



张炎泼先生于2016年加入白山云科技,主要负责对象存储研发、数据跨机房分布和修复问题解决等工作。以实现100PB级数据存储为目标,其带领团队完成全网分布存储系统的设计、实现与部署工作,将数据“冷”“热”分离,使冷数据成本压缩至1.2倍冗余度。
张炎泼先生2006年至2015年,曾就职于新浪,负责Cross-IDC PB级云存储服务的架构设计、协作流程制定、代码规范和实施标准制定及大部分功能实现等工作,支持新浪微博、微盘、视频、SAE、音乐、软件下载等新浪内部存储等业务;2015年至2016年,于美团担任高级技术专家,设计了跨机房的百PB对象存储解决方案:设计和实现高并发和高可靠的多副本复制策略,优化Erasure Code降低90%IO开销。
软件开发中,一个hash表相当于把n个key随机放入到b个bucket中,以实现n个数据在b个单位空间的存储。
我们发现hash表中存在一些有趣现象:
hash表中key的分布规律
当hash表中key和bucket数量一样时(n/b=1):
37% 的bucket是空的
37% 的bucket里只有1个key
26% 的bucket里有1个以上的key(hash冲突)
下图直观的展示了当n=b=20时,hash表里每个bucket中key的数量(按照key的数量对bucket做排序):
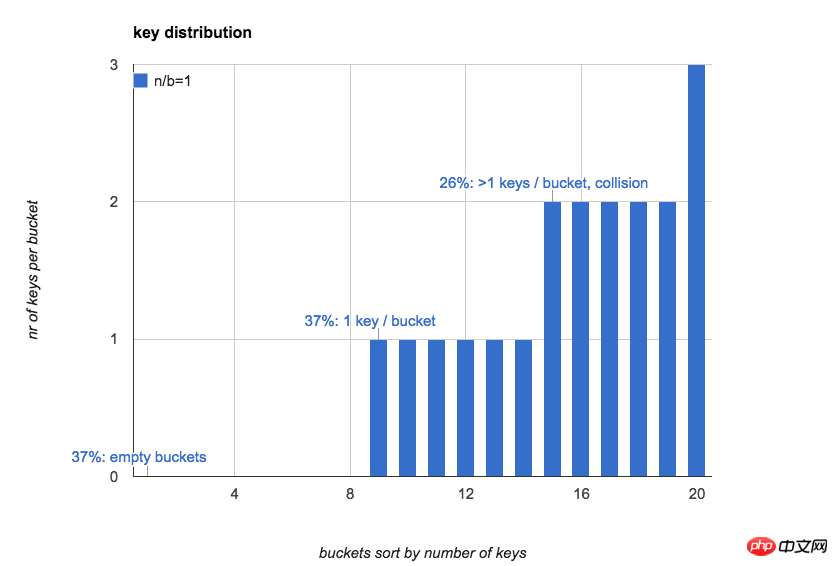
往往我们对hash表的第一感觉是:如果将key随机放入所有的bucket,bucket中key的数量较为均匀,每个bucket里key数量的期望是1。
而实际上,bucket里key的分布在n较小时非常不均匀;当n增大时,才会逐渐趋于平均。
key的数量对3类bucket数量的影响
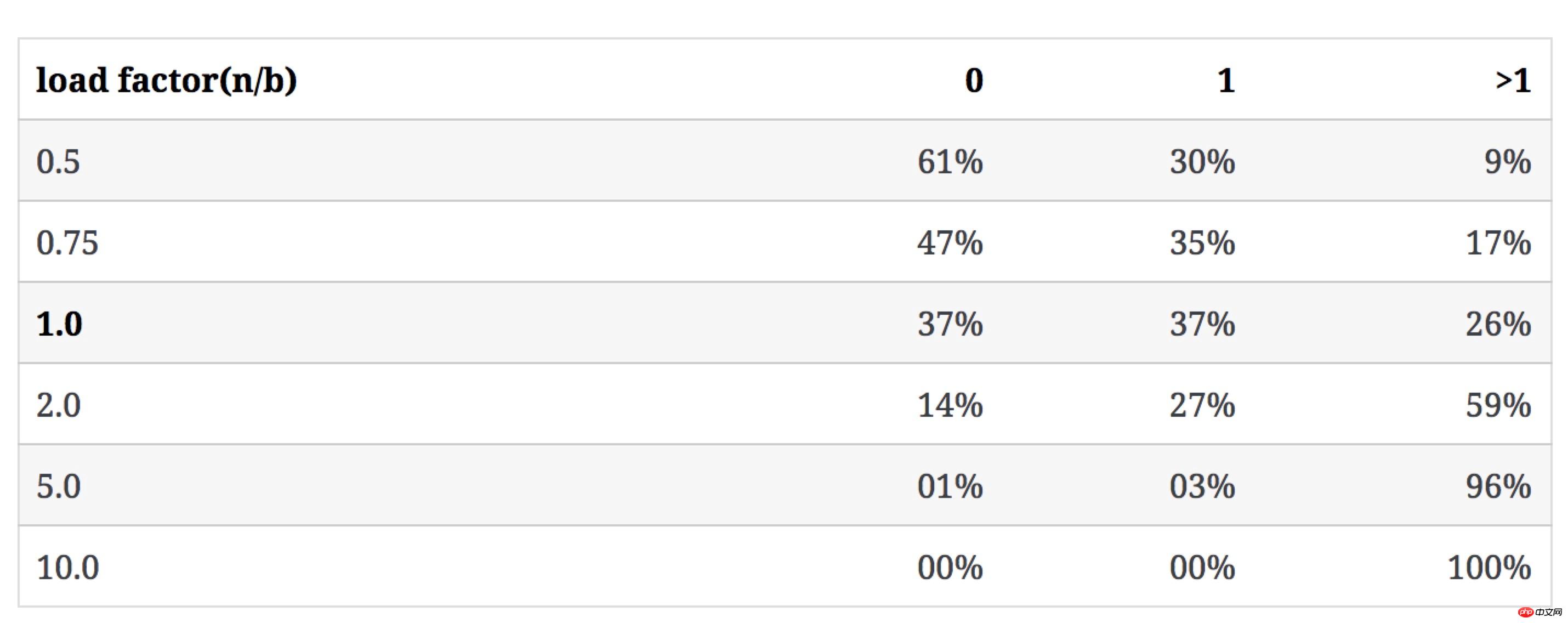
下表表示当b不变,n增大时,n/b的值如何影响3类bucket的数量占比(冲突率即含有多于1个key的bucket占比):
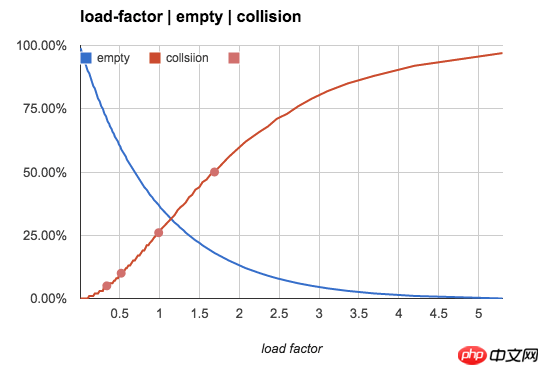
更直观一点,我们用下图来展示空bucket率和冲突率随n/b值的变化趋势:
key数量对bucket均匀程度的影响
上面几组数字是当n/b较小时有意义的参考值,但随n/b逐渐增大,空bucket与1个key的bucket数量几乎为0,绝大多数bucket含有多个key。
当n/b超过1(1个bucket允许存储多个key), 我们主要观察的对象就转变成bucket里key数量的分布规律。
下表表示当n/b较大,每个bucket里key的数量趋于均匀时,不均匀的程度是多少。
为了描述这种不均匀的程度,我们使用bucket中key数量的最大值和最小值之间的比例((most-fewest)/most)来表示。
下表列出了b=100时,随n增大,key的分布情况。
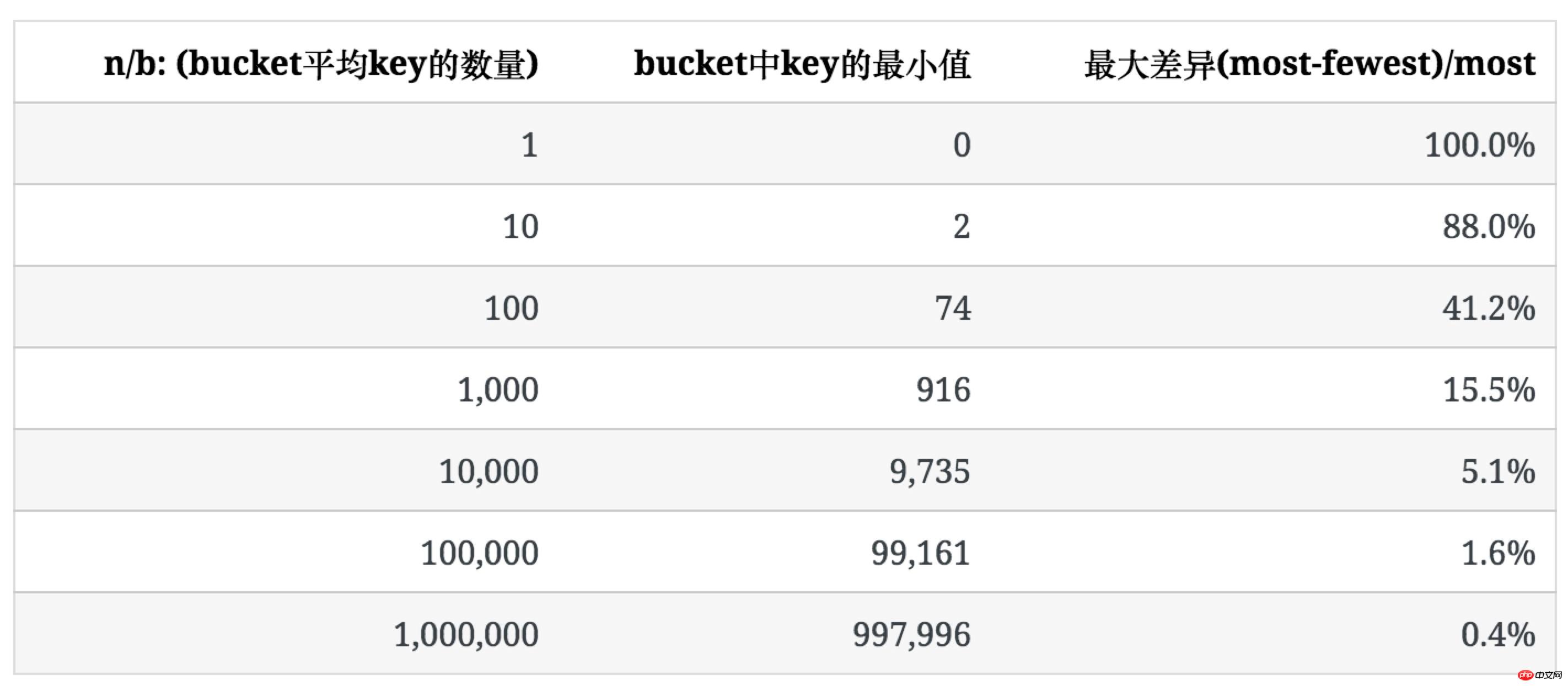
可以看出,随着bucket里key平均数量的增加,其分布的不均匀程度也逐渐降低。
和空bucket或1个key的bucket的占比不同n/b,均匀程度不仅取决于n/b的值,也受b值的影响,后面会提到。 未使用统计中常用的均方差法去描述key分布的不均匀程度,是因为软件开发过程中,更多时候要考虑最坏情况下所需准备的内存等资源。
Load Factor:n/b274ea5e19b4ff76c85d67b8feccb62871
另外一种hash表的实现,专门用来存储比较多的key,当 n/b>1n/b1.0时,线性探测失效(没有足够的bucket存储每个key)。这时1个bucket里不仅存储1个key,一般在一个bucket内用chaining,将所有落在这个bucket的key用链表连接起来,来解决冲突时多个key的存储。
链表只在n/b不是很大时适用。因为链表的查找需要O(n)的时间开销,对于非常大的n/b,有时会用tree替代链表来管理bucket内的key。
n/b值较大的使用场景之一是:将一个网站的用户随机分配到多个不同的web-server上,这时每个web-server可以服务多个用户。多数情况下,我们都希望这种分配能尽可能均匀,从而有效利用每个web-server资源。
这就要求我们关注hash的均匀程度。因此,接下来要讨论的是,假定hash函数完全随机的,均匀程度根据n和b如何变化。
n/b 越大,key的分布越均匀
当 n/b 足够大时,空bucket率趋近于0,且每个bucket中key的数量趋于平均。每个bucket中key数量的期望是:
avg=n/b
定义一个bucket平均key的数量是100%:bucket中key的数量刚好是n/b,下图分别模拟了 b=20,n/b分别为 10、100、1000时,bucket中key的数量分布。
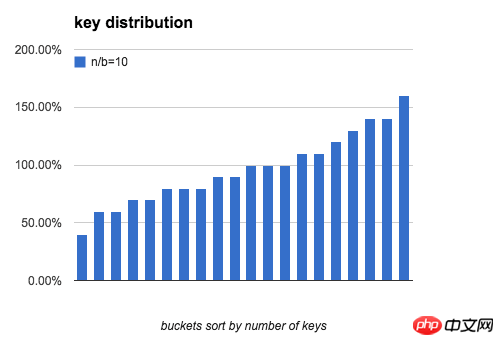
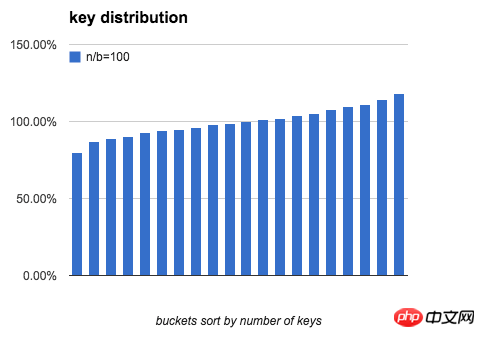
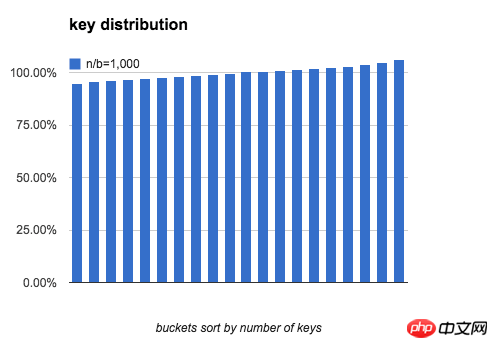
可以看出,当 n/b 增大时,bucket中key数量的最大值与最小值差距在逐渐缩小。下表列出了随b和n/b增大,key分布的均匀程度的变化:
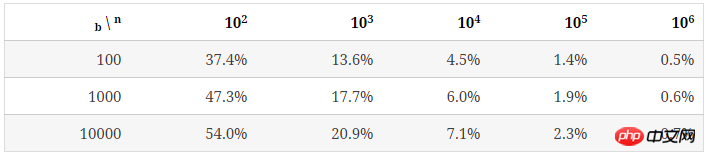
结论:
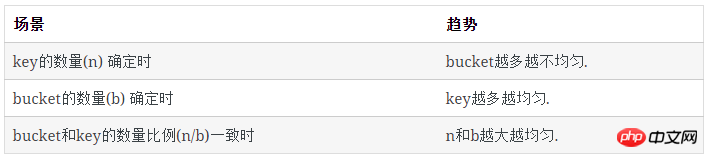
计算
上述大部分结果来自于程序模拟,现在我们来解决从数学上如何计算这些数值。
每类bucket的数量
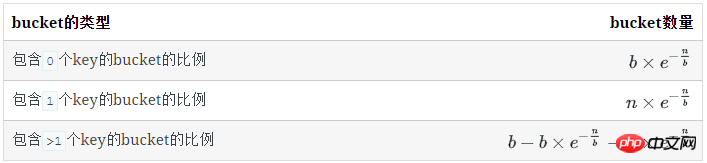
空bucket数量
对于1个key, 它不在某个特定的bucket的概率是 (b−1)/b
所有key都不在某个特定的bucket的概率是( (b−1)/b)n
已知:
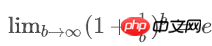
空bucket率是:
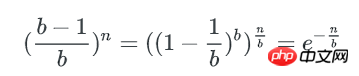
空bucket数量为:

有1个key的bucket数量
n个key中,每个key有1/b的概率落到某个特定的bucket里,其他key以1-(1/b)的概率不落在这个bucket里,因此,对某个特定的bucket,刚好有1个key的概率是:
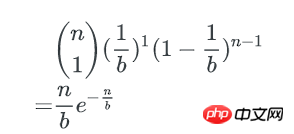
刚好有1个key的bucket数量为:
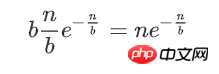
多个key的bucket
剩下即为含多个key的bucket数量:
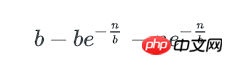
key在bucket中分布的均匀程度
类似的,1个bucket中刚好有i个key的概率是:n个key中任选i个,并都以1/b的概率落在这个bucket里,其他n-i个key都以1-1/b的概率不落在这个bucket里,即:
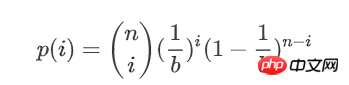
这就是著名的二项式分布。
我们可通过二项式分布估计bucket中key数量的最大值与最小值。
通过正态分布来近似
当 n, b 都很大时,二项式分布可以用正态分布来近似估计key分布的均匀性:
p=1/b,1个bucket中刚好有i个key的概率为:
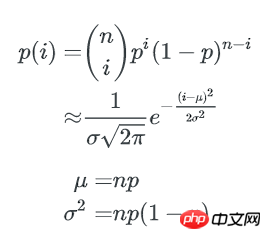
1个bucket中key数量不多于x的概率是:
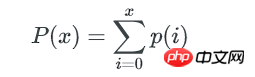
所以,所有不多于x个key的bucket数量是:
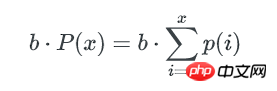
bucket中key数量的最小值,可以这样估算: 如果不多于x个key的bucket数量是1,那么这唯一1个bucket就是最少key的bucket。我们只要找到1个最小的x,让包含不多于x个key的bucket总数为1, 这个x就是bucket中key数量的最小值。
计算key数量的最小值x
一个bucket里包含不多于x个key的概率是:
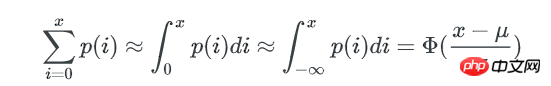
Φ(x) 是正态分布的累计分布函数,当x-μ趋近于0时,可以使用以下方式来近似:
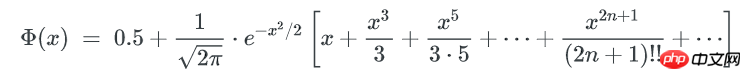
这个函数的计算较难,但只是要找到x,我们可以在[0~μ]的范围内逆向遍历x,以找到一个x 使得包含不多于x个key的bucket期望数量是1。
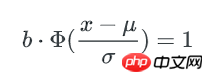
x可以认为这个x就是bucket里key数量的最小值,而这个hash表中,不均匀的程度可以用key数量最大值与最小值的差异来描述: 因为正态分布是对称的,所以key数量的最大值可以用 μ + (μ-x) 来表示。最终,bucket中key数量最大值与最小值的比例就是:
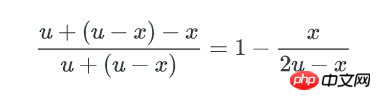
(μ是均值n/b)
程序模拟
以下python脚本模拟了key在bucket中分布的情况,同时可以作为对比,验证上述计算结果。
import sysimport mathimport timeimport hashlibdef normal_pdf(x, mu, sigma):
x = float(x)
mu = float(mu)
m = 1.0 / math.sqrt( 2 * math.pi ) / sigma
n = math.exp(-(x-mu)**2 / (2*sigma*sigma))return m * ndef normal_cdf(x, mu, sigma):
# integral(-oo,x)
x = float(x)
mu = float(mu)
sigma = float(sigma) # to standard form
x = (x - mu) / sigma
s = x
v = x for i in range(1, 100):
v = v * x * x / (2*i+1)
s += v return 0.5 + s/(2*math.pi)**0.5 * math.e ** (-x*x/2)def difference(nbucket, nkey):
nbucket, nkey= int(nbucket), int(nkey) # binomial distribution approximation by normal distribution
# find the bucket with minimal keys.
#
# the probability that a bucket has exactly i keys is:
# # probability density function
# normal_pdf(i, mu, sigma)
#
# the probability that a bucket has 0 ~ i keys is:
# # cumulative distribution function
# normal_cdf(i, mu, sigma)
#
# if the probability that a bucket has 0 ~ i keys is greater than 1/nbucket, we
# say there will be a bucket in hash table has:
# (i_0*p_0 + i_1*p_1 + ...)/(p_0 + p_1 + ..) keys.
p = 1.0 / nbucket
mu = nkey * p
sigma = math.sqrt(nkey * p * (1-p))
target = 1.0 / nbucket
minimal = mu while True:
xx = normal_cdf(minimal, mu, sigma) if abs(xx-target) < target/10: break
minimal -= 1
return minimal, (mu-minimal) * 2 / (mu + (mu - minimal))def difference_simulation(nbucket, nkey):
t = str(time.time())
nbucket, nkey= int(nbucket), int(nkey)
buckets = [0] * nbucket for i in range(nkey):
hsh = hashlib.sha1(t + str(i)).digest()
buckets[hash(hsh) % nbucket] += 1
buckets.sort()
nmin, mmax = buckets[0], buckets[-1] return nmin, float(mmax - nmin) / mmaxif __name__ == "__main__":
nbucket, nkey= sys.argv[1:]
minimal, rate = difference(nbucket, nkey) print 'by normal distribution:'
print ' min_bucket:', minimal print ' difference:', rate
minimal, rate = difference_simulation(nbucket, nkey) print 'by simulation:'
print ' min_bucket:', minimal print ' difference:', rate以上是程序员进阶篇之hash表的脾性的详细内容。更多信息请关注PHP中文网其他相关文章!

 PHP和Python:解释了不同的范例Apr 18, 2025 am 12:26 AM
PHP和Python:解释了不同的范例Apr 18, 2025 am 12:26 AMPHP主要是过程式编程,但也支持面向对象编程(OOP);Python支持多种范式,包括OOP、函数式和过程式编程。PHP适合web开发,Python适用于多种应用,如数据分析和机器学习。
 PHP和Python:深入了解他们的历史Apr 18, 2025 am 12:25 AM
PHP和Python:深入了解他们的历史Apr 18, 2025 am 12:25 AMPHP起源于1994年,由RasmusLerdorf开发,最初用于跟踪网站访问者,逐渐演变为服务器端脚本语言,广泛应用于网页开发。Python由GuidovanRossum于1980年代末开发,1991年首次发布,强调代码可读性和简洁性,适用于科学计算、数据分析等领域。
 在PHP和Python之间进行选择:指南Apr 18, 2025 am 12:24 AM
在PHP和Python之间进行选择:指南Apr 18, 2025 am 12:24 AMPHP适合网页开发和快速原型开发,Python适用于数据科学和机器学习。1.PHP用于动态网页开发,语法简单,适合快速开发。2.Python语法简洁,适用于多领域,库生态系统强大。
 PHP和框架:现代化语言Apr 18, 2025 am 12:14 AM
PHP和框架:现代化语言Apr 18, 2025 am 12:14 AMPHP在现代化进程中仍然重要,因为它支持大量网站和应用,并通过框架适应开发需求。1.PHP7提升了性能并引入了新功能。2.现代框架如Laravel、Symfony和CodeIgniter简化开发,提高代码质量。3.性能优化和最佳实践进一步提升应用效率。
 PHP的影响:网络开发及以后Apr 18, 2025 am 12:10 AM
PHP的影响:网络开发及以后Apr 18, 2025 am 12:10 AMPHPhassignificantlyimpactedwebdevelopmentandextendsbeyondit.1)ItpowersmajorplatformslikeWordPressandexcelsindatabaseinteractions.2)PHP'sadaptabilityallowsittoscaleforlargeapplicationsusingframeworkslikeLaravel.3)Beyondweb,PHPisusedincommand-linescrip
 PHP类型提示如何起作用,包括标量类型,返回类型,联合类型和无效类型?Apr 17, 2025 am 12:25 AM
PHP类型提示如何起作用,包括标量类型,返回类型,联合类型和无效类型?Apr 17, 2025 am 12:25 AMPHP类型提示提升代码质量和可读性。1)标量类型提示:自PHP7.0起,允许在函数参数中指定基本数据类型,如int、float等。2)返回类型提示:确保函数返回值类型的一致性。3)联合类型提示:自PHP8.0起,允许在函数参数或返回值中指定多个类型。4)可空类型提示:允许包含null值,处理可能返回空值的函数。
 PHP如何处理对象克隆(克隆关键字)和__clone魔法方法?Apr 17, 2025 am 12:24 AM
PHP如何处理对象克隆(克隆关键字)和__clone魔法方法?Apr 17, 2025 am 12:24 AMPHP中使用clone关键字创建对象副本,并通过\_\_clone魔法方法定制克隆行为。1.使用clone关键字进行浅拷贝,克隆对象的属性但不克隆对象属性内的对象。2.通过\_\_clone方法可以深拷贝嵌套对象,避免浅拷贝问题。3.注意避免克隆中的循环引用和性能问题,优化克隆操作以提高效率。
 PHP与Python:用例和应用程序Apr 17, 2025 am 12:23 AM
PHP与Python:用例和应用程序Apr 17, 2025 am 12:23 AMPHP适用于Web开发和内容管理系统,Python适合数据科学、机器学习和自动化脚本。1.PHP在构建快速、可扩展的网站和应用程序方面表现出色,常用于WordPress等CMS。2.Python在数据科学和机器学习领域表现卓越,拥有丰富的库如NumPy和TensorFlow。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Atom编辑器mac版下载
最流行的的开源编辑器

MinGW - 适用于 Windows 的极简 GNU
这个项目正在迁移到osdn.net/projects/mingw的过程中,你可以继续在那里关注我们。MinGW:GNU编译器集合(GCC)的本地Windows移植版本,可自由分发的导入库和用于构建本地Windows应用程序的头文件;包括对MSVC运行时的扩展,以支持C99功能。MinGW的所有软件都可以在64位Windows平台上运行。

