
什么是决策树算法?

- PHP中文网原创
- 2017-06-20 10:11:184964浏览
英文名字: Decision Tree
决策树是一种典型的分类方法,首先对数据进行处理,利用归纳算法生成可读的规则和决策树,然后使用决策对新数据进行分析。本质上决策树是通过一系列规则对数据进行分类的过程。
决策树是一个监督式学习方法,主要用于分类和回归。 算法的目标是通过推断数据特征,学习决策规则从而创建一个预测目标变量的模型。
决策树类似if-else结构,它的结果就是你要生成这样一个可以从树根开始不断判断选择到叶子节点的树。 但是这里的if-else判断条件不是人工设置,而是计算机根据我们提供的算法自动生成的。
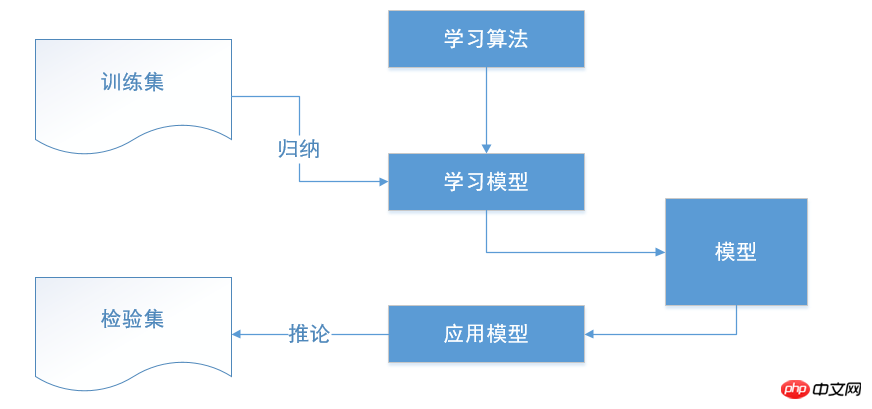
决策树组成元素
决策点
是对几种可能方案的选择,即最后选择的最佳方案。如果决策属于多级决策,则决策树的中间可以有多个决策点,以决策树根部的决策点为最终决策方案。
状态节点
代表备选方案的经济效果(期望值),通过各状态节点的经济效果的对比,按照一定的决策标准就可以选出最佳方案。由状态节点引出的分支称为概率枝,概率枝的数目表示可能出现的自然状态数目每个分枝上要注明该状态出现的概率。
结果节点
将每个方案在各种自然状态下取得的损益值标注于结果节点的右端
决策树组优缺点
决策树优势
简单易懂,原理清晰,决策树可以实现可视化
推理过程容易理解,决策推理过程可以表示成if-else形式
推理过程完全依赖于属性变量的取值特点
可自动忽略目标变量没有贡献的属性变量,也为判断属性变量的重要性,减少变量的数目提供参考
决策树劣势
可能会建立过于复杂的规则,即过拟合。
决策树有时候是不稳定的,因为数据微小的变动,可能生成完全不同的决策树。
学习最优决策树是一个NP完全问题。 所以,实际决策树学习算法是基于试探性算法,例如在每个节点实现局部最优值的贪心算法。 这样的算法是无法保证返回一个全局最优的决策树。可以通过随机选择特征和样本训练多个决策树来缓解这个问题。
有些问题学习起来非常难,因为决策树很难表达。如:异或问题、奇偶校验或多路复用器问题
如果有些因素占据支配地位,决策树是有偏的。因此建议在拟合决策树之前先平衡数据的影响因子。
决策树常见算法
决策树的算法有很多,有CART、ID3、C4.5、C5.0等,其中ID3、C4.5、C5.0都是基于信息熵的, 而CART采用的是类似于熵的指数作为分类决策,形成决策树后之后还要进行剪枝。
熵(Entropy): 系统的凌乱程度
ID3算法
ID3算法是一种分类决策树算法。他通过一系列的规则,将数据最后分类成决策树的形式,分类的根据是熵。
ID3算法是一种经典的决策树学习算法,由Quinlan提出。 ID3算法的基本思想是,以信息熵为度量,用于决策树节 点的属性选择,每次优先选取信息量最多的属性,亦即能使熵值 变为最小的属性,以构造一颗熵值下降最快的决策树,到叶子节 点处的熵值为0。此时,每个叶子节点对应的实例集中的实例属于 同一类。
通过ID3算法来实现客户流失的预警分析,找出客户流失的 特征,以帮助电信公司有针对性地改善客户关系,避免客户流失
利用决策树方法进行数据挖掘,一般有如下步骤:数据预处 理、决策树挖掘操作,模式评估和应用。
C4.5算法
C4.5是ID3的进一步延伸,通过将连续属性离散化,去除了特征的限制。C4.5将训练树转换为一系列if-then的语法规则。可确定这些规则的准确性,从而决定哪些应该被采用。如果去掉某项规则,准确性能提高,则应该实行修剪。
C4.5与ID3在核心的算法是一样的,但是有一点所采用的办法是不同的,C4.5采用了信息增益率作为划分的根据,克服了ID3算法中采用信息增益划分导致属性选择偏向取值多的属性。
C5.0算法
C5.0较C4.5使用更小的内存,建立更小的决策规则,更加准确。
CART算法
分类与回归树(CART——Classification And Regression Tree)) 是一种非常有趣并且十分有效的非参数分类和回归方法。它通过构建二叉树达到预测目的。 分类与回归树CART 模型最早由Breiman 等人提出,已经在统计领域和数据挖掘技术中普遍使用。它采用与传统统计学完全不同的方式构建预测准则,它是以二叉树的形式给出,易于理解、使用和解释。由CART 模型构建的预测树在很多情况下比常用的统计方法构建的代数学预测准则更加准确,且数据越复杂、变量越多,算法的优越性就越显著。模型的关键是预测准则的构建,准确的。 定义: 分类和回归首先利用已知的多变量数据构建预测准则, 进而根据其它变量值对一个变量进行预测。在分类中, 人们往往先对某一客体进行各种测量, 然后利用一定的分类准则确定该客体归属那一类。例如, 给定某一化石的鉴定特征, 预测该化石属那一科、那一属, 甚至那一种。另外一个例子是, 已知某一地区的地质和物化探信息, 预测该区是否有矿。回归则与分类不同, 它被用来预测客体的某一数值, 而不是客体的归类。例如, 给定某一地区的矿产资源特征, 预测该区的资源量。
CART和C4.5很相似,但是它支持数值的目标变量(回归)且不产生决策规则。CART使用特征和阈值在每个节点获得最大的信息增益来构建决策树。
scikit-learn 使用的是 CART 算法
示例代码:
#! /usr/bin/env python#-*- coding:utf-8 -*-from sklearn import treeimport numpy as np# scikit-learn使用的决策树算法是CARTX = [[0,0],[1,1]] Y = ["A","B"] clf = tree.DecisionTreeClassifier() clf = clf.fit(X,Y) data1 = np.array([2.,2.]).reshape(1,-1)print clf.predict(data1) # 预测类别 print clf.predict_proba(data1) # 预测属于各个类的概率
好,就这些了,希望对你有帮助。
本文github地址:
20170619_决策树算法.md
欢迎补充
以上是什么是决策树算法?的详细内容。更多信息请关注PHP中文网其他相关文章!