



一.分布式架构的发展历史
1946年,世界上第一台电子计算机在美国的宾夕法尼亚大学诞生,它的名字是:ENICAC ,这台计算机的体重比较大,计算速度也不快,但是而代表了计算机时代的到来,再以后的互联网的发展中也有基础性的意义。
计算机的组成是有五部分完成的,分别是:输入设备,输出设备,存储器,存储器里面由运算器和控制器,有一个冯诺依曼的模型非常形象的对象计算机的组成进行了描述,不过计算机也是有数据流,指令流,控制流来进行计算的和正常运转的。如图:
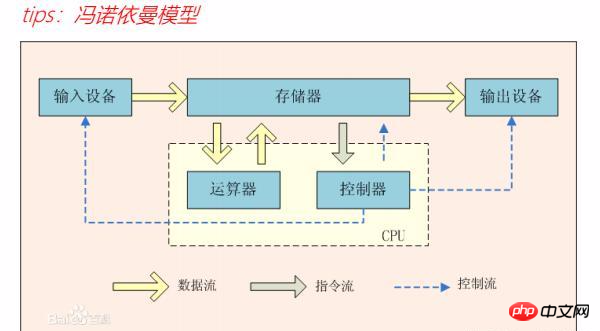
ENIAC之后,电子计算机进入到了IBM主导的大型机的时代, 在1946年第一台IBM大型机SYSTEM/360诞生,这使得IBM在20世纪50~60年代统治了整个大型计算机的工业,在大型主机时代,计算机架构向两个方向发展CISC(微处理器执行的计算机语言指令集)CPU为架构的价格便宜的个人PC和RISC(精简指令集计算机)价格高的小型UNIX服务器。
大型主机的出现,凭借着计算能力和处理能力,高的稳定性和安全性,在很长的一段时间内引领到计算领域的发展。但是集中式的计算机系统来带来了一些问题,来越来越不能满足用户的需求比如说:
1.大型的主机非常贵,一般的小企业用不起。
2.大型主机比较复杂,培养人才的成本比较高。
3.单点问题,如过大型机出现故障,整个系统都挂了运行不了,使企业的损失非常大。
4.随着技术的进步,个人PC电脑的性能越来越高,成本也越来越低。
阿里巴巴在2009年发起了一项去“IOE”的驱动
IOE指的是IBM的小型机,Oracle的数据库和EMC的高端存储设备,2009年的去IOE的运动,一直到2003的支付宝的最后一台IBM的小型机的下线。
为什么要去IOE
阿里巴巴过去数据库使用的是Oracle,并使用小型机和高端存储设备提供高性能的数据处理和存储服务。随着公司的业务量的上升,用户规模的不断上涨,传统的集中式的架构Oracle数据库在扩展方面遭遇了瓶颈。向传统的Oracle,DB2都是以集中式的为主,存在的缺点就是扩展性的不足,集中式的扩展主要是采用的是向上的扩展不是水平的扩展,这样时间长了,早晚都会遇到系统瓶颈。
一.分布式架构的常见概念
集群
小饭店原来是一个厨师,切菜洗菜备料炒菜全干。后来客人多了,厨房一个厨师忙不过来,又请了个厨师,两个厨师都能炒一样的菜,这两个厨师的关系就是集群。
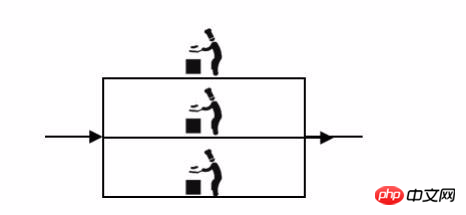
分布式
为了让厨师专心炒菜,把菜做到极致,又请了个配菜师负责切菜,备菜,备料,厨师和配菜师的关系就是分布式的,一个配菜师也忙不过来,有请了个配菜师,这两个配菜师的关系就是集群了。所以说有分布式的架构中可能有集群,但集群不等于有分布式。
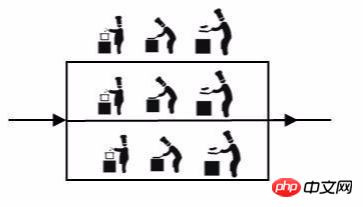
节点
节点是指一个可以独立按照分布式协议完成一组逻辑的程序个体。在具体的项目中,一个节点表示的是一个操作系统上的进程。
副本机制
副本指的是在分布式系统中为数据或服务提供冗余。
数据副本指在不同的节点上持久化同一份数据,当出现某一个节点的数据丢失时,可以从副本读取数据。数据副本是分布式系统中结果数据丢失的唯一手段。
服务副本表示的是多个节点提供相同的服务,通过主从关系来实现服务的高可用方案。
中间件
中间件位与操作系统提供的服务之外,又不属于应用,它是位与应用和系统层之间为开发者方便的处理通信,输入和输出的一类软件,能够让用户关心自己应用的一部分。
架构的发展过程
一个成熟的大型网站系统架构并不是一开始就设计的非常完美的,也不是一开始就具备高性能,高可用,安全性等特性,而是随着用户量的增加,业务功能的扩展慢慢完善演变过来的。在这个发展过程中,开发模式,技术架构等都会发生非常大的变化。
假如系统具备一下功能:
用户模块:用户注册和管理
商品模块:商品展示和管理
交易模块:创建交易及支付结算
阶段一:单应用架构
系统的初级都是应用和数据库都放在一台服务器上。

阶段二:应用服务器和数据库服务器分离
随着网站的用户量增大,流量增大,对应用服务器和数据库服务器单独的部署机器,这样可以增加系统的性能,提高访问的效率,提高单机的负载能力和容灾的能力。
阶段三:应用服务器集群-应用服务器负载告警
随着访问量和流量的增加,假设数据库没有遇到瓶颈,对应用服务器集群来对请求进行分流,提高程序的性能。存在的问题:用户的请求由谁来转发,session如何来管理的问题。
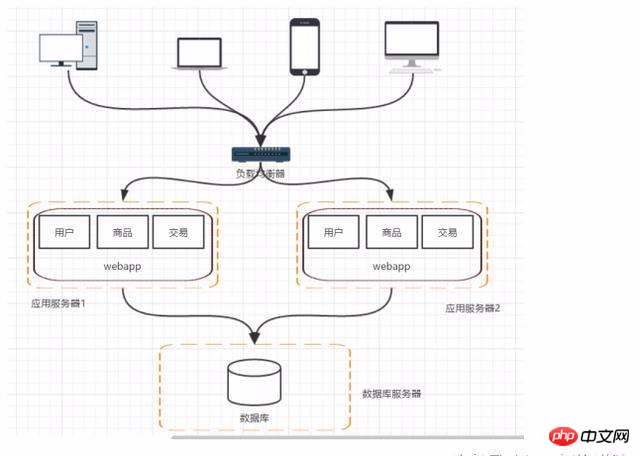
阶段四:数据库压力变大-数据库读写分离
读写分离的话,这样以后的请求,查询的请求就可以去从库里面读数据,写的数据可以到主库中了,但是会带来几个问题:
1.主从的数据库之间的数据同步:可以使用mysql自带的master-slave方式实现主从复制
2.对应的数据源的选择:采用第三方数据库中间件,例如:mycat
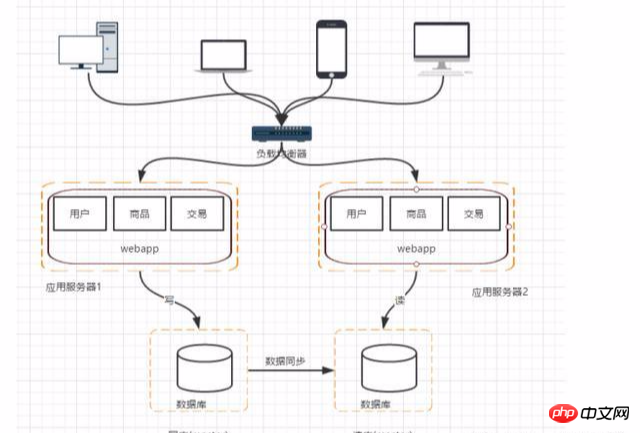
阶段五:使用搜索引擎缓解读库的压力
数据库做读库的话,常常对模糊查询的性能不是很好,特别是对于大型的互联网公司来说,想搜索的模块就比较核心了,这是可以使用搜索引擎了,虽然可以大幅度的提高查询的速度,但是同时也会带来一些问题比如索引的构建。
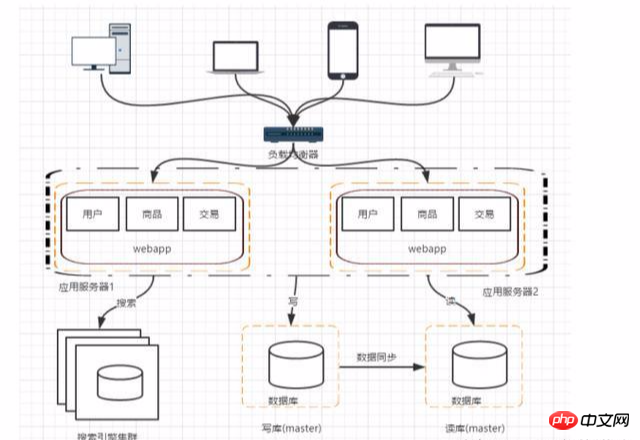
阶段六:引入缓存机制缓解数据库的压力
对一些热点的数据,可以使用redis,memcache来作为应用层的缓存;另外在某些场景下,可以使用mongodb来替代关系型数据库来存储。
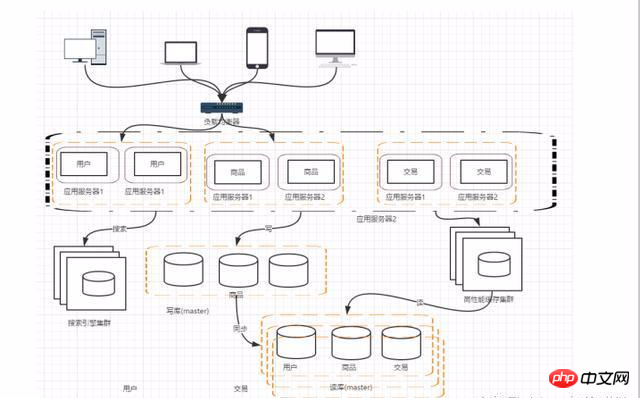
阶段七:数据库的水平/垂直拆分
垂直拆分:把数据库中不同的业务数据拆分到不同的数据库中。
水平拆分:把同一个表中的数据拆分到两个甚至更多的数据库中,水平拆分的原因是某些业务量数据量大的已经达到了单个数据库的瓶颈,这时候可以采取将表拆分到多个数据库中。

阶段八:应用的拆分
随着业务的发展,业务越来越多,应用的压力越来越大。工程规模也越来越庞大。这个时候就可以考虑将应用拆分,按照领域模型将我们的用户,商品,交易分拆成子系统。
这样拆分以后,可能会有一些相同的代码,比如用户操作,商品的交易查询,所有会导致每个系统都会有用户查询和访问相关的操作。这些相同的代码和模块一定要抽象出来。这样有利于维护和管理。
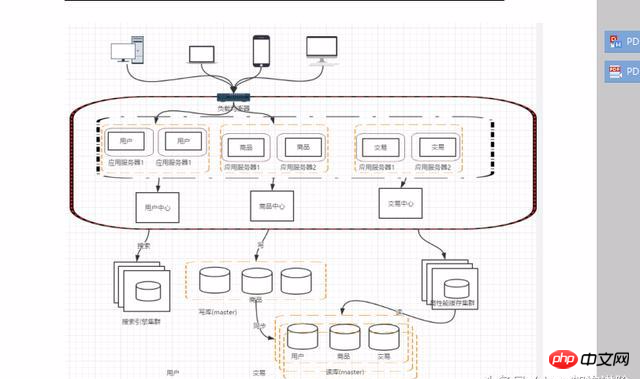
服务拆分以后,服务之间的通信可以通过RPC技术,比较典型的有:webservice、hession、http、RMI等。
以上是浅谈Java应用分布式架构的演进过程的详细内容。更多信息请关注PHP中文网其他相关文章!

 如何将Maven或Gradle用于高级Java项目管理,构建自动化和依赖性解决方案?Mar 17, 2025 pm 05:46 PM
如何将Maven或Gradle用于高级Java项目管理,构建自动化和依赖性解决方案?Mar 17, 2025 pm 05:46 PM本文讨论了使用Maven和Gradle进行Java项目管理,构建自动化和依赖性解决方案,以比较其方法和优化策略。
 如何使用适当的版本控制和依赖项管理创建和使用自定义Java库(JAR文件)?Mar 17, 2025 pm 05:45 PM
如何使用适当的版本控制和依赖项管理创建和使用自定义Java库(JAR文件)?Mar 17, 2025 pm 05:45 PM本文使用Maven和Gradle之类的工具讨论了具有适当的版本控制和依赖关系管理的自定义Java库(JAR文件)的创建和使用。
 如何使用咖啡因或Guava Cache等库在Java应用程序中实现多层缓存?Mar 17, 2025 pm 05:44 PM
如何使用咖啡因或Guava Cache等库在Java应用程序中实现多层缓存?Mar 17, 2025 pm 05:44 PM本文讨论了使用咖啡因和Guava缓存在Java中实施多层缓存以提高应用程序性能。它涵盖设置,集成和绩效优势,以及配置和驱逐政策管理最佳PRA
 如何将JPA(Java持久性API)用于具有高级功能(例如缓存和懒惰加载)的对象相关映射?Mar 17, 2025 pm 05:43 PM
如何将JPA(Java持久性API)用于具有高级功能(例如缓存和懒惰加载)的对象相关映射?Mar 17, 2025 pm 05:43 PM本文讨论了使用JPA进行对象相关映射,并具有高级功能,例如缓存和懒惰加载。它涵盖了设置,实体映射和优化性能的最佳实践,同时突出潜在的陷阱。[159个字符]
 Java的类负载机制如何起作用,包括不同的类载荷及其委托模型?Mar 17, 2025 pm 05:35 PM
Java的类负载机制如何起作用,包括不同的类载荷及其委托模型?Mar 17, 2025 pm 05:35 PMJava的类上载涉及使用带有引导,扩展程序和应用程序类负载器的分层系统加载,链接和初始化类。父代授权模型确保首先加载核心类别,从而影响自定义类LOA


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

WebStorm Mac版
好用的JavaScript开发工具

SublimeText3汉化版
中文版,非常好用

Dreamweaver Mac版
视觉化网页开发工具

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

Atom编辑器mac版下载
最流行的的开源编辑器

