



本篇文章给大家带来的内容是关于如何用java实现一个p2p种子搜索的功能,有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。
很多年前对p2p就有很大的兴趣,不过都是停留在理论上,一直没有机会去真正的实践。最近把这个东西实现了一下,从刚开始入手到现在,我觉得有些东西可以分享一下。进入正题吧那就
基本概念
再讲p2p之前,我想先讲一下我们是如何进行下载文件的。我列举一下几种文件下载的方式
1.使用http协议下载,使用的最多的可能就是通过浏览器进行文件的下载。
2.使用ftp下载,ftp有两种模式,一种是port(主动)模式,这种模式客户端会在本地开启一个端口N(>1023)建立ftp连接,然后发送给ftp服务器N+1监听端口用来数据传输,当有防火墙或者客户端被nat的情况下就无法下载。另外一种方式是被动模式(passive),这种模式ftp服务端除了21端口以外会开启一个另外大于1023的端口,也就是说客户端会主动发起ftp连接和数据传输连接,只要ftp服务器开放了这个端口那就不会有问题。
上面两种方式可以统称为cs架构,这种架构下面,资源都集中在服务端,当数据量大到一定程度的时候就会出现问题。为了解决这个问题,我们可能会想到分布式去中心化,于是p2p应运而生,p2p即 peer to peer,这是一种对等架构,每个节点既是客服端又是服务端。
p2p架构
当把资源都存储在每个节点上面的时候,我们可能会想,当我下载一个资源的时候 ,那我怎么知道这个文件在那些机器上面能下载呢?
早期的p2p架构中存在一个tracker的角色,这个tracker负责存储文件的元数据信息。那么现在文件会保存在每个peer上面,然后通过tracker获取文件信息。
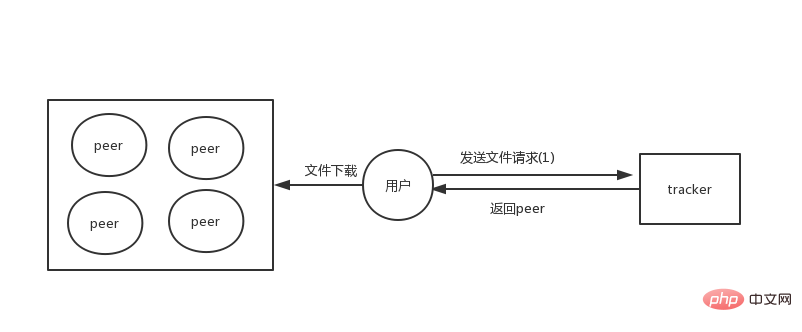
这种架构下面我们所有的文件都分布式了,只是tracker会负责存储所有文件的元数据信息,所以tracker只需要存储少量数据,相对于存在文件会相对轻松很多了。
但是一旦出现tracker服务器挂了或者服务不可用那么就会导致所有的文件都无法下载,因为它还没有完全的分布式,为了完全的去中心化,后面出来一种trackerless架构,
这个时候不在存在tracker这个东西,所有的文件包括文件的元数据信息都分布式存储。
DHT
DHT(Distributed Hash Table)分布式哈希表,它是用来代替tracker。实现dht的算法有很多,比如Kademlia算法等等。
几个概念:
1.nodeid 在dht网络中每个nodeid都是160bit
2.XOR 两个节点之间的距离使用异或来计算
3.routting table路由表
这里的话还是主要讲实现所以原理这部分的话 网上也有很多资料 大家可以参考看看
如何实现
实现种子搜索分为两步,第一步是爬虫,用来爬取网上的种子信息,第二步是加入搜索。
需要具备以下知识:种子,bittorrent dht 协议,bencoded
提到p2p不得不提种子,就是那种.torrent结果的那种文件,大家可能都是用过bt种子下载过文件,下载文件使用的是bittorrent协议。那么如何收集网络上面的种子呢?
bt种子包含的主要字段:戳:https://segmentfault.com/a/1190000000681331
在dht中获取的种子叫trackerless torrent,没有announce这个属性,但是会有nodes属性来代替。官方建议不要router.bittorrent.com把这个添加到种子里面,也不要添加到路由表。
1.如何从dht中获取种子
如果想要得到种子信息,那么必须要对DHT Protocol深入了解,bep_0005描述了DHT Protocol
具体可以戳这里 http://www.bittorrent.org/beps/bep_0005.html
如何实现一个路由表:
路由表覆盖了所有Node的id,从0到2的160次方。路由表可以由bucket组成,每个bucket覆盖了所有node的一部分。
刚开始一个路由表只有一个bucket,覆盖了所有的nodeid。每个bucket,只能hold最多K个nodes,当前这个K值是8。如果bucket已经满了,并且里面的node都是好的,而且自身的nodeid不在这个bucket里面,那么就讲原来的bucket分成两个新的bucket,分别覆盖0..2159和2159..2160。
当一个bucket已经满了的时候,新node很容易被丢弃,如果这里面的node掉线了,那么就会被replace。如果一个节点最近15分钟都没有ping过,那么就对这个节点发起ping,如果没有返回response,那么这个节点也会被replace。
每一个bucket应该有一个last changed属性,用来表明这个bucket的活跃度。这几种情况会更新这个字段:
1.bucket里面的node被ping了并且有response
2.一个node添加到了这个bucket里面
3.bucket里面的node被replace了
bucket在15分钟之内没有更新这个字段的话 ,那么就会随机选取一个在该bucket范围内的id,做find_node操作。
KRPC Protocol
dht网络中通过KRPC Protocol来传递消息。
1.ping
ping查询主要用来心跳检查
2.find_node
查找一个节点,对方会从自己的路由表中查询最近的N个节点返回,一般是8个
3.get_peers
根据infohash查找拥有该infohash的peer,如果查到到返回peers,没有查找到返回nodes
4.announce_peer
告诉其他的peers,自己也拥有infohash。
注意以上四个都会刷新路由表
一开始路由表里面没有任何节点,所以需要从超级节点(例如dht.transmissionbt.com等等)通过find_node请求来查找并添加节点,返回的节点在进行find_node。
我自己实现的路由表稍微和上面描述的不太一样。
dht网络中采用udp进行数据传输,所以我只用开启一个upd端口不断的发送find_node请求建立路由表,然后通过get_peers和announce_peer来获取种子的infohash。
当我们加入dht网络后,通过上面介绍的四个方法只能得到种子文件的infohash,所以我们还需要通过infohash来下载种子,具体可以参照bep_009http://www.bittorrent.org/beps/bep_0009.html
我们主要通过bep_009来获取种子的名字字段,获取了文件名字段就可以根据名字和infohash来建立索引提供搜索。(这里主要构建磁力链接,有了磁力链接就可以去迅雷,百度网盘等去下载资源啦)
大部分磁力链接格式:magnet:?xt=urn:btih:infohash
上面介绍的方式是通过获取infohash来构建磁力链接,再借助第三方软件下载,当然也可以自己通过BitTorrent Protocol来下载,有兴趣的可以自行研究。
好了,上面只是简单的介绍了一些实现的步骤,很多细节和具体实现的话没有提到,我自己的话,参考了一些github dht的项目,然后自己实现了一下具体地址如下:https://github.com/mistletoe9527/dht-spider
以上是如何用java实现一个p2p种子搜索的功能的详细内容。更多信息请关注PHP中文网其他相关文章!

 如何将Maven或Gradle用于高级Java项目管理,构建自动化和依赖性解决方案?Mar 17, 2025 pm 05:46 PM
如何将Maven或Gradle用于高级Java项目管理,构建自动化和依赖性解决方案?Mar 17, 2025 pm 05:46 PM本文讨论了使用Maven和Gradle进行Java项目管理,构建自动化和依赖性解决方案,以比较其方法和优化策略。
 如何使用适当的版本控制和依赖项管理创建和使用自定义Java库(JAR文件)?Mar 17, 2025 pm 05:45 PM
如何使用适当的版本控制和依赖项管理创建和使用自定义Java库(JAR文件)?Mar 17, 2025 pm 05:45 PM本文使用Maven和Gradle之类的工具讨论了具有适当的版本控制和依赖关系管理的自定义Java库(JAR文件)的创建和使用。
 如何使用咖啡因或Guava Cache等库在Java应用程序中实现多层缓存?Mar 17, 2025 pm 05:44 PM
如何使用咖啡因或Guava Cache等库在Java应用程序中实现多层缓存?Mar 17, 2025 pm 05:44 PM本文讨论了使用咖啡因和Guava缓存在Java中实施多层缓存以提高应用程序性能。它涵盖设置,集成和绩效优势,以及配置和驱逐政策管理最佳PRA
 如何将JPA(Java持久性API)用于具有高级功能(例如缓存和懒惰加载)的对象相关映射?Mar 17, 2025 pm 05:43 PM
如何将JPA(Java持久性API)用于具有高级功能(例如缓存和懒惰加载)的对象相关映射?Mar 17, 2025 pm 05:43 PM本文讨论了使用JPA进行对象相关映射,并具有高级功能,例如缓存和懒惰加载。它涵盖了设置,实体映射和优化性能的最佳实践,同时突出潜在的陷阱。[159个字符]
 Java的类负载机制如何起作用,包括不同的类载荷及其委托模型?Mar 17, 2025 pm 05:35 PM
Java的类负载机制如何起作用,包括不同的类载荷及其委托模型?Mar 17, 2025 pm 05:35 PMJava的类上载涉及使用带有引导,扩展程序和应用程序类负载器的分层系统加载,链接和初始化类。父代授权模型确保首先加载核心类别,从而影响自定义类LOA


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

Dreamweaver Mac版
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

SublimeText3 Linux新版
SublimeText3 Linux最新版

WebStorm Mac版
好用的JavaScript开发工具

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

