



本篇文章给大家分享的内容是3利用python如何爬取js里面的内容 ,有着一定的参考价值,有需要的朋友可以参考一下
一、在编写爬虫软件获取所需内容时可能会碰到所需要的内容是由javascript添加上去的 在获取的时候为空 比如我们在获取新浪新闻的评论数时使用普通的方法就无法获取
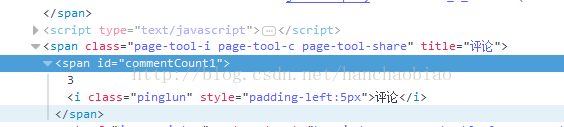
普通获取代码示例:
import requests from bs4 import BeautifulSoup res = requests.get('http://news.sina.com.cn/c/nd/2017-06-12/doc-ifyfzhac1650783.shtml') res.encoding = 'utf-8' soup = BeautifulSoup(res.text,'html.parser') #取评论数 commentCount = soup.select_one('#commentCount1') print(commentCount.text)
此时所获取的结果为空 这是由于内容是存储在js文件中
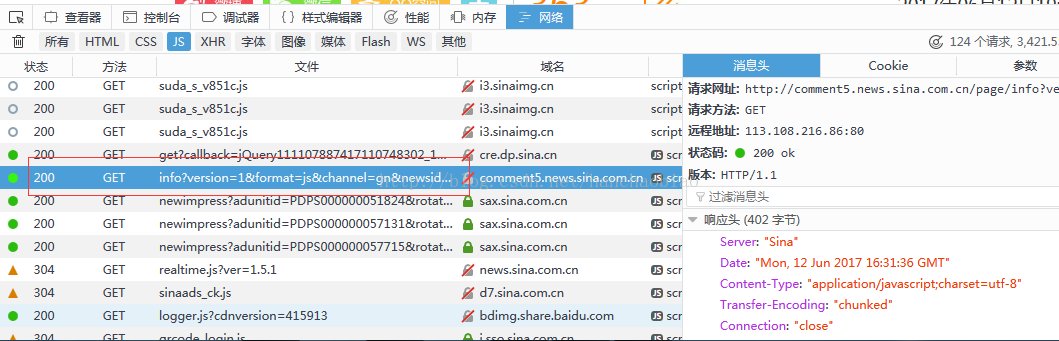
因此我们需要取寻找存储评论内容的js 经过查找我们发现其存储在改js里
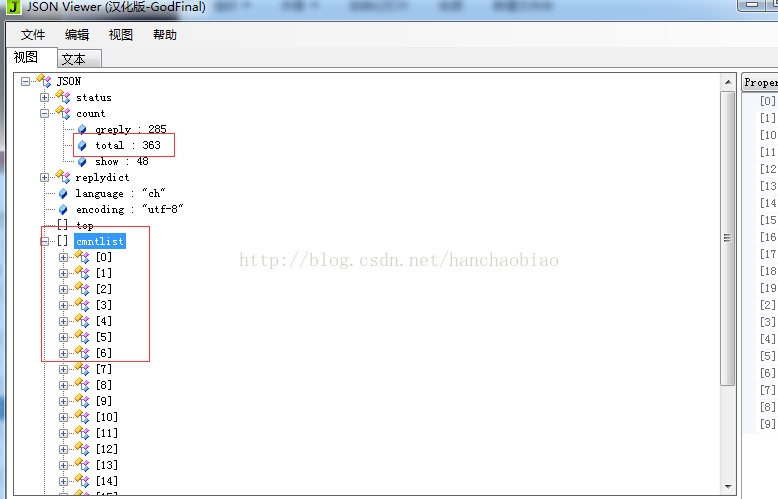
将相应内容放入json数据查看器中我们发现评论总数和评论内容都在该js文件中一json格式存放
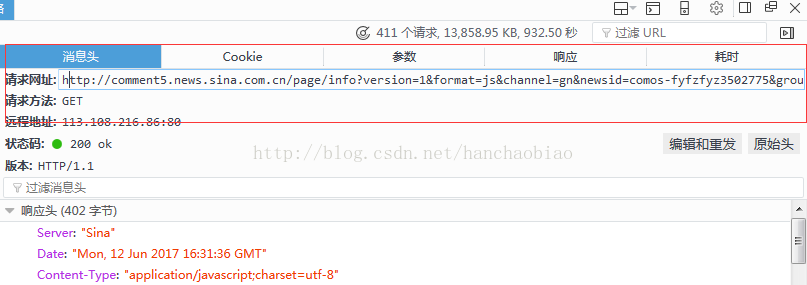
在消息头中我们可以看的该js文件的访问路径及请求方式
代码示例
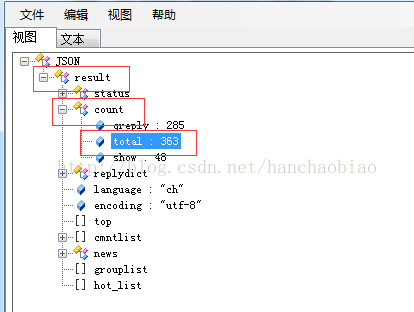
import json comments = requests.get('http://comment5.news.sina.com.cn/page/info?version=1&format=js&channel=gn&newsid=comos-fyfzhac1650783') comments.encoding = 'utf-8' print(comments) jd = json.loads(comments.text.strip('var data=')) #移除改var data=将其变为json数据 print(jd['result']['count']['total'])
注释:这里解释下为何需要移除 var data= 因为在获取时字符串前缀是包含var data=的 其不符合json数据格式 因此转化时需将其从请求内容中移除

取评论总数时为何使用jd['result']['count']['total']
以上是利用python如何爬取js里面的内容的详细内容。更多信息请关注PHP中文网其他相关文章!

 es6数组怎么去掉重复并且重新排序May 05, 2022 pm 07:08 PM
es6数组怎么去掉重复并且重新排序May 05, 2022 pm 07:08 PM去掉重复并排序的方法:1、使用“Array.from(new Set(arr))”或者“[…new Set(arr)]”语句,去掉数组中的重复元素,返回去重后的新数组;2、利用sort()对去重数组进行排序,语法“去重数组.sort()”。
 JavaScript的Symbol类型、隐藏属性及全局注册表详解Jun 02, 2022 am 11:50 AM
JavaScript的Symbol类型、隐藏属性及全局注册表详解Jun 02, 2022 am 11:50 AM本篇文章给大家带来了关于JavaScript的相关知识,其中主要介绍了关于Symbol类型、隐藏属性及全局注册表的相关问题,包括了Symbol类型的描述、Symbol不会隐式转字符串等问题,下面一起来看一下,希望对大家有帮助。
 原来利用纯CSS也能实现文字轮播与图片轮播!Jun 10, 2022 pm 01:00 PM
原来利用纯CSS也能实现文字轮播与图片轮播!Jun 10, 2022 pm 01:00 PM怎么制作文字轮播与图片轮播?大家第一想到的是不是利用js,其实利用纯CSS也能实现文字轮播与图片轮播,下面来看看实现方法,希望对大家有所帮助!
 JavaScript对象的构造函数和new操作符(实例详解)May 10, 2022 pm 06:16 PM
JavaScript对象的构造函数和new操作符(实例详解)May 10, 2022 pm 06:16 PM本篇文章给大家带来了关于JavaScript的相关知识,其中主要介绍了关于对象的构造函数和new操作符,构造函数是所有对象的成员方法中,最早被调用的那个,下面一起来看一下吧,希望对大家有帮助。
 JavaScript面向对象详细解析之属性描述符May 27, 2022 pm 05:29 PM
JavaScript面向对象详细解析之属性描述符May 27, 2022 pm 05:29 PM本篇文章给大家带来了关于JavaScript的相关知识,其中主要介绍了关于面向对象的相关问题,包括了属性描述符、数据描述符、存取描述符等等内容,下面一起来看一下,希望对大家有帮助。
 javascript怎么移除元素点击事件Apr 11, 2022 pm 04:51 PM
javascript怎么移除元素点击事件Apr 11, 2022 pm 04:51 PM方法:1、利用“点击元素对象.unbind("click");”方法,该方法可以移除被选元素的事件处理程序;2、利用“点击元素对象.off("click");”方法,该方法可以移除通过on()方法添加的事件处理程序。
 foreach是es6里的吗May 05, 2022 pm 05:59 PM
foreach是es6里的吗May 05, 2022 pm 05:59 PMforeach不是es6的方法。foreach是es3中一个遍历数组的方法,可以调用数组的每个元素,并将元素传给回调函数进行处理,语法“array.forEach(function(当前元素,索引,数组){...})”;该方法不处理空数组。
 整理总结JavaScript常见的BOM操作Jun 01, 2022 am 11:43 AM
整理总结JavaScript常见的BOM操作Jun 01, 2022 am 11:43 AM本篇文章给大家带来了关于JavaScript的相关知识,其中主要介绍了关于BOM操作的相关问题,包括了window对象的常见事件、JavaScript执行机制等等相关内容,下面一起来看一下,希望对大家有帮助。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

