


这次给大家带来解析JS正则的原理和语法,解析JS正则原理和语法的注意事项有哪些,下面就是实战案例,一起来看一下。
正则啊,就像一座灯塔,当你在字符串的海洋不知所措的时候,总能给你一点思路;正则啊,就像一台验钞机,在你不知道用户提交的钞票真假的时候,总能帮你一眼识别;正则啊,就像一个手电筒,在你需要找什么玩意的时候,总能帮你get你要的东西...
—— 节选自 Stinson 同学的语文排比句练习《正则》
欣赏了一段文学节选后,我们正式来梳理一遍JS中的正则,本文的首要目的是,防止我经常忘记正则的一些用法,故梳理和写下来加强熟练度和用作参考,次要目的是与君共勉,如有纰漏,请不吝赐教,良辰谢过。
本文既然取题为“一条龙”,就要对得起”龙”,故将包括正则原理、语法一览、JS(ES5)中的正则、ES6对正则的扩展、实践正则的思路,我尽量深入尽量浅出地去讲这些东西(搞得好像真能深入浅出一样的),如果你只想知道怎么应用,那么看第二、三、五部分,基本就能满足你的需求了,如果想掌握JS中的正则的,那么还是委屈你跟着我的思路来吧,嘿嘿嘿!
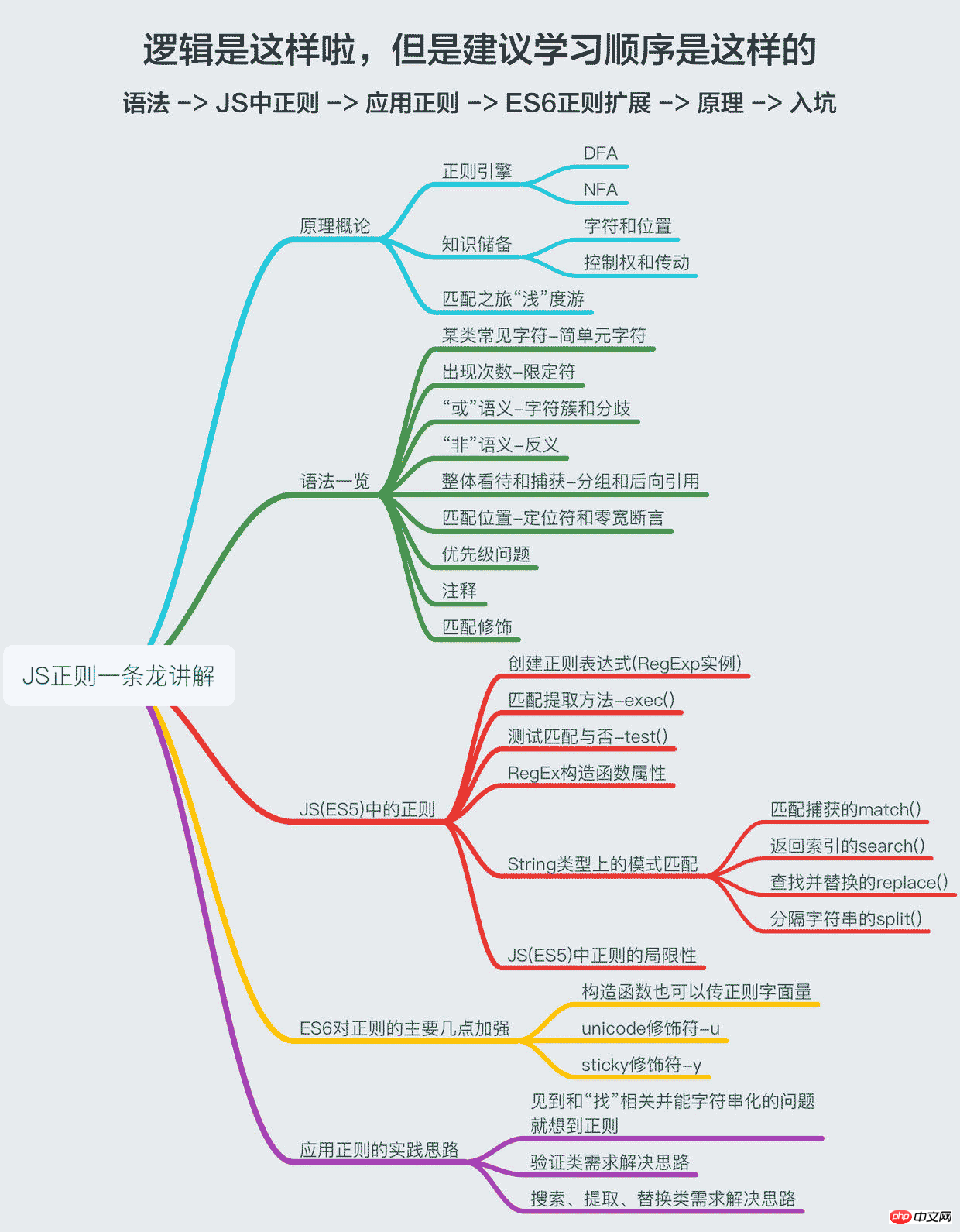
一、原理概论
在一开始用正则的时候,就觉得神奇,计算机究竟是怎么根据一个正则表达式来匹配字符串的?直到后来我遇到了一本书叫《计算理论》,看到了正则、DFA、NFA的概念和相互间的联系,才有一些恍然小悟的意思。
但如果真的要从原理上吃透正则表达式,那么恐怕最好的方式是:
1. 首先去找一本专门讲正则的书去看看,O'REILLY的“动物总动员”系列里就有;
2. 再自己实现一个正则引擎。
而本文的重点在于JS中正则的应用,故原理仅作简单介绍(因为我也没写过正则引擎,也不深入),一来大致“糊弄下”像我一样的好奇宝宝们对正则原理的疑惑,二来知道一些原理方面基本的知识,对于理解语法和写正则是大有裨益的。
1. 正则引擎
为什么正则能有效,因为有引擎,这和为什么JS能执行一样,有JS引擎,所谓正则引擎,可以理解为根据你的正则表达式用算法去模拟一台机器,这台机器有很多状态,通过读取待测的字符串,在这些状态间跳来跳去,如果最后停在了“终结状态”(Happy Ending),那么就Say I Do,否则Say You Are a Good Man。如此将一个正则表达式转换为一个可在有限的步数中计算出结果的机器,那么就实现了引擎。
正则的引擎大致可分为两类:DFA和NFA
1. DFA (Deterministic finite automaton) 确定型有穷自动机
2. NFA (Non-deterministic finite automaton) 非确定型有穷自动机,大部分都是NFA
这里的“确定型”指,对于某个确定字符的输入,这台机器的状态会确定地从a跳到b,“非确定型”指,对于某个确定字符的输入,这台机器可能有好几种状态的跳法;这里的“有穷”指,状态是有限的,可以在有限的步数内确定某个字符串是被接受还是发好人卡的;这里的“自动机”,可以理解为,一旦这台机器的规则设定完成,就可以自行判断了,不要人看。
DFA引擎不需要进行回溯,所以匹配效率一般情况下要高,但是它并不支持捕获组,于是也就不支持反向引用和$这种形式的引用,也不支持环视(Lookaround)、非贪婪模式等一些NFA引擎特有的特性。
如果想更详细地了解正则、DFA、NFA,那么可以去看一下《计算理论》,然后你可以根据某个正则表达式自己画出一台自动机。
2. 知识储备
这一小节对于你理解正则表达式很有用,尤其是明白什么是字符,什么是位置。
2.1 正则眼中的字符串——n个字符,n+1个位置

在上面的“笑声”字符串中,一共有8个字符,这是你能看到的,还有9个位置,这是聪明的人才能看到的。为什么要有字符还要有位置呢?因为位置是可以被匹配的。
那么进一步我们再来理解“占有字符”和“零宽度”:
如果一个子正则表达式匹配到的是字符,而不是位置,而且会被保存到最终的结果中,那个这个子表达式就是占有字符的,比如/ha/(匹配ha)就是占有字符的;
如果一个子正则匹配的是位置,而不是字符,或者匹配到的内容不保存在结果中(其实也可以看做一个位置),那么这个子表达式是零宽度的,比如/read(?=ing)/(匹配reading,但是只将read放入结果中,下文会详述语法,此处仅仅举例用),其中的(?=ing)就是零宽度的,它本质代表一个位置。
占有字符是互斥的,零宽度是非互斥的。也就是一个字符,同一时间只能由一个子表达式匹配,而一个位置,却可以同时由多个零宽度的子表达式匹配。举个栗子,比如/aa/是匹配不了a的,这个字符串中的a只能由正则的第一个a字符匹配,而不能同时由第二个a匹配(废话);但是位置是可以多个匹配的,比如/\b\ba/是可以匹配a的,虽然正则表达式里有2个表示单词开头位置的\b元字符,这两个\b是可以同时匹配位置0(在这个例子中)的。
注意:我们说字符和位置是面向字符串说的,而说占有字符和零宽度是面向正则说的。
2.2 控制权和传动
这两个词可能在搜一些博文或者资料的时候会遇到,这里做一个解释先:
控制权是指哪一个正则子表达式(可能为一个普通字符、元字符或元字符序列组成)在匹配字符串,那么控制权就在哪。
传动是指正则引擎的一种机制,传动装置将定位正则从字符串的哪里开始匹配。
正则表达式当开始匹配的时候,一般是由一个子表达式获取控制权,从字符串中的某一个位置开始尝试匹配,一个子表达式开始尝试匹配的位置,是从前一子表达匹配成功的结束位置开始的。
举一个栗子,read(?=ing)ing\sbook匹配reading book,我们把这个正则看成5个子表达式read、(?=ing)、ing、\s、book,当然你也可以吧read看做4个单独字符的子表达式,只是我们这里为了方便这么看待。read从位置0开始匹配到位置4,后面的(?=ing)继续从位置4开始匹配,发现位置4后面确实是ing,于是断言匹配成功,也就是整一个(?=ing)就是匹配了位置4这一个位置而已(这里更能理解什么是零宽了吧),然后后面的ing再从位置4开始匹配到位置7,然后\s再从位置7匹配到位置8,最后的book从位置8匹配到位置12,整一个匹配完成。
3. 匹配之旅“浅”度游(可跳过)
说了那么多,我们把自己当做一个正则引擎,一步一步以最小的单位——“字符”和“位置”——去看一下正则匹配的过程,举几个栗子。
3.1 基本匹配
正则表达式:easy
源字符串:So easy
匹配过程:首先由正则表达式字符e取得控制权,从字符串的位置0开始匹配,遇到字符串字符‘S',匹配失败,然后正则引擎向前传动,从位置1开始尝试,遇到字符串字符‘o',匹配失败,继续传动,后面的空格自然也失败,于是从位置3开始尝试匹配,成功匹配字符串字符‘e',控制权交给正则表达式子表达式(这里也是一个字符)a,尝试从上次匹配成功的结束位置4开始匹配,成功匹配字符串字符‘a',后面一直如此匹配到‘y',然后匹配完成,匹配结果为easy。
3.2 零宽匹配
正则:^(?=[aeiou])[a-z]+$ 源字符串:apple
首先这个正则表示:匹配这样一个从头到尾完整的字符串,这整一个字符串仅由小写字母组成,并且以a、e、i、o、u这5个字母任一字母开头。
匹配过程:首先正则的^(表示字符串开始的位置)获取控制权,从位置0开始匹配,匹配成功,控制权交给(?=[aeiou]),这个子表达式要求该位置右边必须是元音小写字母中的一个,零宽子表达式相互间不互斥,所以从位置0开始尝试匹配,右侧是字符串的‘a',符合因此匹配成功,所以(?=[aeiou])匹配此处的位置0匹配成功,控制权交给[a-z]+,从位置0开始匹配,字符串‘apple'中的每个字符都匹配成功,匹配到字符串末尾,控制权交回正则的$,尝试匹配字符串结束位置,成功,至此,整个匹配完成。
3.3 贪婪匹配和非贪婪匹配
正则1:{.*}
正则2:{.*?}
源字符串:{233}
这里有两个正则,在限定符(语法会讲什么是限定符)后面加?符号表示忽略优先量词,也就是非贪婪匹配,这个栗子我剥得快一点。
首先开头的{匹配,两个正则都是一样的表现。
正则1的.*为贪婪匹配,所以一直匹配余下字符串'233}',匹配到字符串结束位置,只是每次匹配,都记录一个备选状态,为了以后回溯,每次匹配有两条路,选择了匹配这条路,但记一下这里还可以有不匹配这条路,如果前面死胡同了,可以退回来,此时控制权交还给正则的},去匹配字符串结束位置,失败,于是回溯,意思就是说前面的.*你吃的太多了,吐一个出来,于是控制权回给.*,吐出一个}(其实是用了前面记录的备选状态,尝试不用.*去匹配'}'),控制权再给正则的},这次匹配就成功了。
正则2的.*?为非贪婪匹配,尽可能少地匹配,所以匹配'233}'的每一个字符的时候,都是尝试不匹配,但是一但控制权交还给最后的}就发现出问题了,赶紧回溯乖乖匹配,于是每一个字符都如此,最终匹配成功。
云里雾里?这就对了!可以移步去下面推荐的博客看看:
想详细了解贪婪和非贪婪匹配原理以及获取更多正则相关原理,除了看书之外,推荐去一个CSDN的博客 雁过无痕-博客频道 - CSDN.NET ,讲解得很详细和透彻
二、语法一览
正则的语法相信许多人已经看过deerchao写的30分钟入门教程,我也是从那篇文字中入门的,deerchao从语法逻辑的角度以.NET正则的标准来讲述了正则语法,而我想重新组织一遍,以便于应用的角度、以JS为宿主语言来重新梳理一遍语法,这将便于我们把语言描述翻译成正则表达式。
下面这张一览图(可能需要放大),整理了常用的正则语法,并且将JS不支持的语法特性以红色标注出来了(正文将不会描述这些不支持的特性),语法部分的详细描述也将根据下面的图,从上到下,从左到右的顺序来梳理,尽量不啰嗦。
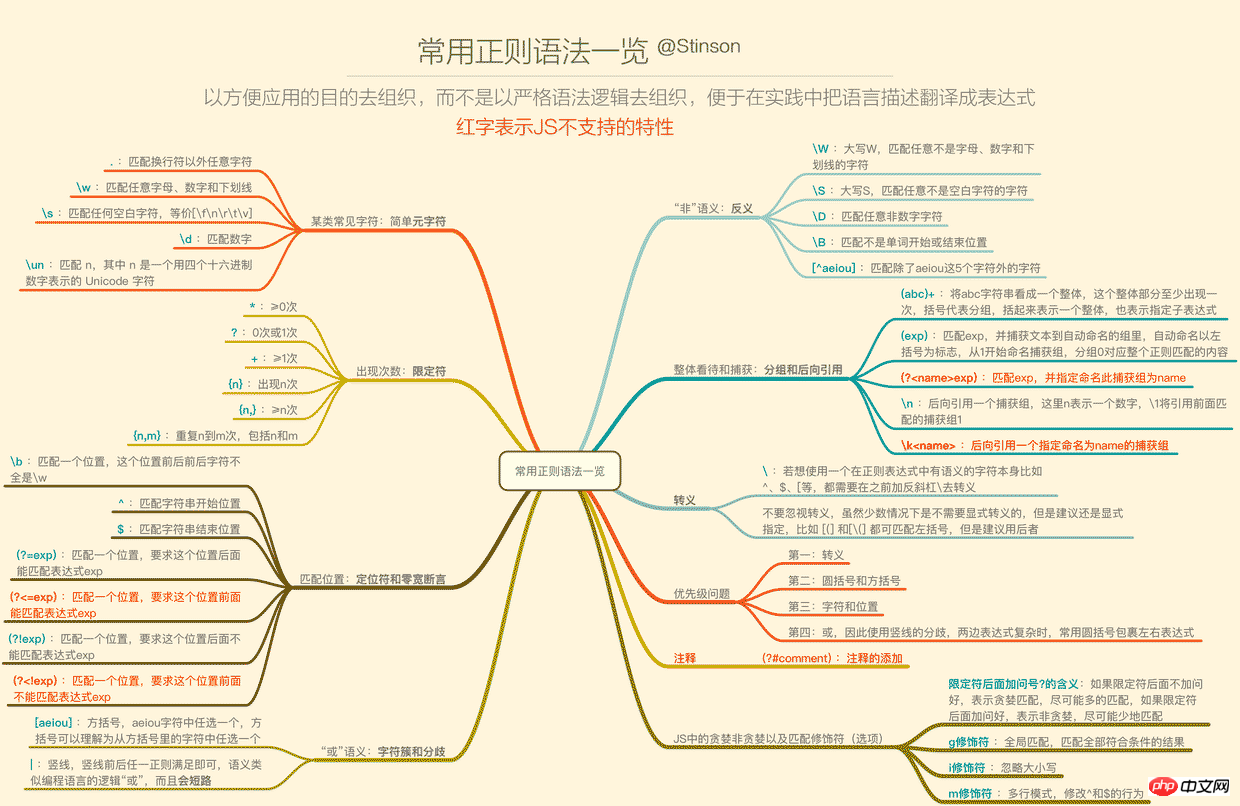
1. 要用某类常见字符——简单元字符
为什么这里要加简单2个字,因为在正则中,\d、\w这样的叫元字符,而{n,m}、(?!exp)这样的也叫元字符,所以元字符是在正则中有特定意义的标识,而这一小节讲的是简单的一些元字符。
.匹配除了换行符以外的任意字符,也即是[^\n],如果要包含任意字符,可使用(.|\n)
\w匹配任意字母、数字或者下划线,等价于[a-zA-Z0-9_],在deerchao的文中还指出可匹配汉字,但是\w在JS中是不能匹配汉字的
\s匹配任意空白符,包含换页符\f、换行符\n、回车符\r、水平制表符\t、垂直制表符\v
\d匹配数字
\un匹配n,这里的n是一个有4个十六进制数字表示的Unicode字符,比如\u597d表示中文字符“好”,那么超过\uffff编号的字符怎么表示呢?ES6的u修饰符会帮你。
2. 要表示出现次数(重复)——限定符
a*表示字符a连续出现次数 >= 0 次
a+表示字符a连续出现次数 >= 1 次
a?表示字符a出现次数 0 或 1 次
a{5}表示字符a连续出现次数 5 次
a{5,}表示字符a连续出现次数 >= 5次
a{5,10}表示字符a连续出现次数为 5到10次 ,包括5和10
3. 匹配位置——定位符和零宽断言
匹配某个位置的表达式都是零宽的,这是主要包含两部分,一是定位符,匹配一个特定位置,二是零宽断言,匹配一个要满足某要求的位置。
定位符有以下几个常用的:
\b匹配单词边界位置,准确的描述是它匹配一个位置,这个位置前后不全是\w能描述的字符,所以像\u597d\babc是可以匹配“好abc”的。
^匹配字符串开始位置,也就是位置0,如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 '\n' 或 '\r' 之后的位置
$匹配字符串结束位置,如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 '\n' 或 '\r' 之前的位置
零宽断言(JS支持的)有以下两个:
(?=exp)匹配一个位置,这个位置的右边能匹配表达式exp,注意这个表达式仅仅匹配一个位置,只是它对于这个位置的右边有要求,而右边的东西是不会被放进结果的,比如用read(?=ing)去匹配“reading”,结果是“read”,而“ing”是不会放进结果的
(?!exp)匹配一个位置,这个位置的右边不能匹配表达式exp
4. 想表达“或”的意思——字符簇和分歧
我们经常会表达“或”的含义,比如这几个字符中的任意一个都行,再比如匹配5个数字或者5个字母都行等等需求。
字符簇可用来表达字符级别的“或”语义,表示的是方括号中的字符任选一:
[abc]表示a、b、c这3个字符中的任意一个,如果字母或者数字是连续的,那么可以用-连起来表示,[b-f]代表从b到f这么多字符中任选一个
[(ab)(cd)]并不会用来匹配字符串“ab”或“cd”,而是匹配a、b、c、d、(、)这6个字符中的任一个,也就是想表达“匹配字符串ab或者cd”这样的需求不能这么做,要这么写ab|cd。但这里要匹配圆括号本身,讲道理是要反斜杠转义的,但是在方括号中,圆括号被当成普通字符看待,即便如此,仍然建议显式地转义
分歧用来表达表达式级别的“或”语义,表示的是匹配|左右任一表达就可:
ab|cd会匹配字符串“ab”或者“cd”
会短路,回想下编程语言中逻辑或的短路,所以用(ab|abc)去匹配字符串“abc”,结果会是“ab”,因为竖线左边的已经满足了,就用左边的匹配结果代表整个正则的结果
5. 想表达“非”的意思——反义
有时候我们想表达“除了某些字符之外”这样的需求,这个时候就要用到反义
\W、\D、\S、\B 用大写字母的这几个元字符表示就是对应小写字母匹配内容的反义,这几个依次匹配“除了字母、数字、下划线外的字符”、“非数字字符”、“非空白符”、“非单词边界位置”
[^aeiou]表示除了a、e、i、o、u外的任一字符,在方括号中且出现在开头位置的^表示排除,如果^在方括号中不出现在开头位置,那么它仅仅代表^字符本身
6. 整体看待和捕获——分组和后向引用
其实你在上面的一些地方已经看到了圆括号,是的,圆括号就是用来分组的,括在一对括号里的就是一个分组。
上面讲的大部分是针对字符级别的,比如重复字母 “A” 5次,可以用A{5}来表示,但是如果想要字符串“ABC”重复5次呢?这个时候就需要用到括号。
括号的第一个作用,将括起来的分组当做一个整体看待,所以你可以像对待字符重复一样在一个分组后面加限定符,比如(ABC){5}。
分组匹配到的内容也就是这个分组捕获到的内容,从左往右,以左括号为标志,每个分组会自动拥有一个从1开始的编号,编号0的分组对应整个正则表达式,JS不支持捕获组显示命名。
括号的第二个作用,分组捕获到的内容,可以在之后通过\分组编号的形式进行后向引用。比如(ab|cd)123\1可以匹配“ab123ab”或者“cd123cd”,但是不能匹配“ab123cd”或“cd123ab”,这里有一对括号,也是第一对括号,所以编号为捕获组1,然后在正则中通过\1去引用了捕获组1的捕获的内容,这叫后向引用。
括号的第三个作用,改变优先级,比如abc|de和(abc|d)e表达的完全不是一个意思。
7. 转义
任何在正则表达式中有作用的字符都建议转义,哪怕有些情况下不转义也能正确,比如[]中的圆括号、^符号等。
8. 优先级问题
优先级从高到低是:
转义 \
括号(圆括号和方括号)(), (?:), (?=), []
字符和位置
竖线 |
9. 贪婪和非贪婪
在限定符中,除了{n}确切表示重复几次,其余的都是一个有下限的范围。
在默认的模式(贪婪)下,会尽可能多的匹配内容。比如用ab*去匹配字符串“abbb”,结果是“abbb”。
而通过在限定符后面加问号?可以进行非贪婪匹配,会尽可能少地匹配。用ab*?去匹配“abbb”,结果会是“a”。
不带问号的限定符也称匹配优先量词,带问号的限定符也称忽略匹配优先量词。
10. 修饰符(匹配选项)
其实正则的匹配选项有很多可选,不同的宿主语言环境下可能各有不同,此处就JS的修饰符作一个说明:
加g修饰符:表示全局匹配,模式将被应用到所有字符串,而不是在发现第一个匹配项时停止
加i修饰符:表示不区分大小写
加m修饰符:表示多行模式,会改变^和$的行为,上文已述
三、JS(ES5)中的正则
JS中的正则由引用类型RegExp表示,下面主要就RegExp类型的创建、两个主要方法和构造函数属性来展开,然后会提及String类型上的模式匹配,最后会简单罗列JS中正则的一些局限。
1. 创建正则表达式
一种是用字面量的方式创建,一种是用构造函数创建,我们始终建议用前者。
//创建一个正则表达式
var exp = /pattern/flags;
//比如
var pattern=/\b[aeiou][a-z]+\b/gi;
//等价下面的构造函数创建
var pattern=new RegExp("\\b[aeiou][a-z]+\\b","gi");
其中pattern可以是任意的正则表达式,flags部分是修饰符,在上文中已经阐述过了,有 g、i、m 这3个(ES5中)。
现在说一下为什么不要用构造函数,因为用构造函数创建正则,可能会导致对一些字符的双重转义,在上面的例子中,构造函数中第一个参数必须传入字符串(ES6可以传字面量),所以字符\ 会被转义成\,因此字面量的\b会变成字符串中的\\b,这样很容易出错,贼多的反斜杠。
2. RegExp上用来匹配提取的方法——exec()
var matches=pattern.exec(str); 接受一个参数:源字符串 返回:结果数组,在没有匹配项的情况下返回null
结果数组包含两个额外属性,index表示匹配项在字符串中的位置,input表示源字符串,结果数组matches第一项即matches[0]表示匹配整个正则表达式匹配的字符串,matches[n]表示于模式中第n个捕获组匹配的字符串。
要注意的是,第一,exec()永远只返回一个匹配项(指匹配整个正则的),第二,如果设置了g修饰符,每次调用exec()会在字符串中继续查找新匹配项,不设置g修饰符,对一个字符串每次调用exec()永远只返回第一个匹配项。所以如果要匹配一个字符串中的所有需要匹配的地方,那么可以设置g修饰符,然后通过循环不断调用exec方法。
//匹配所有ing结尾的单词
var str="Reading and Writing";
var pattern=/\b([a-zA-Z]+)ing\b/g;
var matches;
while(matches=pattern.exec(str)){
console.log(matches.index +' '+ matches[0] + ' ' + matches[1]);
}
//循环2次输出
//0 Reading Read
//12 Writing Writ
3. RegExp上用来测试匹配成功与否的方法——test()
var result=pattern.test(str);
接受一个参数:源字符串
返回:找到匹配项,返回true,没找到返回false
4. RegExp构造函数属性
RegExp构造函数包含一些属性,适用于作用域中的所有正则表达式,并且基于所执行的最近一次正则表达式操作而变化。
RegExp.input或RegExp["$_"]:最近一次要匹配的字符串
RegExp.lastMatch或RegExp["$&"]:最近一次匹配项
RegExp.lastParen或RegExp["$+"]:最近一次匹配的捕获组
RegExp.leftContext或RegExp["$`"]:input字符串中lastMatch之前的文本
RegExp.rightContext或RegExp["$'"]:input字符串中lastMatch之后的文本
RegExp["$n"]:表示第n个捕获组的内容,n取1-9
5. String类型上的模式匹配方法
上面提到的exec和test都是在RegExp实例上的方法,调用主体是一个正则表达式,而以字符串为主体调用模式匹配也是最为常用的。
5.1 匹配捕获的match方法
在字符串上调用match方法,本质上和在正则上调用exec相同,但是match方法返回的结果数组是没有input和index属性的。
var str="Reading and Writing"; var pattern=/\b([a-zA-Z]+)ing\b/g; //在String上调用match var matches=str.match(pattern); //等价于在RegExp上调用exec var matches=pattern.exec(str);
5.2 返回索引的search方法
接受的参数和match方法相同,要么是一个正则表达式,要么是一个RegExp对象。
//下面两个控制台输出是一样的,都是5 var str="I am reading."; var pattern=/\b([a-zA-Z]+)ing\b/g; var matches=pattern.exec(str); console.log(matches.index); var pos=str.search(pattern); console.log(pos);
5.3 查找并替换的replace方法
var result=str.replace(RegExp or String, String or Function); 第一个参数(查找):RegExp对象或者是一个字符串(这个字符串就被看做一个平凡的字符串) 第二个参数(替换内容):一个字符串或者是一个函数 返回:替换后的结果字符串,不会改变原来的字符串
第一个参数是字符串
只会替换第一个子字符串
第一个参数是正则
指定g修饰符,则会替换所有匹配正则的地方,否则只替换第一处
第二个参数是字符串
可以使用一些特殊的字符序列,将正则表达式操作的值插进入,这是很常用的。
$n:匹配第n个捕获组的内容,n取0-9
$nn:匹配第nn个捕获组内容,nn取01-99
$`:匹配子字符串之后的字符串
$':匹配子字符串之前的字符串
$&:匹配整个模式得字符串
$$:表示$符号本身
第二个参数是一个函数
在只有一个匹配项的情况下,会传递3个参数给这个函数:模式的匹配项、匹配项在字符串中的位置、原始字符串
在有多个捕获组的情况下,传递的参数是模式匹配项、第一个捕获组、第二个、第三个...最后两个参数是模式的匹配项在字符串位置、原始字符串
这个函数要返回一个字符串,表示要替换掉的匹配项
5.4 分隔字符串的split
基于指定的分隔符将一个字符串分割成多个子字符串,将结果放入一个数组,接受的第一个参数可以是RegExp对象或者是一个字符串(不会被转为正则),第二个参数可选指定数组大小,确保数组不会超过既定大小。
6 JS(ES5)中正则的局限
JS(ES5)中不支持以下正则特性(在一览图中也可以看到):
匹配字符串开始和结尾的\A和\Z锚 向后查找(所以不支持零宽度后发断言) 并集和交集类 原子组 Unicode支持(\uFFFF之后的) 命名的捕获组 单行和无间隔模式 条件匹配 注释
四、ES6对正则的主要加强
ES6对正则做了一些加强,这边仅仅简单罗列以下主要的3点,具体可以去看ES6
1. 构造函数可以传正则字面量了
ES5中构造函数是不能接受字面量的正则的,所以会有双重转义,但是ES6是支持的,即便如此,还是建议用字面量创建,简洁高效。
2. u修饰符
加了u修饰符,会正确处理大于\uFFFF的Unicode,意味着4个字节的Unicode字符也可以被支持了。
// \uD83D\uDC2A是一个4字节的UTF-16编码,代表一个字符
/^\uD83D/u.test('\uD83D\uDC2A')
// false,加了u可以正确处理
/^\uD83D/.test('\uD83D\uDC2A')
// true,不加u,当做两个unicode字符处理
加了u修饰符,会改变一些正则的行为:
.原本只能匹配不大于\uFFFF的字符,加了u修饰符可以匹配任何Unicode字符
Unicode字符新表示法\u{码点}必须在加了u修饰符后才是有效的
使用u修饰符后,所有量词都会正确识别码点大于0xFFFF的Unicode字符
使一些反义元字符对于大于\uFFFF的字符也生效
3. y修饰符
y修饰符的作用与g修饰符类似,也是全局匹配,开始从位置0开始,后一次匹配都从上一次匹配成功的下一个位置开始。
不同之处在于,g修饰符只要剩余位置中存在匹配就可,而y修饰符确保匹配必须从剩余的第一个位置开始。
所以/a/y去匹配"ba"会匹配失败,因为y修饰符要求,在剩余位置第一个位置(这里是位置0)开始就要匹配。
ES6对正则的加强,可以看这篇
五、应用正则的实践思路
应用正则,一般是要先想到正则(废话),只要看到和“找”相关的需求并且这个源是可以被字符串化的,就可以想到用正则试试。
一般在应用正则有两类情况,一是验证类问题,另一类是搜索、提取、替换类问题。验证,最常见的如表单验证;搜索,以某些设定的命令加关键词去搜索;提取,从某段文字中提取什么,或者从某个JSON对象中提取什么(因为JSON对象可以字符串化啊);替换,模板引擎中用到。
1. 验证类问题
验证类问题是我们最常遇到的,这个时候其实源字符串长什么样我们是不知道,鬼知道萌萌哒的用户会做出什么邪恶的事情来,推荐的方式是这样的:
首先用白话描述清楚你要怎样的字符串,描述好了之后,就开脑洞地想用户可能输入什么奇怪的东西,就是自己举例,拿一张纸可举一大堆的,有接受的和不接受的(这个是你知道的),这个过程中可能你会去修改之前的描述;
把你的描述拆解开来,翻译成正则表达式;
测试你的正则表达式对你之前举的例子的判断是不是和你预期一致,这里就推荐用在线的JS正则测试去做,不要自己去一遍遍写了。
2. 搜索、提取、替换类问题
这类问题,一般我们是知道源文本的格式或者大致内容的,所以在解决这类问题时一般已经会有一些测试的源数据,我们要从这些源数据中提取出什么、或者替换什么。
找到这些手上的源数据中你需要的部分;
观察这些部分的特征,这些部分本身的特征以及这些部分周围的特征,比如这部分前一个符号一定是一个逗号,后一个符号一定是一个冒号,总之就是找规律;
考察你找的特征,首先能不能确切地标识出你要的部分,不会少也不会多,然后考虑下以后的源数据也是如此么,以后会不会这些特征就没有了;
组织你对要找的这部分的描述,描述清楚经过你考察的特征;
翻译成正则表达式;
测试。
终于絮絮叨叨写完了,1万多字有关JS正则的讲解,写完发现自己对正则的熟练又进了一步,所以推荐大家经常做做梳理,很有用,然后乐于分享,于己于人都是大有裨益,感谢能看完的所有人。
相信看了本文案例你已经掌握了方法,更多精彩请关注php中文网其它相关文章!
推荐阅读:
以上是解析JS正则的原理和语法的详细内容。更多信息请关注PHP中文网其他相关文章!

 es6数组怎么去掉重复并且重新排序May 05, 2022 pm 07:08 PM
es6数组怎么去掉重复并且重新排序May 05, 2022 pm 07:08 PM去掉重复并排序的方法:1、使用“Array.from(new Set(arr))”或者“[…new Set(arr)]”语句,去掉数组中的重复元素,返回去重后的新数组;2、利用sort()对去重数组进行排序,语法“去重数组.sort()”。
 JavaScript的Symbol类型、隐藏属性及全局注册表详解Jun 02, 2022 am 11:50 AM
JavaScript的Symbol类型、隐藏属性及全局注册表详解Jun 02, 2022 am 11:50 AM本篇文章给大家带来了关于JavaScript的相关知识,其中主要介绍了关于Symbol类型、隐藏属性及全局注册表的相关问题,包括了Symbol类型的描述、Symbol不会隐式转字符串等问题,下面一起来看一下,希望对大家有帮助。
 原来利用纯CSS也能实现文字轮播与图片轮播!Jun 10, 2022 pm 01:00 PM
原来利用纯CSS也能实现文字轮播与图片轮播!Jun 10, 2022 pm 01:00 PM怎么制作文字轮播与图片轮播?大家第一想到的是不是利用js,其实利用纯CSS也能实现文字轮播与图片轮播,下面来看看实现方法,希望对大家有所帮助!
 JavaScript对象的构造函数和new操作符(实例详解)May 10, 2022 pm 06:16 PM
JavaScript对象的构造函数和new操作符(实例详解)May 10, 2022 pm 06:16 PM本篇文章给大家带来了关于JavaScript的相关知识,其中主要介绍了关于对象的构造函数和new操作符,构造函数是所有对象的成员方法中,最早被调用的那个,下面一起来看一下吧,希望对大家有帮助。
 JavaScript面向对象详细解析之属性描述符May 27, 2022 pm 05:29 PM
JavaScript面向对象详细解析之属性描述符May 27, 2022 pm 05:29 PM本篇文章给大家带来了关于JavaScript的相关知识,其中主要介绍了关于面向对象的相关问题,包括了属性描述符、数据描述符、存取描述符等等内容,下面一起来看一下,希望对大家有帮助。
 javascript怎么移除元素点击事件Apr 11, 2022 pm 04:51 PM
javascript怎么移除元素点击事件Apr 11, 2022 pm 04:51 PM方法:1、利用“点击元素对象.unbind("click");”方法,该方法可以移除被选元素的事件处理程序;2、利用“点击元素对象.off("click");”方法,该方法可以移除通过on()方法添加的事件处理程序。
 整理总结JavaScript常见的BOM操作Jun 01, 2022 am 11:43 AM
整理总结JavaScript常见的BOM操作Jun 01, 2022 am 11:43 AM本篇文章给大家带来了关于JavaScript的相关知识,其中主要介绍了关于BOM操作的相关问题,包括了window对象的常见事件、JavaScript执行机制等等相关内容,下面一起来看一下,希望对大家有帮助。
 foreach是es6里的吗May 05, 2022 pm 05:59 PM
foreach是es6里的吗May 05, 2022 pm 05:59 PMforeach不是es6的方法。foreach是es3中一个遍历数组的方法,可以调用数组的每个元素,并将元素传给回调函数进行处理,语法“array.forEach(function(当前元素,索引,数组){...})”;该方法不处理空数组。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

Dreamweaver Mac版
视觉化网页开发工具

