



今天和mysql视频教程栏目一起看看一条更新语句又是怎么一个执行流程。

查询语句的一套执行流程,更新语句也会同样的走一步,下边我们在对照上次文章中的图来简单的看一下:
 " data- style="max-width:90%" data- style="max-width:90%">
" data- style="max-width:90%" data- style="max-width:90%">
首先,在执行语句前要先连接数据库,这是第一步中连接器的工作,前面我们也说过,当一个表有更新的时候,跟这个表有关的查询缓存都会失效,所以我们一般不建议十月查询缓存。
接下来,分析器会经过语法分析和词法分析,知道了这是一条更新语句后,优化器决定要使用哪一个索引,然后执行器负责具体的执行,先找到这一行,然后做更新。
与查询语句更新不同的是,更新流程还涉及两个重要的日志,这个我们在前边的文章中也有专门的介绍,有兴趣的可以找一下上周的文章《MySQL的两个日志系统》,这里就不多做介绍了。
下边通过一个简单的例子来分析一下更新操作的流程。
我们先创建一张表,这个表有主键ID和一个整型字段c:
mysql> create table demo T (ID int primarty ,c int);复制代码
然后将ID=2的这一行的值加1
mysql> update table demo set c = c + 1 where ID = 2;复制代码
接下来我们来看看update语句的执行流程,图中浅色框表示在存储引擎中执行的,神色框代表的是执行器中执行的。
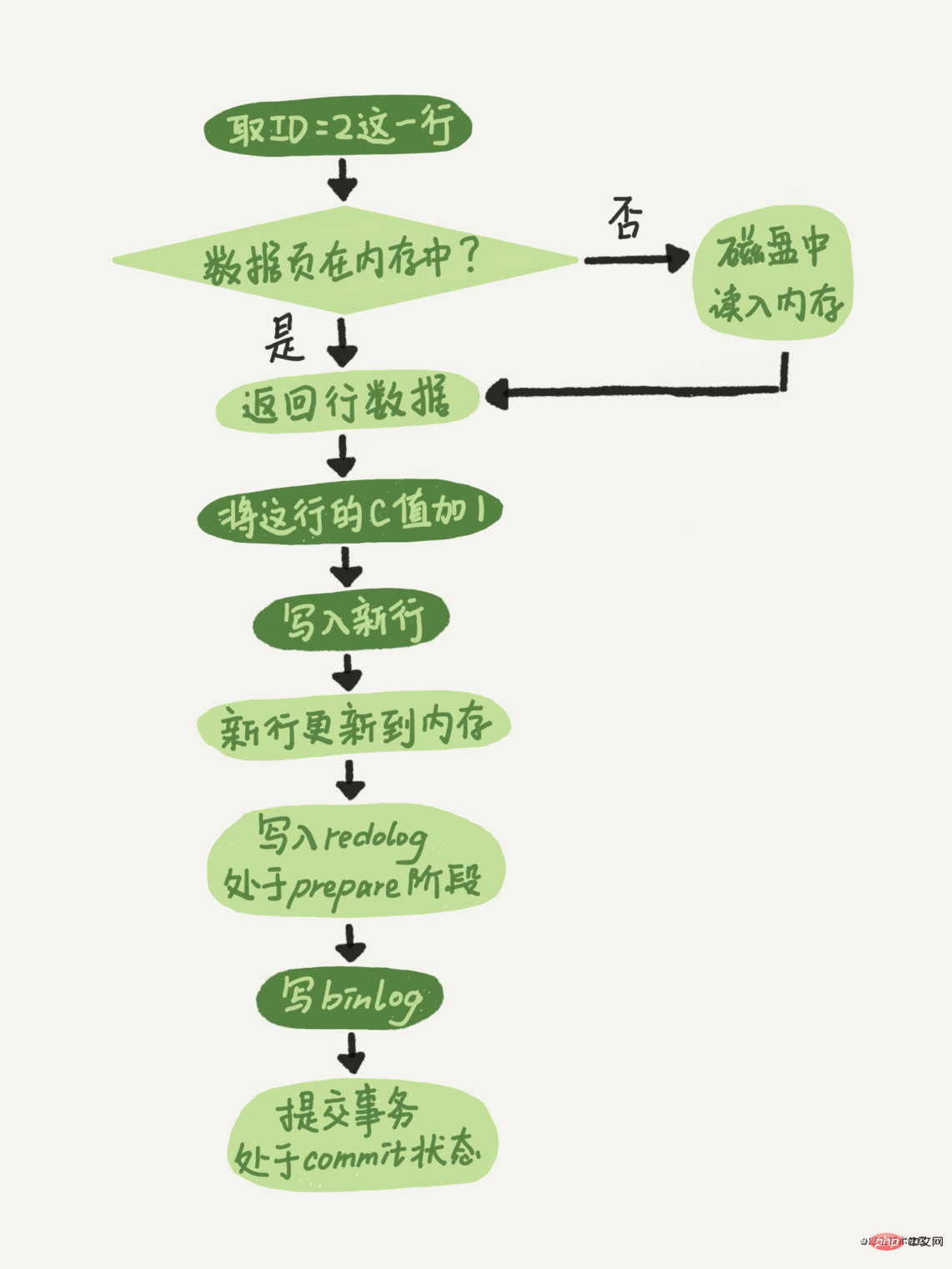
我们可以看到最后的时候,写redolog的时候分了两步,prepare和commit,这就是我们常说的“两阶段提交”。
为什么日志需要“两阶段提交”?
由于redo log和binlog分别是存储引擎和执行器的日志,是两个独立的逻辑,如果不用两阶段提交,无论先提交哪个后提交哪个都会存在一些问题。我们这里也借助上边的例子看一下,假设当前ID=2的这一行值为0 ,在update的过程中写完了第一个日志后,第二个日志还没写期间发生了crash,会怎么样?
- 先写redolog后写binlog。假设redolog写完,binlog还没写完,MySQL进程异常重启了。我们知道,redolog写完以后,系统即使崩溃了,也可以将数据恢复,所以在MySQL重启后,这一行回被恢复成1。由于binlog没写完就crash,这时候binlog里面是没有这个语句的,因此之后备份日志的的时候,存起来的binlog日志也没有这一条语句。当我们需要通过binlog来恢复数据的时候,由于binlog丢失了这条语句,恢复出来的这一行的值就是0,与原库的值不一样啦。
- 先写binlog后写redo log。如果写完buglog之后,redo log还没写完的时候发生 crash,如果这个时候数据库奔溃了,恢复以后这个事务无效,所以这一行的值还是0,但是binlog里已经记载了这条更新语句的日志,在以后需要用binlog来恢复数据的时候,就会多了一个事务出来,执行这条更新语句,将值从0更新成1,与原库中的0就不同了。
我们可以看到如果不使用“两阶段提交",那么数据库的状态就会和用日志恢复出来的库不一致。虽然平时用日志恢复数据的概率比较低,但是用日志最多的还是扩容的时候,用全量备份和binlog来实现的,这个时候就可能导致线上的主从数据库不一致的情况。
相关免费学习推荐:mysql视频教程
以上是SQL在MySQL数据库中是如何执行的的详细内容。更多信息请关注PHP中文网其他相关文章!

 说明InnoDB重做日志和撤消日志的作用。Apr 15, 2025 am 12:16 AM
说明InnoDB重做日志和撤消日志的作用。Apr 15, 2025 am 12:16 AMInnoDB使用redologs和undologs确保数据一致性和可靠性。1.redologs记录数据页修改,确保崩溃恢复和事务持久性。2.undologs记录数据原始值,支持事务回滚和MVCC。
 在解释输出(类型,键,行,额外)中要查找的关键指标是什么?Apr 15, 2025 am 12:15 AM
在解释输出(类型,键,行,额外)中要查找的关键指标是什么?Apr 15, 2025 am 12:15 AMEXPLAIN命令的关键指标包括type、key、rows和Extra。1)type反映查询的访问类型,值越高效率越高,如const优于ALL。2)key显示使用的索引,NULL表示无索引。3)rows预估扫描行数,影响查询性能。4)Extra提供额外信息,如Usingfilesort提示需要优化。
 在解释中使用临时状态以及如何避免它是什么?Apr 15, 2025 am 12:14 AM
在解释中使用临时状态以及如何避免它是什么?Apr 15, 2025 am 12:14 AMUsingtemporary在MySQL查询中表示需要创建临时表,常见于使用DISTINCT、GROUPBY或非索引列的ORDERBY。可以通过优化索引和重写查询避免其出现,提升查询性能。具体来说,Usingtemporary出现在EXPLAIN输出中时,意味着MySQL需要创建临时表来处理查询。这通常发生在以下情况:1)使用DISTINCT或GROUPBY时进行去重或分组;2)ORDERBY包含非索引列时进行排序;3)使用复杂的子查询或联接操作。优化方法包括:1)为ORDERBY和GROUPB
 描述不同的SQL交易隔离级别(读取未读取,读取,可重复的读取,可序列化)及其在MySQL/InnoDB中的含义。Apr 15, 2025 am 12:11 AM
描述不同的SQL交易隔离级别(读取未读取,读取,可重复的读取,可序列化)及其在MySQL/InnoDB中的含义。Apr 15, 2025 am 12:11 AMMySQL/InnoDB支持四种事务隔离级别:ReadUncommitted、ReadCommitted、RepeatableRead和Serializable。1.ReadUncommitted允许读取未提交数据,可能导致脏读。2.ReadCommitted避免脏读,但可能发生不可重复读。3.RepeatableRead是默认级别,避免脏读和不可重复读,但可能发生幻读。4.Serializable避免所有并发问题,但降低并发性。选择合适的隔离级别需平衡数据一致性和性能需求。
 MySQL与其他数据库:比较选项Apr 15, 2025 am 12:08 AM
MySQL与其他数据库:比较选项Apr 15, 2025 am 12:08 AMMySQL适合Web应用和内容管理系统,因其开源、高性能和易用性而受欢迎。1)与PostgreSQL相比,MySQL在简单查询和高并发读操作上表现更好。2)相较Oracle,MySQL因开源和低成本更受中小企业青睐。3)对比MicrosoftSQLServer,MySQL更适合跨平台应用。4)与MongoDB不同,MySQL更适用于结构化数据和事务处理。
 MySQL索引基数如何影响查询性能?Apr 14, 2025 am 12:18 AM
MySQL索引基数如何影响查询性能?Apr 14, 2025 am 12:18 AMMySQL索引基数对查询性能有显着影响:1.高基数索引能更有效地缩小数据范围,提高查询效率;2.低基数索引可能导致全表扫描,降低查询性能;3.在联合索引中,应将高基数列放在前面以优化查询。
 MySQL:新用户的资源和教程Apr 14, 2025 am 12:16 AM
MySQL:新用户的资源和教程Apr 14, 2025 am 12:16 AMMySQL学习路径包括基础知识、核心概念、使用示例和优化技巧。1)了解表、行、列、SQL查询等基础概念。2)学习MySQL的定义、工作原理和优势。3)掌握基本CRUD操作和高级用法,如索引和存储过程。4)熟悉常见错误调试和性能优化建议,如合理使用索引和优化查询。通过这些步骤,你将全面掌握MySQL的使用和优化。
 现实世界Mysql:示例和用例Apr 14, 2025 am 12:15 AM
现实世界Mysql:示例和用例Apr 14, 2025 am 12:15 AMMySQL在现实世界的应用包括基础数据库设计和复杂查询优化。1)基本用法:用于存储和管理用户数据,如插入、查询、更新和删除用户信息。2)高级用法:处理复杂业务逻辑,如电子商务平台的订单和库存管理。3)性能优化:通过合理使用索引、分区表和查询缓存来提升性能。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

Dreamweaver CS6
视觉化网页开发工具

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

