



判断问题SQL
判断SQL是否有问题时可以通过两个表象进行判断:
- 系统级别表象
- CPU消耗严重
- IO等待严重
- 页面响应时间过长
- 应用的日志出现超时等错误
可以使用sar命令,top命令查看当前系统状态。

也可以通过Prometheus、Grafana等监控工具观察系统状态。
- SQL语句表象
- 冗长
- 执行时间过长
- 从全表扫描获取数据
- 执行计划中的rows、cost很大
冗长的SQL都好理解,一段SQL太长阅读性肯定会差,而且出现问题的频率肯定会更高。更进一步判断SQL问题就得从执行计划入手,如下所示:

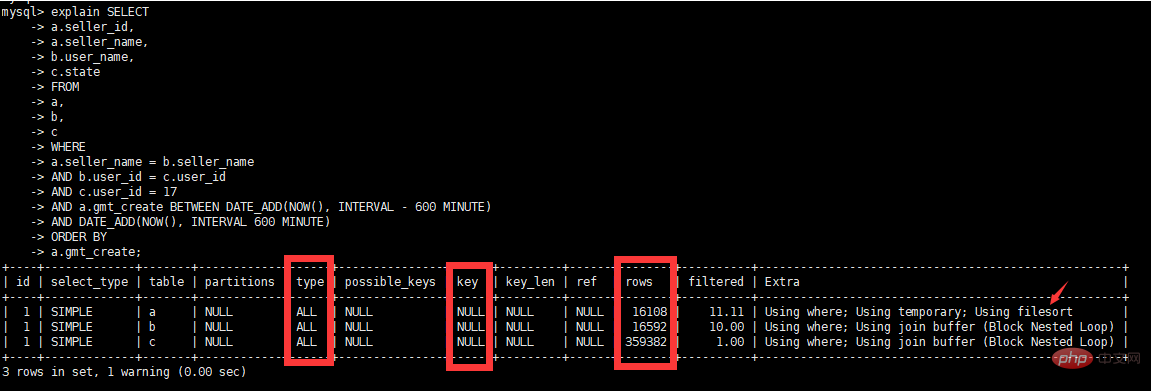
执行计划告诉我们本次查询走了全表扫描Type=ALL,rows很大(9950400)基本可以判断这是一段"有味道"的SQL。
获取问题SQL
不同数据库有不同的获取方法,以下为目前主流数据库的慢查询SQL获取工具
- MySQL
- 慢查询日志
- 测试工具loadrunner
- Percona公司的ptquery等工具
- Oracle
- AWR报告
- 测试工具loadrunner等
- 相关内部视图如v$sql、v$session_wait等
- GRID CONTROL监控工具
- 达梦数据库
- AWR报告
- 测试工具loadrunner等
- 达梦性能监控工具(dem)
- 相关内部视图如v$sql、v$session_wait等
SQL编写技巧
SQL编写有以下几个通用的技巧:
• 合理使用索引
索引少了查询慢;索引多了占用空间大,执行增删改语句的时候需要动态维护索引,影响性能
选择率高(重复值少)且被where频繁引用需要建立B树索引;一般join列需要建立索引;复杂文档类型查询采用全文索引效率更好;索引的建立要在查询和DML性能之间取得平衡;复合索引创建时要注意基于非前导列查询的情况
• 使用UNION ALL替代UNION
UNION ALL的执行效率比UNION高,UNION执行时需要排重;UNION需要对数据进行排序
• 避免select * 写法
执行SQL时优化器需要将 * 转成具体的列;每次查询都要回表,不能走覆盖索引。
• JOIN字段建议建立索引
一般JOIN字段都提前加上索引
• 避免复杂SQL语句
提升可阅读性;避免慢查询的概率;可以转换成多个短查询,用业务端处理
• 避免where 1=1写法
• 避免order by rand()类似写法
RAND()导致数据列被多次扫描
SQL优化 执行计划
完成SQL优化一定要先读执行计划,执行计划会告诉你哪些地方效率低,哪里可以需要优化。我们以MYSQL为例,看看执行计划是什么。(每个数据库的执行计划都不一样,需要自行了解)

| 字段 | 解释 |
|---|---|
| id | 每个被独立执行的操作标识,标识对象被操作的顺序,id值越大,先被执行,如果相同,执行顺序从上到下 |
| select_type | 查询中每个select 字句的类型 |
| table | 被操作的对象名称,通常是表名,但有其他格式 |
| partitions | 匹配的分区信息(对于非分区表值为NULL) |
| type | 连接操作的类型 |
| possible_keys | 可能用到的索引 |
| key | 优化器实际使用的索引(最重要的列) 从最好到最差的连接类型为const、eq_reg、ref、range、index和ALL。当出现ALL时表示当前SQL出现了“坏味道” |
| key_len | 被优化器选定的索引键长度,单位是字节 |
| ref | 表示本行被操作对象的参照对象,无参照对象为NULL |
| rows | 查询执行所扫描的元组个数(对于innodb,此值为估计值) |
| filtered | 条件表上数据被过滤的元组个数百分比 |
| extra | 执行计划的重要补充信息,当此列出现Using filesort , Using temporary 字样时就要小心了,很可能SQL语句需要优化 |
接下来我们用一段实际优化案例来说明SQL优化的过程及优化技巧。
优化案例
表结构
CREATE TABLE `a` ( `id` int(11) NOT NULLAUTO_INCREMENT, `seller_id` bigint(20) DEFAULT NULL, `seller_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL, `gmt_create` varchar(30) DEFAULT NULL, PRIMARY KEY (`id`) ); CREATE TABLE `b` ( `id` int(11) NOT NULLAUTO_INCREMENT, `seller_name` varchar(100) DEFAULT NULL, `user_id` varchar(50) DEFAULT NULL, `user_name` varchar(100) DEFAULT NULL, `sales` bigint(20) DEFAULT NULL, `gmt_create` varchar(30) DEFAULT NULL, PRIMARY KEY (`id`) ); CREATE TABLE `c` ( `id` int(11) NOT NULLAUTO_INCREMENT, `user_id` varchar(50) DEFAULT NULL, `order_id` varchar(100) DEFAULT NULL, `state` bigint(20) DEFAULT NULL, `gmt_create` varchar(30) DEFAULT NULL, PRIMARY KEY (`id`) );
三张表关联,查询当前用户在当前时间前后10个小时的订单情况,并根据订单创建时间升序排列,具体SQL如下
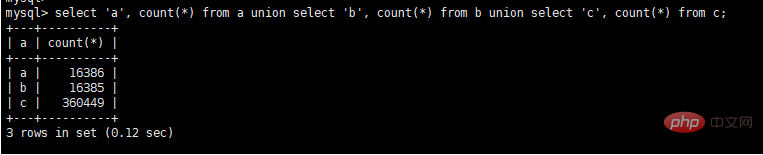
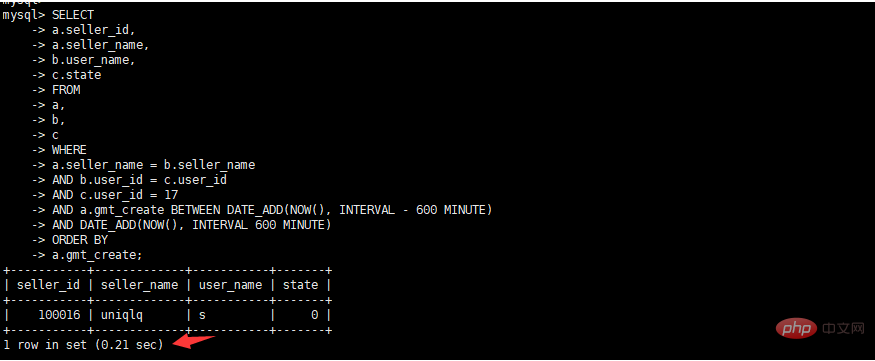
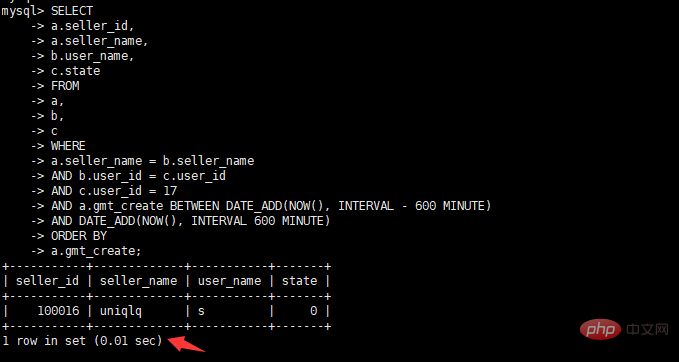
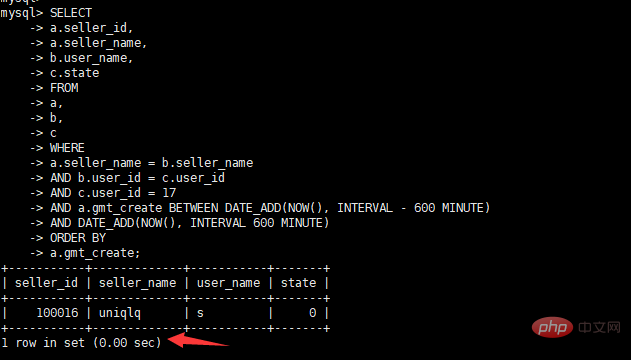
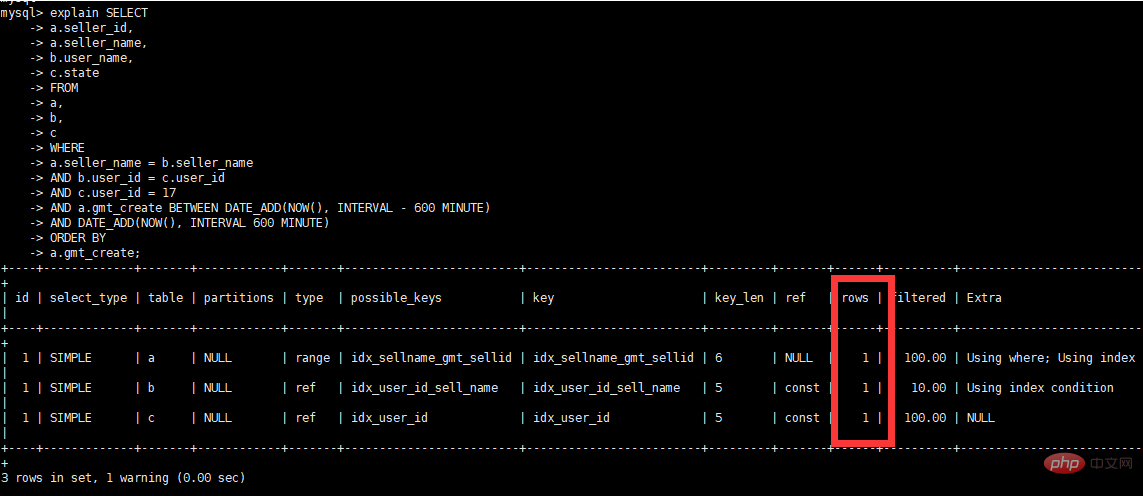
select a.seller_id, a.seller_name, b.user_name, c.state from a, b, c where a.seller_name = b.seller_name and b.user_id = c.user_id and c.user_id = 17 and a.gmt_create BETWEEN DATE_ADD(NOW(), INTERVAL – 600 MINUTE) AND DATE_ADD(NOW(), INTERVAL 600 MINUTE) order by a.gmt_create
-
查看数据量

-
原执行时间
-
原执行计划
初步优化思路
SQL中 where条件字段类型要跟表结构一致,表中
user_id为varchar(50)类型,实际SQL用的int类型,存在隐式转换,也未添加索引。将b和c表user_id字段改成int类型。因存在b表和c表关联,将b和c表
user_id创建索引因存在a表和b表关联,将a和b表
seller_name字段创建索引利用复合索引消除临时表和排序
初步优化SQL
alter table b modify `user_id` int(10) DEFAULT NULL; alter table c modify `user_id` int(10) DEFAULT NULL; alter table c add index `idx_user_id`(`user_id`); alter table b add index `idx_user_id_sell_name`(`user_id`,`seller_name`); alter table a add index `idx_sellname_gmt_sellid`(`gmt_create`,`seller_name`,`seller_id`);
-
查看优化后执行时间
-
查看优化后执行计划
-
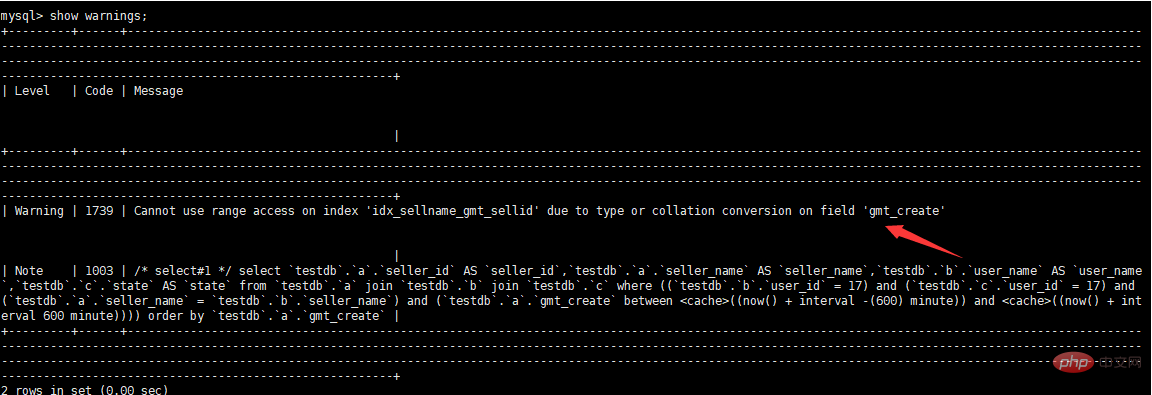
查看warnings信息
继续优化
alter table a modify "gmt_create" datetime DEFAULT NULL
查看执行时间
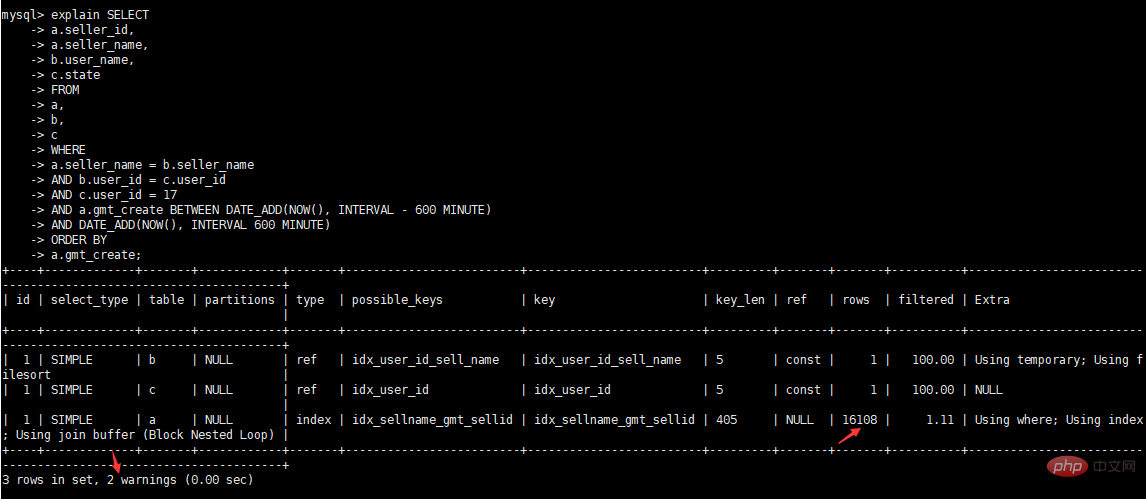
查看执行计划
优化总结
- 查看执行计划 explain
- 如果有告警信息,查看告警信息 show warnings;
- 查看SQL涉及的表结构和索引信息
- 根据执行计划,思考可能的优化点
- 按照可能的优化点执行表结构变更、增加索引、SQL改写等操作
- 查看优化后的执行时间和执行计划
如果优化效果不明显,重复第四步操作
推荐 《mysql视频教程》
以上是MySQL数据库SQL语句优化的详细内容。更多信息请关注PHP中文网其他相关文章!

 图文详解mysql架构原理May 17, 2022 pm 05:54 PM
图文详解mysql架构原理May 17, 2022 pm 05:54 PM本篇文章给大家带来了关于mysql的相关知识,其中主要介绍了关于架构原理的相关内容,MySQL Server架构自顶向下大致可以分网络连接层、服务层、存储引擎层和系统文件层,下面一起来看一下,希望对大家有帮助。
 mysql的msi与zip版本有什么区别May 16, 2022 pm 04:33 PM
mysql的msi与zip版本有什么区别May 16, 2022 pm 04:33 PMmysql的msi与zip版本的区别:1、zip包含的安装程序是一种主动安装,而msi包含的是被installer所用的安装文件以提交请求的方式安装;2、zip是一种数据压缩和文档存储的文件格式,msi是微软格式的安装包。
 mysql怎么去掉第一个字符May 19, 2022 am 10:21 AM
mysql怎么去掉第一个字符May 19, 2022 am 10:21 AM方法:1、利用right函数,语法为“update 表名 set 指定字段 = right(指定字段, length(指定字段)-1)...”;2、利用substring函数,语法为“select substring(指定字段,2)..”。
 mysql怎么替换换行符Apr 18, 2022 pm 03:14 PM
mysql怎么替换换行符Apr 18, 2022 pm 03:14 PM在mysql中,可以利用char()和REPLACE()函数来替换换行符;REPLACE()函数可以用新字符串替换列中的换行符,而换行符可使用“char(13)”来表示,语法为“replace(字段名,char(13),'新字符串') ”。
 MySQL复制技术之异步复制和半同步复制Apr 25, 2022 pm 07:21 PM
MySQL复制技术之异步复制和半同步复制Apr 25, 2022 pm 07:21 PM本篇文章给大家带来了关于mysql的相关知识,其中主要介绍了关于MySQL复制技术的相关问题,包括了异步复制、半同步复制等等内容,下面一起来看一下,希望对大家有帮助。
 mysql怎么将varchar转换为int类型May 12, 2022 pm 04:51 PM
mysql怎么将varchar转换为int类型May 12, 2022 pm 04:51 PM转换方法:1、利用cast函数,语法“select * from 表名 order by cast(字段名 as SIGNED)”;2、利用“select * from 表名 order by CONVERT(字段名,SIGNED)”语句。
 mysql怎么判断是否是数字类型May 16, 2022 am 10:09 AM
mysql怎么判断是否是数字类型May 16, 2022 am 10:09 AM在mysql中,可以利用REGEXP运算符判断数据是否是数字类型,语法为“String REGEXP '[^0-9.]'”;该运算符是正则表达式的缩写,若数据字符中含有数字时,返回的结果是true,反之返回的结果是false。
 mysql怎么删除unique keyMay 12, 2022 pm 03:01 PM
mysql怎么删除unique keyMay 12, 2022 pm 03:01 PM在mysql中,可利用“ALTER TABLE 表名 DROP INDEX unique key名”语句来删除unique key;ALTER TABLE语句用于对数据进行添加、删除或修改操作,DROP INDEX语句用于表示删除约束操作。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

MinGW - 适用于 Windows 的极简 GNU
这个项目正在迁移到osdn.net/projects/mingw的过程中,你可以继续在那里关注我们。MinGW:GNU编译器集合(GCC)的本地Windows移植版本,可自由分发的导入库和用于构建本地Windows应用程序的头文件;包括对MSVC运行时的扩展,以支持C99功能。MinGW的所有软件都可以在64位Windows平台上运行。

SublimeText3汉化版
中文版,非常好用

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

