


根据上面所学的CSS基础语法知识,现在来实现字段的解析。首先还是解析标题。打开网页开发者工具,找到标题所对应的源代码。本文主要介绍了CSS选择器实现字段解析的相关资料,需要的朋友可以参考下,希望能帮助到大家
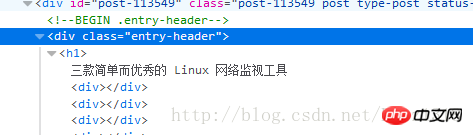
发现是在p class="entry-header"下面的h1节点中,于是打开scrapy shell 进行调试

但是我不想要4a249f0d628e2318394fd9b75b4636b1这种标签该咋办,这时候就要使用CSS选择器中的伪类方法。如下所示。

注意的是两个冒号。使用CSS选择器真的很方便。同理我用CSS实现字段解析。代码如下
# -*- coding: utf-8 -*-
import scrapy
import re
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/113549/']
def parse(self, response):
# title = response.xpath('//p[@class = "entry-header"]/h1/text()').extract()[0]
# create_date = response.xpath("//p[@class = 'entry-meta-hide-on-mobile']/text()").extract()[0].strip().replace("·","").strip()
# praise_numbers = response.xpath("//span[contains(@class,'vote-post-up')]/h10/text()").extract()[0]
# fav_nums = response.xpath("//span[contains(@class,'bookmark-btn')]/text()").extract()[0]
# match_re = re.match(".*?(\d+).*",fav_nums)
# if match_re:
# fav_nums = match_re.group(1)
# comment_nums = response.xpath("//a[@href='#article-comment']/span").extract()[0]
# match_re = re.match(".*?(\d+).*", comment_nums)
# if match_re:
# comment_nums = match_re.group(1)
# content = response.xpath("//p[@class='entry']").extract()[0]
#通过CSS选择器提取字段
title = response.css(".entry-header h1::text").extract()[0]
create_date = response.css(".entry-meta-hide-on-mobile::text").extract()[0].strip().replace("·","").strip()
praise_numbers = response.css(".vote-post-up h10::text").extract()[0]
fav_nums = response.css("span.bookmark-btn::text").extract()[0]
match_re = re.match(".*?(\d+).*", fav_nums)
if match_re:
fav_nums = match_re.group(1)
comment_nums = response.css("a[href='#article-comment'] span::text").extract()[0]
match_re = re.match(".*?(\d+).*", comment_nums)
if match_re:
comment_nums = match_re.group(1)
content = response.css("p.entry").extract()[0]
tags = response.css("p.entry-meta-hide-on-mobile a::text").extract()[0]
pass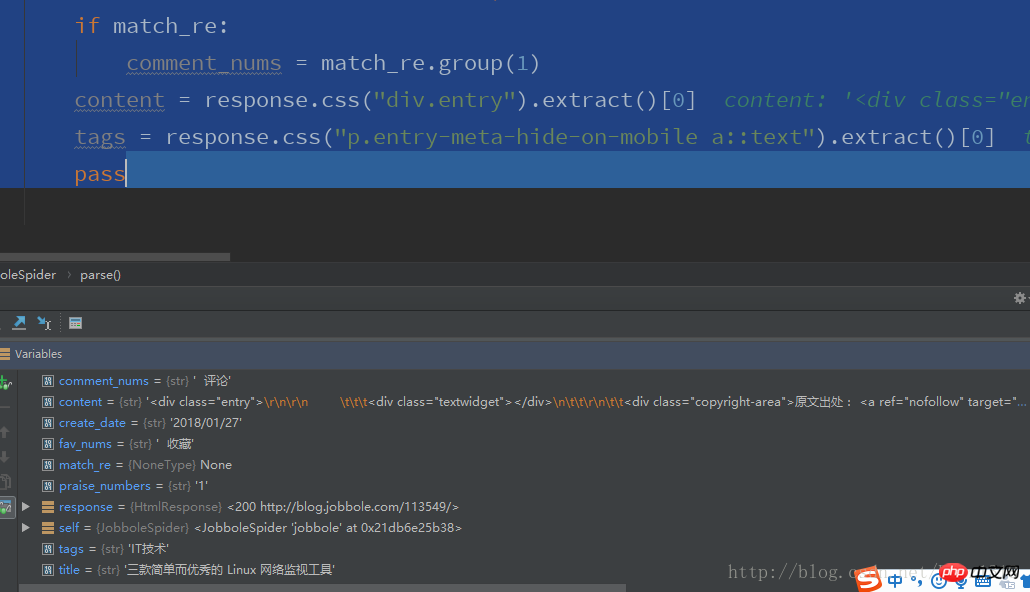
相关推荐:
以上是CSS选择器字段解析的实现方法的详细内容。更多信息请关注PHP中文网其他相关文章!

 css中id选择符的标识是什么Sep 22, 2022 pm 03:57 PM
css中id选择符的标识是什么Sep 22, 2022 pm 03:57 PM在css中,id选择符的标识是“#”,可以为标有特定id属性值的HTML元素指定特定的样式,语法结构“#ID值 {属性 : 属性值;}”。ID属性在整个页面中是唯一不可重复的;ID属性值不要以数字开头,数字开头的ID在Mozilla/Firefox浏览器中不起作用。
 使用:nth-child(n+3)伪类选择器选择位置大于等于3的子元素的样式Nov 20, 2023 am 11:20 AM
使用:nth-child(n+3)伪类选择器选择位置大于等于3的子元素的样式Nov 20, 2023 am 11:20 AM使用:nth-child(n+3)伪类选择器选择位置大于等于3的子元素的样式,具体代码示例如下:HTML代码:<divid="container"><divclass="item">第一个子元素</div><divclass="item"&
 css伪选择器学习之伪类选择器解析Aug 03, 2022 am 11:26 AM
css伪选择器学习之伪类选择器解析Aug 03, 2022 am 11:26 AM在之前的文章《css伪选择器学习之伪元素选择器解析》中,我们学习了伪元素选择器,而今天我们详细了解一下伪类选择器,希望对大家有所帮助!
 javascript选择器失效怎么办Feb 10, 2023 am 10:15 AM
javascript选择器失效怎么办Feb 10, 2023 am 10:15 AMjavascript选择器失效是因为代码不规范导致的,其解决办法:1、把引入的JS代码去掉,ID选择器方法即可有效;2、在引入“jquery.js”之前引入指定JS代码即可。
 从入门到精通:掌握is与where选择器的使用技巧Sep 08, 2023 am 09:15 AM
从入门到精通:掌握is与where选择器的使用技巧Sep 08, 2023 am 09:15 AM从入门到精通:掌握is与where选择器的使用技巧引言:在进行数据处理和分析的过程中,选择器(selector)是一项非常重要的工具。通过选择器,我们可以按照特定的条件从数据集中提取所需的数据。本文将介绍is和where选择器的使用技巧,帮助读者快速掌握这两个选择器的强大功能。一、is选择器的使用is选择器是一种基本的选择器,它允许我们根据给定条件对数据集进
 css中的选择器包括超文本标记选择器吗Sep 01, 2022 pm 05:25 PM
css中的选择器包括超文本标记选择器吗Sep 01, 2022 pm 05:25 PM不包括。css选择器有:1、标签选择器,是通过HTML页面的元素名定位具体HTML元素;2、类选择器,是通过HTML元素的class属性的值定位具体HTML元素;3、ID选择器,是通过HTML元素的id属性的值定位具体HTML元素;4、通配符选择器“*”,可以指代所有类型的标签元素,包括自定义元素;5、属性选择器,是通过HTML元素已经存在属性名或属性值来定位具体HTML元素。
 深度解析is与where选择器:提升CSS编程水平Sep 08, 2023 pm 08:22 PM
深度解析is与where选择器:提升CSS编程水平Sep 08, 2023 pm 08:22 PM深度解析is与where选择器:提升CSS编程水平引言:在CSS编程过程中,选择器是必不可少的元素。它们允许我们根据特定的条件选择HTML文档中的元素并对其进行样式化。在这篇文章中,我们将深入探讨两个常用的选择器,即:is选择器和where选择器。通过了解它们的工作原理和使用场景,我们可以大大提升CSS编程的水平。一、is选择器is选择器是一个非常强大的选择
 wxss选择器有哪些Sep 28, 2023 pm 04:27 PM
wxss选择器有哪些Sep 28, 2023 pm 04:27 PMwxss选择器有元素选择器、类选择器、ID选择器、伪类选择器、子元素选择器、属性选择器、后代选择器和通配选择器等。详细介绍:1、元素选择器,使用元素名称作为选择器,选取匹配的元素,使用“view”选择器可以选取所有的“view”组件;2、类选择器,使用类名作为选择器,选取具有特定类名的元素,使用“.classname”选择器可以选取具有“.classname”类名的元素等等。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

SublimeText3 Linux新版
SublimeText3 Linux最新版

Atom编辑器mac版下载
最流行的的开源编辑器

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

禅工作室 13.0.1
功能强大的PHP集成开发环境

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

