

这篇文章主要为大家详细介绍了python实现八大排序算法的第二篇,具有一定的参考价值,感兴趣的小伙伴们可以参考一下
本文接上一篇博客python实现的八大排序算法part1,将继续使用python实现八大排序算法中的剩余四个:快速排序、堆排序、归并排序、基数排序
5、快速排序
快速排序是通常被认为在同数量级(O(nlog2n))的排序方法中平均性能最好的。
算法思想:
已知一组无序数据a[1]、a[2]、……a[n],需将其按升序排列。首先任取数据a[x]作为基准。比较a[x]与其它数据并排序,使a[x]排在数据的第k位,并且使a[1]~a[k-1]中的每一个数据1926709adc12805ce1b57d7d8d4e5282a[x],然后采用分治的策略分别对a[1]~a[k-1]和a[k+1]~a[n]两组数据进行快速排序。
优点:极快,数据移动少;
缺点:不稳定。
python代码实现:
def quick_sort(list):
little = []
pivotList = []
large = []
# 递归出口
if len(list) <= 1:
return list
else:
# 将第一个值做为基准
pivot = list[0]
for i in list:
# 将比基准小的值放到less数列
if i < pivot:
little.append(i)
# 将比基准大的值放到more数列
elif i > pivot:
large.append(i)
# 将和基准相同的值保存在基准数列
else:
pivotList.append(i)
# 对less数列和more数列继续进行快速排序
little = quick_sort(little)
large = quick_sort(large)
return little + pivotList + large下面这段代码出自《Python cookbook 第二版的三行实现python快速排序。
#!/usr/bin/env python
#coding:utf-8
'''
file:python-8sort.py
date:9/1/17 9:03 AM
author:lockey
email:lockey@123.com
desc:python实现八大排序算法
'''
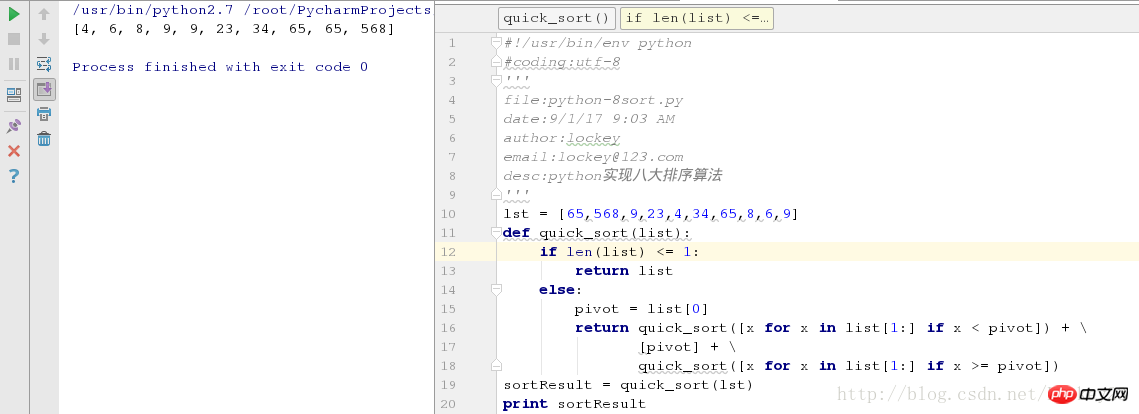
lst = [65,568,9,23,4,34,65,8,6,9]
def quick_sort(list):
if len(list) <= 1:
return list
else:
pivot = list[0]
return quick_sort([x for x in list[1:] if x < pivot]) + \
[pivot] + \
quick_sort([x for x in list[1:] if x >= pivot])运行测试结果截图:
好吧,还有更精简的语法糖,一行完事:
quick_sort = lambda xs : ( (len(xs) 103f214b10b427af5a045934eb5668cd= xs[0]] ) ] )[0]
若初始序列按关键码有序或基本有序时,快排序反而蜕化为冒泡排序。为改进之,通常以“三者取中法”来选取基准记录,即将排序区间的两个端点与中点三个记录关键码居中的调整为支点记录。快速排序是一个不稳定的排序方法。
在改进算法中,我们将只对长度大于k的子序列递归调用快速排序,让原序列基本有序,然后再对整个基本有序序列用插入排序算法排序。实践证明,改进后的算法时间复杂度有所降低,且当k取值为 8 左右时,改进算法的性能最佳。
6、堆排序(Heap Sort)
堆排序是一种树形选择排序,是对直接选择排序的有效改进。
优点 : 效率高
缺点:不稳定
堆的定义下:具有n个元素的序列 (h1,h2,...,hn),当且仅当满足(hi>=h2i,hi>=2i+1)或(hi<=h2i,hi<=2i+1) (i=1,2,...,n/2)时称之为堆。在这里只讨论满足前者条件的堆。由堆的定义可以看出,堆顶元素(即第一个元素)必为最大项(大顶堆)。完全二 叉树可以很直观地表示堆的结构。堆顶为根,其它为左子树、右子树。
算法思想:
初始时把要排序的数的序列看作是一棵顺序存储的二叉树,调整它们的存储序,使之成为一个 堆,这时堆的根节点的数最大。然后将根节点与堆的最后一个节点交换。然后对前面(n-1)个数重新调整使之成为堆。依此类推,直到只有两个节点的堆,并对 它们作交换,最后得到有n个节点的有序序列。从算法描述来看,堆排序需要两个过程,一是建立堆,二是堆顶与堆的最后一个元素交换位置。所以堆排序有两个函数组成。一是建堆的渗透函数,二是反复调用渗透函数实现排序的函数。
python代码实现:
# -*- coding: UTF-8 -*-
'''
Created on 2017年9月2日
Running environment:win7.x86_64 eclipse python3
@author: Lockey
'''
lst = [65,568,9,23,4,34,65,8,6,9]
def adjust_heap(lists, i, size):# 调整堆
lchild = 2 * i + 1;rchild = 2 * i + 2
max = i
if i < size / 2:
if lchild < size and lists[lchild] > lists[max]:
max = lchild
if rchild < size and lists[rchild] > lists[max]:
max = rchild
if max != i:
lists[max], lists[i] = lists[i], lists[max]
adjust_heap(lists, max, size)
def build_heap(lists, size):# 创建堆
halfsize = int(size/2)
for i in range(0, halfsize)[::-1]:
adjust_heap(lists, i, size)
def heap_sort(lists):# 堆排序
size = len(lists)
build_heap(lists, size)
for i in range(0, size)[::-1]:
lists[0], lists[i] = lists[i], lists[0]
adjust_heap(lists, 0, i)
print(lists)结果示例:

7、归并排序
算法思想:
归并(Merge)排序是建立在归并操作上的一种有效的排序算法,该算法是采用分治法的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
归并过程为:比较a[i]和a[j]的大小,若a[i]≤a[j],则将第一个有序表中的元素a[i]复制到r[k]中,并令i和k分别加上1;否则将第二个有序表中的元素a[j]复制到r[k]中,并令j和k分别加上1,如此循环下去,直到其中一个有序表取完,然后再将另一个有序表中剩余的元素复制到r中从下标k到下标t的单元。归并排序的算法我们通常用递归实现,先把待排序区间[s,t]以中点二分,接着把左边子区间排序,再把右边子区间排序,最后把左区间和右区间用一次归并操作合并成有序的区间[s,t]。
# -*- coding: UTF-8 -*-
'''
Created on 2017年9月2日
Running environment:win7.x86_64 eclipse python3
@author: Lockey
'''
lst = [65,568,9,23,4,34,65,8,6,9]
def merge(left, right):
i, j = 0, 0
result = []
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result += left[i:]
result += right[j:]
print(result)
return result
def merge_sort(lists):# 归并排序
if len(lists) <= 1:
return lists
num = int(len(lists) / 2)
left = merge_sort(lists[:num])
right = merge_sort(lists[num:])
return merge(left, right)程序结果示例:

8、桶排序/基数排序(Radix Sort)
优点:快,效率最好能达到O(1)
缺点:
1.首先是空间复杂度比较高,需要的额外开销大。排序有两个数组的空间开销,一个存放待排序数组,一个就是所谓的桶,比如待排序值是从0到m-1,那就需要m个桶,这个桶数组就要至少m个空间。
2.其次待排序的元素都要在一定的范围内等等。
算法思想:
是将阵列分到有限数量的桶子里。每个桶子再个别排序(有可能再使用别的排序算法或是以递回方式继续使用桶排序进行排序)。桶排序是鸽巢排序的一种归纳结果。当要被排序的阵列内的数值是均匀分配的时候,桶排序使用线性时间(Θ(n))。但桶排序并不是 比较排序,他不受到 O(n log n) 下限的影响。
简单来说,就是把数据分组,放在一个个的桶中,然后对每个桶里面的在进行排序。
例如要对大小为[1..1000]范围内的n个整数A[1..n]排序
首先,可以把桶大小设为10,这样就有100个桶了,具体而言,设集合B[1]存储[1..10]的整数,集合B[2]存储 (10..20]的整数,……集合B[i]存储( (i-1)*10, i*10]的整数,i = 1,2,..100。总共有 100个桶。
然后,对A[1..n]从头到尾扫描一遍,把每个A[i]放入对应的桶B[j]中。 再对这100个桶中每个桶里的数字排序,这时可用冒泡,选择,乃至快排,一般来说任 何排序法都可以。
最后,依次输出每个桶里面的数字,且每个桶中的数字从小到大输出,这 样就得到所有数字排好序的一个序列了。
假设有n个数字,有m个桶,如果数字是平均分布的,则每个桶里面平均有n/m个数字。如果
对每个桶中的数字采用快速排序,那么整个算法的复杂度是
O(n + m * n/m*log(n/m)) = O(n + nlogn - nlogm)
从上式看出,当m接近n的时候,桶排序复杂度接近O(n)
当然,以上复杂度的计算是基于输入的n个数字是平均分布这个假设的。这个假设是很强的 ,实际应用中效果并没有这么好。如果所有的数字都落在同一个桶中,那就退化成一般的排序了。
python代码实现:
# -*- coding: UTF-8 -*-
'''
Created on 2017年9月2日
Running environment:win7.x86_64 eclipse python3
@author: Lockey
'''
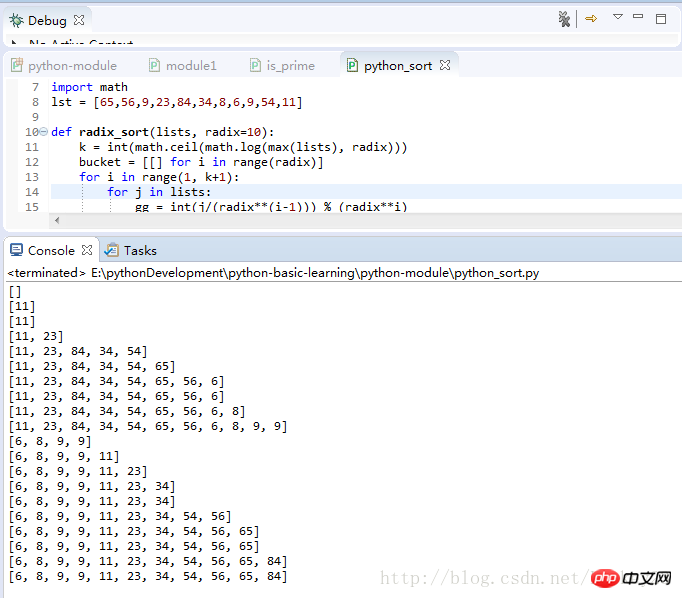
import math
lst = [65,56,9,23,84,34,8,6,9,54,11]
#因为列表数据范围在100以内,所以将使用十个桶来进行排序
def radix_sort(lists, radix=10):
k = int(math.ceil(math.log(max(lists), radix)))
bucket = [[] for i in range(radix)]
for i in range(1, k+1):
for j in lists:
gg = int(j/(radix**(i-1))) % (radix**i)
bucket[gg].append(j)
del lists[:]
for z in bucket:
lists += z
del z[:]
print(lists)
return lists程序运行测试结果:
以上是总结有关python八大排序算法(下)的详细内容。更多信息请关注PHP中文网其他相关文章!

 如何使用numpy创建多维数组?Apr 29, 2025 am 12:27 AM
如何使用numpy创建多维数组?Apr 29, 2025 am 12:27 AM使用NumPy创建多维数组可以通过以下步骤实现:1)使用numpy.array()函数创建数组,例如np.array([[1,2,3],[4,5,6]])创建2D数组;2)使用np.zeros(),np.ones(),np.random.random()等函数创建特定值填充的数组;3)理解数组的shape和size属性,确保子数组长度一致,避免错误;4)使用np.reshape()函数改变数组形状;5)注意内存使用,确保代码清晰高效。
 说明Numpy阵列中'广播”的概念。Apr 29, 2025 am 12:23 AM
说明Numpy阵列中'广播”的概念。Apr 29, 2025 am 12:23 AM播放innumpyisamethodtoperformoperationsonArraySofDifferentsHapesbyAutapityallate AligningThem.itSimplifififiesCode,增强可读性,和Boostsperformance.Shere'shore'showitworks:1)较小的ArraySaraySaraysAraySaraySaraySaraySarePaddedDedWiteWithOnestOmatchDimentions.2)
 说明如何在列表,Array.Array和用于数据存储的Numpy数组之间进行选择。Apr 29, 2025 am 12:20 AM
说明如何在列表,Array.Array和用于数据存储的Numpy数组之间进行选择。Apr 29, 2025 am 12:20 AMforpythondataTastorage,choselistsforflexibilityWithMixedDatatypes,array.ArrayFormeMory-effficityHomogeneousnumericalData,andnumpyArraysForAdvancedNumericalComputing.listsareversareversareversareversArversatilebutlessEbutlesseftlesseftlesseftlessforefforefforefforefforefforefforefforefforefforlargenumerdataSets; arrayoffray.array.array.array.array.array.ersersamiddreddregro
 Python中有可能理解吗?如果是,为什么以及如果不是为什么?Apr 28, 2025 pm 04:34 PM
Python中有可能理解吗?如果是,为什么以及如果不是为什么?Apr 28, 2025 pm 04:34 PM文章讨论了由于语法歧义而导致的Python中元组理解的不可能。建议使用tuple()与发电机表达式使用tuple()有效地创建元组。(159个字符)
 Python中的模块和包装是什么?Apr 28, 2025 pm 04:33 PM
Python中的模块和包装是什么?Apr 28, 2025 pm 04:33 PM本文解释了Python中的模块和包装,它们的差异和用法。模块是单个文件,而软件包是带有__init__.py文件的目录,在层次上组织相关模块。
 Python中的Docstring是什么?Apr 28, 2025 pm 04:30 PM
Python中的Docstring是什么?Apr 28, 2025 pm 04:30 PM文章讨论了Python中的Docstrings,其用法和收益。主要问题:Docstrings对于代码文档和可访问性的重要性。




热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

