


有时候因为工作、自身的需求,我们都会去浏览不同网站去获取我们需要的数据,于是爬虫应运而生,下面是我在开发一个简单爬虫的经过与遇到的问题。
开发一个爬虫,首先你要知道你的这个爬虫是要用来做什么的。我是要用来去不同网站找特定关键字的文章,并获取它的链接,以便我快速阅读。
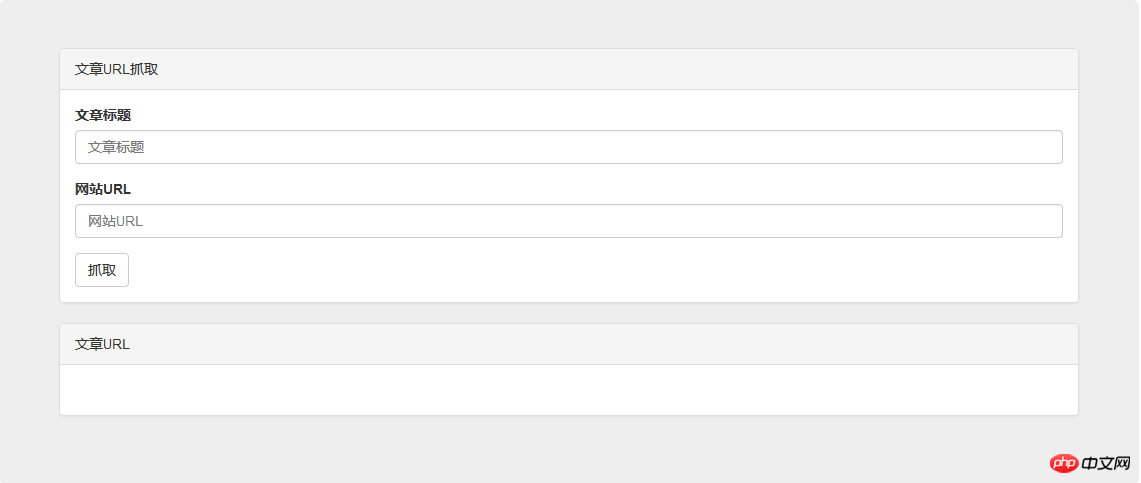
按照个人习惯,我首先要写一个界面,理清下思路。
1、去不同网站。那么我们需要一个url输入框。
2、找特定关键字的文章。那么我们需要一个文章标题输入框。
3、获取文章链接。那么我们需要一个搜索结果的显示容器。
<p class="jumbotron" id="mainJumbotron">
<p class="panel panel-default">
<p class="panel-heading">文章URL抓取</p>
<p class="panel-body">
<p class="form-group">
<label for="article_title">文章标题</label>
<input type="text" class="form-control" id="article_title" placeholder="文章标题">
</p>
<p class="form-group">
<label for="website_url">网站URL</label>
<input type="text" class="form-control" id="website_url" placeholder="网站URL">
</p>
<button type="submit" class="btn btn-default">抓取</button>
</p>
</p>
<p class="panel panel-default">
<p class="panel-heading">文章URL</p>
<p class="panel-body">
<h3></h3>
</p>
</p>
</p>直接上代码,然后加上自己的一些样式调整,界面就完成啦:
那么接下来就是功能的实现了,我用PHP来写,首先第一步就是获取网站的html代码,获取html代码的方式也有很多,我就不一一介绍了,这里用了curl来获取,传入网站url就能得到html代码啦:
private function get_html($url){
$ch = curl_init();
$timeout = 10;
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.131 Safari/537.36');
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, $timeout);
$html = curl_exec($ch);
return $html;
}虽然得到了html代码,但是很快你会遇到一个问题,那就是编码问题,这可能让你下一步的匹配无功而返,我们这里统一把得到的html内容转为utf8编码:
$coding = mb_detect_encoding($html); if ($coding != "UTF-8" || !mb_check_encoding($html, "UTF-8")) $html = mb_convert_encoding($html, 'utf-8', 'GBK,UTF-8,ASCII');
得到网站的html,要获取文章的url,那么下一步就是要匹配该网页下的所有a标签,需要用到正则表达式,经过多次测试,最终得到一个比较靠谱的正则表达式,不管a标签下结构多复杂,只要是a标签的都不放过:(最关键的一步)
$pattern = '|<a[^>]*>(.*)</a>|isU'; preg_match_all($pattern, $html, $matches);
匹配的结果在$matches中,它大概是这样的一个多维素组:
array(2) {
[0]=>
array(*) {
[0]=>
string(*) "完整的a标签"
.
.
.
}
[1]=>
array(*) {
[0]=>
string(*) "与上面下标相对应的a标签中的内容"
}
}只要能得到这个数据,其他就完全可以操作啦,你可以遍历这个素组,找到你想要a标签,然后获取a标签相应的属性,想怎么操作就怎么操作啦,下面推荐一个类,让你更方便操作a标签:
$dom = new DOMDocument();
@$dom->loadHTML($a);//$a是上面得到的一些a标签
$url = new DOMXPath($dom);
$hrefs = $url->evaluate('//a');
for ($i = 0; $i < $hrefs->length; $i++) {
$href = $hrefs->item($i);
$url = $href->getAttribute('href'); //这里获取a标签的href属性
}当然,这只是一种方式,你也可以通过正则表达式匹配你想要的信息,把数据玩出新花样。
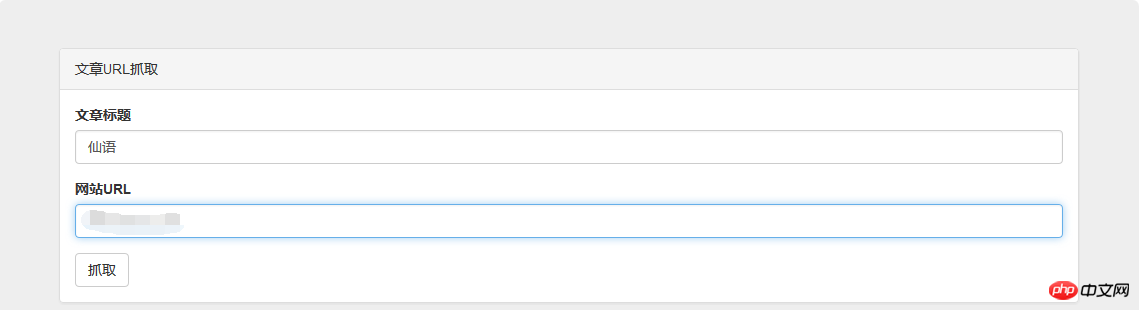
得到并匹配得出你想要的结果,下一步当然就是传回前端将他们显示出来啦,把接口写好,然后前端用js获取数据,用jquery动态添加内容显示出来:
var website_url = '你的接口地址';
$.getJSON(website_url,function(data){
if(data){
if(data.text == ''){
$('#article_url').html('<p><p>暂无该文章链接</p></p>');
return;
}
var string = '';
var list = data.text;
for (var j in list) {
var content = list[j].url_content;
for (var i in content) {
if (content[i].title != '') {
string += '<p class="item">' +
'<em>[<a href="http://' + list[j].website.web_url + '" target="_blank">' + list[j].website.web_name + '</a>]</em>' +
'<a href=" ' + content[i].url + '" target="_blank" class="web_url">' + content[i].title + '</a>' +
'</p>';
}
}
}
$('#article_url').html(string);
});上最终效果图:

以上是php实现简单爬虫的开发案例的详细内容。更多信息请关注PHP中文网其他相关文章!

 PHP类型提示如何起作用,包括标量类型,返回类型,联合类型和无效类型?Apr 17, 2025 am 12:25 AM
PHP类型提示如何起作用,包括标量类型,返回类型,联合类型和无效类型?Apr 17, 2025 am 12:25 AMPHP类型提示提升代码质量和可读性。1)标量类型提示:自PHP7.0起,允许在函数参数中指定基本数据类型,如int、float等。2)返回类型提示:确保函数返回值类型的一致性。3)联合类型提示:自PHP8.0起,允许在函数参数或返回值中指定多个类型。4)可空类型提示:允许包含null值,处理可能返回空值的函数。
 PHP如何处理对象克隆(克隆关键字)和__clone魔法方法?Apr 17, 2025 am 12:24 AM
PHP如何处理对象克隆(克隆关键字)和__clone魔法方法?Apr 17, 2025 am 12:24 AMPHP中使用clone关键字创建对象副本,并通过\_\_clone魔法方法定制克隆行为。1.使用clone关键字进行浅拷贝,克隆对象的属性但不克隆对象属性内的对象。2.通过\_\_clone方法可以深拷贝嵌套对象,避免浅拷贝问题。3.注意避免克隆中的循环引用和性能问题,优化克隆操作以提高效率。
 PHP与Python:用例和应用程序Apr 17, 2025 am 12:23 AM
PHP与Python:用例和应用程序Apr 17, 2025 am 12:23 AMPHP适用于Web开发和内容管理系统,Python适合数据科学、机器学习和自动化脚本。1.PHP在构建快速、可扩展的网站和应用程序方面表现出色,常用于WordPress等CMS。2.Python在数据科学和机器学习领域表现卓越,拥有丰富的库如NumPy和TensorFlow。
 描述不同的HTTP缓存标头(例如,Cache-Control,ETAG,最后修饰)。Apr 17, 2025 am 12:22 AM
描述不同的HTTP缓存标头(例如,Cache-Control,ETAG,最后修饰)。Apr 17, 2025 am 12:22 AMHTTP缓存头的关键玩家包括Cache-Control、ETag和Last-Modified。1.Cache-Control用于控制缓存策略,示例:Cache-Control:max-age=3600,public。2.ETag通过唯一标识符验证资源变化,示例:ETag:"686897696a7c876b7e"。3.Last-Modified指示资源最后修改时间,示例:Last-Modified:Wed,21Oct201507:28:00GMT。
 说明PHP中的安全密码散列(例如,password_hash,password_verify)。为什么不使用MD5或SHA1?Apr 17, 2025 am 12:06 AM
说明PHP中的安全密码散列(例如,password_hash,password_verify)。为什么不使用MD5或SHA1?Apr 17, 2025 am 12:06 AM在PHP中,应使用password_hash和password_verify函数实现安全的密码哈希处理,不应使用MD5或SHA1。1)password_hash生成包含盐值的哈希,增强安全性。2)password_verify验证密码,通过比较哈希值确保安全。3)MD5和SHA1易受攻击且缺乏盐值,不适合现代密码安全。
 PHP:服务器端脚本语言的简介Apr 16, 2025 am 12:18 AM
PHP:服务器端脚本语言的简介Apr 16, 2025 am 12:18 AMPHP是一种服务器端脚本语言,用于动态网页开发和服务器端应用程序。1.PHP是一种解释型语言,无需编译,适合快速开发。2.PHP代码嵌入HTML中,易于网页开发。3.PHP处理服务器端逻辑,生成HTML输出,支持用户交互和数据处理。4.PHP可与数据库交互,处理表单提交,执行服务器端任务。
 PHP和网络:探索其长期影响Apr 16, 2025 am 12:17 AM
PHP和网络:探索其长期影响Apr 16, 2025 am 12:17 AMPHP在过去几十年中塑造了网络,并将继续在Web开发中扮演重要角色。1)PHP起源于1994年,因其易用性和与MySQL的无缝集成成为开发者首选。2)其核心功能包括生成动态内容和与数据库的集成,使得网站能够实时更新和个性化展示。3)PHP的广泛应用和生态系统推动了其长期影响,但也面临版本更新和安全性挑战。4)近年来的性能改进,如PHP7的发布,使其能与现代语言竞争。5)未来,PHP需应对容器化、微服务等新挑战,但其灵活性和活跃社区使其具备适应能力。
 为什么要使用PHP?解释的优点和好处Apr 16, 2025 am 12:16 AM
为什么要使用PHP?解释的优点和好处Apr 16, 2025 am 12:16 AMPHP的核心优势包括易于学习、强大的web开发支持、丰富的库和框架、高性能和可扩展性、跨平台兼容性以及成本效益高。1)易于学习和使用,适合初学者;2)与web服务器集成好,支持多种数据库;3)拥有如Laravel等强大框架;4)通过优化可实现高性能;5)支持多种操作系统;6)开源,降低开发成本。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

Atom编辑器mac版下载
最流行的的开源编辑器

PhpStorm Mac 版本
最新(2018.2.1 )专业的PHP集成开发工具

禅工作室 13.0.1
功能强大的PHP集成开发环境

WebStorm Mac版
好用的JavaScript开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

