

一、ASII
美国(国家)信息交换标准(代)码。
计算机中只有数字,一切都是用数字表示,屏幕上显示的一个一个的字符也不例外。
一个字节可表示的数字为0-255,足以显示键盘上的所有的字符 例如. a 为97 b为 98。这种数字与字符对应的编码规则,称为Asc11 码,ASC11 码的最高bit位都是0,也就是说,ASC11码的值都在0-127之间。
二、GB2312和GBK(中国的本地字符集)
中国大陆将每个中文字符都用2个字节表示,中文字符第个字节最高bit位都是1。这种编码格式称为 (gb2312) 国标码 那么gb2312码对应的数字都是负数。
在此gb2312基础上,又增了一些,比如繁体字 ,称为GBK
附:
GB18030编码是在GBK编码基础上的扩充,因为汉字更多,仅仅使用两位编码已经不能容纳要求的汉字,所以采用了2\4位混和的办法,可以支持更多的汉字编码。
三、ANSI
为了扩充ASCII编码,以用于显示本国的语言,不同的国家和地区制定了不同的标准,由此产生了 GB2312, BIG5, JIS等各自的编码标准。这些使用 2 个字节来代表一个字符的各种汉字延伸编码方式,称为 ANSI 编码,又称为"MBCS(Muilti-Bytes Charecter Set,多字节字符集)"。在简体中文系统下,ANSI 编码代表 GB2312 编码,在日文操作系统下,ANSI 编码代表 JIS 编码,所以在中文 windows下要转码成gb2312,gbk只需要把文本保存为ANSI 编码即可。 不同 ANSI 编码之间互不兼容。
四、本地字符集
在中国大陆使用的计算机系统上, GBK和GB2312就被称为该系统的本地字符集。
"中国 " 的中字,在中国大陆的编码是16进制的D6D0,在台湾是 A4A4 台湾的编码称为BIG5 大五码。在一个国家的本地化系统中出现的一个字符,通过电子邮件传到另外一个国家的本地化系统中,看到的就不是那个原始字符了,而是另外一个国家的字符或乱码。
五、Unicode编码
ISO 组织将全世界的符号进行了统一,称之为Unicode编码。
“中”这个符号,在全世界都是16进制的 4e2d。如果所有的计算机都使用Unicode编码,则"中"这个字,在全世界上的计算机上都能显示为"中",Unicode 编码的字符占用两个字节大小,对于AC11 码所表示的字符,只是简单地在AS11码原来占用的一个字节的前面,增中一个所有bits为0的字节, 它表示的字符的个数不会超过65535 ,实际上,它还保留了2000多个数值没有用于编码。
unicode 一统天下的局面还没有形成,在相当长时间内,本地化字符编码将与Unicode编码共存
java中的字符使用的都是Unicode编码。
java在通过Unicode保证跨平台的特性前提下,也支持本地平台字符集。
六、UTF-8
在java语言和其他程序的开发过程中.特别是XML 还涉及到UTF-8 UTF-16。广义上的unicode也包含 UTF8 和utf-16
UTF-8
--ASC11码字符保持原样,伋然只占用一个字节。
--对于其他国家的字符,UTF-8 使用2个或三个字节来表示。
--使用utf-8 编码的文件,通常都要用 EF BB BF 作为文件开头的三个字节数据。
七、UTF-8和unicode编码之间的转换规则
-- 0001-007f (一个字节)
0xxxxxx
-- 0000或其泛围在 0080 到 07ff之间的字符,
110xxxxx 10xxxxxx (11个有效bit位) (0080-07ff之间)一个unicode有16位,实际上只有11个有效位,其余都是标志。
-- 0800 到 ffff 之间的字符,1110xxxx 10xxxxxx 10xxxxxx (16比特有效位),软件很容易根据UTF-8 编码中那些固定不变的bit值,来确定一个字符占用的是一个字节,还是两个字节,还是三个字节。
八、UTF-8的优点
-- 不出现ox00 (在c语言中,\0 代表符串的结束结束标志,说明已经到了字符串的末尾)unicode 中 对于ACS11 字符,它都要占用两个字节,增加一个内容为空(0x00)的字节,浪费,而且这个字节,在C语言和其他程序有中特殊的应用。
-- 便于应用程序检查数据在传输中是否发生了错误 它可以检查出数据传输过程中是否出现了错误 。
-- 直接处理使用ASC11的文档
九、联通,联想和联
在记事本中输入联通 联想,联,查看.分别会看到一些错误情况

联通 (或联系) 出现乱码
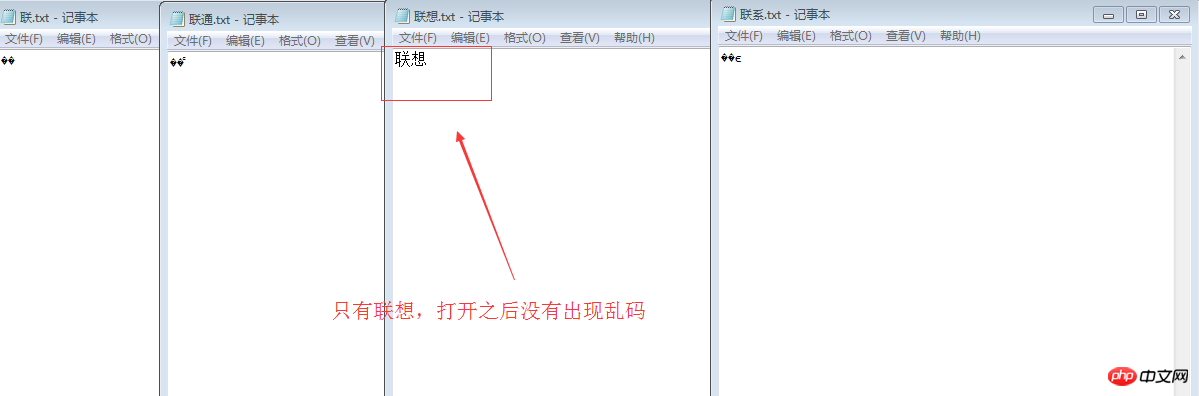
用ue打开,查看一下16进制,分别是C1AA CDA8 C1AA CFE8 //这些都是用的GB2312编码 如果是中,则是D6D0,也就是 C1AA 是联 CDA8 是通CFE8是想。可以用以下方式得到它产的二进制表示:
int x=0xCDA8; System.out.println(Integer.toBinaryString(x) );
//11000001 10101010 联 11001101 10101000 通
记事本中的文件,默认是按中文字符集GB2312来存诸的,所以"联"字就被解析成了 1100 0001 1010 1010 ,通字就被存成了 1100 1101 1010 1000, 打开记事本文档的时候,这些二进制形式,恰好都都对应上了 UTF-8 的规则,所以系统就认为这是一个UTF-8 编码的文件 就按UTF-8来解释,出现了乱码,解决的方法:保存的时候,直接按utf-8 保存就不会出现了。
十、用程序查看字符的编码
查看中文字符的GB2312 码
查看中文字符的UTF-8 码
查看中文字符的Unicode 码
public static void main(String[] args) throws UnsupportedEncodingException {
String str="中国"; //查看字符的unicode码,将一个字符转成整数,得到的就是unicode值/* for(int i=0;i<str.length();i++){
int unicodeCode=str.charAt(i);
System.out.println(unicodeCode); // 20013,22269
System.out.println(Integer.toHexString(unicodeCode)); //对应的16进制 4e2d,56fd
}*///查看字符的gb2312码byte [] buff =str.getBytes("gb2312"); for(int i=0;i<buff.length;i++){
System.out.println(buff[i]); // -42,-48, -71,-6System.out.println(Integer.toHexString(buff[i])); //ffffffd6 ,ffffffd0 ffffffb9,fffffffa }
}
以上是Java基础入门之字符编码的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

记事本++7.3.1
好用且免费的代码编辑器

MinGW - 适用于 Windows 的极简 GNU
这个项目正在迁移到osdn.net/projects/mingw的过程中,你可以继续在那里关注我们。MinGW:GNU编译器集合(GCC)的本地Windows移植版本,可自由分发的导入库和用于构建本地Windows应用程序的头文件;包括对MSVC运行时的扩展,以支持C99功能。MinGW的所有软件都可以在64位Windows平台上运行。

WebStorm Mac版
好用的JavaScript开发工具

SublimeText3 Linux新版
SublimeText3 Linux最新版

