
Heka配置的详细介绍

- 零下一度原创
- 2017-07-18 16:47:213044浏览
这个linux教程将为您说明Heka配置讲解,具体操作过程:
基于Heka,ElasticSearch和Kibana的分布式后端日志架构
目前主流的后端日志都采用的标准的elk模式(Elasticsearch,Logstash,Kinaba),分别负责日志存储,收集和日志可视化。
不过介于我们的日志文件多样,分布在各个不同的服务器,各种不同的日志,为了日后方便二次开发定制。所以采用了Mozilla仿照Logstash使用golang开源实现的Heka。
基于Heka,ElasticSearch和Kibana的分布式后端日志架构
目前主流的后端日志都采用的标准的elk模式(Elasticsearch,Logstash,Kinaba),分别负责日志存储,收集和日志可视化。
不过介于我们的日志文件多样,分布在各个不同的服务器,各种不同的日志,为了日后方便二次开发定制。所以采用了Mozilla仿照Logstash使用golang开源实现的Heka。
整体架构图
采用Heka,ElasticSearch和Kibana后的整体架构如下图所示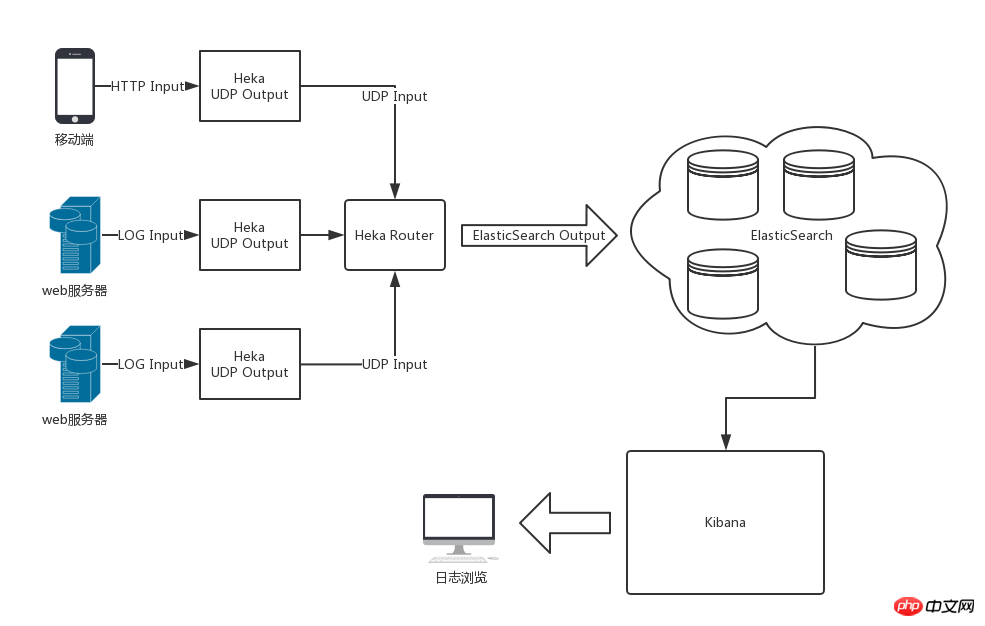
Heka篇
简介
Heka对日志的处理流程为输入 分割 解码 过滤 编码 输出。单个Heka服务内部的数据流了通过Heka定义的Message数据模型在各个模块内进行流转。
heka内置了常用的大多数模块插件,比如
输入插件有Logstreamer Input可以将日志文件作为输入源,
解码插件Nginx Access Log Decoder可以将nginx访问日志解码为标准的键值对数据交给后边的模块插件进行处理。
得益于输入输出的灵活配置,可以将分散各地的Heka收集到的日志数据加工后统一输出到日志中心的Heka进行统一编码后交给ElasticSearch存储。
以上是Heka配置的详细介绍的详细内容。更多信息请关注PHP中文网其他相关文章!
声明:
本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有涉嫌抄袭侵权的内容,请联系admin@php.cn