
Java如何获取http和https网址对应html数据(附代码)

- 不言转载
- 2018-10-11 15:11:314242浏览
本篇文章给大家带来的内容是关于Java如何获取http和https网址对应html数据(附代码),有一定的参考价值,有需要的朋友可以参考一下,希望对你有所帮助。
由于之前在公司一直用的C#做的软件开发,近些天有同学需要用Java做一个从指定网址获取信息的Java程序。正好不是很难,顺便复习了一下Java的知识。
要求如下,在https://www.marinetraffic.com/en/ais/details/ships/shipid:650235/mmsi:414726000/vessel:YU%20MING网址中得到如下图框中标记的数据。
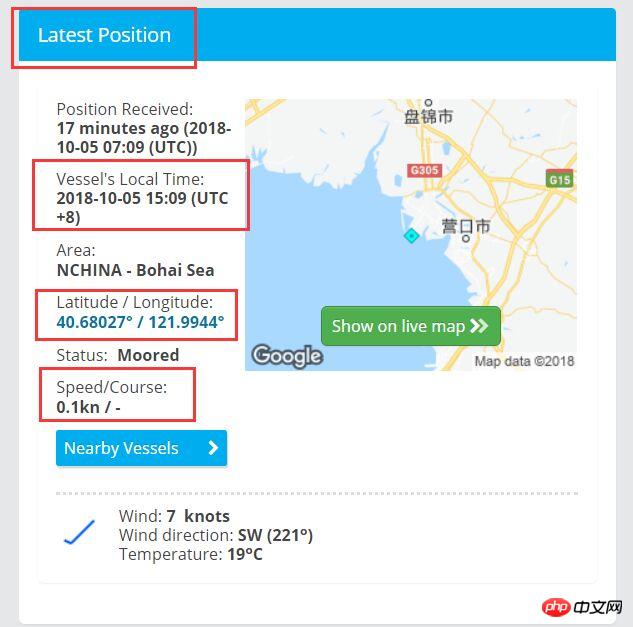
程序如下:GetWebPosition类是主要程序类
package yinhang.wang;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import javax.net.ssl.HttpsURLConnection;
import javax.net.ssl.SSLContext;
import javax.net.ssl.SSLSocketFactory;
import javax.net.ssl.TrustManager;
public class GetWebPosition {
/**
* @param args
*/
public static void main(String[] args) {
// TODO Auto-generated method stub
String info = GetDataByTwo();
System.out.println(info);
}
// 从指定的url中获取数据
//https://www.marinetraffic.com/en/ais/details/ships/shipid:650235/mmsi:414726000/vessel:YU%20MING
private static String HttpRequest(String requestUrl) {
StringBuffer buffer = null;
BufferedReader bufferedReader = null;
InputStreamReader inputStreamReader = null;
InputStream inputStream = null;
HttpsURLConnection httpUrlConn = null;
// 建立并向网页发送请求
try {
TrustManager[] tm = { new MyX509TrustManager() };
SSLContext sslContext = SSLContext.getInstance("SSL", "SunJSSE");
sslContext.init(null, tm, new java.security.SecureRandom());
// 从上述SSLContext对象中得到SSLSocketFactory对象
SSLSocketFactory ssf = sslContext.getSocketFactory();
URL url = new URL(requestUrl);
// 描述状态
httpUrlConn = (HttpsURLConnection) url.openConnection();
httpUrlConn.setSSLSocketFactory(ssf);
httpUrlConn
.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36)");
//防止报403错误。
httpUrlConn.setDoOutput(true);
httpUrlConn.setDoInput(true);
httpUrlConn.setUseCaches(false);
// 请求的类型
httpUrlConn.setRequestMethod("GET");
// 获取输入流
inputStream = httpUrlConn.getInputStream();
inputStreamReader = new InputStreamReader(inputStream, "utf-8");
bufferedReader = new BufferedReader(inputStreamReader);
// 从输入流读取结果
buffer = new StringBuffer();
String str = null;
while ((str = bufferedReader.readLine()) != null) {
buffer.append(str);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// 释放资源
if (bufferedReader != null) {
try {
bufferedReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (inputStreamReader != null) {
try {
inputStreamReader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (inputStream != null) {
try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (httpUrlConn != null) {
httpUrlConn.disconnect();
}
}
return buffer.toString();
} private static String HtmlFiter(String html) {
StringBuffer buffer = new StringBuffer();
String str1 = "";
String str2 = "";
//取出所用的范围,
//Pattern p = Pattern.compile("(.*)(<p class=\"panel panel-primary
no-border vertical-offset-20\">)(.*)(</p>)(.*)");
Pattern p = Pattern.compile("(.*)(</script>)(.*)(<p class=\"wind_icon wind_low\")(.*)");
Matcher m = p.matcher(html);
if (m.matches()) {
str1 = m.group(3);
//取得时间:Vessel's Local Time:
p = Pattern.compile("(.*)(time datetime=\")(.*)(\">)(.*)(</time>)(.*)(</span></strong>)(.*)");
m = p.matcher(str1);
if (m.matches()) {
str2 = m.group(5);
String str3 = m.group(7);
buffer.append("\nVessel's Local Time: ");
buffer.append(str2);
buffer.append(str3);
}
// <a href="/en/ais/home/centerx:120.3903/centery:32.02979/zoom:10/mmsi:414726000/shipid:650235"
// class="details_data_link">32.02979° / 120.3903°</a>
//取得当前经纬度:Latitude / Longitude:
p = Pattern.compile("(.*)(class=\"details_data_link\">)(.*)(</a></strong></span>)(.*)");
m = p.matcher(str1);
if (m.matches()) {
str2 = m.group(3);
buffer.append("\nLatitude / Longitude: ");
buffer.append(str2);
}
//取得当前速度航线Speed/Course:
p = Pattern.compile("(.*)(<span><strong>)(.*)(</strong></span>)(.*)");
m = p.matcher(str1);
if (m.matches()) {
str2 = m.group(3);
buffer.append("\nSpeed/Course: ");
buffer.append(str2);
}
}
return buffer.toString();
}
//封裝上述两个方法
public static String GetDataByTwo(){
//调用第一个方法,获得html字符串
String html =
HttpRequest("https://www.marinetraffic.com/en/ais/details/ships/shipid:650235/mmsi:414726000/vessel:YU%20MING");
//调用第二个方法,过滤掉无用的信息
String result = HtmlFiter(html);
return result;
}
}MyX509TrustManager这个类的作用是提供安全证书去访问https类型的网站
package yinhang.wang;
import java.security.cert.CertificateException;
import java.security.cert.X509Certificate;
import javax.net.ssl.X509TrustManager;
public class MyX509TrustManager implements X509TrustManager {
public void checkClientTrusted(X509Certificate[] chain, String authType)
throws CertificateException
{
}
public void checkServerTrusted(X509Certificate[] chain, String authType)
throws CertificateException
{
}
public X509Certificate[] getAcceptedIssuers()
{
return null;
}
}希望初步学习正则表达式和爬数据的小伙伴们能够用到。
以上是Java如何获取http和https网址对应html数据(附代码)的详细内容。更多信息请关注PHP中文网其他相关文章!
声明:
本文转载于:cnblogs.com。如有侵权,请联系admin@php.cn删除