

这篇文章主要跟大家介绍了利用python爬取散文网文章的相关资料,文中介绍的非常详细,对大家具有一定的参考学习价值,需要的朋友们下面来一起看看吧。
本文主要给大家介绍的是关于python爬取散文网文章的相关内容,分享出来供大家参考学习,下面一起来看看详细的介绍:
效果图如下:

配置python 2.7
bs4 requests
安装 用pip进行安装 sudo pip install bs4
sudo pip install requests
简要说明一下bs4的使用因为是爬取网页 所以就介绍find 跟find_all
find跟find_all的不同在于返回的东西不同 find返回的是匹配到的第一个标签及标签里的内容
find_all返回的是一个列表
比如我们写一个test.html 用来测试find跟find_all的区别。
内容是:
<html> <head> </head> <body> <p id="one"><a></a></p> <p id="two"><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >abc</a></p> <p id="three"><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >three a</a><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >three a</a><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >three a</a></p> <p id="four"><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >four<p>four p</p><p>four p</p><p>four p</p> a</a></p> </body> </html>
然后test.py的代码为:
from bs4 import BeautifulSoup import lxml if __name__=='__main__': s = BeautifulSoup(open('test.html'),'lxml') print s.prettify() print "------------------------------" print s.find('p') print s.find_all('p') print "------------------------------" print s.find('p',id='one') print s.find_all('p',id='one') print "------------------------------" print s.find('p',id="two") print s.find_all('p',id="two") print "------------------------------" print s.find('p',id="three") print s.find_all('p',id="three") print "------------------------------" print s.find('p',id="four") print s.find_all('p',id="four") print "------------------------------"
运行以后我们可以看到结果当获取指定标签时候两者区别不大当获取一组标签的时候两者的区别就会显示出来
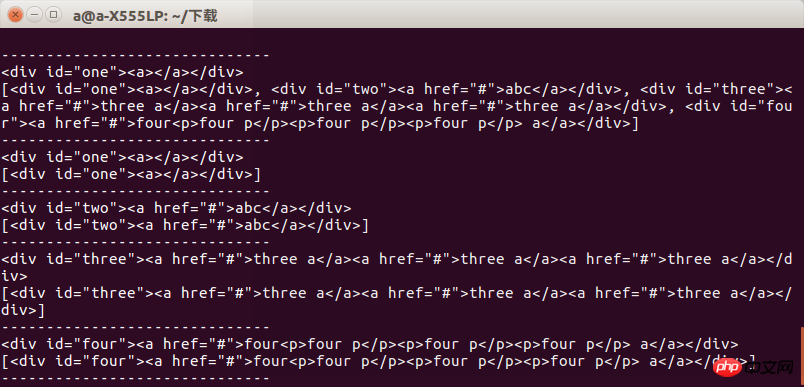
所以我们在使用时候要注意到底要的是什么,否则会出现报错
接下来就是通过requests 获取网页信息了,我不太懂别人为什么要写heard跟其他的东西
我直接进行网页访问,通过get方式获取散文网几个分类的二级网页然后通过一个组的测试,把所有的网页爬取一遍
def get_html():
url = "https://www.sanwen.net/"
two_html = ['sanwen','shige','zawen','suibi','rizhi','novel']
for doc in two_html:
i=1
if doc=='sanwen':
print "running sanwen -----------------------------"
if doc=='shige':
print "running shige ------------------------------"
if doc=='zawen':
print 'running zawen -------------------------------'
if doc=='suibi':
print 'running suibi -------------------------------'
if doc=='rizhi':
print 'running ruzhi -------------------------------'
if doc=='nove':
print 'running xiaoxiaoshuo -------------------------'
while(i<10):
par = {'p':i}
res = requests.get(url+doc+'/',params=par)
if res.status_code==200:
soup(res.text)
i+=i这部分的代码中我没有对res.status_code不是200的进行处理,导致的问题是会不显示错误,爬取的内容会有丢失。然后分析散文网的网页,发现是www.sanwen.net/rizhi/&p=1
p最大值是10这个不太懂,上次爬盘多多是100页,算了算了以后再分析。然后就通过get方法获取每页的内容。
获取每页内容以后就是分析作者跟题目了代码是这样的
def soup(html_text): s = BeautifulSoup(html_text,'lxml') link = s.find('p',class_='categorylist').find_all('li') for i in link: if i!=s.find('li',class_='page'): title = i.find_all('a')[1] author = i.find_all('a')[2].text url = title.attrs['href'] sign = re.compile(r'(//)|/') match = sign.search(title.text) file_name = title.text if match: file_name = sign.sub('a',str(title.text))
获取标题的时候出现坑爹的事,请问大佬们写散文你标题加斜杠干嘛,不光加一个还有加两个的,这个问题直接导致我后面写入文件的时候文件名出现错误,于是写正则表达式,我给你改行了吧。
最后就是获取散文内容了,通过每页的分析,获得文章地址,然后直接获取内容,本来还想直接通过改网页地址一个一个的获得呢,这样也省事了。
def get_content(url): res = requests.get('https://www.sanwen.net'+url) if res.status_code==200: soup = BeautifulSoup(res.text,'lxml') contents = soup.find('p',class_='content').find_all('p') content = '' for i in contents: content+=i.text+'\n' return content
最后就是写入文件保存ok
f = open(file_name+'.txt','w') print 'running w txt'+file_name+'.txt' f.write(title.text+'\n') f.write(author+'\n') content=get_content(url) f.write(content) f.close()
三个函数获取散文网的散文,不过有问题,问题在于不知道为什么有些散文丢失了我只能获取到大概400多篇文章,这跟散文网的文章是差很多很多的,但是确实是一页一页的获取来的,这个问题希望大佬帮忙看看。可能应该做网页无法访问的处理,当然我觉得跟我宿舍这个破网有关系
f = open(file_name+'.txt','w') print 'running w txt'+file_name+'.txt' f.write(title.text+'\n') f.write(author+'\n') content=get_content(url) f.write(content) f.close()
差点忘了效果图
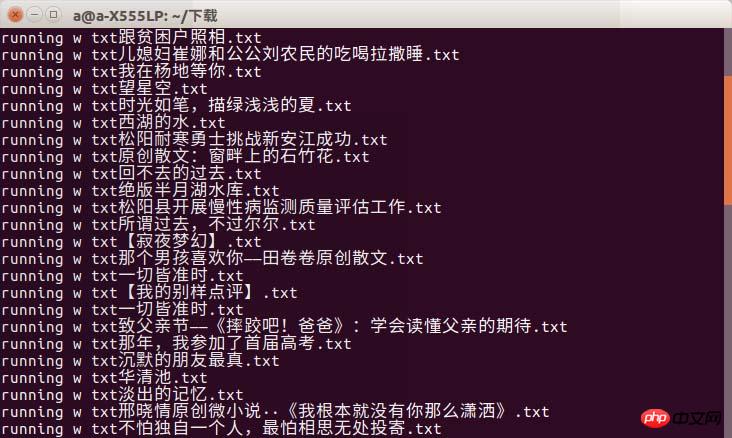
能会出现timeout现象吧,只能说上大学一定要选网好的啊!
以上是python爬取文章实例教程的详细内容。更多信息请关注PHP中文网其他相关文章!

 Python和时间:充分利用您的学习时间Apr 14, 2025 am 12:02 AM
Python和时间:充分利用您的学习时间Apr 14, 2025 am 12:02 AM要在有限的时间内最大化学习Python的效率,可以使用Python的datetime、time和schedule模块。1.datetime模块用于记录和规划学习时间。2.time模块帮助设置学习和休息时间。3.schedule模块自动化安排每周学习任务。
 Python:游戏,Guis等Apr 13, 2025 am 12:14 AM
Python:游戏,Guis等Apr 13, 2025 am 12:14 AMPython在游戏和GUI开发中表现出色。1)游戏开发使用Pygame,提供绘图、音频等功能,适合创建2D游戏。2)GUI开发可选择Tkinter或PyQt,Tkinter简单易用,PyQt功能丰富,适合专业开发。
 Python vs.C:申请和用例Apr 12, 2025 am 12:01 AM
Python vs.C:申请和用例Apr 12, 2025 am 12:01 AMPython适合数据科学、Web开发和自动化任务,而C 适用于系统编程、游戏开发和嵌入式系统。 Python以简洁和强大的生态系统着称,C 则以高性能和底层控制能力闻名。
 2小时的Python计划:一种现实的方法Apr 11, 2025 am 12:04 AM
2小时的Python计划:一种现实的方法Apr 11, 2025 am 12:04 AM2小时内可以学会Python的基本编程概念和技能。1.学习变量和数据类型,2.掌握控制流(条件语句和循环),3.理解函数的定义和使用,4.通过简单示例和代码片段快速上手Python编程。
 Python:探索其主要应用程序Apr 10, 2025 am 09:41 AM
Python:探索其主要应用程序Apr 10, 2025 am 09:41 AMPython在web开发、数据科学、机器学习、自动化和脚本编写等领域有广泛应用。1)在web开发中,Django和Flask框架简化了开发过程。2)数据科学和机器学习领域,NumPy、Pandas、Scikit-learn和TensorFlow库提供了强大支持。3)自动化和脚本编写方面,Python适用于自动化测试和系统管理等任务。
 您可以在2小时内学到多少python?Apr 09, 2025 pm 04:33 PM
您可以在2小时内学到多少python?Apr 09, 2025 pm 04:33 PM两小时内可以学到Python的基础知识。1.学习变量和数据类型,2.掌握控制结构如if语句和循环,3.了解函数的定义和使用。这些将帮助你开始编写简单的Python程序。
 如何在10小时内通过项目和问题驱动的方式教计算机小白编程基础?Apr 02, 2025 am 07:18 AM
如何在10小时内通过项目和问题驱动的方式教计算机小白编程基础?Apr 02, 2025 am 07:18 AM如何在10小时内教计算机小白编程基础?如果你只有10个小时来教计算机小白一些编程知识,你会选择教些什么�...
 如何在使用 Fiddler Everywhere 进行中间人读取时避免被浏览器检测到?Apr 02, 2025 am 07:15 AM
如何在使用 Fiddler Everywhere 进行中间人读取时避免被浏览器检测到?Apr 02, 2025 am 07:15 AM使用FiddlerEverywhere进行中间人读取时如何避免被检测到当你使用FiddlerEverywhere...


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

Dreamweaver Mac版
视觉化网页开发工具

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

WebStorm Mac版
好用的JavaScript开发工具

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

