
boosting和bootstrap区别

- (*-*)浩原创
- 2019-07-12 09:46:233342浏览
bootstrap、boosting是机器学习中几种常用的重采样方法。其中bootstrap重采样方法主要用于统计量的估计,boosting方法则主要用于多个子分类器的组合。

bootstrap:估计统计量的重采样方法(推荐学习:Python视频教程)
bootstrap方法是从大小为n的原始训练数据集DD中随机选择n个样本点组成一个新的训练集,这个选择过程独立重复B次,然后用这B个数据集对模型统计量进行估计(如均值、方差等)。由于原始数据集的大小就是n,所以这B个新的训练集中不可避免的会存在重复的样本。
统计量的估计值定义为独立的B个训练集上的估计值θbθb的平均:
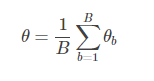
boosting:
boosting依次训练k个子分类器,最终的分类结果由这些子分类器投票决定。
首先从大小为n的原始训练数据集中随机选取n1n1个样本训练出第一个分类器,记为C1C1,然后构造第二个分类器C2C2的训练集D2D2,要求:D2D2中一半样本能被C1C1正确分类,而另一半样本被C1C1错分。
接着继续构造第三个分类器C3C3的训练集D3D3,要求:C1C1、C2C2对D3D3中样本的分类结果不同。剩余的子分类器按照类似的思路进行训练。
boosting构造新训练集的主要原则是使用最富信息的样本。
更多Python相关技术文章,请访问Python教程栏目进行学习!
以上是boosting和bootstrap区别的详细内容。更多信息请关注PHP中文网其他相关文章!
声明:
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系admin@php.cn
上一篇:python库是什么意思下一篇:python怎么学