



为什么要优化
系统的吞吐量瓶颈往往出现在数据库的访问速度上,即随着应用程序的运行,数据库的中的数据会越来越多,处理时间会相应变慢,且数据是存放在磁盘上的,读写速度无法和内存相比
如何优化
1、设计数据库时:数据库表、字段的设计,存储引擎
2、利用好MySQL自身提供的功能,如索引,语句写法的调优
3、MySQL集群、分库分表、读写分离
关于SQL语句的优化的方法方式,网络有很多经验,所以本文抛开这些,设法在DAO层的优化和数据库设计优化上建树,并列举两个简单实例
例子1:ERP查询优化
现状分析:
1、缺少关联索引
2、Mysql本身的性能所限,对多个表的关联支持不好,目前的性能主要集中在列表查询上面,列表查询关联了很多表
应对方法:
1 增加必要的索引:通过explain查看执行记录,根据执行计划添加索引;
2 先统计业务数据主表主键,获取较小结果集,然后再利用结果集关联查询;
1) 先根据主表和条件查询显示业务数据的主键
2) 根据主键作为查询条件,再关联其他关联表,查询需要的业务字段
3) 在主表查询时,针对需要关联其他表的查询条件,需要做只有设置这个条件,才会做表关联的设置
例如 有如下表 TT_A TT_B TT_C TT_D 假设未优化前的SQL是这样的 SELECT A.ID, .... B.NAME, ..... C.AGE, .... D.SEX ..... FROM TT_A A LEFT JOIN TT_B B ON A.ID = B.ITEM_ID LEFT JOIN TT_C C ON B.ID = C.ITEM_ID LEFT JOIN TT_D D ON C.ID = D.ITEM_ID WHERE 1=1AND A.XX = ?AND A.VV = ?..... 那么优化后的SQL是 第一步 SELECT A.ID FROM TT_A A WHERE 1=1AND A.XX = ?AND A.VV = ?第二步 SELECT A.ID, .... B.NAME, ..... C.AGE, .... D.SEX ..... FROM ( SELECT A.ID,..... FROM TT_A WHERE ID IN (1,2,3..) ) A LEFT JOIN TT_B B ON A.ID = B.ITEM_ID LEFT JOIN TT_C C ON B.ID = C.ITEM_ID LEFT JOIN TT_D D ON C.ID = D.ITEM_ID WHERE 1=1AND A.XX = ?AND A.VV = ?
小结:
这种优化适用于,列表查询,因为一个列表查询的条件一般都是和主表挂钩的,所以利用这一点,建立关键字段索引,同时通过查询条件的限制大大的缩小主表的数据量。这样关联其他表的时候就会快的多
例子2:文章搜索优化
假设你要做个贴吧的文章搜索功能,最简单直接的存储结构,就是利用关系数据库,创建这样一个存储文章的关系数据库表 TT_ARTICLES:

那么,假如现在的搜索关键字是“目标”,我们就可以利用字符串匹配的方式来对 CONTENT 列进行匹配查询:
select * from ARTICLES where CONTENT like '% 目标 %';
这很容易就实现了搜索功能。但是,这样的方式有着明显的问题,即使用 % 来进行字符串匹配是非常低效的,因此这样的查询需要遍历整个表(全表扫描)。几篇、几十篇文章的时 候,还不是什么问题,但是如果有几十万、几百万的文章,这种方式是完全不可行的。且不说单独的关系数据库表就不能容纳那么大的数据了,就是能够容纳,要扫描一遍,这里的时间代价是难以想象的
于是,我们就要引入“倒排索引”的技术了。在前面所述的场景下, 我们可以把这个概念拆分为两个部分来解释: 好,那上面的 ARTICLES 表依然存在,但现在需要添加一个关键字表 KEYWORDS,并且,KEYWORD 列需要添加索引,因此这条关键字的记录可以被迅速找到:
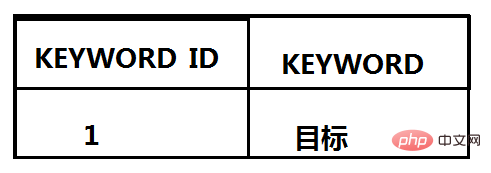
当然,我们还需要一个关联关系表把 KEYWORDS 表和 ARTICLES 表结合起来, KEYWORD_ID 和 ARTICLE_ID 作为联合主键

你看,这其实是一个多对多的关系,即同一个关键字可以出现在多篇文章中,而一篇文章可 以包含多个不同的关键字。这样,我们可以先根据被索引了的关键字,从 KEYWARDS 表 中找到相应的 KEYWORD_ID,进而根据它在上面的关联关系表找到 ARTICLE_ID,再根据 它去 ARTICLES 表中找到对应的文章。
小结:
这看起来是三次查找,但是因为每次都走索引,就免去了全表扫描,在数据量较小的时候速 度并不慢,并且,在使用 SQL 实现的时候,这个过程完全可以放到一个 SQL 语句中。在数 据量较小的时候,上面的方法已经足够好用了。 这样解决了全表扫描和字符串 % 匹配查询造成的性能问题。
总结:
在技术面试的时候,如果你能举出实际的例子,或者是直接说自己开发过程的问题和收获会让面试分会加很多,回答逻辑性也要强一点,不要东一点西一点,容易把自己都绕晕的。例如,问为怎么优化SQL你不要一上来就直接回答加索引,你可以这样回答:
面试官您好,首先我们的项目DB数据量遇到了瓶颈,导致列表查询非常缓慢,给用户的体验不好,为了解决这个问题,有很多种方法,例如最基本的数据库表设计,基本的SQL优化,MYSQL的集群,读写分离,分库分表,架构上增加缓存层等,他们的优缺点……,综合这些然后再结合我们项目特点,最后我们在技术选型的时候选了谁。
如果你这样有条不紊,有理有据的回答了问题而且还说出这么多问题外的知识点,面试官会觉得你不只是一个会写代码的人,而是你逻辑清晰,你对技术选型,有自己的理解和思考
本文来自 SQL教程 栏目,欢迎学习!
以上是SQL查询如何优化?(详解)的详细内容。更多信息请关注PHP中文网其他相关文章!

 SQL和MySQL:数据管理初学者指南Apr 29, 2025 am 12:50 AM
SQL和MySQL:数据管理初学者指南Apr 29, 2025 am 12:50 AMSQL和MySQL的区别在于,SQL是用于管理和操作关系数据库的语言,而MySQL是实现这些操作的开源数据库管理系统。1)SQL允许用户定义、操作和查询数据,通过命令如CREATETABLE、INSERT、SELECT等实现。2)MySQL作为RDBMS,支持这些SQL命令,并提供高性能和可靠性。3)SQL的工作原理基于关系代数,MySQL通过查询优化器和索引等机制优化性能。
 SQL的核心功能:查询和检索信息Apr 28, 2025 am 12:11 AM
SQL的核心功能:查询和检索信息Apr 28, 2025 am 12:11 AMSQL查询的核心功能是通过SELECT语句从数据库中提取、过滤和排序信息。1.基本用法:使用SELECT从表中查询特定列,如SELECTname,departmentFROMemployees。2.高级用法:结合子查询和ORDERBY实现复杂查询,如找出薪水高于平均值的员工并按薪水降序排列。3.调试技巧:检查语法错误,使用小规模数据验证逻辑错误,利用EXPLAIN命令优化性能。4.性能优化:使用索引,避免SELECT*,合理使用子查询和JOIN来提高查询效率。
 SQL:数据库的语言解释了Apr 27, 2025 am 12:14 AM
SQL:数据库的语言解释了Apr 27, 2025 am 12:14 AMSQL是数据库操作的核心工具,用于查询、操作和管理数据库。1)SQL允许执行CRUD操作,包括数据查询、操作、定义和控制。2)SQL的工作原理包括解析、优化和执行三个步骤。3)基本用法包括创建表、插入、查询、更新和删除数据。4)高级用法涵盖JOIN、子查询和窗口函数。5)常见错误包括语法、逻辑和性能问题,可通过数据库错误信息、检查查询逻辑和使用EXPLAIN命令调试。6)性能优化技巧包括创建索引、避免SELECT*和使用JOIN。
 SQL:如何克服学习障碍Apr 26, 2025 am 12:25 AM
SQL:如何克服学习障碍Apr 26, 2025 am 12:25 AM要成为SQL高手,应掌握以下策略:1.了解数据库基础概念,如表、行、列、索引。2.学习SQL的核心概念和工作原理,包括解析、优化和执行过程。3.熟练使用基本和高级SQL操作,如CRUD、复杂查询和窗口函数。4.掌握调试技巧,使用EXPLAIN命令优化查询性能。5.通过实践、利用学习资源、重视性能优化和保持好奇心来克服学习挑战。
 SQL和数据库:完美的合作伙伴关系Apr 25, 2025 am 12:04 AM
SQL和数据库:完美的合作伙伴关系Apr 25, 2025 am 12:04 AMSQL与数据库的关系是紧密结合的,SQL是管理和操作数据库的工具。1.SQL是一种声明式语言,用于数据定义、操作、查询和控制。2.数据库引擎解析SQL语句并执行查询计划。3.基本用法包括创建表、插入和查询数据。4.高级用法涉及复杂查询和子查询。5.常见错误包括语法、逻辑和性能问题,可通过语法检查和EXPLAIN命令调试。6.优化技巧包括使用索引、避免全表扫描和优化查询。
 SQL与MySQL:澄清两者之间的关系Apr 24, 2025 am 12:02 AM
SQL与MySQL:澄清两者之间的关系Apr 24, 2025 am 12:02 AMSQL是一种用于管理关系数据库的标准语言,而MySQL是一个使用SQL的数据库管理系统。SQL定义了与数据库交互的方式,包括CRUD操作,而MySQL实现了SQL标准并提供了额外的功能,如存储过程和触发器。
 SQL的重要性:数字时代的数据管理Apr 23, 2025 am 12:01 AM
SQL的重要性:数字时代的数据管理Apr 23, 2025 am 12:01 AMSQL在数据管理中的作用是通过查询、插入、更新和删除操作来高效处理和分析数据。1.SQL是一种声明式语言,允许用户以结构化方式与数据库对话。2.使用示例包括基本的SELECT查询和高级的JOIN操作。3.常见错误如忘记WHERE子句或误用JOIN,可通过EXPLAIN命令调试。4.性能优化涉及使用索引和遵循最佳实践如代码可读性和可维护性。
 SQL入门:基本概念和技能Apr 22, 2025 am 12:01 AM
SQL入门:基本概念和技能Apr 22, 2025 am 12:01 AMSQL是一种用于管理和操作关系数据库的语言。1.创建表:使用CREATETABLE语句,如CREATETABLEusers(idINTPRIMARYKEY,nameVARCHAR(100),emailVARCHAR(100));2.插入、更新、删除数据:使用INSERTINTO、UPDATE、DELETE语句,如INSERTINTOusers(id,name,email)VALUES(1,'JohnDoe','john@example.com');3.查询数据:使用SELECT语句,如SELEC


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

WebStorm Mac版
好用的JavaScript开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

Dreamweaver Mac版
视觉化网页开发工具

Atom编辑器mac版下载
最流行的的开源编辑器

