



今天mysql教程栏目介绍join功能。

关于MySQL 的 join,大家一定了解过很多它的“轶事趣闻”,比如两表 join 要小表驱动大表,阿里开发者规范禁止三张表以上的 join 操作,MySQL 的 join 功能弱爆了等等。这些规范或者言论亦真亦假,时对时错,需要大家自己对 join 有深入的了解后才能清楚地理解。
下面,我们就来全面的了解一下 MySQL 的 join 操作。
正文
在日常数据库查询时,我们经常要对多表进行连表操作来一次性获得多个表合并后的数据,这是就要使用到数据库的 join 语法。join 是在数据领域中十分常见的将两个数据集进行合并的操作,如果大家了解的多的话,会发现 MySQL,Oracle,PostgreSQL 和 Spark 都支持该操作。本篇文章的主角是 MySQL,下文没有特别说明的话,就是以 MySQL 的 join 为主语。而 Oracle ,PostgreSQL 和 Spark 则可以算做将其吊打的大boss,其对 join 的算法优化和实现方式都要优于 MySQL。
MySQL 的 join 有诸多规则,可能稍有不慎,可能一个不好的 join 语句不仅会导致对某一张表的全表查询,还有可能会影响数据库的缓存,导致大部分热点数据都被替换出去,拖累整个数据库性能。
所以,业界针对 MySQL 的 join 总结了很多规范或者原则,比如说小表驱动大表和禁止三张表以上的 join 操作。下面我们会依次介绍 MySQL join 的算法,和 Oracle 和 Spark 的 join 实现对比,并在其中穿插解答为什么会形成上述的规范或者原则。
对于 join 操作的实现,大概有 Nested Loop Join (循环嵌套连接),Hash Join(散列连接) 和 Sort Merge Join(排序归并连接) 三种较为常见的算法,它们各有优缺点和适用条件,接下来我们会依次来介绍。
MySQL 中的 Nested Loop Join 实现
Nested Loop Join 是扫描驱动表,每读出一条记录,就根据 join 的关联字段上的索引去被驱动表中查询对应数据。它适用于被连接的数据子集较小的场景,它也是 MySQL join 的唯一算法实现,关于它的细节我们接下来会详细讲解。
MySQL 中有两个 Nested Loop Join 算法的变种,分别是 Index Nested-Loop Join 和 Block Nested-Loop Join。
Index Nested-Loop Join 算法
下面,我们先来初始化一下相关的表结构和数据
CREATE TABLE `t1` (
`id` int(11) NOT NULL,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `a` (`a`)
) ENGINE=InnoDB;
delimiter ;;
# 定义存储过程来初始化t1
create procedure init_data()
begin
declare i int;
set i=1;
while(i<=10000)do
insert into t1 values(i, i, i);
set i=i+1;
end while;
end;;
delimiter ;
# 调用存储过来来初始化t1
call init_data();
# 创建并初始化t2
create table t2 like t1;
insert into t2 (select * from t1 where id<=500)复制代码有上述命令可知,这两个表都有一个主键索引 id 和一个索引 a,字段 b 上无索引。存储过程 init_data 往表 t1 里插入了 10000 行数据,在表 t2 里插入的是 500 行数据。
为了避免 MySQL 优化器会自行选择表作为驱动表,影响分析 SQL 语句的执行过程,我们直接使用 straight_join 来让 MySQL 使用固定的连接表顺序进行查询,如下语句中,t1是驱动表,t2是被驱动表。
select * from t2 straight_join t1 on (t2.a=t1.a);复制代码
使用我们之前文章介绍的 explain 命令查看一下该语句的执行计划。
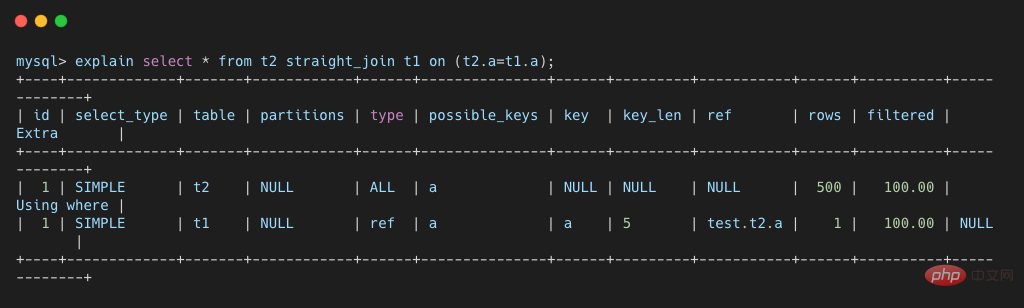
从上图可以看到,t1 表上的 a 字段是由索引的,join 过程中使用了该索引,因此该 SQL 语句的执行流程如下:
- 从 t2 表中读取一行数据 L1;
- 使用L1 的 a 字段,去 t1 表中作为条件进行查询;
- 取出 t1 中满足条件的行, 跟 L1组成相应的行,成为结果集的一部分;
- 重复执行,直到扫描完 t2 表。
这个流程我们就称之为 Index Nested-Loop Join,简称 NLJ,它对应的流程图如下所示。
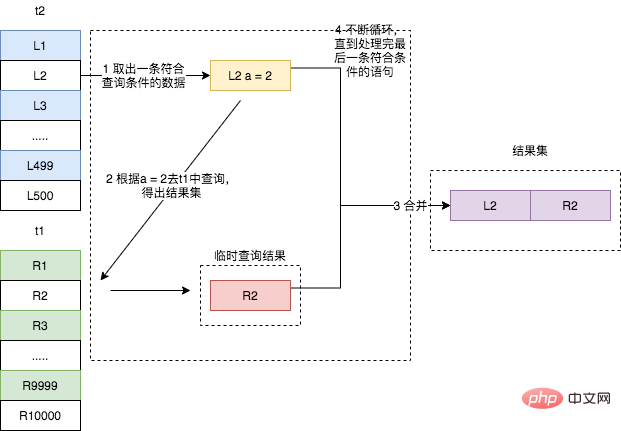
需要注意的是,在第二步中,根据 a 字段去表t1中查询时,使用了索引,所以每次扫描只会扫描一行(从explain结果得出,根据不同的案例场景而变化)。
假设驱动表的行数是N,被驱动表的行数是 M。因为在这个 join 语句执行过程中,驱动表是走全表扫描,而被驱动表则使用了索引,并且驱动表中的每一行数据都要去被驱动表中进行索引查询,所以整个 join 过程的近似复杂度是 N2log2M。显然,N 对扫描行数的影响更大,因此这种情况下应该让小表来做驱动表。
当然,这一切的前提是 join 的关联字段是 a,并且 t1 表的 a 字段上有索引。
如果没有索引时,再用上图的执行流程时,每次到 t1 去匹配的时候,就要做一次全表扫描。这也导致整个过程的时间复杂度编程了 N * M,这是不可接受的。所以,当没有索引时,MySQL 使用 Block Nested-Loop Join 算法。
Block Nested-Loop Join
Block Nested-Loop Join的算法,简称 BNL,它是 MySQL 在被驱动表上无可用索引时使用的 join 算法,其具体流程如下所示:
- 把表 t2 的数据读取当前线程的 join_buffer 中,在本篇文章的示例 SQL 没有在 t2 上做任何条件过滤,所以就是讲 t2 整张表 放入内存中;
- 扫描表 t1,每取出一行数据,就跟 join_buffer 中的数据进行对比,满足 join 条件的,则放入结果集。
比如下面这条 SQL
select * from t2 straight_join t1 on (t2.b=t1.b);复制代码
这条语句的 explain 结果如下所示。可以看出
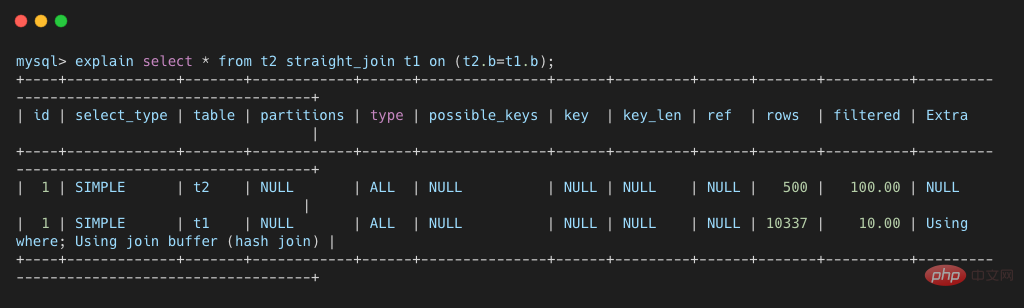
可以看出,这次 join 过程对 t1 和 t2 都做了一次全表扫描,并且将表 t2 中的 500 条数据全部放入内存 join_buffer 中,并且对于表 t1 中的每一行数据,都要去 join_buffer 中遍历一遍,都要做 500 次对比,所以一共要进行 500 * 10000 次内存对比操作,具体流程如下图所示。
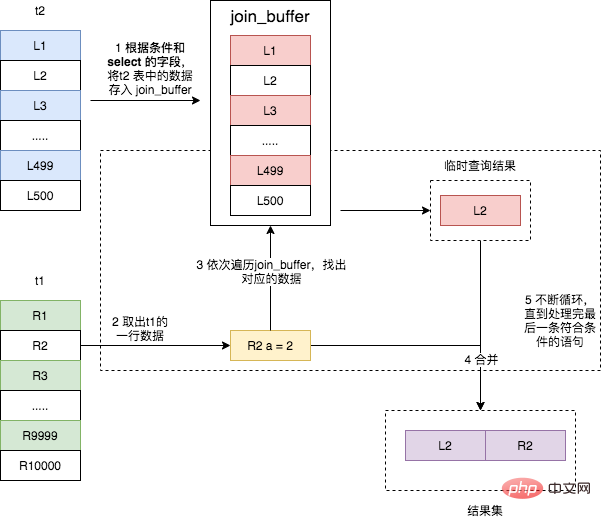
主要注意的是,第一步中,并不是将表 t2 中的所有数据都放入 join_buffer,而是根据具体的 SQL 语句,而放入不同行的数据和不同的字段。比如下面这条 join 语句则只会将表 t2 中符合 b >= 100 的数据的 b 字段存入 join_buffer。
select t2.b,t1.b from t2 straight_join t1 on (t2.b=t1.b) where t2.b >= 100;复制代码
join_buffer 并不是无限大的,由 join_buffer_size 控制,默认值为 256K。当要存入的数据过大时,就只有分段存储了,整个执行过程就变成了:
- 扫描表 t2,将符合条件的数据行存入 join_buffer,因为其大小有限,存到100行时满了,则执行第二步;
- 扫描表 t1,每取出一行数据,就跟 join_buffer 中的数据进行对比,满足 join 条件的,则放入结果集;
- 清空 join_buffer;
- 再次执行第一步,直到全部数据被扫描完,由于 t2 表中有 500行数据,所以一共重复了 5次
这个流程体现了该算法名称中 Block 的由来,分块去执行 join 操作。因为表 t2 的数据被分成了 5 次存入 join_buffer,导致表 t1 要被全表扫描 5次。
| 全部存入 | 分5次存入 | |
|---|---|---|
| 内存操作 | 10000 * 500 | 10000 * (100 + 100 + 100 + 100 + 100) |
| 扫描行数 | 10000 + 500 | 10000 * 5 + 500 |
如上所示,和表数据可以全部存入 join_buffer 相比,内存判断的次数没有变化,都是两张表行数的乘积,也就是 10000 * 500,但是被驱动表会被多次扫描,每多存入一次,被驱动表就要扫描一遍,影响了最终的执行效率。
基于上述两种算法,我们可以得出下面的结论,这也是网上大多数对 MySQL join 语句的规范。
被驱动表上有索引,也就是可以使用Index Nested-Loop Join 算法时,可以使用 join 操作。
无论是Index Nested-Loop Join 算法或者 Block Nested-Loop Join 都要使用小表做驱动表。
因为上述两个 join 算法的时间复杂度至少也和涉及表的行数成一阶关系,并且要花费大量的内存空间,所以阿里开发者规范所说的严格禁止三张表以上的 join 操作也是可以理解的了。
但是上述这两个算法只是 join 的算法之一,还有更加高效的 join 算法,比如 Hash Join 和 Sorted Merged join。可惜这两个算法 MySQL 的主流版本中目前都不提供,而 Oracle ,PostgreSQL 和 Spark 则都支持,这也是网上吐槽 MySQL 弱爆了的原因(MySQL 8.0 版本支持了 Hash join,但是8.0目前还不是主流版本)。
其实阿里开发者规范也是在从 Oracle 迁移到 MySQL 时,因为 MySQL 的 join 操作性能太差而定下的禁止三张表以上的 join 操作规定的 。
Hash Join 算法
Hash Join 是扫描驱动表,利用 join 的关联字段在内存中建立散列表,然后扫描被驱动表,每读出一行数据,并从散列表中找到与之对应数据。它是大数据集连接操时的常用方式,适用于驱动表的数据量较小,可以放入内存的场景,它对于没有索引的大表和并行查询的场景下能够提供最好的性能。可惜它只适用于等值连接的场景,比如 on a.id = where b.a_id。
还是上述两张表 join 的语句,其执行过程如下
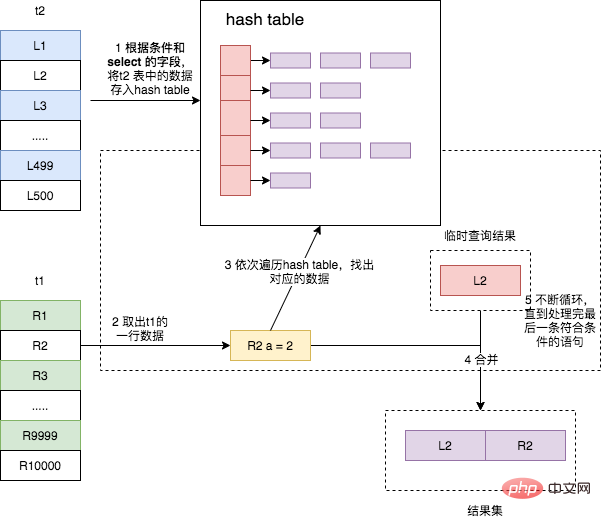
- 将驱动表 t2 中符合条件的数据取出,对其每行的 join 字段值进行 hash 操作,然后存入内存中的散列表中;
- 遍历被驱动表 t1,每取出一行符合条件的数据,也对其 join 字段值进行 hash 操作,拿结果到内存的散列表中查找匹配,如果找到,则成为结果集的一部分。
可以看出,该算法和 Block Nested-Loop Join 有类似之处,只不过是将无序的 Join Buffer 改为了散列表 hash table,从而让数据匹配不再需要将 join buffer 中的数据全部遍历一遍,而是直接通过 hash,以接近 O(1) 的时间复杂度获得匹配的行,这极大地提高了两张表的 join 速度。
不过由于 hash 的特性,该算法只能适用于等值连接的场景,其他的连接场景均无法使用该算法。
Sorted Merge Join 算法
Sort Merge Join 则是先根据 join 的关联字段将两张表排序(如果已经排序好了,比如字段上有索引则不需要再排序),然后在对两张表进行一次归并操作。如果两表已经被排过序,在执行排序合并连接时不需要再排序了,这时Merge Join的性能会优于Hash Join。Merge Join可适于于非等值Join(>,<,>=,<=,但是不包含!=,也即<>)。
需要注意的是,如果连接的字段已经有索引,也就说已经排好序的话,可以直接进行归并操作,但是如果连接的字段没有索引的话,则它的执行过程如下图所示。
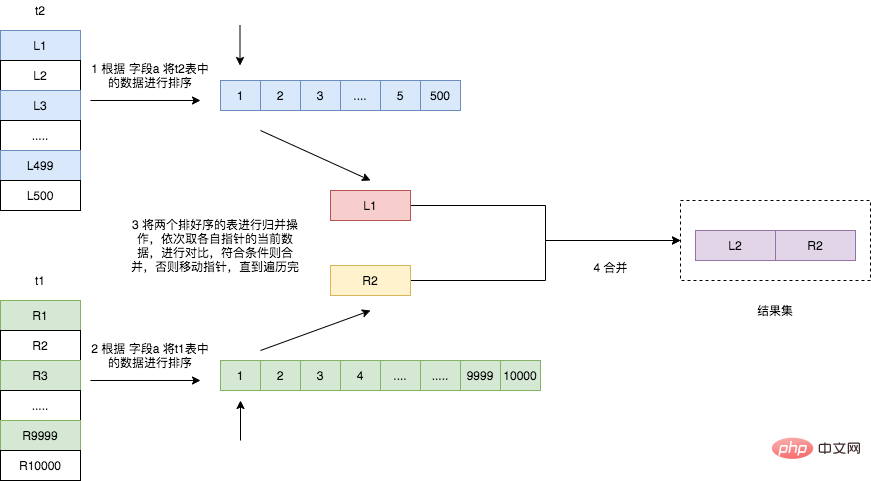
- 遍历表 t2,将符合条件的数据读取出来,按照连接字段 a 的值进行排序;
- 遍历表 t1,将符合条件的数据读取出来,也按照连接字段 a 的值进行排序;
- 将两个排序好的数据进行归并操作,得出结果集。
Sorted Merge Join 算法的主要时间消耗在于对两个表的排序操作,所以如果两个表已经按照连接字段排序过了,该算法甚至比 Hash Join 算法还要快。在一边情况下,该算法是比 Nested Loop Join 算法要快的。
下面,我们来总结一下上述三种算法的区别和优缺点。
| Nested Loop Join | Hash Join | Sorted Merge Join | |
|---|---|---|---|
| 连接条件 | 适用于任何条件 | 只适用于等值连接(=) | 等值或非等值连接(>,<,=,>=,<=),‘<>’除外 |
| 主要消耗资源 | CPU、磁盘I/O | 内存、临时空间 | 内存、临时空间 |
| 特点 | 当有高选择性索引或进行限制性搜索时效率比较高,能够快速返回第一次的搜索结果 | 当缺乏索引或者索引条件模糊时,Hash Join 比 Nested Loop 有效。通常比 Merge Join 快。在数据仓库环境下,如果表的纪录数多,效率高 | 当缺乏索引或者索引条件模糊时,Sort Merge Join 比 Nested Loop 有效。当连接字段有索引或者提前排好序时,比 hash join 快,并且支持更多的连接条件 |
| 缺点 | 无索引或者表记录多时效率低 | 建立哈希表需要大量内存,第一次的结果返回较慢 | 所有的表都需要排序。它为最优化的吞吐量而设计,并且在结果没有全部找到前不返回数据 |
| 需要索引 | 是(没有索引效率太差) | 否 | 否 |
对于 Join 操作的理解
讲完了 Join 相关的算法,我们这里也聊一聊对于 join 操作的业务理解。
在业务不复杂的情况下,大多数join并不是无可替代。比如订单记录里一般只有订单用户的 user_id,返回信息时需要取得用户姓名,可能的实现方案有如下几种:
- 一次数据库操作,使用 join 操作,订单表和用户表进行 join,连同用户名一起返回;
- 两次数据库操作,分两次查询,第一次获得订单信息和 user_id,第二次根据 user_id 取姓名,使用代码程序进行信息合并;
- 使用冗余用户名称或者从 ES 等非关系数据库中读取。
上述方案都能解决数据聚合的问题,而且基于程序代码来处理,比数据库 join 更容易调试和优化,比如取用户姓名不从数据库中取,而是先从缓存中查找。
当然, join 操作也不是一无是处,所以技术都有其使用场景,上边这些方案或者规则都是互联网开发团队总结出来的,适用于高并发、轻写重读、分布式、业务逻辑简单的情况,这些场景一般对数据的一致性要求都不高,甚至允许脏读。
但是,在金融银行或者财务等企业应用场景,join 操作则是不可或缺的,这些应用一般都是低并发、频繁复杂数据写入、CPU密集而非IO密集,主要业务逻辑通过数据库处理甚至包含大量存储过程、对一致性与完整性要求很高的系统。
更多相关免费学习推荐:mysql教程(视频)
以上是MySQL 的 join 功能弱爆了?的详细内容。更多信息请关注PHP中文网其他相关文章!

 图文详解mysql架构原理May 17, 2022 pm 05:54 PM
图文详解mysql架构原理May 17, 2022 pm 05:54 PM本篇文章给大家带来了关于mysql的相关知识,其中主要介绍了关于架构原理的相关内容,MySQL Server架构自顶向下大致可以分网络连接层、服务层、存储引擎层和系统文件层,下面一起来看一下,希望对大家有帮助。
 mysql的msi与zip版本有什么区别May 16, 2022 pm 04:33 PM
mysql的msi与zip版本有什么区别May 16, 2022 pm 04:33 PMmysql的msi与zip版本的区别:1、zip包含的安装程序是一种主动安装,而msi包含的是被installer所用的安装文件以提交请求的方式安装;2、zip是一种数据压缩和文档存储的文件格式,msi是微软格式的安装包。
 mysql怎么去掉第一个字符May 19, 2022 am 10:21 AM
mysql怎么去掉第一个字符May 19, 2022 am 10:21 AM方法:1、利用right函数,语法为“update 表名 set 指定字段 = right(指定字段, length(指定字段)-1)...”;2、利用substring函数,语法为“select substring(指定字段,2)..”。
 mysql怎么替换换行符Apr 18, 2022 pm 03:14 PM
mysql怎么替换换行符Apr 18, 2022 pm 03:14 PM在mysql中,可以利用char()和REPLACE()函数来替换换行符;REPLACE()函数可以用新字符串替换列中的换行符,而换行符可使用“char(13)”来表示,语法为“replace(字段名,char(13),'新字符串') ”。
 mysql怎么将varchar转换为int类型May 12, 2022 pm 04:51 PM
mysql怎么将varchar转换为int类型May 12, 2022 pm 04:51 PM转换方法:1、利用cast函数,语法“select * from 表名 order by cast(字段名 as SIGNED)”;2、利用“select * from 表名 order by CONVERT(字段名,SIGNED)”语句。
 MySQL复制技术之异步复制和半同步复制Apr 25, 2022 pm 07:21 PM
MySQL复制技术之异步复制和半同步复制Apr 25, 2022 pm 07:21 PM本篇文章给大家带来了关于mysql的相关知识,其中主要介绍了关于MySQL复制技术的相关问题,包括了异步复制、半同步复制等等内容,下面一起来看一下,希望对大家有帮助。
 mysql怎么判断是否是数字类型May 16, 2022 am 10:09 AM
mysql怎么判断是否是数字类型May 16, 2022 am 10:09 AM在mysql中,可以利用REGEXP运算符判断数据是否是数字类型,语法为“String REGEXP '[^0-9.]'”;该运算符是正则表达式的缩写,若数据字符中含有数字时,返回的结果是true,反之返回的结果是false。
 带你把MySQL索引吃透了Apr 22, 2022 am 11:48 AM
带你把MySQL索引吃透了Apr 22, 2022 am 11:48 AM本篇文章给大家带来了关于mysql的相关知识,其中主要介绍了mysql高级篇的一些问题,包括了索引是什么、索引底层实现等等问题,下面一起来看一下,希望对大家有帮助。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

