

这次给大家带来怎样使用vue内diff算法,使用vue内diff算法的注意事项有哪些,下面就是实战案例,一起来看一下。
1. 当数据发生变化时,vue是怎么更新节点的?
要知道渲染真实DOM的开销是很大的,比如有时候我们修改了某个数据,如果直接渲染到真实dom上会引起整个dom树的重绘和重排,有没有可能我们只更新我们修改的那一小块dom而不要更新整个dom呢?diff算法能够帮助我们。
我们先根据真实DOM生成一颗 virtual DOM ,当 virtual DOM 某个节点的数据改变后会生成一个新的 Vnode ,然后 Vnode 和 oldVnode 作对比,发现有不一样的地方就直接修改在真实的DOM上,然后使 oldVnode 的值为 Vnode 。
diff的过程就是调用名为 patch 的函数,比较新旧节点,一边比较一边给 真实的DOM 打补丁。
2. virtual DOM和真实DOM的区别?
virtual DOM是将真实的DOM的数据抽取出来,以对象的形式模拟树形结构。比如dom是这样的:
<p> <p>123</p> </p>
对应的virtual DOM(伪代码):
var Vnode = {
tag: 'p',
children: [
{ tag: 'p', text: '123' }
]
};
(温馨提示: VNode 和 oldVNode 都是对象,一定要记住)
3. diff的比较方式?
在采取diff算法比较新旧节点的时候,比较只会在同层级进行, 不会跨层级比较。
<p> <p>123</p> </p>456
上面的代码会分别比较同一层的两个p以及第二层的p和span,但是不会拿p和span作比较。在别处看到的一张很形象的图:
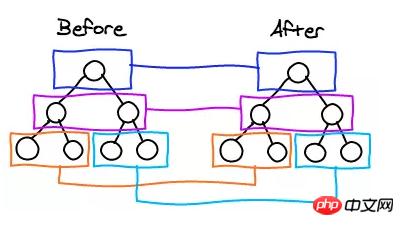
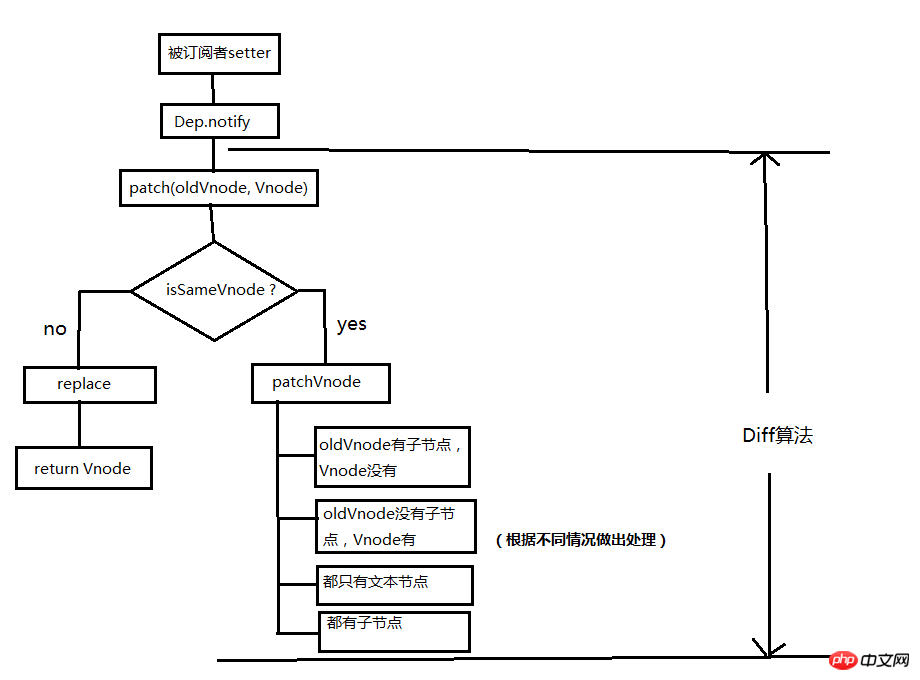
diff流程图
当数据发生改变时,set方法会让调用 Dep.notify 通知所有订阅者Watcher,订阅者就会调用 patch 给真实的DOM打补丁,更新相应的视图。
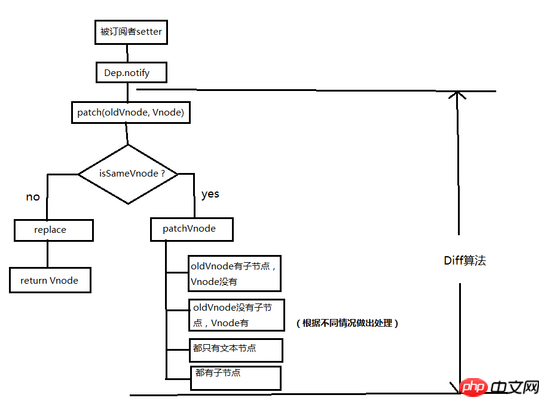
具体分析
patch
来看看 patch 是怎么打补丁的(代码只保留核心部分)
function patch (oldVnode, vnode) {
// some code
if (sameVnode(oldVnode, vnode)) {
patchVnode(oldVnode, vnode)
} else {
const oEl = oldVnode.el // 当前oldVnode对应的真实元素节点
let parentEle = api.parentNode(oEl) // 父元素
createEle(vnode) // 根据Vnode生成新元素
if (parentEle !== null) {
api.insertBefore(parentEle, vnode.el, api.nextSibling(oEl)) // 将新元素添加进父元素
api.removeChild(parentEle, oldVnode.el) // 移除以前的旧元素节点
oldVnode = null
}
}
// some code
return vnode
}
patch函数接收两个参数 oldVnode 和 Vnode 分别代表新的节点和之前的旧节点
判断两节点是否值得比较,值得比较则执行 patchVnode
function sameVnode (a, b) {
return (
a.key === b.key && // key值
a.tag === b.tag && // 标签名
a.isComment === b.isComment && // 是否为注释节点
// 是否都定义了data,data包含一些具体信息,例如onclick , style
isDef(a.data) === isDef(b.data) &&
sameInputType(a, b) // 当标签是<input>的时候,type必须相同
)
}
不值得比较则用 Vnode 替换 oldVnode
如果两个节点都是一样的,那么就深入检查他们的子节点。如果两个节点不一样那就说明 Vnode 完全被改变了,就可以直接替换 oldVnode 。
虽然这两个节点不一样但是他们的子节点一样怎么办?别忘了,diff可是逐层比较的,如果第一层不一样那么就不会继续深入比较第二层了。(我在想这算是一个缺点吗?相同子节点不能重复利用了...)
patchVnode
当我们确定两个节点值得比较之后我们会对两个节点指定 patchVnode 方法。那么这个方法做了什么呢?
patchVnode (oldVnode, vnode) {
const el = vnode.el = oldVnode.el
let i, oldCh = oldVnode.children, ch = vnode.children
if (oldVnode === vnode) return
if (oldVnode.text !== null && vnode.text !== null && oldVnode.text !== vnode.text) {
api.setTextContent(el, vnode.text)
}else {
updateEle(el, vnode, oldVnode)
if (oldCh && ch && oldCh !== ch) {
updateChildren(el, oldCh, ch)
}else if (ch){
createEle(vnode) //create el's children dom
}else if (oldCh){
api.removeChildren(el)
}
}
}
这个函数做了以下事情:
找到对应的真实dom,称为
el判断
Vnode和oldVnode是否指向同一个对象,如果是,那么直接
return如果他们都有文本节点并且不相等,那么将el的文本节点设置为Vnode的文本节点。如果
oldVnode有子节点而Vnode没有,则删除el的子节点如果
oldVnode没有子节点而Vnode有,则将Vnode的子节点真实化之后添加到el如果两者都有子节点,则执行updateChildren函数比较子节点,这一步很重要
其他几个点都很好理解,我们详细来讲一下updateChildren
updateChildren
代码量很大,不方便一行一行的讲解,所以下面结合一些示例图来描述一下。
updateChildren (parentElm, oldCh, newCh) {
let oldStartIdx = 0, newStartIdx = 0
let oldEndIdx = oldCh.length - 1
let oldStartVnode = oldCh[0]
let oldEndVnode = oldCh[oldEndIdx]
let newEndIdx = newCh.length - 1
let newStartVnode = newCh[0]
let newEndVnode = newCh[newEndIdx]
let oldKeyToIdx
let idxInOld
let elmToMove
let before
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (oldStartVnode == null) { // 对于vnode.key的比较,会把oldVnode = null
oldStartVnode = oldCh[++oldStartIdx]
}else if (oldEndVnode == null) {
oldEndVnode = oldCh[--oldEndIdx]
}else if (newStartVnode == null) {
newStartVnode = newCh[++newStartIdx]
}else if (newEndVnode == null) {
newEndVnode = newCh[--newEndIdx]
}else if (sameVnode(oldStartVnode, newStartVnode)) {
patchVnode(oldStartVnode, newStartVnode)
oldStartVnode = oldCh[++oldStartIdx]
newStartVnode = newCh[++newStartIdx]
}else if (sameVnode(oldEndVnode, newEndVnode)) {
patchVnode(oldEndVnode, newEndVnode)
oldEndVnode = oldCh[--oldEndIdx]
newEndVnode = newCh[--newEndIdx]
}else if (sameVnode(oldStartVnode, newEndVnode)) {
patchVnode(oldStartVnode, newEndVnode)
api.insertBefore(parentElm, oldStartVnode.el, api.nextSibling(oldEndVnode.el))
oldStartVnode = oldCh[++oldStartIdx]
newEndVnode = newCh[--newEndIdx]
}else if (sameVnode(oldEndVnode, newStartVnode)) {
patchVnode(oldEndVnode, newStartVnode)
api.insertBefore(parentElm, oldEndVnode.el, oldStartVnode.el)
oldEndVnode = oldCh[--oldEndIdx]
newStartVnode = newCh[++newStartIdx]
}else {
// 使用key时的比较
if (oldKeyToIdx === undefined) {
oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx) // 有key生成index表
}
idxInOld = oldKeyToIdx[newStartVnode.key]
if (!idxInOld) {
api.insertBefore(parentElm, createEle(newStartVnode).el, oldStartVnode.el)
newStartVnode = newCh[++newStartIdx]
}
else {
elmToMove = oldCh[idxInOld]
if (elmToMove.sel !== newStartVnode.sel) {
api.insertBefore(parentElm, createEle(newStartVnode).el, oldStartVnode.el)
}else {
patchVnode(elmToMove, newStartVnode)
oldCh[idxInOld] = null
api.insertBefore(parentElm, elmToMove.el, oldStartVnode.el)
}
newStartVnode = newCh[++newStartIdx]
}
}
}
if (oldStartIdx > oldEndIdx) {
before = newCh[newEndIdx + 1] == null ? null : newCh[newEndIdx + 1].el
addVnodes(parentElm, before, newCh, newStartIdx, newEndIdx)
}else if (newStartIdx > newEndIdx) {
removeVnodes(parentElm, oldCh, oldStartIdx, oldEndIdx)
}
}
先说一下这个函数做了什么
将
Vnode的子节点Vch和oldVnode的子节点oldCh提取出来oldCh和vCh各有两个头尾的变量StartIdx和EndIdx,它们的2个变量相互比较,一共有4种比较方式。如果4种比较都没匹配,如果设置了key,就会用key进行比较,在比较的过程中,变量会往中间靠,一旦StartIdx>EndIdx表明oldCh和vCh至少有一个已经遍历完了,就会结束比较。
图解updateChildren
终于来到了这一部分,上面的总结相信很多人也看得一脸懵逼,下面我们好好说道说道。(这都是我自己画的,求推荐好用的画图工具...)
粉红色的部分为oldCh和vCh
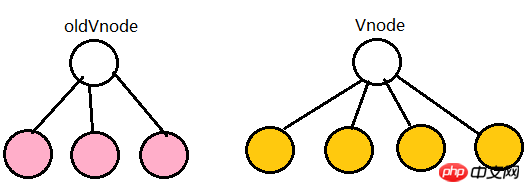
我们将它们取出来并分别用s和e指针指向它们的头child和尾child
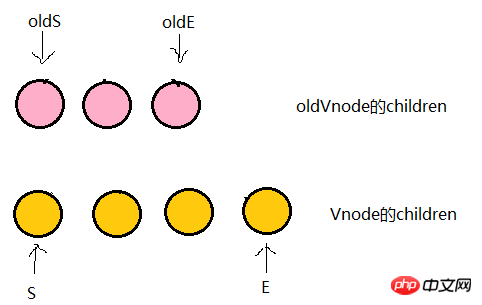
现在分别对 oldS、oldE、S、E 两两做 sameVnode 比较,有四种比较方式,当其中两个能匹配上那么真实dom中的相应节点会移到Vnode相应的位置,这句话有点绕,打个比方
如果是oldS和E匹配上了,那么真实dom中的第一个节点会移到最后
如果是oldE和S匹配上了,那么真实dom中的最后一个节点会移到最前,匹配上的两个指针向中间移动
如果四种匹配没有一对是成功的,那么遍历
oldChild,S挨个和他们匹配,匹配成功就在真实dom中将成功的节点移到最前面,如果依旧没有成功的,那么将S对应的节点插入到dom中对应的oldS位置,oldS和S指针向中间移动。
再配个图
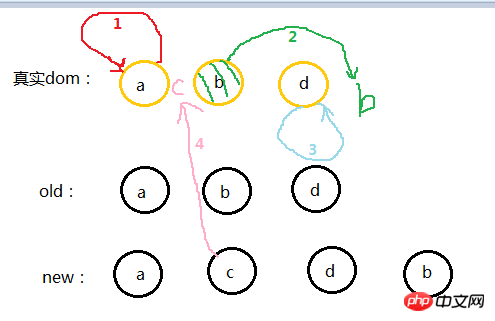
第一步
oldS = a, oldE = d; S = a, E = b;
oldS 和 S 匹配,则将dom中的a节点放到第一个,已经是第一个了就不管了,此时dom的位置为:a b d
第二步
oldS = b, oldE = d; S = c, E = b;
oldS 和 E 匹配,就将原本的b节点移动到最后,因为 E 是最后一个节点,他们位置要一致,这就是上面说的: 当其中两个能匹配上那么真实dom中的相应节点会移到Vnode相应的位置 ,此时dom的位置为:a d b
第三步
oldS = d, oldE = d; S = c, E = d;
oldE 和 E 匹配,位置不变此时dom的位置为:a d b
第四步
oldS++; oldE--; oldS > oldE;
遍历结束,说明 oldCh 先遍历完。就将剩余的 vCh 节点根据自己的的index插入到真实dom中去,此时dom位置为:a c d b
一次模拟完成。
这个匹配过程的结束有两个条件:
oldS > oldE 表示 oldCh 先遍历完,那么就将多余的 vCh 根据index添加到dom中去(如上图) S > E 表示vCh先遍历完,那么就在真实dom中将区间为 [oldS, oldE] 的多余节点删掉
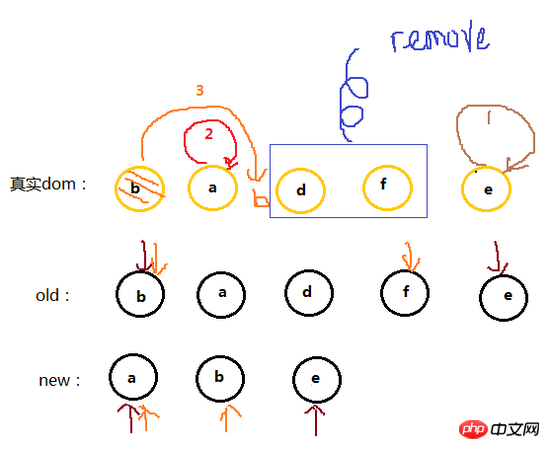
下面再举一个例子,可以像上面那样自己试着模拟一下
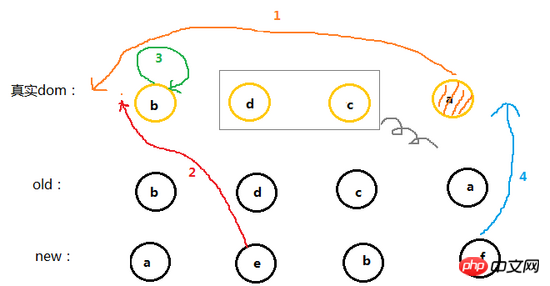
当这些节点 sameVnode 成功后就会紧接着执行 patchVnode 了,可以看一下上面的代码
if (sameVnode(oldStartVnode, newStartVnode)) {
patchVnode(oldStartVnode, newStartVnode)
}
就这样层层递归下去,直到将oldVnode和Vnode中的所有子节点比对完。也将dom的所有补丁都打好啦。那么现在再回过去看updateChildren的代码会不会容易很多呢?
总结
以上为diff算法的全部过程,放上一张文章开始就发过的总结图,可以试试看着这张图回忆一下diff的过程。
相信看了本文案例你已经掌握了方法,更多精彩请关注php中文网其它相关文章!
推荐阅读:
以上是怎样使用vue内diff算法的详细内容。更多信息请关注PHP中文网其他相关文章!

 特斯拉自动驾驶算法和模型解读Apr 11, 2023 pm 12:04 PM
特斯拉自动驾驶算法和模型解读Apr 11, 2023 pm 12:04 PM特斯拉是一个典型的AI公司,过去一年训练了75000个神经网络,意味着每8分钟就要出一个新的模型,共有281个模型用到了特斯拉的车上。接下来我们分几个方面来解读特斯拉FSD的算法和模型进展。01 感知 Occupancy Network特斯拉今年在感知方面的一个重点技术是Occupancy Network (占据网络)。研究机器人技术的同学肯定对occupancy grid不会陌生,occupancy表示空间中每个3D体素(voxel)是否被占据,可以是0/1二元表示,也可以是[0, 1]之间的
 基于因果森林算法的决策定位应用Apr 08, 2023 am 11:21 AM
基于因果森林算法的决策定位应用Apr 08, 2023 am 11:21 AM译者 | 朱先忠审校 | 孙淑娟在我之前的博客中,我们已经了解了如何使用因果树来评估政策的异质处理效应。如果你还没有阅读过,我建议你在阅读本文前先读一遍,因为我们在本文中认为你已经了解了此文中的部分与本文相关的内容。为什么是异质处理效应(HTE:heterogenous treatment effects)呢?首先,对异质处理效应的估计允许我们根据它们的预期结果(疾病、公司收入、客户满意度等)选择提供处理(药物、广告、产品等)的用户(患者、用户、客户等)。换句话说,估计HTE有助于我
 Mango:基于Python环境的贝叶斯优化新方法Apr 08, 2023 pm 12:44 PM
Mango:基于Python环境的贝叶斯优化新方法Apr 08, 2023 pm 12:44 PM译者 | 朱先忠审校 | 孙淑娟引言模型超参数(或模型设置)的优化可能是训练机器学习算法中最重要的一步,因为它可以找到最小化模型损失函数的最佳参数。这一步对于构建不易过拟合的泛化模型也是必不可少的。优化模型超参数的最著名技术是穷举网格搜索和随机网格搜索。在第一种方法中,搜索空间被定义为跨越每个模型超参数的域的网格。通过在网格的每个点上训练模型来获得最优超参数。尽管网格搜索非常容易实现,但它在计算上变得昂贵,尤其是当要优化的变量数量很大时。另一方面,随机网格搜索是一种更快的优化方法,可以提供更好的
 因果推断主要技术思想与方法总结Apr 12, 2023 am 08:10 AM
因果推断主要技术思想与方法总结Apr 12, 2023 am 08:10 AM导读:因果推断是数据科学的一个重要分支,在互联网和工业界的产品迭代、算法和激励策略的评估中都扮演者重要的角色,结合数据、实验或者统计计量模型来计算新的改变带来的收益,是决策制定的基础。然而,因果推断并不是一件简单的事情。首先,在日常生活中,人们常常把相关和因果混为一谈。相关往往代表着两个变量具有同时增长或者降低的趋势,但是因果意味着我们想要知道对一个变量施加改变的时候会发生什么样的结果,或者说我们期望得到反事实的结果,如果过去做了不一样的动作,未来是否会发生改变?然而难点在于,反事实的数据往往是
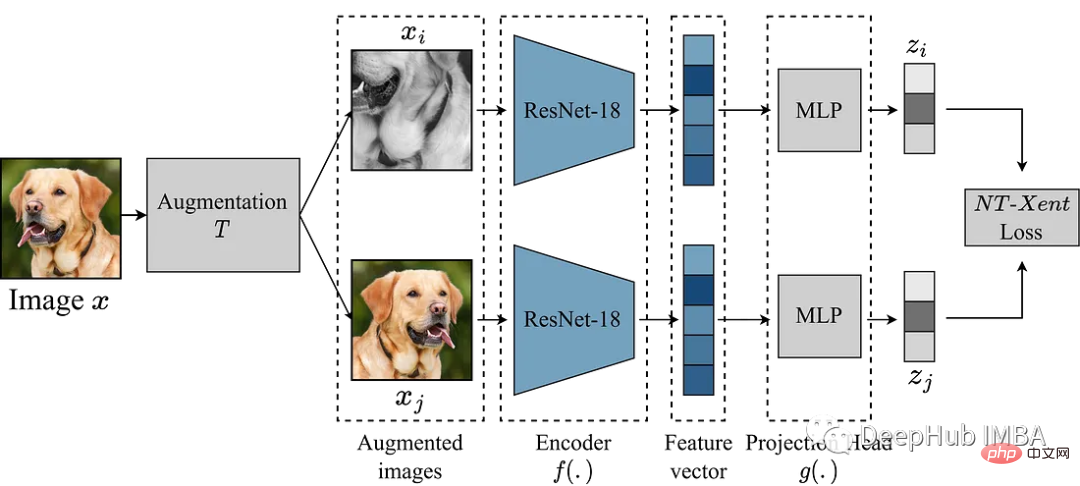 使用Pytorch实现对比学习SimCLR 进行自监督预训练Apr 10, 2023 pm 02:11 PM
使用Pytorch实现对比学习SimCLR 进行自监督预训练Apr 10, 2023 pm 02:11 PMSimCLR(Simple Framework for Contrastive Learning of Representations)是一种学习图像表示的自监督技术。 与传统的监督学习方法不同,SimCLR 不依赖标记数据来学习有用的表示。 它利用对比学习框架来学习一组有用的特征,这些特征可以从未标记的图像中捕获高级语义信息。SimCLR 已被证明在各种图像分类基准上优于最先进的无监督学习方法。 并且它学习到的表示可以很容易地转移到下游任务,例如对象检测、语义分割和小样本学习,只需在较小的标记
 盒马供应链算法实战Apr 10, 2023 pm 09:11 PM
盒马供应链算法实战Apr 10, 2023 pm 09:11 PM一、盒马供应链介绍1、盒马商业模式盒马是一个技术创新的公司,更是一个消费驱动的公司,回归消费者价值:买的到、买的好、买的方便、买的放心、买的开心。盒马包含盒马鲜生、X 会员店、盒马超云、盒马邻里等多种业务模式,其中最核心的商业模式是线上线下一体化,最快 30 分钟到家的 O2O(即盒马鲜生)模式。2、盒马经营品类介绍盒马精选全球品质商品,追求极致新鲜;结合品类特点和消费者购物体验预期,为不同品类选择最为高效的经营模式。盒马生鲜的销售占比达 60%~70%,是最核心的品类,该品类的特点是用户预期时
 用vimdiff替代svn diff:比较代码的工具Jan 09, 2024 pm 07:54 PM
用vimdiff替代svn diff:比较代码的工具Jan 09, 2024 pm 07:54 PM在linux下,直接使用svndiff命令查看代码的修改是很吃力的,于是在网上搜索到了一个比较好的解决方案,就是让vimdiff作为svndiff的查看代码工具,尤其对于习惯用vim的人来说真的是很方便。当使用svndiff命令比较某个文件的修改前后时,例如执行以下命令:$svndiff-r4420ngx_http_limit_req_module.c那么实际会向默认的diff程序发送如下命令:-u-Lngx_http_limit_req_module.c(revision4420)-Lngx_
 研究表明强化学习模型容易受到成员推理攻击Apr 09, 2023 pm 08:01 PM
研究表明强化学习模型容易受到成员推理攻击Apr 09, 2023 pm 08:01 PM译者 | 李睿 审校 | 孙淑娟随着机器学习成为人们每天都在使用的很多应用程序的一部分,人们越来越关注如何识别和解决机器学习模型的安全和隐私方面的威胁。 然而,不同机器学习范式面临的安全威胁各不相同,机器学习安全的某些领域仍未得到充分研究。尤其是强化学习算法的安全性近年来并未受到太多关注。 加拿大的麦吉尔大学、机器学习实验室(MILA)和滑铁卢大学的研究人员开展了一项新研究,主要侧重于深度强化学习算法的隐私威胁。研究人员提出了一个框架,用于测试强化学习模型对成员推理攻击的脆弱性。 研究


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

SublimeText3 Linux新版
SublimeText3 Linux最新版

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

Atom编辑器mac版下载
最流行的的开源编辑器

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

