

本篇文章主要介绍了PHP实现小偷程序实例,实现了抓取网页咨询和商品信息的功能,具有一定的参考价值,感兴趣的小伙伴们可以参考一下。
为什么使用“小偷程序”?
远程抓取文章资讯或商品信息是很多企业要求程序员实现的功能,也就是俗说的小偷程序。其最主要的优点是:解决了公司网编繁重的工作,大大提高了效率。只需要一运行就能快速的抓取别人网站的信息。
“小偷程序”在哪里运行?
“小偷程序” 应该在 Windows 下的 DOS或 Linux 下通过 PHP 命令运行为最佳,因为,网页运行会超时。
比如图(Windows 下 DOS 为例):
“小偷程序”的实现
这里主要通过一个实例来讲解,我们来抓取下“华强电子网”的资讯信息,请先看观察这个链接 http://www.hqew.com/info-c10.html,当您打开这个页面的时候发现这个页面会发现一些现象:
1、资讯列表有 500 页(2012-01-03);
2、每页的 url 链接都有规律,比如:第1页为http://www.hqew.com/info-c10-1.html;第2页为http://www.hqew.com/info-c10-2.html;……第500页为http://www.hqew.com/info-c10-500.html;
3、由第二点就可以知道,“华强电子网” 的资讯是伪静态或者是生成的静态页面
其实,基本上大部分的网站都有这样的规律,比如:中关村在线、慧聪网、新浪、淘宝……。
这样,我们可以通过这样的思路来实现页面内容的抓取:
1、先获取文章列表页内容;
2、根据文章列表页内容循环获取文章的 url 地址;
3、根据文章的 url 地址获取文章的详细内容
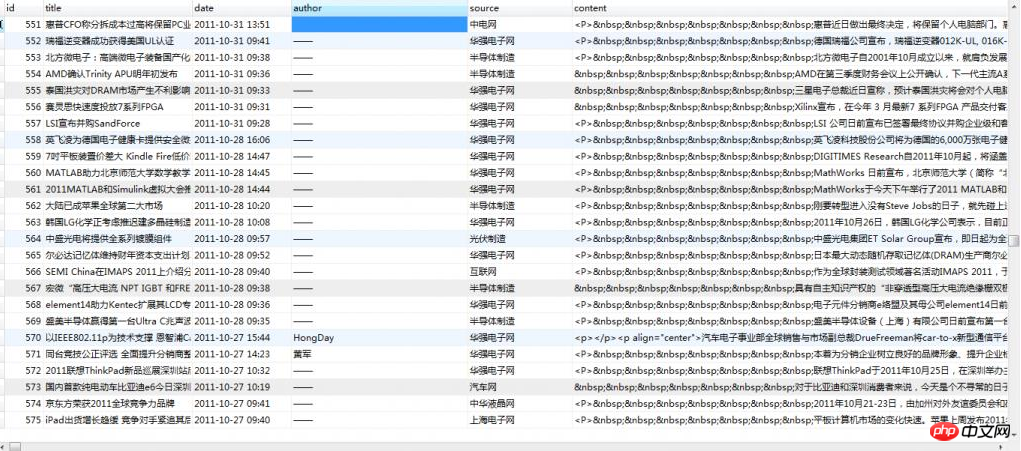
这里,我们主要抓取资讯页里面的:标题(title)、发布如期(date)、作者(author)、来源(source)、内容(content)
“华强电子网”资讯抓取
首先,先建数据表结构,如下所示:
CREATE TABLE `article`.`article` ( `id` MEDIUMINT( 8 ) UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY , `title` VARCHAR( 255 ) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL , `date` VARCHAR( 50 ) NOT NULL , `author` VARCHAR( 100 ) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL , `source` VARCHAR( 100 ) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL , `content` TEXT NOT NULL ) ENGINE = MYISAM CHARACTER SET utf8 COLLATE utf8_general_ci;
抓取程序:
<?php
/**
* 抓取“华强电子网”资讯程序
* author Lee.
* Last modify $Date: 2012-1-3 15:39:35 $
*/
header('Content-Type:text/html;Charset=utf-8');
$mysqli = new mysqli('localhost', 'root', '1715544', 'article'); # 数据库连接,请手动修改您自己的数据库信息
$mysqli->set_charset('UTF8'); # 设置数据库编码
function data($url) {
global $mysqli;
$result = file_get_contents($url); # $result 获取 url 链接内容(注意:这里是文章列表链接)
$pattern = '/<li><span class="box_r">.+<\/span><a href="([^"]+)" title=".+" >.+<\/a><\/li>/Usi'; # 取得文章 url 的匹配正则
preg_match_all($pattern, $result, $arr); # 把文章列表 url 分配给数组$arr(二维数组)
foreach ($arr[1] as $val) {
$val = 'http://www.hqew.com' . $val; # 真实文章 url 地址
$re = file_get_contents($val); # $re 为文章 url 的内容
$pa = '/<p id="article">\s+<h1>(.+)<\/h1>\s+<p id="article\_extinfo">\s+发布:\s+(.+)\s+\|\s+作者:\s+(.+)\s+\|\s+来源:\s+(.*?)\s+<span style="display:none" >.+<p id="article_body">\s*(.+)\s+<\/p>\s+<\/p><!--article end-->/Usi'; # 取得文章内容的正则
preg_match_all($pa, $re, $array); # 把取到的内容分配到数组 $array
$content = trim($array[5][0]);
$con = array(
'title'=>mysqlString($array[1][0]),
'date'=>mysqlString($array[2][0]),
'author'=>mysqlString(stripAuthorTag($array[3][0])),
'source'=>mysqlString($array[4][0]),
'content'=>mysqlString(stripContentTag($content))
);
$sql = "INSERT INTO article(title,date,author,source,content) VALUES ('{$con['title']}','{$con['date']}','{$con['author']}','{$con['source']}','{$con['content']}')";
$row = $mysqli->query($sql); # 添加到数据库
if ($row) {
echo 'add success!';
} else {
echo 'add failed!';
}
}
}
/**
* stripOfficeTag($v) 对文章内容进行过滤,比如:去掉文章中的链接,过滤掉没用的 HTML 标签……
* @param string $v
* @return string
*/
function stripContentTag($v){
$v = str_replace('<p> </p>', '', $v);
$v = str_replace('<p />', '', $v);
$v = preg_replace('/<a href=".+" target="\_blank"><strong>(.+)<\/strong><\/a>/Usi', '\1', $v);
$v = preg_replace('%(<span\s*[^>]*>(.*)</span>)%Usi', '\2', $v);
$v = preg_replace('%(\s+class="Mso[^"]+")%si', '', $v);
$v = preg_replace('%( style="[^"]*mso[^>]*)%si', '', $v);
$v = preg_replace('/<b><\/b>/', '', $v);
return $v;
}
/**
* stripTitleTag($title) 对文章标题进行过滤
* @param string $v
* @return string
*/
function stripAuthorTag($v) {
$v = preg_replace('/<a href=".+" target="\_blank">(.+)<\/a>/Usi', '\1', $v);
return $v;
}
/**
* mysqlString($str) 过滤数据
* @param string $str
* @return string
*/
function mysqlString($str) {
return addslashes(trim($str));
}
/**
* init($min, $max) 入口程序方法,从 $min 页开始取,到 $max 页结束
* @param int $min 从 1 开始
* @param int $max
* @return string 返回 URL 地址
*/
function init($min=1, $max) {
for ($i=$min; $i<=$max; $i++) {
data("http://www.hqew.com/info-c10-{$i}.html");
}
}
init(1, 500); // 程序入口,从第一页开始抓,抓取500页
?>
通过上面的程序,就可以实现抓取华强电子网的资讯信息。
入口方法 init($min, $max) 如果想抓取 1-500 页面内容,那么 init(1, 500) 即可!这样,用不了多长时间,华强电子网的资讯就会全部抓取到数据库里面了。^_^
执行界面:
数据库:
以上就是本文的全部内容,希望对大家的学习有所帮助。
相关推荐:
以上是PHP实现小偷程序实例的详细内容。更多信息请关注PHP中文网其他相关文章!

 高流量网站的PHP性能调整May 14, 2025 am 12:13 AM
高流量网站的PHP性能调整May 14, 2025 am 12:13 AMTheSecretTokeEpingAphp-PowerEdwebSiterUnningSmoothlyShyunderHeavyLoadInVolvOLVOLVOLDEVERSALKEYSTRATICES:1)emplactopCodeCachingWithOpcachingWithOpCacheToreCescriptexecution Time,2)使用atabasequercachingCachingCachingWithRedataBasEndataBaseLeSendataBaseLoad,3)
 PHP中的依赖注入:初学者的代码示例May 14, 2025 am 12:08 AM
PHP中的依赖注入:初学者的代码示例May 14, 2025 am 12:08 AM你应该关心DependencyInjection(DI),因为它能让你的代码更清晰、更易维护。1)DI通过解耦类,使其更模块化,2)提高了测试的便捷性和代码的灵活性,3)使用DI容器可以管理复杂的依赖关系,但要注意性能影响和循环依赖问题,4)最佳实践是依赖于抽象接口,实现松散耦合。
 PHP性能:是否可以优化应用程序?May 14, 2025 am 12:04 AM
PHP性能:是否可以优化应用程序?May 14, 2025 am 12:04 AM是的,优化papplicationispossibleandessential.1)empartcachingingcachingusedapcutorediucedsatabaseload.2)优化的atabaseswithexing,高效Quereteries,and ConconnectionPooling.3)EnhanceCodeWithBuilt-unctions,避免使用,避免使用ingglobalalairaiables,并避免使用
 PHP性能优化:最终指南May 14, 2025 am 12:02 AM
PHP性能优化:最终指南May 14, 2025 am 12:02 AMtheKeyStrategiestosiminificallyBoostphpapplicationPermenCeare:1)useOpCodeCachingLikeLikeLikeLikeLikeCacheToreDuceExecutiontime,2)优化AtabaseInteractionswithPreparedStateTemtStatementStatementSandProperIndexing,3)配置
 PHP依赖注入容器:快速启动May 13, 2025 am 12:11 AM
PHP依赖注入容器:快速启动May 13, 2025 am 12:11 AMaphpdepentioncontiveContainerIsatoolThatManagesClassDeptions,增强codemodocultion,可验证性和Maintainability.itactsasaceCentralHubForeatingingIndections,因此reducingTightCightTightCoupOulplingIndeSingantInting。
 PHP中的依赖注入与服务定位器May 13, 2025 am 12:10 AM
PHP中的依赖注入与服务定位器May 13, 2025 am 12:10 AM选择DependencyInjection(DI)用于大型应用,ServiceLocator适合小型项目或原型。1)DI通过构造函数注入依赖,提高代码的测试性和模块化。2)ServiceLocator通过中心注册获取服务,方便但可能导致代码耦合度增加。
 PHP性能优化策略。May 13, 2025 am 12:06 AM
PHP性能优化策略。May 13, 2025 am 12:06 AMphpapplicationscanbeoptimizedForsPeedAndeffificeby:1)启用cacheInphp.ini,2)使用preparedStatatementSwithPdoforDatabasequesies,3)3)替换loopswitharray_filtaray_filteraray_maparray_mapfordataprocrocessing,4)conformentnginxasaseproxy,5)
 PHP电子邮件验证:确保正确发送电子邮件May 13, 2025 am 12:06 AM
PHP电子邮件验证:确保正确发送电子邮件May 13, 2025 am 12:06 AMphpemailvalidation invoLvesthreesteps:1)格式化进行regulareXpressecthemailFormat; 2)dnsvalidationtoshethedomainhasavalidmxrecord; 3)


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

Atom编辑器mac版下载
最流行的的开源编辑器

记事本++7.3.1
好用且免费的代码编辑器

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

PhpStorm Mac 版本
最新(2018.2.1 )专业的PHP集成开发工具

