


下面小编就为大家带来一篇hadoop中实现java网络爬虫(示例讲解)。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧
这一篇网络爬虫的实现就要联系上大数据了。在前两篇java实现网络爬虫和heritrix实现网络爬虫的基础上,这一次是要完整的做一次数据的收集、数据上传、数据分析、数据结果读取、数据可视化。
需要用到
Cygwin:一个在windows平台上运行的类UNIX模拟环境,直接网上搜索下载,并且安装;
Hadoop:配置Hadoop环境,实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS,用来将收集的数据直接上传保存到HDFS,然后用MapReduce分析;
Eclipse:编写代码,需要导入hadoop的jar包,以可以创建MapReduce项目;
Jsoup:html的解析jar包,结合正则表达式能更好的解析网页源码;
----->
目录:
1、配置Cygwin
2、配置Hadoop黄静
3、Eclipse开发环境搭建
4、网络数据爬取(jsoup)
-------->
1、安装配置Cygwin
从官方网站下载Cygwin 安装文件,地址:https://cygwin.com/install.html
下载运行后进入安装界面。
安装时直接从网络镜像中下载扩展包,至少需要选择ssh和ssl支持包
安装后进入cygwin控制台界面,
运行ssh-host-config命令,安装SSH
输入:no,yes,ntsec,no,no
注意:win7下需要改为yes,yes,ntsec,no,yes,输入密码并确认这个步骤
完成后会在windows操作系统中配置好一个Cygwin sshd服务,启动该服务即可。

然后要配置ssh免密码登陆
重新运行cygwin。
执行ssh localhost,会要求使用密码进行登陆。
使用ssh-keygen命令来生成一个ssh密钥,一直回车结束即可。
生成后进入.ssh目录,使用命令:cp id_rsa.pub authorized_keys 命令来配置密钥。
之后使用exit退出即可。
重新进入系统后,通过ssh localhost就可以直接进入系统,不需要再输入密码了。
2、配置Hadoop环境
修改hadoop-env.sh文件,加入JDK安装目录的JAVA_HOME位置设置。
# The java implementation to use. Required. export JAVA_HOME=/cygdrive/c/Java/jdk1.7.0_67
如图注意:Program Files缩写为PROGRA~1

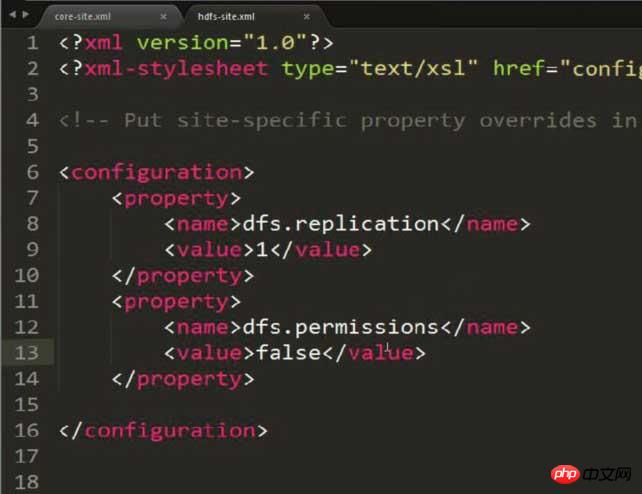
修改hdfs-site.xml,设置存放副本为1(因为配置的是伪分布式方式)
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
注意:此图片多加了一个property,内容就是解决可能出现的权限问题!!!
HDFS:Hadoop 分布式文件系统
可以在HDFS中通过命令动态对文件或文件夹进行CRUD
注意有可能出现权限的问题,需要通过在hdfs-site.xml中配置以下内容来避免:
<property> <name>dfs.permissions</name> <value>false</value> </property>
修改mapred-site.xml,设置JobTracker运行的服务器与端口号(由于当前就是运行在本机上,直接写localhost 即可,端口可以绑定任意空闲端口)
<configuration> <property> <name>mapred.job.tracker</name> <value>localhost:9001</value> </property> </configuration>
配置core-site.xml,配置HDFS文件系统所对应的服务器与端口号(同样就在当前主机)
<configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration>
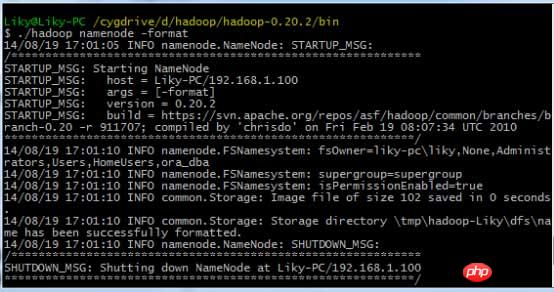
配置好以上内容后,在Cygwin中进入hadoop目录

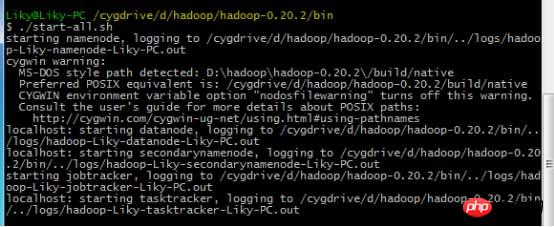
在bin目录下,对HDFS文件系统进行格式化(第一次使用前必须格式化),然后输入启动命令:
3、Eclipse开发环境搭建
这个在我写的博客 大数据【二】HDFS部署及文件读写(包含eclipse hadoop配置)中给出大致配置方法。不过此时需要完善一下。
将hadoop中的hadoop-eclipse-plugin.jar支持包拷贝到eclipse的plugin目录下,为eclipse添加Hadoop支持。
启动Eclipse后,切换到MapReduce界面。
在windows工具选项选择showviews的others里面查找map/reduce locations。
在Map/Reduce Locations窗口中建立一个Hadoop Location,以便与Hadoop进行关联。

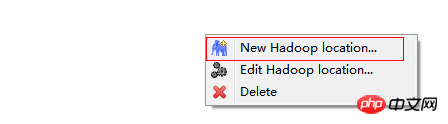
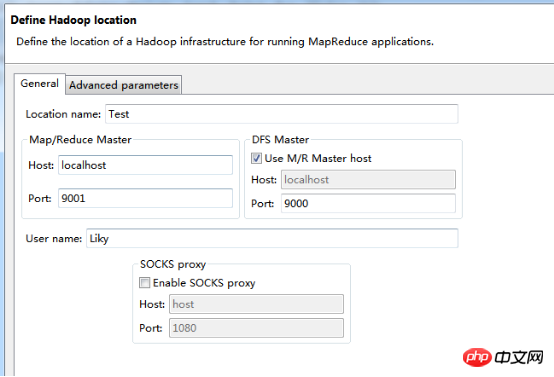
注意:此处的两个端口应为你配置hadoop的时候设置的端口!!!
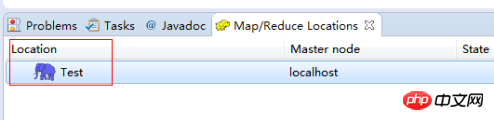
完成后会建立好一个Hadoop Location
在左侧的DFS Location中,还可以看到HDFS中的各个目录
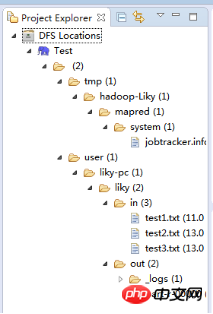
并且你可以在其目录下自由创建文件夹来存取数据。
下面你就可以创建mapreduce项目了,方法同正常创建一样。
4、网络数据爬取
现在我们通过编写一段程序,来将爬取的新闻内容的有效信息保存到HDFS中。
此时就有了两种网络爬虫的方法:
其一就是利用heritrix工具获取的数据;
其一就是java代码结合jsoup编写的网络爬虫。
方法一的信息保存到HDFS:
直接读取生成的本地文件,用jsoup解析html,此时需要将jsoup的jar包导入到项目中。
package org.liky.sina.save;
//这里用到了JSoup开发包,该包可以很简单的提取到HTML中的有效信息
import java.io.File;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class SinaNewsData {
private static Configuration conf = new Configuration();
private static FileSystem fs;
private static Path path;
private static int count = 0;
public static void main(String[] args) {
parseAllFile(new File(
"E:/heritrix-1.12.1/jobs/sina_news_job_02-20170814013255352/mirror/"));
}
public static void parseAllFile(File file) {
// 判断类型
if (file.isDirectory()) {
// 文件夹
File[] allFile = file.listFiles();
if (allFile != null) {
for (File f : allFile) {
parseAllFile(f);
}
}
} else {
// 文件
if (file.getName().endsWith(".html")
|| file.getName().endsWith(".shtml")) {
parseContent(file.getAbsolutePath());
}
}
}
public static void parseContent(String filePath) {
try {
//用jsoup的方法读取文件路径
Document doc = Jsoup.parse(new File(filePath), "utf-8");
//读取标题
String title = doc.title();
Elements descElem = doc.getElementsByAttributeValue("name",
"description");
Element descE = descElem.first();
// 读取内容
String content = descE.attr("content");
if (title != null && content != null) {
//通过Path来保存数据到HDFS中
path = new Path("hdfs://localhost:9000/input/"
+ System.currentTimeMillis() + ".txt");
fs = path.getFileSystem(conf);
// 建立输出流对象
FSDataOutputStream os = fs.create(path);
// 使用os完成输出
os.writeChars(title + "\r\n" + content);
os.close();
count++;
System.out.println("已经完成" + count + " 个!");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}以上是Java网络爬虫在hadoop中的实现方法介绍的详细内容。更多信息请关注PHP中文网其他相关文章!

 Java仍然是基于新功能的好语言吗?May 12, 2025 am 12:12 AM
Java仍然是基于新功能的好语言吗?May 12, 2025 am 12:12 AMJavaremainsagoodlanguageduetoitscontinuousevolutionandrobustecosystem.1)Lambdaexpressionsenhancecodereadabilityandenablefunctionalprogramming.2)Streamsallowforefficientdataprocessing,particularlywithlargedatasets.3)ThemodularsystemintroducedinJava9im
 是什么使Java很棒?关键特征和好处May 12, 2025 am 12:11 AM
是什么使Java很棒?关键特征和好处May 12, 2025 am 12:11 AMJavaisgreatduetoitsplatformindependence,robustOOPsupport,extensivelibraries,andstrongcommunity.1)PlatformindependenceviaJVMallowscodetorunonvariousplatforms.2)OOPfeatureslikeencapsulation,inheritance,andpolymorphismenablemodularandscalablecode.3)Rich
 前5个Java功能:示例和解释May 12, 2025 am 12:09 AM
前5个Java功能:示例和解释May 12, 2025 am 12:09 AMJava的五大特色是多态性、Lambda表达式、StreamsAPI、泛型和异常处理。1.多态性让不同类的对象可以作为共同基类的对象使用。2.Lambda表达式使代码更简洁,特别适合处理集合和流。3.StreamsAPI高效处理大数据集,支持声明式操作。4.泛型提供类型安全和重用性,编译时捕获类型错误。5.异常处理帮助优雅处理错误,编写可靠软件。
 Java的最高功能如何影响性能和可伸缩性?May 12, 2025 am 12:08 AM
Java的最高功能如何影响性能和可伸缩性?May 12, 2025 am 12:08 AMjava'stopfeatureSnificallyEnhanceItsperFormanCeanDscalability.1)对象 - 方向 - incipleslike-polymormormormormormormormormormormormormorableablefleandibleandscalablecode.2)garbageCollectionAutoctionAutoctionAutoctionAutoctionAutoctionautomorymanatesmemorymanateMmanateMmanateMmanagementButCancausElatenceiss.3)
 JVM内部:深入Java虚拟机May 12, 2025 am 12:07 AM
JVM内部:深入Java虚拟机May 12, 2025 am 12:07 AMJVM的核心组件包括ClassLoader、RuntimeDataArea和ExecutionEngine。1)ClassLoader负责加载、链接和初始化类和接口。2)RuntimeDataArea包含MethodArea、Heap、Stack、PCRegister和NativeMethodStacks。3)ExecutionEngine由Interpreter、JITCompiler和GarbageCollector组成,负责bytecode的执行和优化。
 什么是使Java安全安全的功能?May 11, 2025 am 12:07 AM
什么是使Java安全安全的功能?May 11, 2025 am 12:07 AMJava'ssafetyandsecurityarebolsteredby:1)strongtyping,whichpreventstype-relatederrors;2)automaticmemorymanagementviagarbagecollection,reducingmemory-relatedvulnerabilities;3)sandboxing,isolatingcodefromthesystem;and4)robustexceptionhandling,ensuringgr
 必不可少的Java功能:增强您的编码技巧May 11, 2025 am 12:07 AM
必不可少的Java功能:增强您的编码技巧May 11, 2025 am 12:07 AMjavaoffersseveralkeyfeaturesthatenhancecodingskills:1)对象 - 方向 - 方向上的贝利奥洛夫夫人 - 启动worldentities
 JVM最完整的指南May 11, 2025 am 12:06 AM
JVM最完整的指南May 11, 2025 am 12:06 AMthejvmisacrucialcomponentthatrunsjavacodebytranslatingitolachine特定建筑,影响性能,安全性和便携性。1)theclassloaderloader,links andinitializesClasses.2)executionEccutionEngineExecutionEngineExecutionEngineExecuteByteCuteByteCuteByteCuteBytecuteBytecuteByteCuteByteCuteByteCuteBytecuteByteCodeNinstRonctientions.3)Memo.3)Memo


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

Atom编辑器mac版下载
最流行的的开源编辑器

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

Dreamweaver CS6
视觉化网页开发工具

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

