了解什么是MySQL数据库(三)的详细内容。更多信息请关注PHP中文网其他相关文章!

 MySQL与Sqlite有何不同?Apr 24, 2025 am 12:12 AM
MySQL与Sqlite有何不同?Apr 24, 2025 am 12:12 AMMySQL和SQLite的主要区别在于设计理念和使用场景:1.MySQL适用于大型应用和企业级解决方案,支持高性能和高并发;2.SQLite适合移动应用和桌面软件,轻量级且易于嵌入。
 MySQL中的索引是什么?它们如何提高性能?Apr 24, 2025 am 12:09 AM
MySQL中的索引是什么?它们如何提高性能?Apr 24, 2025 am 12:09 AMMySQL中的索引是数据库表中一列或多列的有序结构,用于加速数据检索。1)索引通过减少扫描数据量提升查询速度。2)B-Tree索引利用平衡树结构,适合范围查询和排序。3)创建索引使用CREATEINDEX语句,如CREATEINDEXidx_customer_idONorders(customer_id)。4)复合索引可优化多列查询,如CREATEINDEXidx_customer_orderONorders(customer_id,order_date)。5)使用EXPLAIN分析查询计划,避
 说明如何使用MySQL中的交易来确保数据一致性。Apr 24, 2025 am 12:09 AM
说明如何使用MySQL中的交易来确保数据一致性。Apr 24, 2025 am 12:09 AM在MySQL中使用事务可以确保数据一致性。1)通过STARTTRANSACTION开始事务,执行SQL操作后用COMMIT提交或ROLLBACK回滚。2)使用SAVEPOINT可以设置保存点,允许部分回滚。3)性能优化建议包括缩短事务时间、避免大规模查询和合理使用隔离级别。
 在哪些情况下,您可以选择PostgreSQL而不是MySQL?Apr 24, 2025 am 12:07 AM
在哪些情况下,您可以选择PostgreSQL而不是MySQL?Apr 24, 2025 am 12:07 AM选择PostgreSQL而非MySQL的场景包括:1)需要复杂查询和高级SQL功能,2)要求严格的数据完整性和ACID遵从性,3)需要高级空间功能,4)处理大数据集时需要高性能。PostgreSQL在这些方面表现出色,适合需要复杂数据处理和高数据完整性的项目。
 如何保护MySQL数据库?Apr 24, 2025 am 12:04 AM
如何保护MySQL数据库?Apr 24, 2025 am 12:04 AMMySQL数据库的安全可以通过以下措施实现:1.用户权限管理:通过CREATEUSER和GRANT命令严格控制访问权限。2.加密传输:配置SSL/TLS确保数据传输安全。3.数据库备份和恢复:使用mysqldump或mysqlpump定期备份数据。4.高级安全策略:使用防火墙限制访问,并启用审计日志记录操作。5.性能优化与最佳实践:通过索引和查询优化以及定期维护兼顾安全和性能。
 您可以使用哪些工具来监视MySQL性能?Apr 23, 2025 am 12:21 AM
您可以使用哪些工具来监视MySQL性能?Apr 23, 2025 am 12:21 AM如何有效监控MySQL性能?使用mysqladmin、SHOWGLOBALSTATUS、PerconaMonitoringandManagement(PMM)和MySQLEnterpriseMonitor等工具。1.使用mysqladmin查看连接数。2.用SHOWGLOBALSTATUS查看查询数。3.PMM提供详细性能数据和图形化界面。4.MySQLEnterpriseMonitor提供丰富的监控功能和报警机制。
 MySQL与SQL Server有何不同?Apr 23, 2025 am 12:20 AM
MySQL与SQL Server有何不同?Apr 23, 2025 am 12:20 AMMySQL和SQLServer的区别在于:1)MySQL是开源的,适用于Web和嵌入式系统,2)SQLServer是微软的商业产品,适用于企业级应用。两者在存储引擎、性能优化和应用场景上有显着差异,选择时需考虑项目规模和未来扩展性。
 在哪些情况下,您可以选择SQL Server而不是MySQL?Apr 23, 2025 am 12:20 AM
在哪些情况下,您可以选择SQL Server而不是MySQL?Apr 23, 2025 am 12:20 AM在需要高可用性、高级安全性和良好集成性的企业级应用场景下,应选择SQLServer而不是MySQL。1)SQLServer提供企业级功能,如高可用性和高级安全性。2)它与微软生态系统如VisualStudio和PowerBI紧密集成。3)SQLServer在性能优化方面表现出色,支持内存优化表和列存储索引。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

禅工作室 13.0.1
功能强大的PHP集成开发环境

