


毫无疑问,近些年机器学习和人工智能领域受到了越来越多的关注。随着大数据成为当下工业界最火爆的技术趋势,机器学习也借助大数据在预测和推荐方面取得了惊人的成绩。比较有名的机器学习案例包括Netflix根据用户历史浏览行为给用户推荐电影,亚马逊基于用户的历史购买行为来推荐图书。本文主要介绍了浅谈机器学习需要的了解的十大算法,具有一定借鉴价值,需要的朋友可以参考下。
那么,如果你想要学习机器学习的算法,该如何入门呢?就我而言,我的入门课程是在哥本哈根留学时选修的人工智能课程。老师是丹麦科技大学应用数学和计算机专业的全职教授,他的研究方向是逻辑学和人工智能,主要是用逻辑学的方法来建模。课程包括了理论/核心概念的探讨和动手实践两个部分。我们使用的教材是人工智能的经典书籍之一:PeterNorvig教授的《人工智能——一种现代方法》,课程涉及到了智能代理、基于搜索的求解、对抗搜索、概率论、多代理系统、社交化人工智能,以及人工智能的伦理和未来等话题。在课程的后期,我们三个人还组队做了编程项目,实现了基于搜索的简单算法来解决虚拟环境下的交通运输任务。
我从课程中学到了非常多的知识,并且打算在这个专题里继续深入学习。在过去几周内,我参与了旧金山地区的多场深度学习、神经网络和数据架构的演讲——还有一场众多知名教授云集的机器学习会议。最重要的是,我在六月初注册了Udacity的《机器学习导论》在线课程,并且在几天前学完了课程内容。在本文中,我想分享几个我从课程中学到的常用机器学习算法。
机器学习算法通常可以被分为三大类——监督式学习,非监督式学习和强化学习。监督式学习主要用于一部分数据集(训练数据)有某些可以获取的熟悉(标签),但剩余的样本缺失并且需要预测的场景。非监督式学习主要用于从未标注数据集中挖掘相互之间的隐含关系。强化学习介于两者之间——每一步预测或者行为都或多或少有一些反馈信息,但是却没有准确的标签或者错误提示。由于这是入门级的课程,并没有提及强化学习,但我希望监督式学习和非监督式学习的十个算法足够吊起你的胃口了。
监督式学习
1.决策树:
决策树是一种决策支持工具,它使用树状图或者树状模型来表示决策过程以及后续得到的结果,包括概率事件结果等。请观察下图来理解决策树的结构。
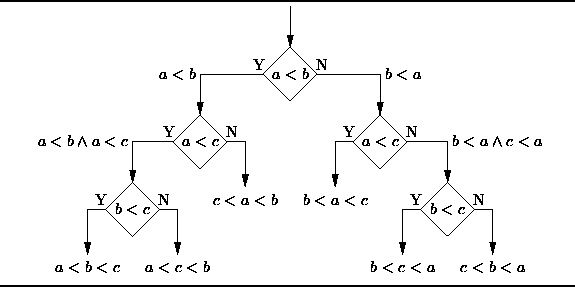
从商业决策的角度来看,决策树就是通过尽可能少的是非判断问题来预测决策正确的概率。这种方法可以帮你用一种结构性的、系统性的方法来得出合理的结论。
2.朴素贝叶斯分类器:
朴素贝叶斯分类器是一类基于贝叶斯理论的简单的概率分类器,它假设特征之前是相互独立的。下图所示的就是公式——P(A|B)表示后验概率,P(B|A)是似然值,P(A)是类别的先验概率,P(B)代表预测器的先验概率。

现实场景中的一些例子包括:
检测垃圾电子邮件
将新闻分为科技、政治、体育等类别
判断一段文字表达积极的情绪还是消极的情绪
用于人脸检测软件
3.最小平方回归:
如果你学过统计课程,也许听说过线性回归的概念。最小平方回归是求线性回归的一种方法。你可以把线性回归想成是用一条直线拟合若干个点。拟合的方法有许多种,“最小平方”的策略相当于你画一条直线,然后计算每个点到直线的垂直距离,最后把各个距离求和;最佳拟合的直线就是距离和最小的那一条。
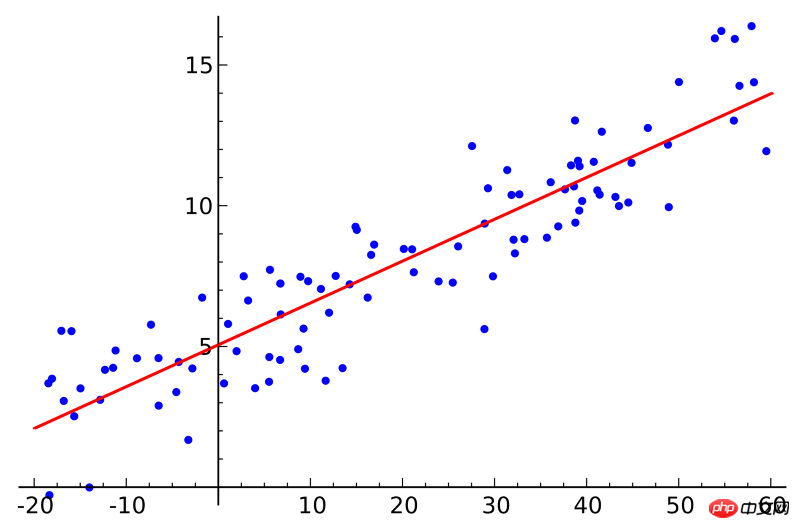
线性指的是用于拟合数据的模型,而最小平方指的是待优化的损失函数。
4.逻辑回归:
逻辑回归模型是一种强大的统计建模方式,它用一个或多个解释性变量对二值输出结果建模。它用逻辑斯蒂函数估计概率值,以此衡量分类依赖变量和一个或多个独立的变量之间的关系,这属于累积的逻辑斯蒂分布。

通常来说,逻辑回归模型在现实场景中的应用包括:
信用评分
预测商业活动的成功概率
预测某款产品的收益
预测某一天发生地震的概率
5.支持向量机:
支持向量机是一种二分类算法。在N维空间中给定两类点,支持向量机生成一个(N-1)维的超平面将这些点分为两类。举个例子,比如在纸上有两类线性可分的点。支持向量机会寻找一条直线将这两类点区分开来,并且与这些点的距离都尽可能远。
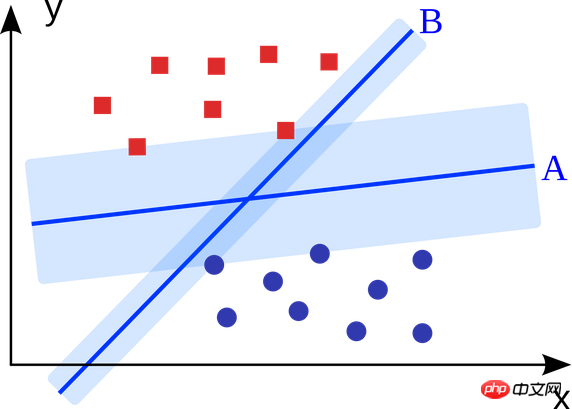
利用支持向量机(结合具体应用场景做了改进)解决的大规模问题包括展示广告、人体结合部位识别、基于图像的性别检查、大规模图像分类等……
6.集成方法:
集成方法是先构建一组分类器,然后用各个分类器带权重的投票来预测新数据的算法。最初的集成方法是贝叶斯平均,但最新的算法包括误差纠正输出编码和提升算法。

那么集成模型的原理是什么,以及它为什么比独立模型的效果好呢?
它们消除了偏置的影响:比如把民主党的问卷和共和党的问卷混合,从中得到的将是一个不伦不类的偏中立的信息。
它们能减小预测的方差:多个模型聚合后的预测结果比单一模型的预测结果更稳定。在金融界,这被称为是多样化——多个股票的混合产品波动总是远小于单个股票的波动。这也解释了为何增加训练数据,模型的效果会变得更好。
它们不容易产生过拟合:如果单个模型不会产生过拟合,那么将每个模型的预测结果简单地组合(取均值、加权平均、逻辑回归),没有理由产生过拟合。
非监督学习
7.聚类算法:
聚类算法的任务是将一群物体聚成多个组,分到同一个组(簇)的物体比其它组的物体更相似。
每种聚类算法都各不相同,这里列举了几种:
基于类心的聚类算法
基于连接的聚类算法
基于密度的聚类算法
概率型算法
降维算法
神经网络/深度学习
8.主成分分析:
主成分分析属于统计学的方法,过正交变换将一组可能存在相关性的变量转换为一组线性不相关的变量,转换后的这组变量叫主成分。

主成分分析的一些实际应用包括数据压缩,简化数据表示,数据可视化等。值得一提的是需要领域知识来判断是否适合使用主成分分析算法。如果数据的噪声太大(即各个成分的方差都很大),就不适合使用主成分分析算法。
9.奇异值分解:
奇异值分解是线性代数中一种重要的矩阵分解,是矩阵分析中正规矩阵酉对角化的推广。对于给定的m*n矩阵M,可以将其分解为M=UΣV,其中U和V是m×m阶酉矩阵,Σ是半正定m×n阶对角矩阵。

主成分分析其实就是一种简单的奇异值分解算法。在计算机视觉领域中,第一例人脸识别算法使用了主成分分析和奇异值分解将人脸表示为一组“特征脸(eigenfaces)”的线性组合,经过降维,然后利用简单的方法匹配候选人脸。尽管现代的方法更加精细,许多技术还是于此很相似。
10.独立成分分析:
独立成分分析是一种利用统计原理进行计算来揭示随机变量、测量值或者信号背后的隐藏因素的方法。独立成分分析算法给所观察到的多变量数据定义了一个生成模型,通常这些变量是大批量的样本。在该模型中,数据变量被假定为一些未知的潜变量的线性混合,而且混合系统也未知。潜变量被假定是非高斯和相互独立的,它们被称为所观察到的数据的独立分量。
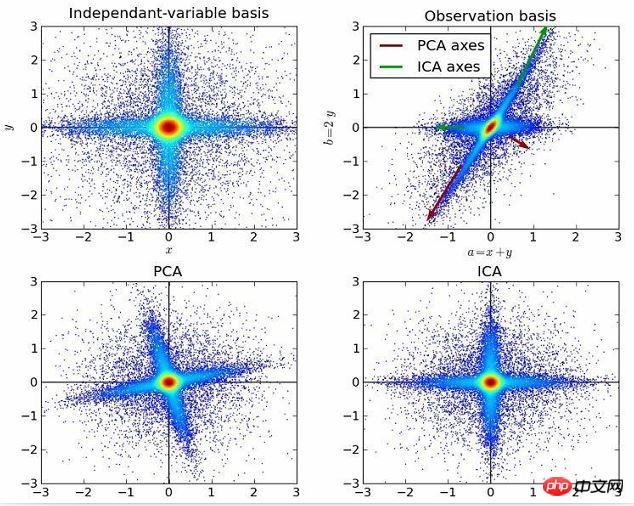
独立成分分析与主成分分析有关联,但它是一个更强大的技术。它能够在这些经典方法失效时仍旧找到数据源的潜在因素。它的应用包括数字图像、文档数据库、经济指标和心理测量。
现在,请运用你所理解的算法,去创造机器学习应用,改善全世界人们的生活质量吧。
相关推荐:

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

Atom编辑器mac版下载
最流行的的开源编辑器

Dreamweaver Mac版
视觉化网页开发工具

SublimeText3 Linux新版
SublimeText3 Linux最新版

