



java基础教程栏目介绍如何解决Java日志级别等问题

相关免费学习推荐:java基础教程
1 日志常见错因
1.1 日志框架繁多
不同类库可能使用不同日志框架,兼容是个难题
1.2 配置复杂且容易出错
日志配置文件通常很繁杂,很多同学习惯从其他项目或网上博客直接复制份配置文件,但却不仔细研究如何修改。常见错误发生于重复记录日志、同步日志的性能、异步记录的错误配置。
1.3 日志记录本身就有些误区
比如没考虑到日志内容获取的代价、胡乱使用日志级别等。
2 SLF4J
Logback、Log4j、Log4j2、commons-logging、JDK自带的java.util.logging等,都是Java体系的日志框架,确实非常多。而不同的类库,还可能选择使用不同的日志框架。这样一来,日志的统一管理就变得非常困难。
- SLF4J(Simple Logging Facade For Java)就为解决该问题
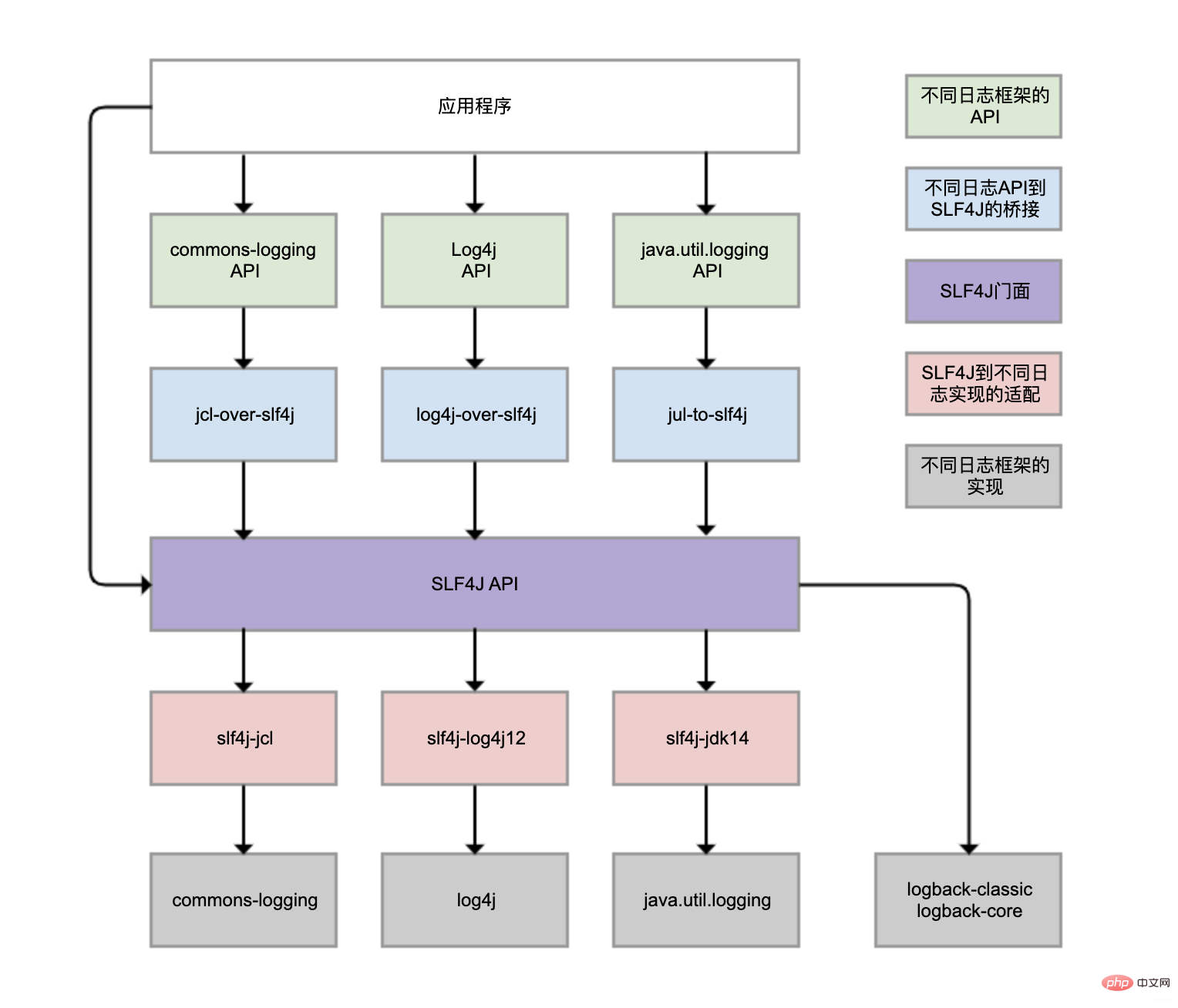
- 提供统一的日志门面API,即图中紫色部分,实现中立的日志记录API
- 桥接功能,蓝色部分,把各种日志框架API(绿色部分)桥接到SLF4J API。这样即便你的程序中使用各种日志API记录日志,最终都可桥接到SLF4J门面API。
- 适配功能,红色部分,可实现SLF4J API和实际日志框架(灰色部分)绑定。
SLF4J只是日志标准,还是需要实际日志框架。日志框架本身未实现SLF4J API,所以需前置转换。Logback就是按SLF4J API标准实现,所以才无需绑定模块做转换。
虽然可用log4j-over-slf4j实现Log4j桥接到SLF4J,也可使用slf4j-log4j12实现SLF4J适配到Log4j,也把它们画到了一列,但是它不能同时使用它们,否则就会产生死循环。jcl和jul同理。
虽然图中有4个灰色的日志实现框架,但日常业务使用最多的还是Logback和Log4j,都是同一人开发的。Logback可认为是Log4j改进版,更推荐使用,基本已是主流。
Spring Boot的日志框架也是Logback。那为什么我们没有手动引入Logback包,就可直接使用Logback?
spring-boot-starter模块依赖spring-boot-starter-logging模块
spring-boot-starter-logging模块自动引入logback-classic(包含SLF4J和Logback日志框架)和SLF4J的一些适配器。其中,log4j-to-slf4j用于实现Log4j2 API到SLF4J的桥接,jul-to-slf4j则是实现java.util.logging API到SLF4J的桥接。
3 日志重复记录
日志重复记录不但给查看日志和统计工作带来不必要的麻烦,还会增加磁盘和日志收集系统的负担。
logger配置继承关系导致日志重复记录
定义一个方法实现debug、info、warn和error四种日志的记录

Logback配置
配置看没啥问题,执行方法后出现日志重复记录
分析
CONSOLE这个Appender同时挂载到了俩Logger,定义的<logger>和<root>,由于定义的<logger>继承自<root>,所以同一条日志既会通过logger记录,也会发送到root记录,因此应用package下日志出现重复记录。

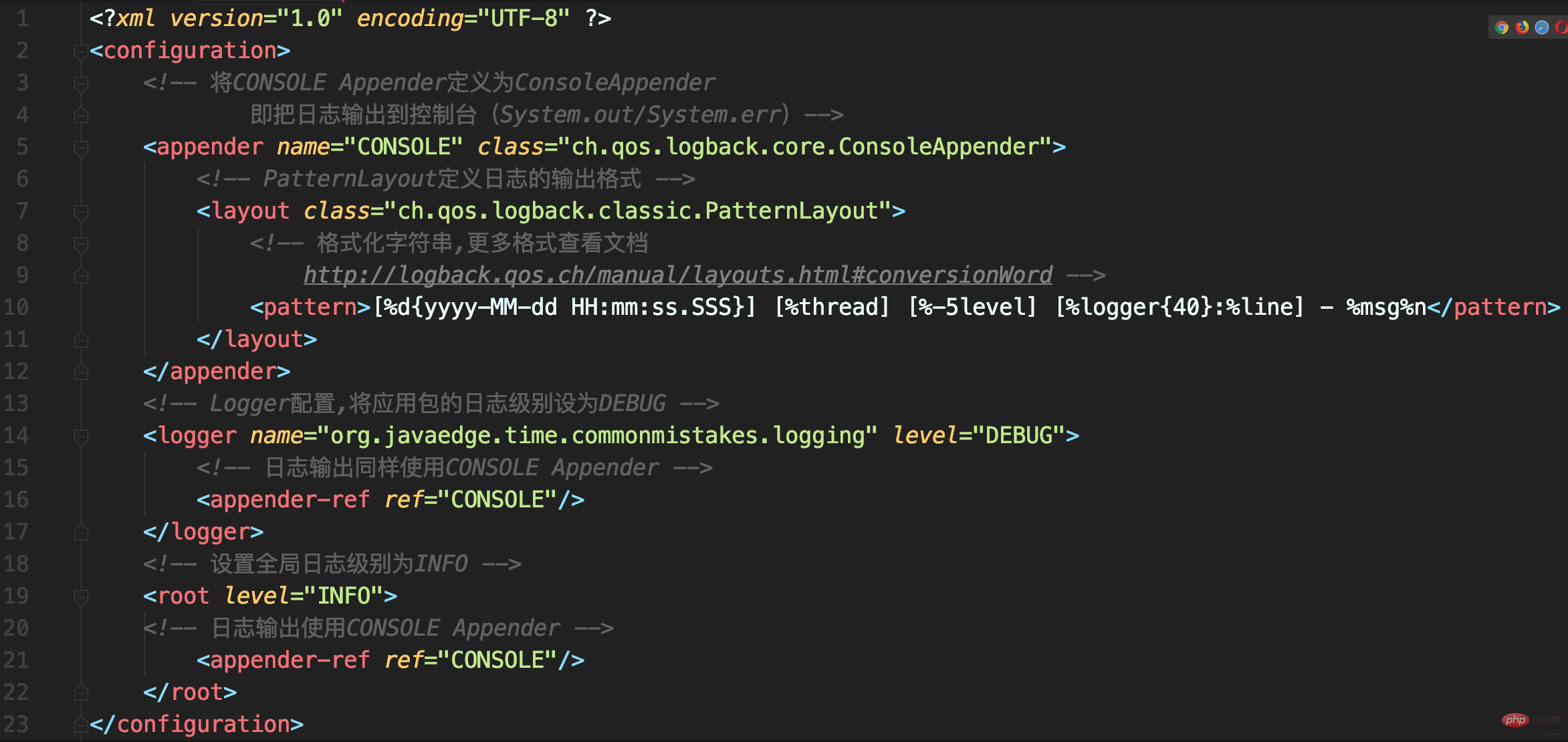
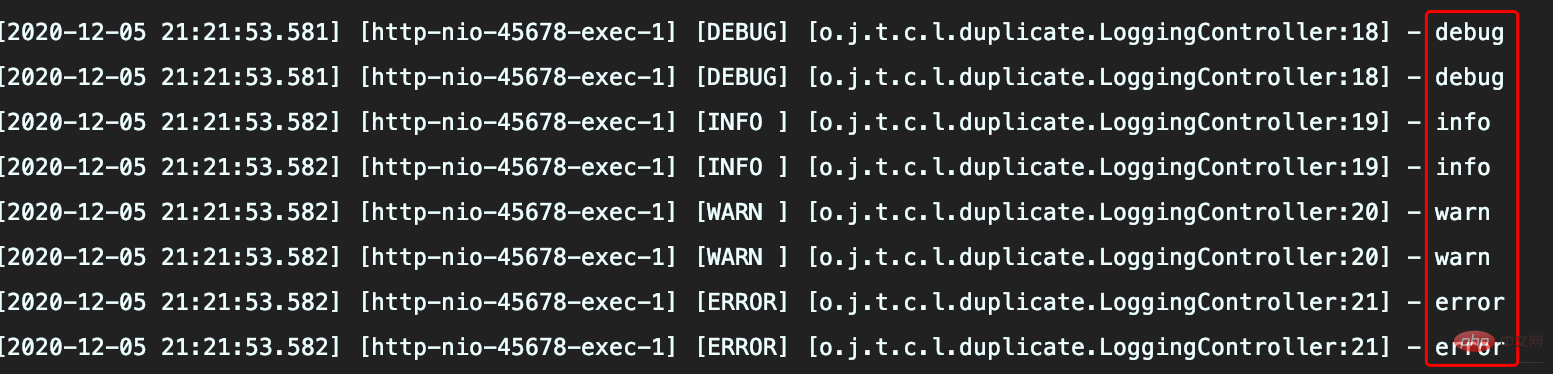
如此配置的初衷是啥呢?
内心是想实现自定义logger配置,让应用内的日志暂时开启DEBUG级别日志记录。其实,这无需重复挂载Appender,去掉<logger>下挂载的Appender即可:
<logger name="org.javaedge.time.commonmistakes.logging" level="DEBUG"/>
若自定义<logger>需把日志输出到不同Appender:
比如
- 应用日志输出到文件app.log
- 其他框架日志输出到控制台
可设置<logger>的additivity属性为false,这就不会继承<root>的Appender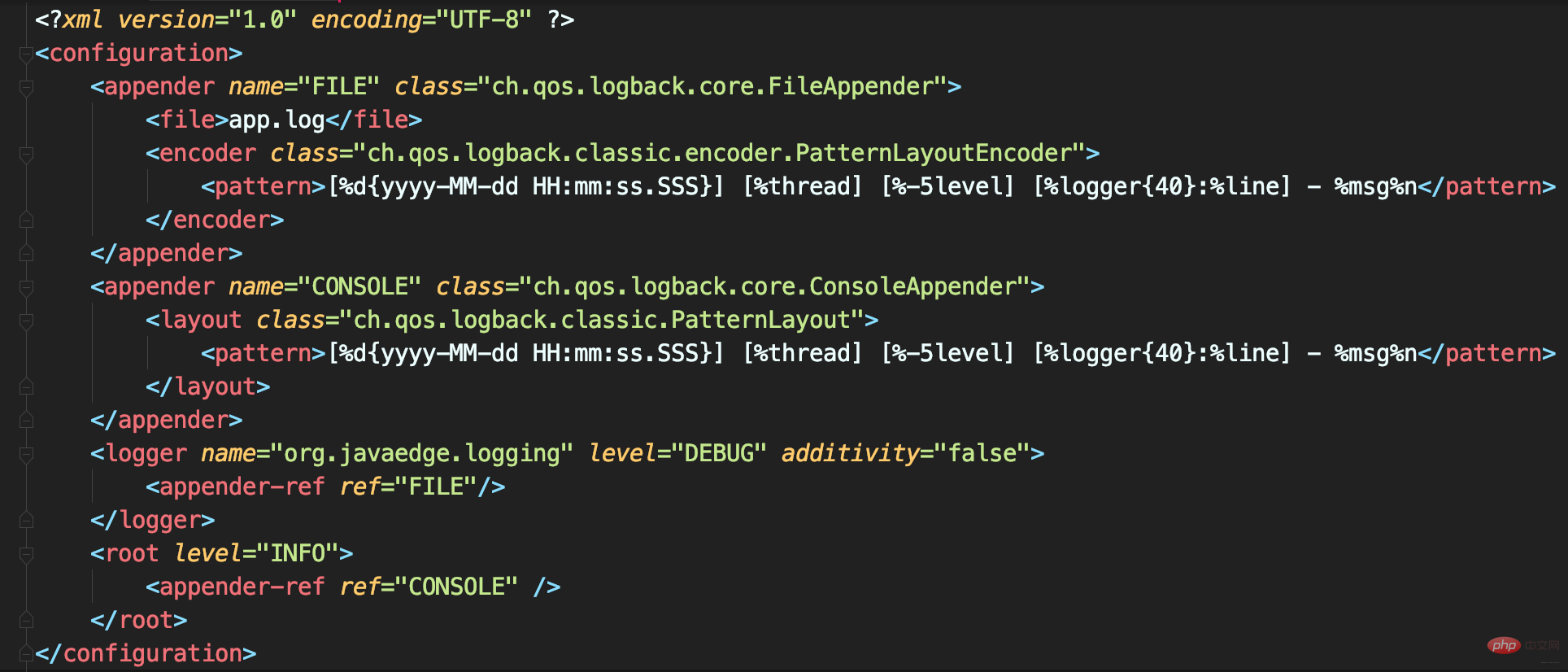
错误配置LevelFilter造成日志重复
在记录日志到控制台的同时,把日志记录按照不同级别记录到俩文件
执行结果
info.log 文件包含INFO、WARN和ERROR三级日志,不符预期
error.log包含WARN和ERROR俩级别日志,导致日志重复收集
事故问责
一些公司使用自动化ELK方案收集日志,日志会同时输出到控制台和文件,开发人员在本地测试不会关心文件中记录的日志,而在测试和生产环境又因为开发人员没有服务器访问权限,所以原始日志文件中的重复问题难以发现。



日志到底为何重复呢?
ThresholdFilter源码解析
- 当
日志级别 ≥ 配置级别返回NEUTRAL,继续调用过滤器链上的下个过滤器 - 否则返回DENY,直接拒绝记录日志

该案例我们将 ThresholdFilter 置 WARN,因此可记录WARN和ERROR级日志。
LevelFilter
用于比较日志级别,然后进行相应处理。
- 若匹配就调用onMatch定义的处理方式:默认交给下一个过滤器处理(AbstractMatcherFilter基类中定义的默认值)
- 否则调用onMismatch定义的处理方式:默认也是交给下一个过滤器
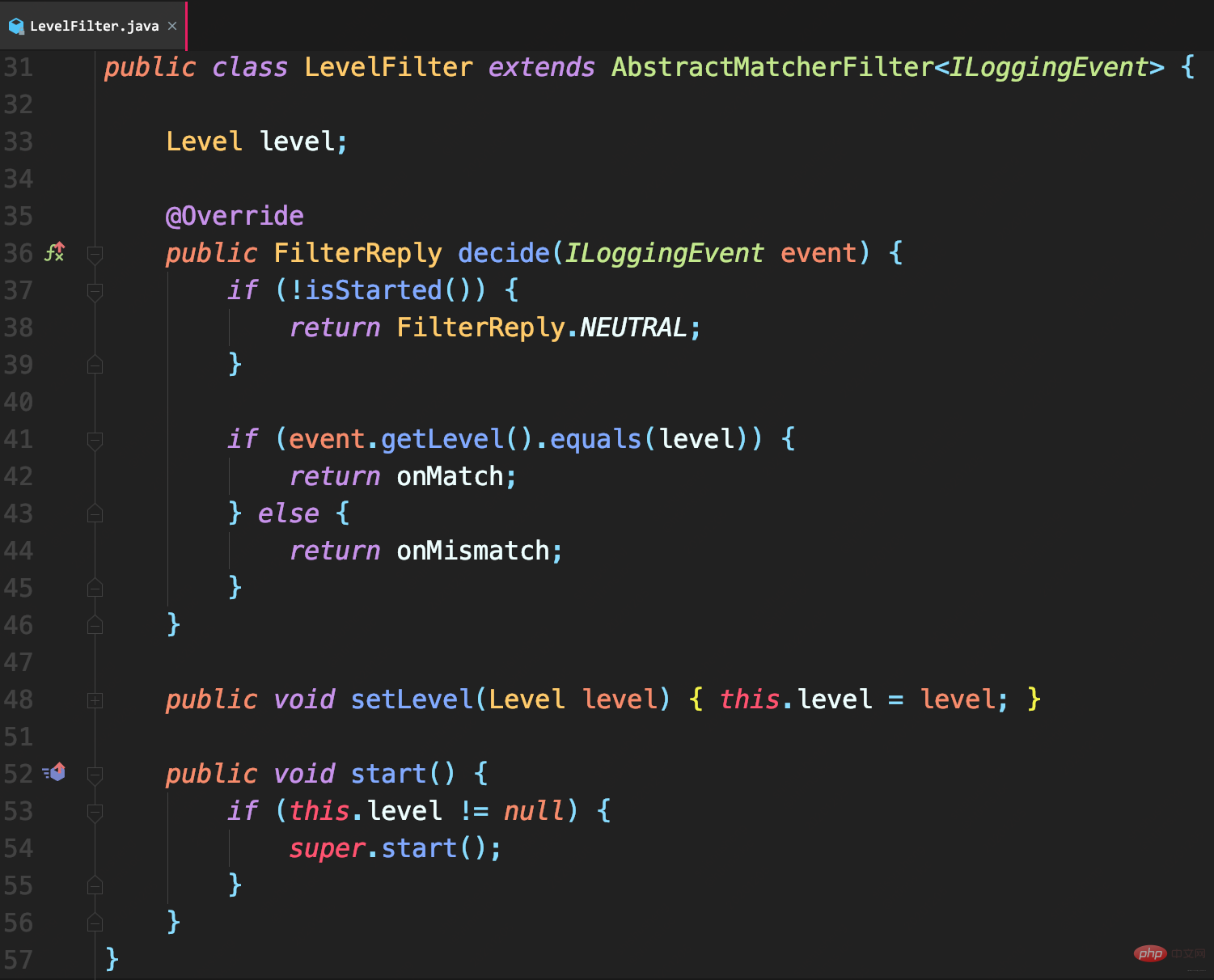

和ThresholdFilter不同,LevelFilter仅配置level无法真正起作用。
由于未配置onMatch和onMismatch属性,所以该过滤器失效,导致INFO以上级别日志都记录了。
修正
配置LevelFilter的onMatch属性为ACCEPT,表示接收INFO级别的日志;配置onMismatch属性为DENY,表示除了INFO级别都不记录: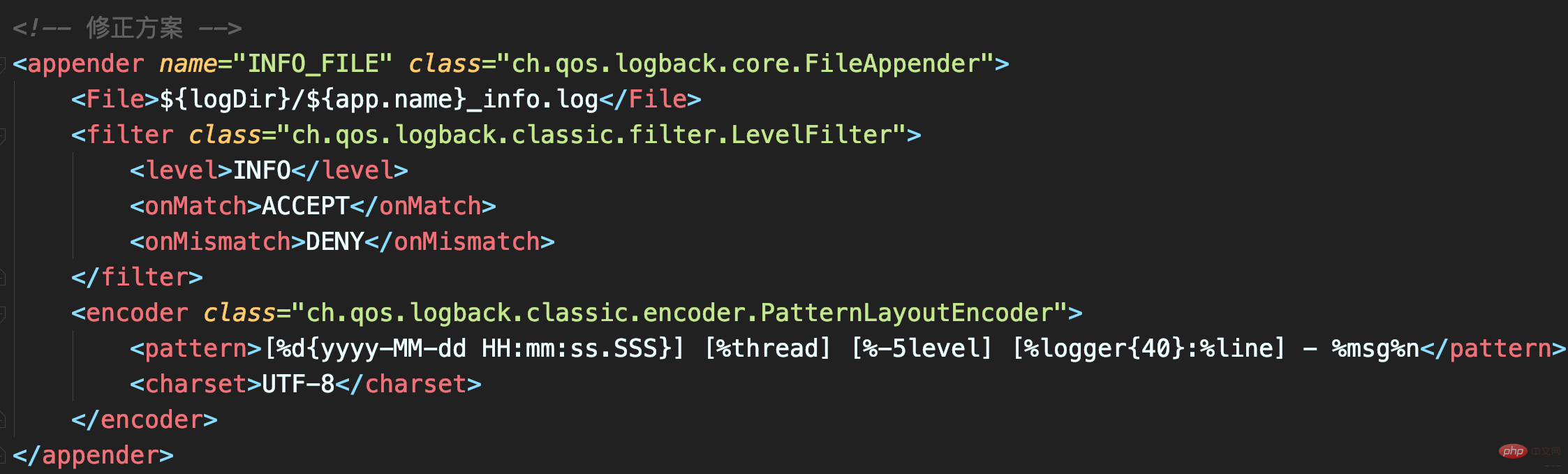
如此,_info.log文件只会有INFO级日志,不会再出现日志重复。
4 异步日志提高性能?
知道了到底如何正确将日志输出到文件后,就该考虑如何避免日志记录成为系统性能瓶颈。这可解决,磁盘(比如机械磁盘)IO性能较差、日志量又很大的情况下,如何记录日志问题。
定义如下的日志配置,一共有两个Appender:
FILE是一个FileAppender,用于记录所有的日志;
CONSOLE是一个ConsoleAppender,用于记录带有time标记的日志。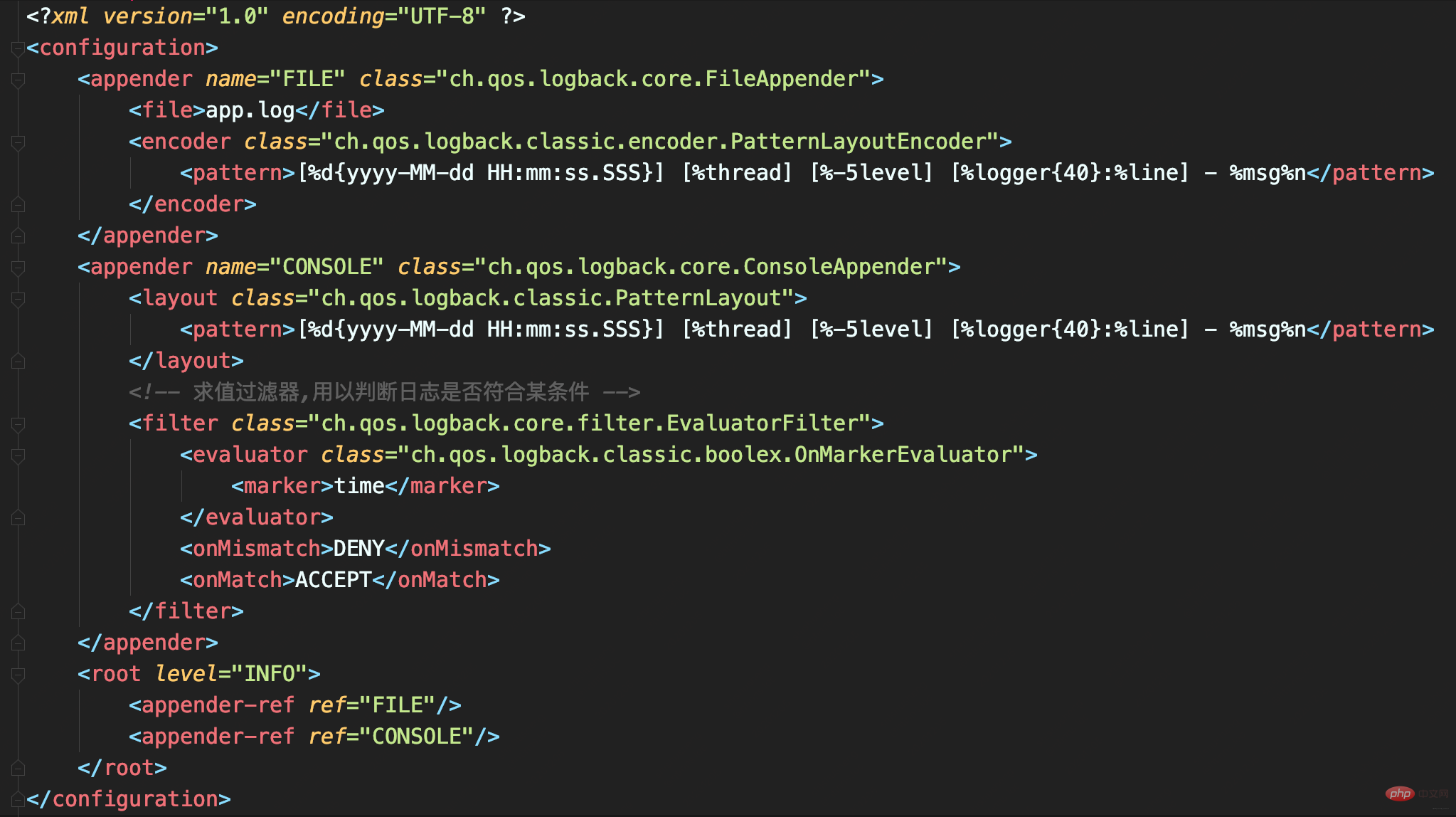
把大量日志输出到文件中,日志文件会非常大,如果性能测试结果也混在其中的话,就很难找到那条日志。所以,这里使用EvaluatorFilter对日志按照标记进行过滤,并将过滤出的日志单独输出到控制台上。该案例中给输出测试结果的那条日志上做了time标记。
配合使用标记和EvaluatorFilter,实现日志的按标签过滤。
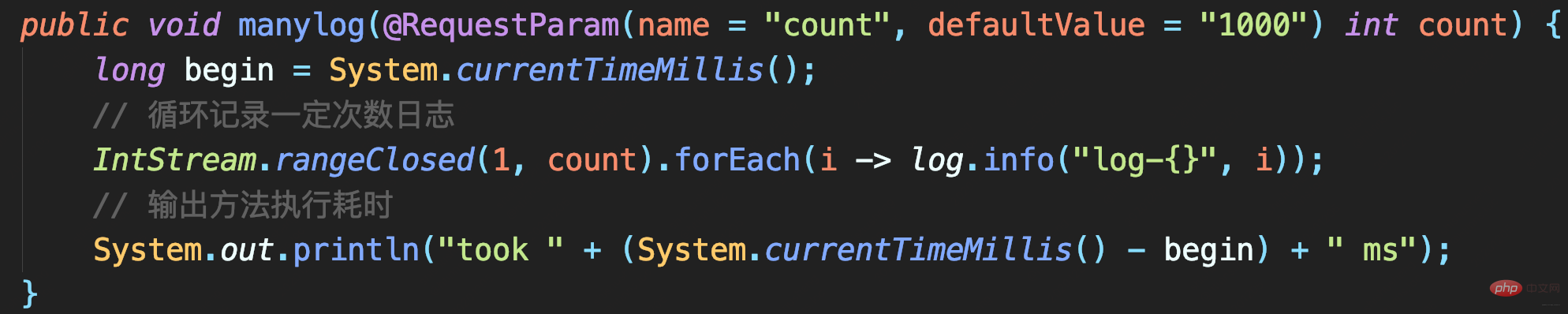
- 测试代码:实现记录指定次数的大日志,每条日志包含1MB字节的模拟数据,最后记录一条以time为标记的方法执行耗时日志:
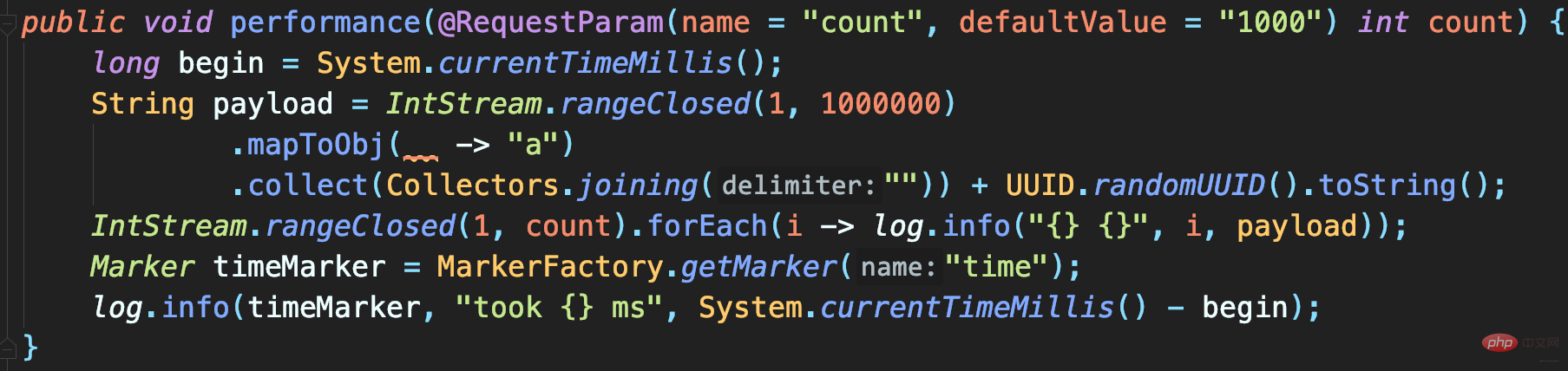
执行程序后可以看到,记录1000次日志和10000次日志的调用耗时,分别是5.1秒和39秒

对只记录文件日志的代码,这耗时过长。
源码解析
FileAppender继承自OutputStreamAppender
在追加日志时,是直接把日志写入OutputStream中,属同步记录日志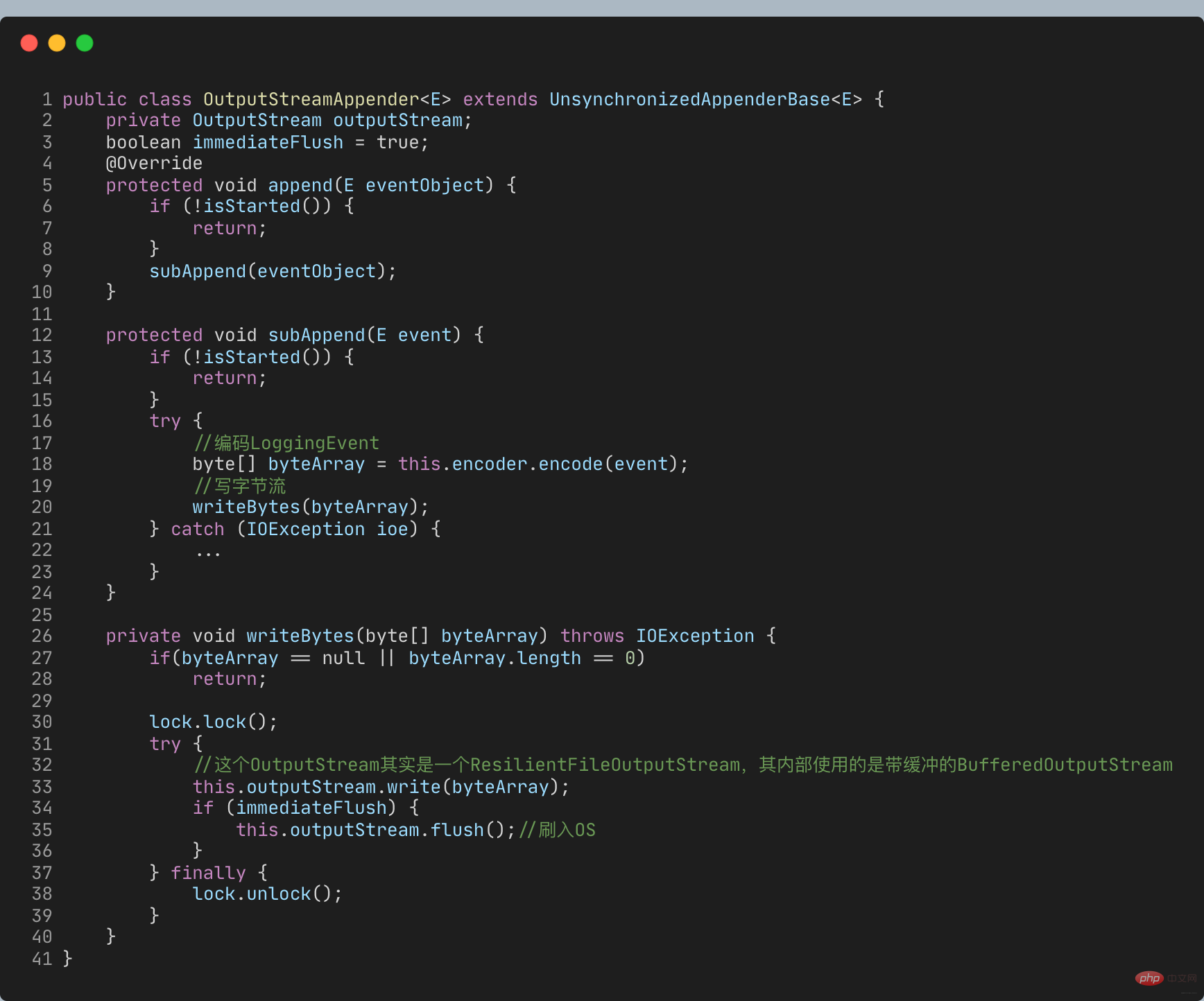
所以日志大量写入才会旷日持久。如何才能实现大量日志写入时,不会过多影响业务逻辑执行耗时而影响吞吐量呢?
AsyncAppender
使用Logback的AsyncAppender
即可实现异步日志记录。AsyncAppender类似装饰模式,在不改变类原有基本功能情况下为其增添新功能。这便可把AsyncAppender附加在其他Appender,将其变为异步。
定义一个异步Appender ASYNCFILE,包装之前的同步文件日志记录的FileAppender, 即可实现异步记录日志到文件
- 记录1000次日志和10000次日志的调用耗时,分别是537毫秒和1019毫秒


异步日志真的如此高性能?并不,因为这并没有记录下所有日志。
AsyncAppender异步日志坑
- 记录异步日志撑爆内存
- 记录异步日志出现日志丢失
- 记录异步日志出现阻塞。
案例
模拟慢日志记录场景:
首先,自定义一个继承自ConsoleAppender的MySlowAppender,作为记录到控制台的输出器,写入日志时休眠1秒。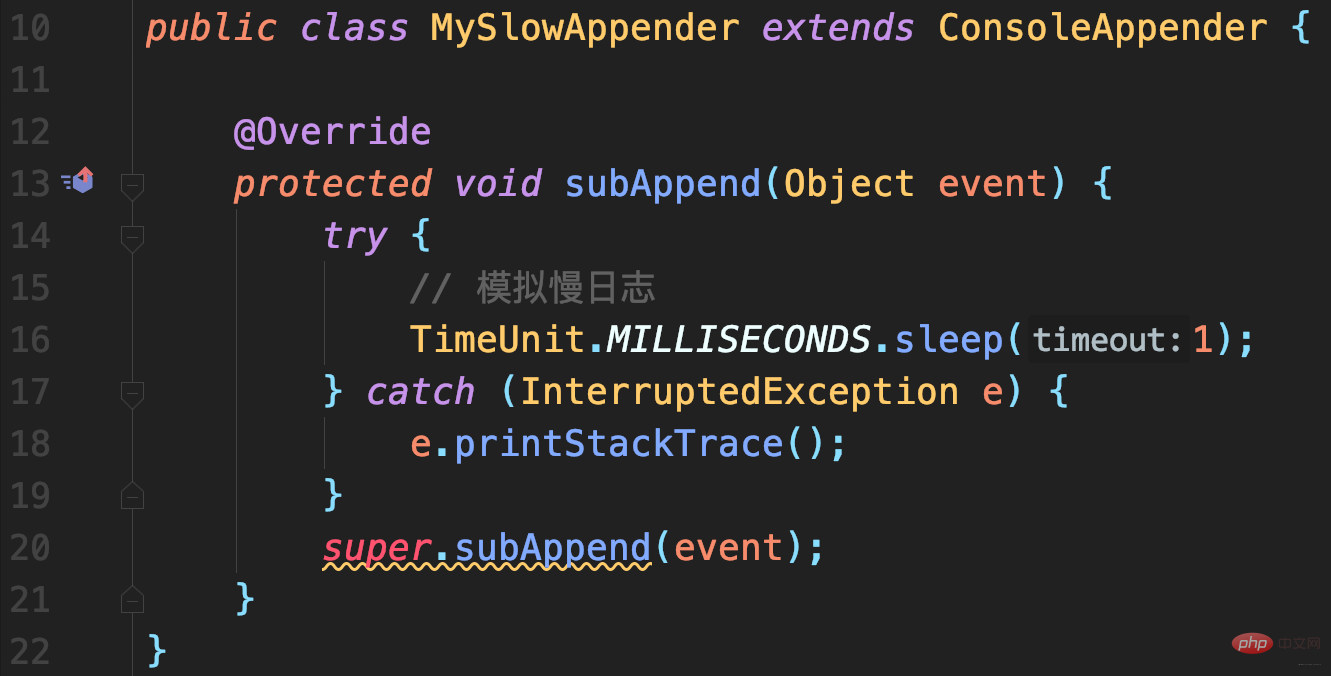
配置文件中使用AsyncAppender,将MySlowAppender包装为异步日志记录
测试代码
耗时很短但出现日志丢失:要记录1000条日志,最终控制台只能搜索到215条日志,而且日志行号变问号。
原因分析
AsyncAppender提供了一些配置参数,而当前没用对。
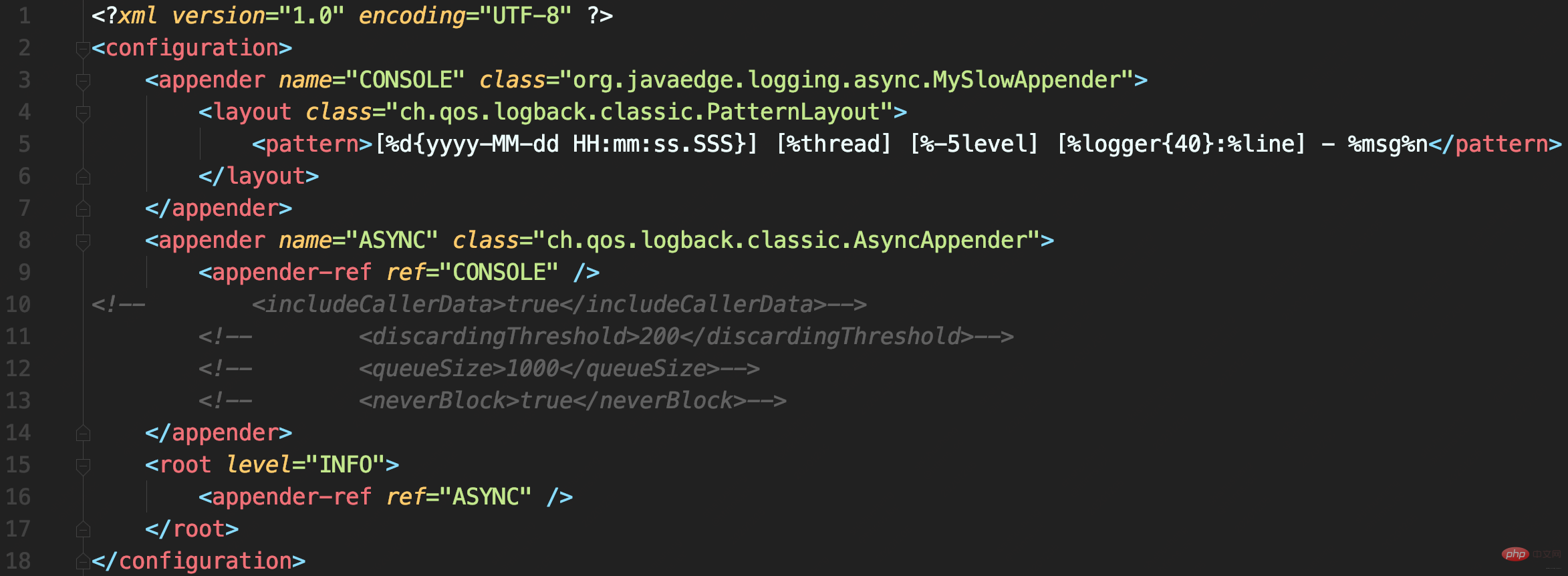
源码解析
- includeCallerData
默认false:方法行号、方法名等信息不显示 - queueSize
控制阻塞队列大小,使用的ArrayBlockingQueue阻塞队列,默认容量256:内存中最多保存256条日志 - discardingThreshold
丢弃日志的阈值,为防止队列满后发生阻塞。默认队列剩余容量 < 队列长度的20%,就会丢弃TRACE、DEBUG和INFO级日志 - neverBlock
控制队列满时,加入的数据是否直接丢弃,不会阻塞等待,默认是false- 队列满时:offer不阻塞,而put会阻塞
- neverBlock为true时,使用offer
public class AsyncAppender extends AsyncAppenderBase<ILoggingEvent> {
// 是否收集调用方数据
boolean includeCallerData = false;
protected boolean isDiscardable(ILoggingEvent event) {
Level level = event.getLevel();
// 丢弃 ≤ INFO级日志
return level.toInt() <= Level.INFO_INT;
}
protected void preprocess(ILoggingEvent eventObject) {
eventObject.prepareForDeferredProcessing();
if (includeCallerData)
eventObject.getCallerData();
}}public class AsyncAppenderBase<E> extends UnsynchronizedAppenderBase<E> implements AppenderAttachable<E> {
// 阻塞队列:实现异步日志的核心
BlockingQueue<E> blockingQueue;
// 默认队列大小
public static final int DEFAULT_QUEUE_SIZE = 256;
int queueSize = DEFAULT_QUEUE_SIZE;
static final int UNDEFINED = -1;
int discardingThreshold = UNDEFINED;
// 当队列满时:加入数据时是否直接丢弃,不会阻塞等待
boolean neverBlock = false;
@Override
public void start() {
...
blockingQueue = new ArrayBlockingQueue<E>(queueSize);
if (discardingThreshold == UNDEFINED)
//默认丢弃阈值是队列剩余量低于队列长度的20%,参见isQueueBelowDiscardingThreshold方法
discardingThreshold = queueSize / 5;
...
}
@Override
protected void append(E eventObject) {
if (isQueueBelowDiscardingThreshold() && isDiscardable(eventObject)) { //判断是否可以丢数据
return;
}
preprocess(eventObject);
put(eventObject);
}
private boolean isQueueBelowDiscardingThreshold() {
return (blockingQueue.remainingCapacity() < discardingThreshold);
}
private void put(E eventObject) {
if (neverBlock) { //根据neverBlock决定使用不阻塞的offer还是阻塞的put方法
blockingQueue.offer(eventObject);
} else {
putUninterruptibly(eventObject);
}
}
//以阻塞方式添加数据到队列
private void putUninterruptibly(E eventObject) {
boolean interrupted = false;
try {
while (true) {
try {
blockingQueue.put(eventObject);
break;
} catch (InterruptedException e) {
interrupted = true;
}
}
} finally {
if (interrupted) {
Thread.currentThread().interrupt();
}
}
}}默认队列大小256,达到80%后开始丢弃<=INFO级日志后,即可理解日志中为什么只有两百多条INFO日志了。
queueSize 过大
可能导致OOM
queueSize 较小
默认值256就已经算很小了,且discardingThreshold设置为大于0(或为默认值),队列剩余容量少于discardingThreshold的配置就会丢弃<=INFO日志。这里的坑点有两个:
- 因为discardingThreshold,所以设置queueSize时容易踩坑。
比如本案例最大日志并发1000,即便置queueSize为1000,同样会导致日志丢失 - discardingThreshold参数容易有歧义,它
不是百分比,而是日志条数。对于总容量10000队列,若希望队列剩余容量少于1000时丢弃,需配置为1000
neverBlock 默认false
意味总可能会出现阻塞。
- 若discardingThreshold = 0,那么队列满时再有日志写入就会阻塞
- 若discardingThreshold != 0,也只丢弃≤INFO级日志,出现大量错误日志时,还是会阻塞
queueSize、discardingThreshold和neverBlock三参密不可分,务必按业务需求设置:
- 若优先绝对性能,设置
neverBlock = true,永不阻塞 - 若优先绝不丢数据,设置
discardingThreshold = 0,即使≤INFO级日志也不会丢。但最好把queueSize设置大一点,毕竟默认的queueSize显然太小,太容易阻塞。 - 若兼顾,可丢弃不重要日志,把queueSize设置大点,再设置合理的discardingThreshold
以上日志配置最常见两个误区
再看日志记录本身的误区。
使用日志占位符就无需判断日志级别?
SLF4J的{}占位符语法,到真正记录日志时才会获取实际参数,因此解决了日志数据获取的性能问题。
这说法对吗?
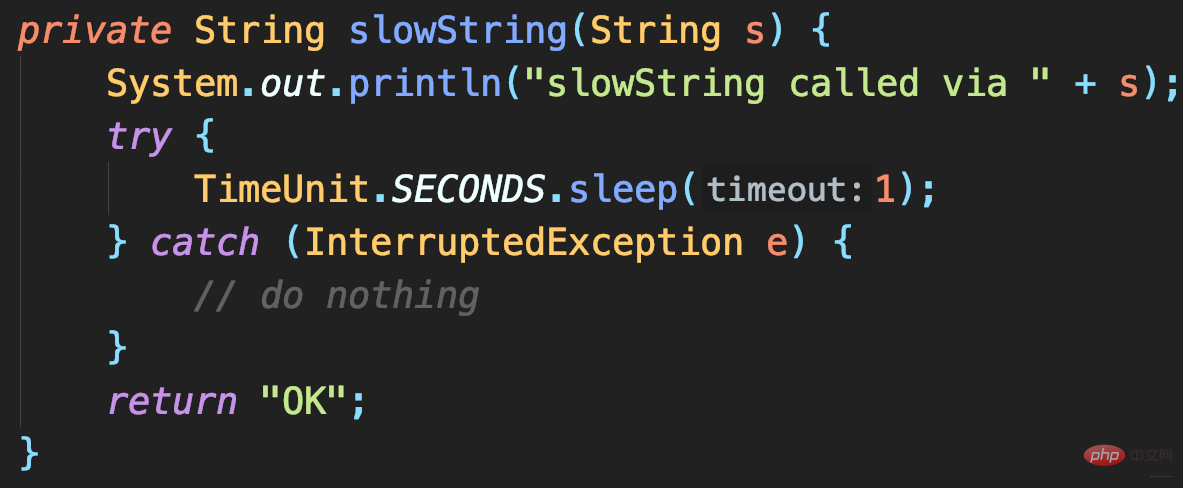
- 验证代码:返回结果耗时1秒
若记录DEBUG日志,并设置只记录>=INFO级日志,程序是否也会耗时1秒?
三种方法测试:
- 拼接字符串方式记录slowString
- 使用占位符方式记录slowString
- 先判断日志级别是否启用DEBUG。
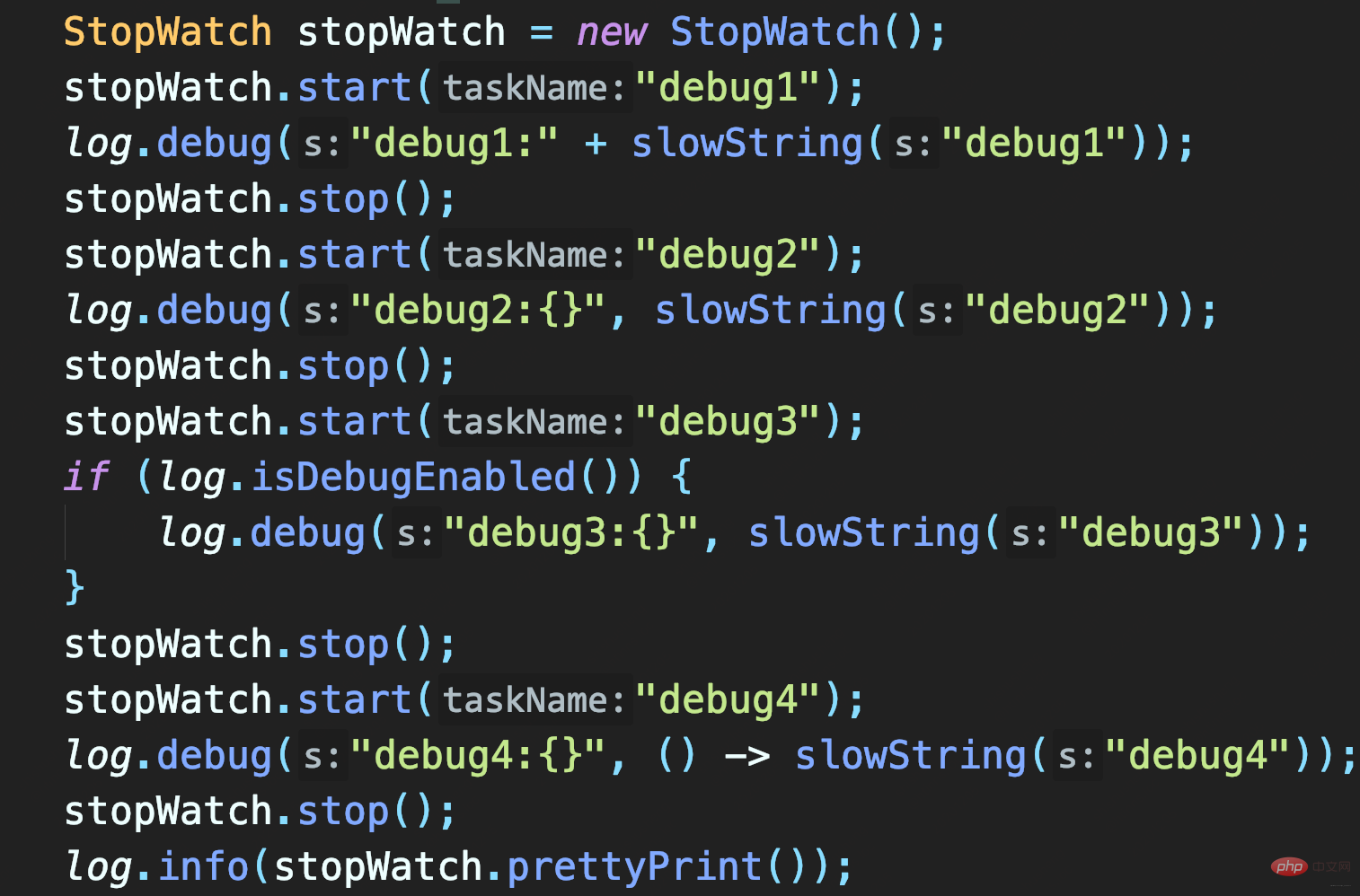
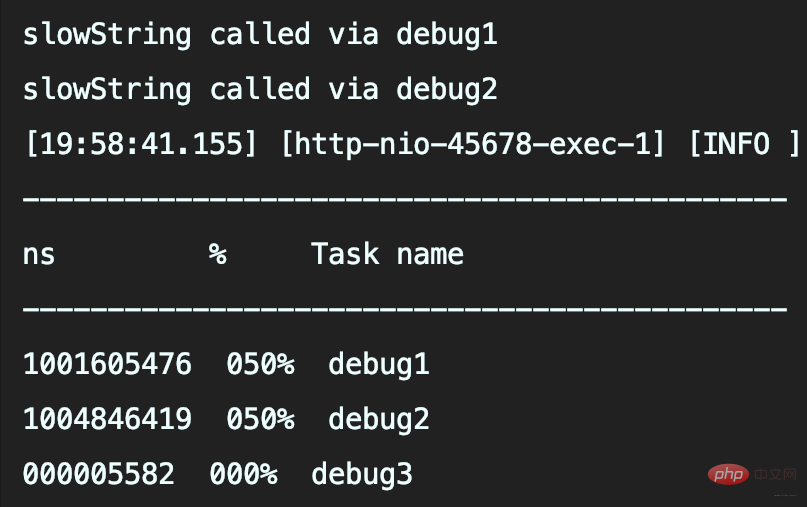
前俩方式都调用slowString,所以都耗时1s。且方式二就是使用占位符记录slowString,这种方式虽允许传Object,不显式拼接String,但也只是延迟(若日志不记录那就是省去)日志参数对象.toString()和字符串拼接的耗时。
本案例除非事先判断日志级别,否则必调用slowString。
所以使用{}占位符不能通过延迟参数值获取,来解决日志数据获取的性能问题。
除事先判断日志级别,还可通过lambda表达式延迟参数内容获取。但SLF4J的API还不支持lambda,因此需使用Log4j2日志API,把Lombok的@Slf4j注解替换为**@Log4j2**注解,即可提供lambda表达式参数的方法: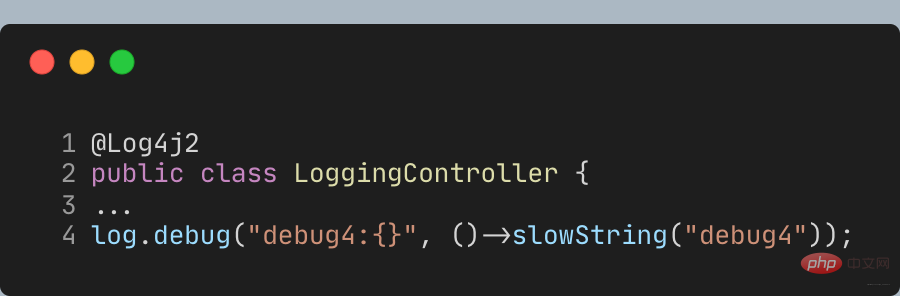
这样调用debug,签名Supplier,参数就会延迟到真正需要记录日志时再获取:



所以debug4并不会调用slowString方法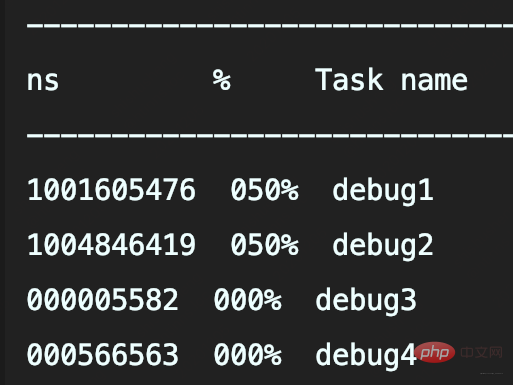
只是换成Log4j2 API,真正的日志记录还是走的Logback,这就是SLF4J适配的好处。
总结
- SLF4J统一了Java日志框架。在使用SLF4J时,要理清楚其桥接API和绑定。若程序启动时出现SLF4J错误提示,那可能是配置问题,可使用Maven的dependency:tree命令梳理依赖关系。
- 异步日志解决性能问题,是用空间换时间。但空间毕竟有限,当空间满,要考虑阻塞等待or丢弃日志。如果更希望不丢弃重要日志,那么选择阻塞等待;如果更希望程序不要因为日志记录而阻塞,那么就需要丢弃日志。
- 日志框架提供的参数化日志记录方式不能完全取代日志级别判断。若你的日志量很大,获取日志参数代价也很大,就要判断日志级别,避免不记录日志也要耗时获取日志参数。
以上是搞懂Java日志级别,重复记录、丢日志问题的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

Atom编辑器mac版下载
最流行的的开源编辑器

禅工作室 13.0.1
功能强大的PHP集成开发环境

