



1. 什么是闭包?
来看一些关于闭包的定义:
闭包是指有权访问另一个函数作用域中变量的函数 --《JS高级程序设计第三版》 p178
函数对象可以通过作用域链相关联起来,函数体内部的变量都可以保存在函数作用域内,这种特性称为 ‘闭包’ 。 --《JS权威指南》 p183
内部函数可以访问定义它们的外部函数的参数和变量(除了
this和arguments)。 --《JS语言精粹》 p36
来个定义总结
可以访问外部函数作用域中变量的
函数被内部函数访问的外部函数的变量可以保存在外部函数作用域内而不被回收---这是核心,后面我们遇到闭包都要想到,我们要重点关注被闭包引用的这个变量。
来创建个简单的闭包
var sayName = function(){var name = 'jozo';return function(){
alert(name);
}
};var say = sayName();
say();来解读后面两个语句:
var say = sayName():返回了一个匿名的内部函数保存在变量say中,并且引用了外部函数的变量name,由于垃圾回收机制,sayName函数执行完毕后,变量name并没有被销毁。say():执行返回的内部函数,依然能访问变量name,输出 'jozo' .
2. 闭包中的作用域链
理解作用域链对理解闭包也很有帮助。
变量在作用域中的查找方式应该都很熟悉了,其实这就是顺着作用域链往上查找的。
当函数被调用时:
先创建一个执行环境(execution context),及相应的作用域链;
将arguments和其他命名参数的值添加到函数的活动对象(activation object)
作用域链:当前函数的活动对象优先级最高,外部函数的活动对象次之,外部函数的外部函数的活动对象依次递减,直至作用域链的末端--全局作用域。优先级就是变量查找的先后顺序;
先来看个普通的作用域链:
function sayName(name){return name;
}var say = sayName('jozo');这段代码包含两个作用域:a.全局作用域;b.sayName函数的作用域,也就是只有两个变量对象,当执行到对应的执行环境时,该变量对象会成为活动对象,并被推入到执行环境作用域链的前端,也就是成为优先级最高的那个。 看图说话:

这图在JS高级程序设计书上也有,我重新绘了遍。
在创建sayName()函数时,会创建一个预先包含变量对象的作用域链,也就是图中索引为1的作用域链,并且被保存到内部的[[Scope]]属性中,当调用sayName()函数的时候,会创建一个执行环境,然后通过复制函数的[[Scope]]属性中的对象构建起作用域链,此后,又有一个活动对象(图中索引为0)被创建,并被推入执行环境作用域链的前端。
一般来说,当函数执行完毕后,局部活动对象就会被销毁,内存中仅保存全局作用域。但是,闭包的情况又有所不同 :
再来看看看闭包的作用域链:
function sayName(name){return function(){return name;
}
}var say = sayName('jozo');这个闭包实例比上一个例子多了一个匿名函数的作用域:
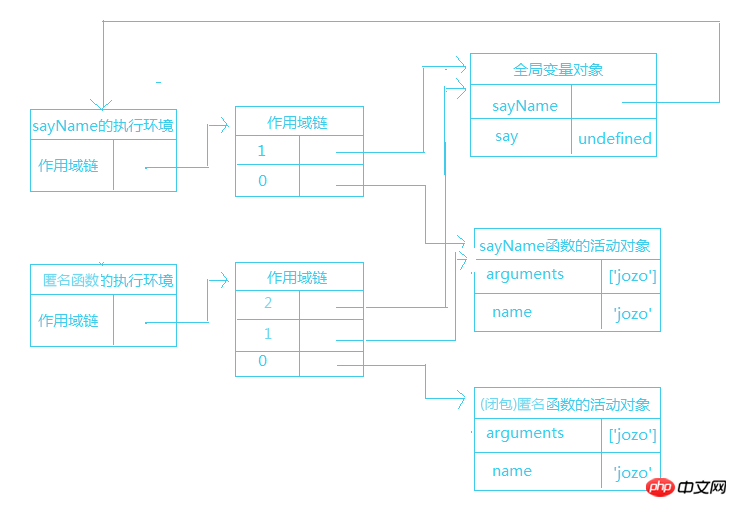
在匿名函数从sayName()函数中被返回后,它的作用域链被初始化为包含sayName()函数的活动对象和全局变量对象。这样,匿名函数就可以访问在sayName()中定义的所有变量和参数,更为重要的是,sayName()函数在执行完毕后,其活动对象也不会被销毁,因为匿名函数的作用域链依然在引用这个活动对象,换句话说,sayName()函数执行完后,其执行环境的作用域链会被销毁,但他的活动对象会留在内存中,知道匿名函数会销毁。这个也是后面要讲到的内存泄露的问题。
作用域链问题不写那么多了,写书上的东西也很累 o(╯□╰)o
3. 闭包的实例
实例1:实现累加
// 方式1var a = 0;var add = function(){
a++;
console.log(a)
}add();add();//方式2 :闭包var add = (function(){
var a = 0;
return function(){
a++;
console.log(a);
}
})();
console.log(a); //undefinedadd();add();
相比之下方式2更加优雅,也减少全局变量,将变量私有化实例2 :给每个li添加点击事件
var oli = document.getElementsByTagName('li'); var i; for(i = 0;i < 5;i++){
oli[i].onclick = function(){
alert(i);
}
} console.log(i); // 5 //执行匿名函数
(function(){
alert(i); //5
}());上面是一个经典的例子,我们都知道执行结果是都弹出5,也知道可以用闭包解决这个问题,但是我刚开始始终不能明白为什么每次弹出都是5,为什么闭包可以解决这问题。后来捋一捋还是把它弄清晰了:
a. 先来分析没用闭包前的情况:for循环中,我们给每个li点击事件绑定了一个匿名函数,匿名函数中返回了变量i的值,当循环结束后,变量i的值变为5,此时我们再去点击每个li,也就是执行相应的匿名函数(看上面的代码),这是变量i已经是5了,所以每个点击弹出5. 因为这里返回的每个匿名函数都是引用了同一个变量i,如果我们新建一个变量保存循环执行时当前的i的值,然后再让匿名函数应用这个变量,最后再返回这个匿名函数,这样就可以达到我们的目的了,这就是运用闭包来实现的!
b. 再来分析下运用闭包时的情况:
var oli = document.getElementsByTagName('li'); var i; for(i = 0;i < 5;i++){
oli[i].onclick = (function(num){ var a = num; // 为了说明问题 return function(){
alert(a);
}
})(i)
} console.log(i); // 5这里for循环执行时,给点击事件绑定的匿名函数传递i后立即执行返回一个内部的匿名函数,因为参数是按值传递的,所以此时形参num保存的就是当前i的值,然后赋值给局部变量 a,然后这个内部的匿名函数一直保存着a的引用,也就是一直保存着当前i的值。 所以循环执行完毕后点击每个li,返回的匿名函数执行弹出各自保存的 a 的引用的值。
4. 闭包的运用
我们来看看闭包的用途。事实上,通过使用闭包,我们可以做很多事情。比如模拟面向对象的代码风格;更优雅,更简洁的表达出代码;在某些方面提升代码的执行效率。
1. 匿名自执行函数
我们在实际情况下经常遇到这样一种情况,即有的函数只需要执行一次,其内部变量无需维护,比如UI的初始化,那么我们可以使用闭包:
//将全部li字体变为红色
(function(){ var els = document.getElementsByTagName('li');for(var i = 0,lng = els.length;i < lng;i++){
els[i].style.color = 'red';
}
})();我们创建了一个匿名的函数,并立即执行它,由于外部无法引用它内部的变量,
因此els,i,lng这些局部变量在执行完后很快就会被释放,节省内存!
关键是这种机制不会污染全局对象。
2. 实现封装/模块化代码
var person= function(){ //变量作用域为函数内部,外部无法访问 var name = "default"; return {
getName : function(){
return name;
},
setName : function(newName){
name = newName;
}
}
}();console.log(person.name);//直接访问,结果为undefined
console.log(person.getName()); //default
person.setName("jozo");
console.log(person.getName()); //jozo3. 实现面向对象中的对象
这样不同的对象(类的实例)拥有独立的成员及状态,互不干涉。虽然JavaScript中没有类这样的机制,但是通过使用闭包,
我们可以模拟出这样的机制。还是以上边的例子来讲:
function Person(){ var name = "default"; return {
getName : function(){
return name;
},
setName : function(newName){
name = newName;
}
}
};
var person1= Person();
print(person1.getName());
john.setName("person1");
print(person1.getName()); // person1
var person2= Person();
print(person2.getName());
jack.setName("erson2");
print(erson2.getName()); //person2Person的两个实例person1 和 person2 互不干扰!因为这两个实例对name这个成员的访问是独立的 。
5. 内存泄露及解决方案
垃圾回收机制
说到内存管理,自然离不开JS中的垃圾回收机制,有两种策略来实现垃圾回收:标记清除 和 引用计数;
标记清除:垃圾收集器在运行的时候会给存储在内存中的所有变量都加上标记,然后,它会去掉环境中的变量的标记和被环境中的变量引用的变量的标记,此后,如果变量再被标记则表示此变量准备被删除。 2008年为止,IE,Firefox,opera,chrome,Safari的javascript都用使用了该方式;
引用计数:跟踪记录每个值被引用的次数,当声明一个变量并将一个引用类型的值赋给该变量时,这个值的引用次数就是1,如果这个值再被赋值给另一个变量,则引用次数加1。相反,如果一个变量脱离了该值的引用,则该值引用次数减1,当次数为0时,就会等待垃圾收集器的回收。
这个方式存在一个比较大的问题就是循环引用,就是说A对象包含一个指向B的指针,对象B也包含一个指向A的引用。 这就可能造成大量内存得不到回收(内存泄露),因为它们的引用次数永远不可能是 0 。早期的IE版本里(ie4-ie6)采用是计数的垃圾回收机制,闭包导致内存泄露的一个原因就是这个算法的一个缺陷。
我们知道,IE中有一部分对象并不是原生额javascript对象,例如,BOM和DOM中的对象就是以COM对象的形式实现的,而COM对象的垃圾回收机制采用的就是引用计数。因此,虽然IE的javascript引擎采用的是标记清除策略,但是访问COM对象依然是基于引用计数的,因此只要在IE中设计COM对象就会存在循环引用的问题!
举个栗子:
window.onload = function(){var el = document.getElementById("id");
el.onclick = function(){
alert(el.id);
}
}这段代码为什么会造成内存泄露?
el.onclick= function () {
alert(el.id);
};执行这段代码的时候,将匿名函数对象赋值给el的onclick属性;然后匿名函数内部又引用了el对象,存在循环引用,所以不能被回收;
解决方法:
window.onload = function(){var el = document.getElementById("id");var id = el.id; //解除循环引用
el.onclick = function(){
alert(id);
}
el = null; // 将闭包引用的外部函数中活动对象清除
}6. 总结闭包的优缺点
优点:
可以让一个变量常驻内存 (如果用的多了就成了缺点
避免全局变量的污染
私有化变量
缺点
因为闭包会携带包含它的函数的作用域,因此会比其他函数占用更多的内存
引起内存泄露
以上是js中关于闭包的详细介绍的详细内容。更多信息请关注PHP中文网其他相关文章!

 幕后:什么语言能力JavaScript?Apr 28, 2025 am 12:01 AM
幕后:什么语言能力JavaScript?Apr 28, 2025 am 12:01 AMJavaScript在浏览器和Node.js环境中运行,依赖JavaScript引擎解析和执行代码。1)解析阶段生成抽象语法树(AST);2)编译阶段将AST转换为字节码或机器码;3)执行阶段执行编译后的代码。
 Python和JavaScript的未来:趋势和预测Apr 27, 2025 am 12:21 AM
Python和JavaScript的未来:趋势和预测Apr 27, 2025 am 12:21 AMPython和JavaScript的未来趋势包括:1.Python将巩固在科学计算和AI领域的地位,2.JavaScript将推动Web技术发展,3.跨平台开发将成为热门,4.性能优化将是重点。两者都将继续在各自领域扩展应用场景,并在性能上有更多突破。
 Python vs. JavaScript:开发环境和工具Apr 26, 2025 am 12:09 AM
Python vs. JavaScript:开发环境和工具Apr 26, 2025 am 12:09 AMPython和JavaScript在开发环境上的选择都很重要。1)Python的开发环境包括PyCharm、JupyterNotebook和Anaconda,适合数据科学和快速原型开发。2)JavaScript的开发环境包括Node.js、VSCode和Webpack,适用于前端和后端开发。根据项目需求选择合适的工具可以提高开发效率和项目成功率。
 JavaScript是用C编写的吗?检查证据Apr 25, 2025 am 12:15 AM
JavaScript是用C编写的吗?检查证据Apr 25, 2025 am 12:15 AM是的,JavaScript的引擎核心是用C语言编写的。1)C语言提供了高效性能和底层控制,适合JavaScript引擎的开发。2)以V8引擎为例,其核心用C 编写,结合了C的效率和面向对象特性。3)JavaScript引擎的工作原理包括解析、编译和执行,C语言在这些过程中发挥关键作用。
 JavaScript的角色:使网络交互和动态Apr 24, 2025 am 12:12 AM
JavaScript的角色:使网络交互和动态Apr 24, 2025 am 12:12 AMJavaScript是现代网站的核心,因为它增强了网页的交互性和动态性。1)它允许在不刷新页面的情况下改变内容,2)通过DOMAPI操作网页,3)支持复杂的交互效果如动画和拖放,4)优化性能和最佳实践提高用户体验。
 C和JavaScript:连接解释Apr 23, 2025 am 12:07 AM
C和JavaScript:连接解释Apr 23, 2025 am 12:07 AMC 和JavaScript通过WebAssembly实现互操作性。1)C 代码编译成WebAssembly模块,引入到JavaScript环境中,增强计算能力。2)在游戏开发中,C 处理物理引擎和图形渲染,JavaScript负责游戏逻辑和用户界面。
 从网站到应用程序:JavaScript的不同应用Apr 22, 2025 am 12:02 AM
从网站到应用程序:JavaScript的不同应用Apr 22, 2025 am 12:02 AMJavaScript在网站、移动应用、桌面应用和服务器端编程中均有广泛应用。1)在网站开发中,JavaScript与HTML、CSS一起操作DOM,实现动态效果,并支持如jQuery、React等框架。2)通过ReactNative和Ionic,JavaScript用于开发跨平台移动应用。3)Electron框架使JavaScript能构建桌面应用。4)Node.js让JavaScript在服务器端运行,支持高并发请求。
 Python vs. JavaScript:比较用例和应用程序Apr 21, 2025 am 12:01 AM
Python vs. JavaScript:比较用例和应用程序Apr 21, 2025 am 12:01 AMPython更适合数据科学和自动化,JavaScript更适合前端和全栈开发。1.Python在数据科学和机器学习中表现出色,使用NumPy、Pandas等库进行数据处理和建模。2.Python在自动化和脚本编写方面简洁高效。3.JavaScript在前端开发中不可或缺,用于构建动态网页和单页面应用。4.JavaScript通过Node.js在后端开发中发挥作用,支持全栈开发。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

SublimeText3汉化版
中文版,非常好用

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

SublimeText3 Linux新版
SublimeText3 Linux最新版

