


本文主要为大家带来一篇python爬取安居客二手房网站数据(实例讲解)。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧,希望能帮助到大家。
现在开始正式进行爬虫书写首先,需要分析一下要爬取的网站的结构:作为一名河南的学生,那就看看郑州的二手房信息吧!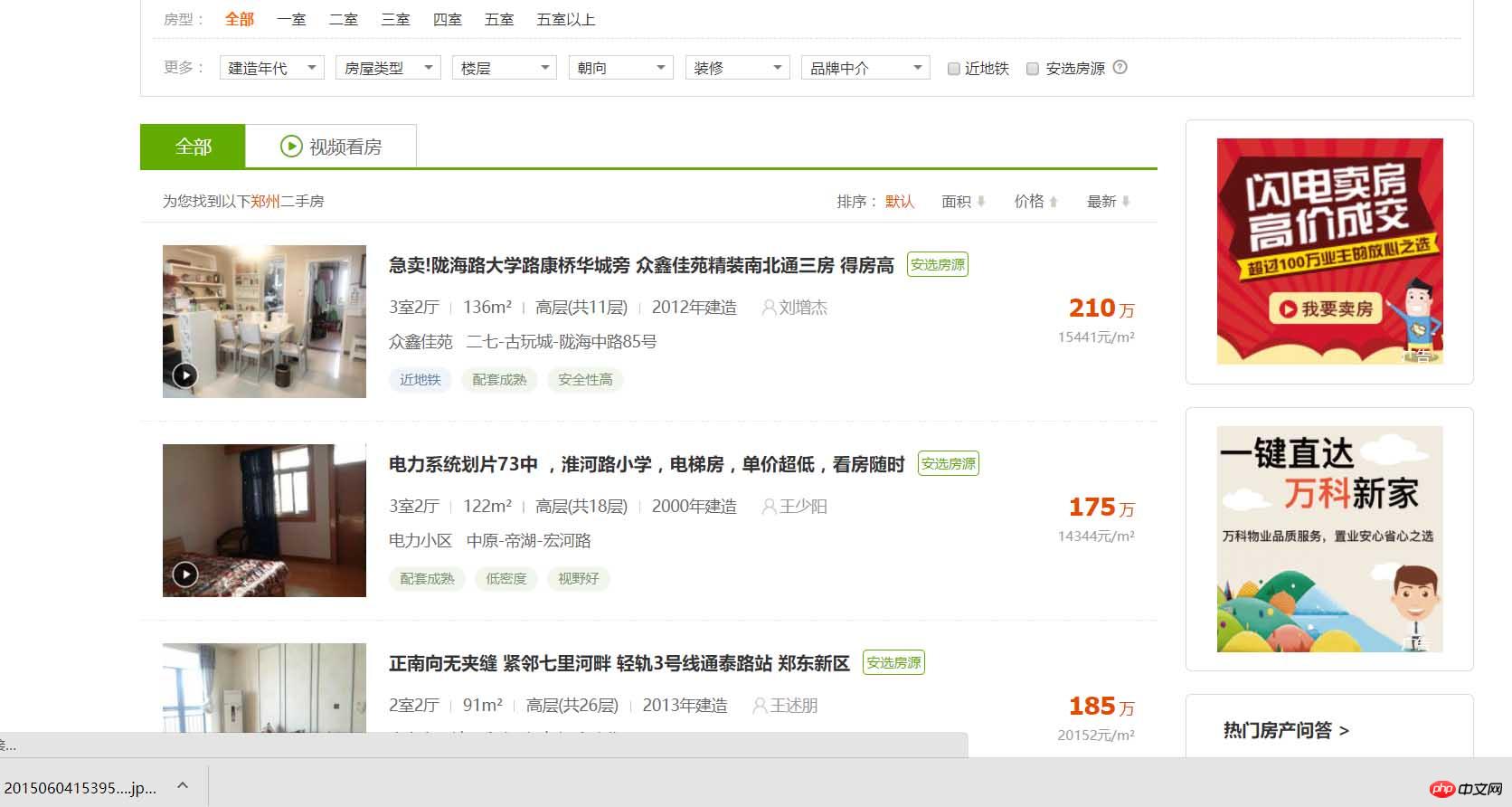
在上面这个页面中,我们可以看到一条条的房源信息,由上可以看到网页一条条的房源信息,点击进去后就会发现:
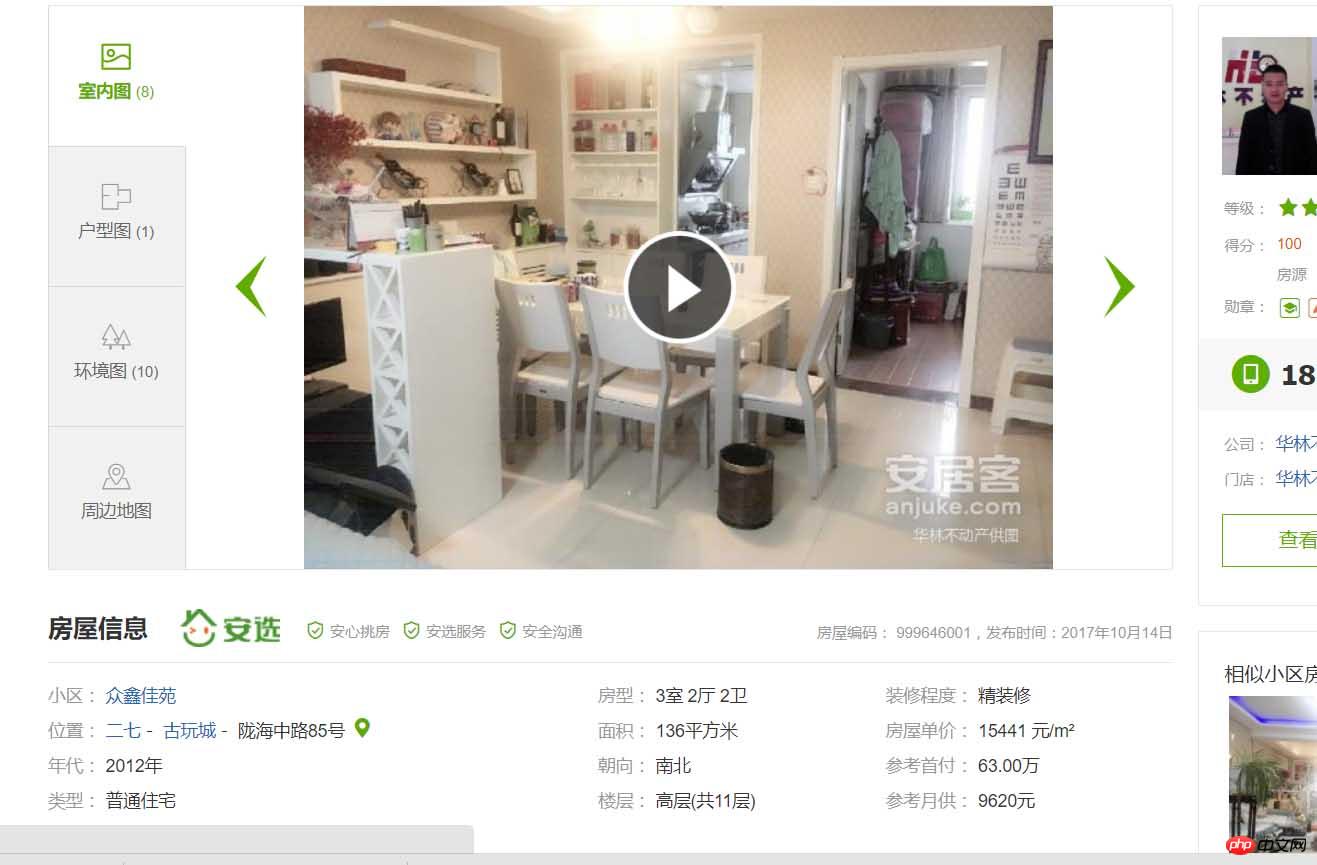
房源的详细信息。OK!那么我们要干嘛呢,就是把郑州这个地区的二手房房源信息都能拿到手,可以保存到数据库中,用来干嘛呢,作为一个地理人,还是有点用处的,这次就不说了好,正式开始,首先我采用python3.6 中的requests,BeautifulSoup模块来进行爬取页面,首先由requests模块进行请求:
# 网页的请求头
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'
}
# url链接
url = 'https://zhengzhou.anjuke.com/sale/'
response = requests.get(url, headers=header)
print(response.text)执行后就会得到这个网站的html代码了
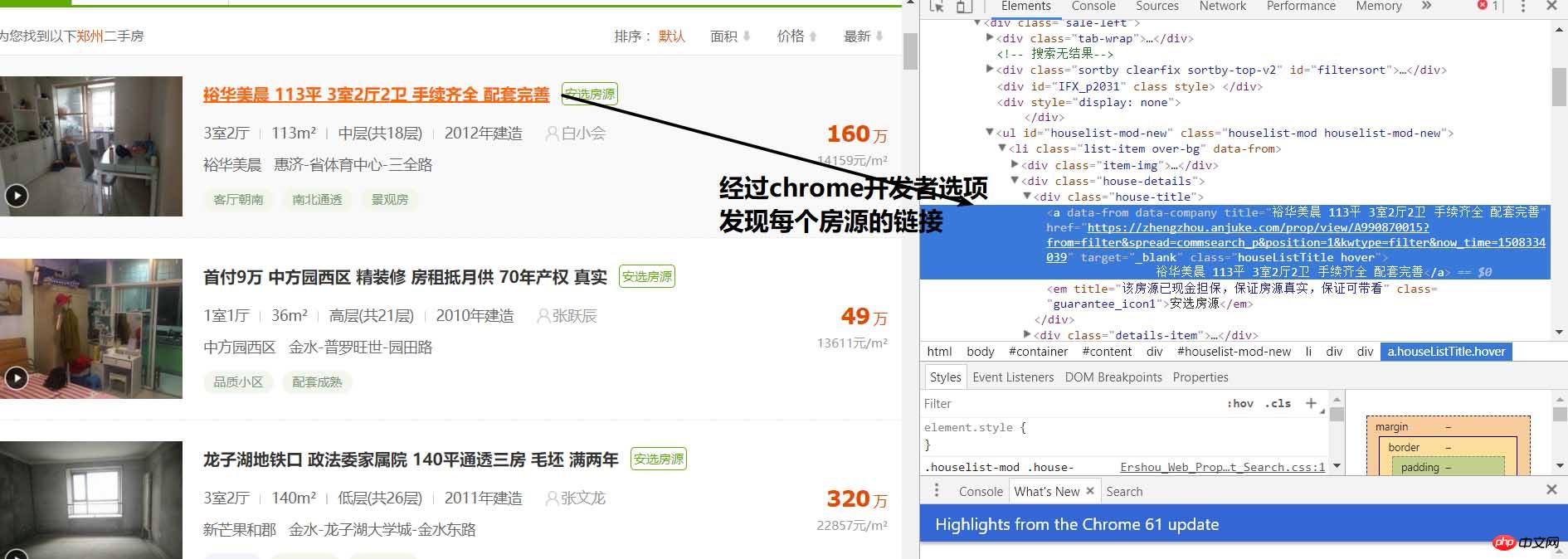
 通过分析可以得到每个房源都在class="list-item"的 li 标签中,那么我们就可以根据BeautifulSoup包进行提取
通过分析可以得到每个房源都在class="list-item"的 li 标签中,那么我们就可以根据BeautifulSoup包进行提取
# 通过BeautifulSoup进行解析出每个房源详细列表并进行打印
soup = BeautifulSoup(response.text, 'html.parser')
result_li = soup.find_all('li', {'class': 'list-item'})
for i in result_li:
print(i)通过打印就能进一步减少了code量,好,继续提取
# 通过BeautifulSoup进行解析出每个房源详细列表并进行打印
soup = BeautifulSoup(response.text, 'html.parser')
result_li = soup.find_all('li', {'class': 'list-item'})
# 进行循环遍历其中的房源详细列表
for i in result_li:
# 由于BeautifulSoup传入的必须为字符串,所以进行转换
page_url = str(i)
soup = BeautifulSoup(page_url, 'html.parser')
# 由于通过class解析的为一个列表,所以只需要第一个参数
result_href = soup.find_all('a', {'class': 'houseListTitle'})[0]
print(result_href.attrs['href'])这样,我们就能看到一个个的url了,是不是很喜欢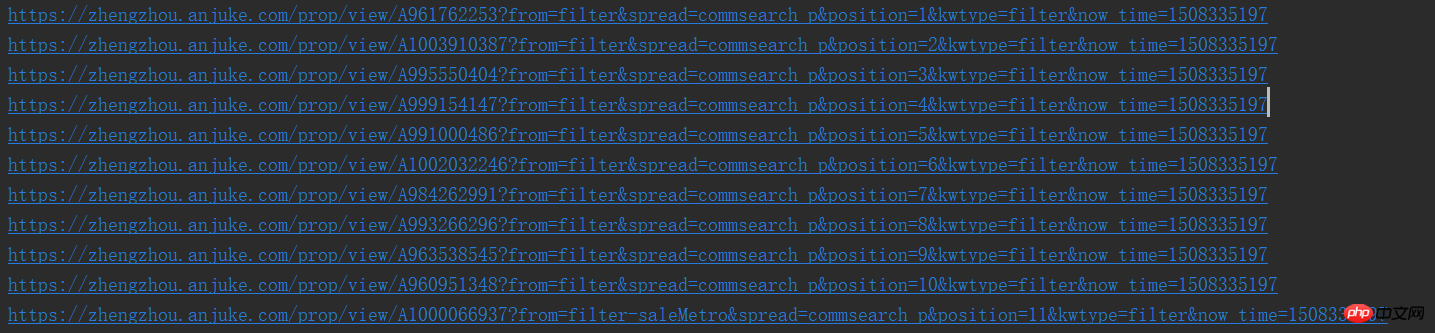
好了,按正常的逻辑就要进入页面开始分析详细页面了,但是爬取完后如何进行下一页的爬取呢所以,我们就需要先分析该页面是否有下一页
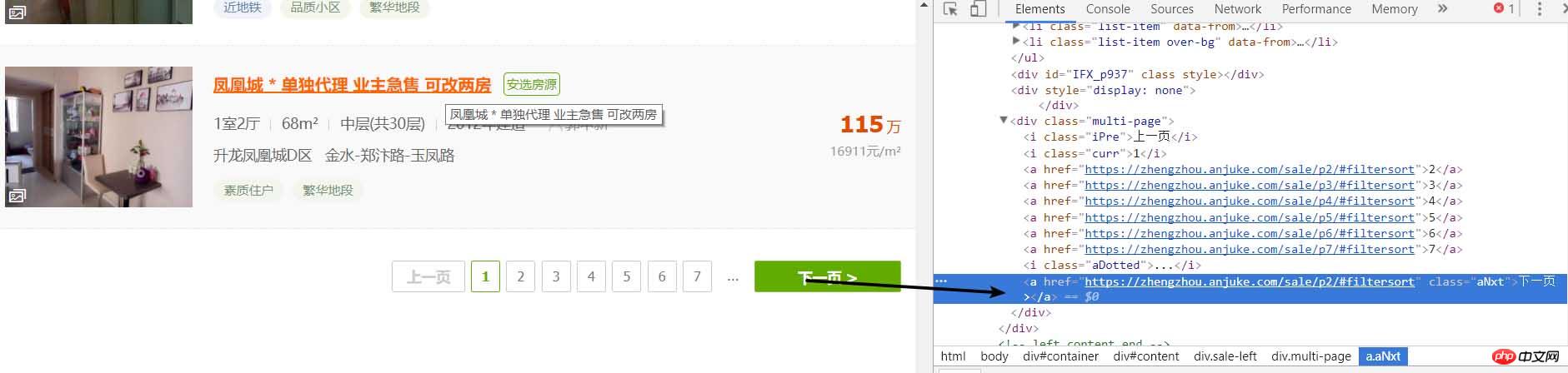
同样的方法就可以发现下一页同样是如此的简单,那么咱们就可以还是按原来的配方原来的味道继续
# 进行下一页的爬取
result_next_page = soup.find_all('a', {'class': 'aNxt'})
if len(result_next_page) != 0:
print(result_next_page[0].attrs['href'])
else:
print('没有下一页了')因为当存在下一页的时候,网页中就是一个a标签,如果没有的话,就会成为i标签了,所以这样的就行,因此,我们就能完善一下,将以上这些封装为一个函数
import requests
from bs4 import BeautifulSoup
# 网页的请求头
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'
}
def get_page(url):
response = requests.get(url, headers=header)
# 通过BeautifulSoup进行解析出每个房源详细列表并进行打印
soup = BeautifulSoup(response.text, 'html.parser')
result_li = soup.find_all('li', {'class': 'list-item'})
# 进行下一页的爬取
result_next_page = soup.find_all('a', {'class': 'aNxt'})
if len(result_next_page) != 0:
# 函数进行递归
get_page(result_next_page[0].attrs['href'])
else:
print('没有下一页了')
# 进行循环遍历其中的房源详细列表
for i in result_li:
# 由于BeautifulSoup传入的必须为字符串,所以进行转换
page_url = str(i)
soup = BeautifulSoup(page_url, 'html.parser')
# 由于通过class解析的为一个列表,所以只需要第一个参数
result_href = soup.find_all('a', {'class': 'houseListTitle'})[0]
# 先不做分析,等一会进行详细页面函数完成后进行调用
print(result_href.attrs['href'])
if __name__ == '__main__':
# url链接
url = 'https://zhengzhou.anjuke.com/sale/'
# 页面爬取函数调用
get_page(url)好了,那么咱们就开始详细页面的爬取了
哎,怎么动不动就要断电了,大学的坑啊,先把结果附上,闲了在补充,
import requests
from bs4 import BeautifulSoup
# 网页的请求头
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'
}
def get_page(url):
response = requests.get(url, headers=header)
# 通过BeautifulSoup进行解析出每个房源详细列表并进行打印
soup_idex = BeautifulSoup(response.text, 'html.parser')
result_li = soup_idex.find_all('li', {'class': 'list-item'})
# 进行循环遍历其中的房源详细列表
for i in result_li:
# 由于BeautifulSoup传入的必须为字符串,所以进行转换
page_url = str(i)
soup = BeautifulSoup(page_url, 'html.parser')
# 由于通过class解析的为一个列表,所以只需要第一个参数
result_href = soup.find_all('a', {'class': 'houseListTitle'})[0]
# 详细页面的函数调用
get_page_detail(result_href.attrs['href'])
# 进行下一页的爬取
result_next_page = soup_idex.find_all('a', {'class': 'aNxt'})
if len(result_next_page) != 0:
# 函数进行递归
get_page(result_next_page[0].attrs['href'])
else:
print('没有下一页了')
# 进行字符串中空格,换行,tab键的替换及删除字符串两边的空格删除
def my_strip(s):
return str(s).replace(" ", "").replace("\n", "").replace("\t", "").strip()
# 由于频繁进行BeautifulSoup的使用,封装一下,很鸡肋
def my_Beautifulsoup(response):
return BeautifulSoup(str(response), 'html.parser')
# 详细页面的爬取
def get_page_detail(url):
response = requests.get(url, headers=header)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# 标题什么的一大堆,哈哈
result_title = soup.find_all('h3', {'class': 'long-title'})[0]
result_price = soup.find_all('span', {'class': 'light info-tag'})[0]
result_house_1 = soup.find_all('p', {'class': 'first-col detail-col'})
result_house_2 = soup.find_all('p', {'class': 'second-col detail-col'})
result_house_3 = soup.find_all('p', {'class': 'third-col detail-col'})
soup_1 = my_Beautifulsoup(result_house_1)
soup_2 = my_Beautifulsoup(result_house_2)
soup_3 = my_Beautifulsoup(result_house_3)
result_house_tar_1 = soup_1.find_all('dd')
result_house_tar_2 = soup_2.find_all('dd')
result_house_tar_3 = soup_3.find_all('dd')
'''
文博公寓,省实验中学,首付只需70万,大三房,诚心卖,价可谈 270万
宇泰文博公寓 金水-花园路-文博东路4号 2010年 普通住宅
3室2厅2卫 140平方米 南北 中层(共32层)
精装修 19285元/m² 81.00万
'''
print(my_strip(result_title.text), my_strip(result_price.text))
print(my_strip(result_house_tar_1[0].text),
my_strip(my_Beautifulsoup(result_house_tar_1[1]).find_all('p')[0].text),
my_strip(result_house_tar_1[2].text), my_strip(result_house_tar_1[3].text))
print(my_strip(result_house_tar_2[0].text), my_strip(result_house_tar_2[1].text),
my_strip(result_house_tar_2[2].text), my_strip(result_house_tar_2[3].text))
print(my_strip(result_house_tar_3[0].text), my_strip(result_house_tar_3[1].text),
my_strip(result_house_tar_3[2].text))
if __name__ == '__main__':
# url链接
url = 'https://zhengzhou.anjuke.com/sale/'
# 页面爬取函数调用
get_page(url)由于自己边写博客,边写的代码,所以get_page函数中进行了一些改变,就是下一页的递归调用需要放在函数后面,以及进行封装了两个函数没有介绍,
而且数据存储到mysql也没有写,所以后期会继续跟进的,thank you!!!
相关推荐:
以上是python爬取安居客二手房网站数据方法分享的详细内容。更多信息请关注PHP中文网其他相关文章!

 Python vs. C:了解关键差异Apr 21, 2025 am 12:18 AM
Python vs. C:了解关键差异Apr 21, 2025 am 12:18 AMPython和C 各有优势,选择应基于项目需求。1)Python适合快速开发和数据处理,因其简洁语法和动态类型。2)C 适用于高性能和系统编程,因其静态类型和手动内存管理。
 Python vs.C:您的项目选择哪种语言?Apr 21, 2025 am 12:17 AM
Python vs.C:您的项目选择哪种语言?Apr 21, 2025 am 12:17 AM选择Python还是C 取决于项目需求:1)如果需要快速开发、数据处理和原型设计,选择Python;2)如果需要高性能、低延迟和接近硬件的控制,选择C 。
 达到python目标:每天2小时的力量Apr 20, 2025 am 12:21 AM
达到python目标:每天2小时的力量Apr 20, 2025 am 12:21 AM通过每天投入2小时的Python学习,可以有效提升编程技能。1.学习新知识:阅读文档或观看教程。2.实践:编写代码和完成练习。3.复习:巩固所学内容。4.项目实践:应用所学于实际项目中。这样的结构化学习计划能帮助你系统掌握Python并实现职业目标。
 最大化2小时:有效的Python学习策略Apr 20, 2025 am 12:20 AM
最大化2小时:有效的Python学习策略Apr 20, 2025 am 12:20 AM在两小时内高效学习Python的方法包括:1.回顾基础知识,确保熟悉Python的安装和基本语法;2.理解Python的核心概念,如变量、列表、函数等;3.通过使用示例掌握基本和高级用法;4.学习常见错误与调试技巧;5.应用性能优化与最佳实践,如使用列表推导式和遵循PEP8风格指南。
 在Python和C之间进行选择:适合您的语言Apr 20, 2025 am 12:20 AM
在Python和C之间进行选择:适合您的语言Apr 20, 2025 am 12:20 AMPython适合初学者和数据科学,C 适用于系统编程和游戏开发。1.Python简洁易用,适用于数据科学和Web开发。2.C 提供高性能和控制力,适用于游戏开发和系统编程。选择应基于项目需求和个人兴趣。
 Python与C:编程语言的比较分析Apr 20, 2025 am 12:14 AM
Python与C:编程语言的比较分析Apr 20, 2025 am 12:14 AMPython更适合数据科学和快速开发,C 更适合高性能和系统编程。1.Python语法简洁,易于学习,适用于数据处理和科学计算。2.C 语法复杂,但性能优越,常用于游戏开发和系统编程。
 每天2小时:Python学习的潜力Apr 20, 2025 am 12:14 AM
每天2小时:Python学习的潜力Apr 20, 2025 am 12:14 AM每天投入两小时学习Python是可行的。1.学习新知识:用一小时学习新概念,如列表和字典。2.实践和练习:用一小时进行编程练习,如编写小程序。通过合理规划和坚持不懈,你可以在短时间内掌握Python的核心概念。
 Python与C:学习曲线和易用性Apr 19, 2025 am 12:20 AM
Python与C:学习曲线和易用性Apr 19, 2025 am 12:20 AMPython更易学且易用,C 则更强大但复杂。1.Python语法简洁,适合初学者,动态类型和自动内存管理使其易用,但可能导致运行时错误。2.C 提供低级控制和高级特性,适合高性能应用,但学习门槛高,需手动管理内存和类型安全。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

MinGW - 适用于 Windows 的极简 GNU
这个项目正在迁移到osdn.net/projects/mingw的过程中,你可以继续在那里关注我们。MinGW:GNU编译器集合(GCC)的本地Windows移植版本,可自由分发的导入库和用于构建本地Windows应用程序的头文件;包括对MSVC运行时的扩展,以支持C99功能。MinGW的所有软件都可以在64位Windows平台上运行。

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

PhpStorm Mac 版本
最新(2018.2.1 )专业的PHP集成开发工具

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

