

继续上一篇文章的内容,上一篇文章中已经将url管理器和下载器写好了。接下来就是url解析器,总的来说这个模块是几个模块中比较难的。因为通过下载器下载完页面之后,我们虽然得到了页面,但是这并不是我们想要的结果。而且由于页面的代码很多,我们很难去里面找到自己想要的数据。所幸,我们下载的是html页面,它是一种由多个多层次的节点组成的树型结构的文本文件。所以,相较于txt文件,我们更加容易定位到我们要找的数据块。现在我们要做的就是去原页面去分析一下,我们想要的数据到底在哪。
打开百度百科pyton词条的页面,然后按F12调出开发者工具。通过使用工具,我们就能定位到页面的内容:
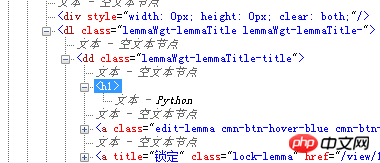

这样我们就找到了我们想要的信息处在哪个标签里了。
1 import bs4 2 import re 3 from urllib.parse import urljoin 4 class HtmlParser(object): 5 """docstring for HtmlParser""" 6 def _get_new_urls(self, url, soup): 7 new_urls = set() 8 links = soup.find_all('a', href = re.compile(r'/item/.')) 9 for link in links:10 new_url = re.sub(r'(/item/)(.*)', r'\1%s' % link.getText(), link['href'])11 new_full_url = urljoin(url, new_url)12 new_urls.add(new_full_url)13 return new_urls14 15 def _get_new_data(self, url, soup):16 res_data = {}17 #url18 res_data['url'] = url19 #<dd class="lemmaWgt-lemmaTitle-title">20 title_node = soup.find('dd', class_ = "lemmaWgt-lemmaTitle-title").find('h1')21 res_data['title'] = title_node.getText()22 #<div class="lemma-summary" label-module="lemmaSummary">23 summary_node = soup.find('div', class_ = "lemma-summary")24 res_data['summary'] = summary_node.getText()25 return res_data26 27 def parse(self, url, html_cont):28 if url is None or html_cont is None:29 return 30 soup = bs4.BeautifulSoup(html_cont, 'lxml')31 new_urls = self._get_new_urls(url, soup)32 new_data = self._get_new_data(url, soup)33 return new_urls, new_data解析器只有一个外部方法就是parse方法,
a.首先它会接受url, html_cont两个参数,然后进行判断页面内容是否为空
b.调用bs4模块的方法来解析网页内容,'lxml'为文档解析器,默认的为html.parser,bs官方推荐我们用lxml,那就听它的吧,谁让人家是官方呢。
c.接下来就是调用两个内部函数来获取新的url列表和数据
d.最后将url列表和数据返回
这里有一些注意点
1.bs的方法调用还有一个参数,from_encoding 这个和我在下载器那里的重复了,所以我就取消了,两个的功能是一样的。
2.获取url列表的内部方法,需要用到正则表达式,这里我也是摸着石头过河,不是很会,中间也调试过许多次。
3.数据是放在字典中的,这样可以通过key来增改删除数据。
最好,就直接数据输出了,这个比较简单,直接上代码。
1 class HtmlOutputer(object): 2 """docstring for HtmlOutputer""" 3 def __init__(self): 4 self.datas = [] 5 def collect_data(self, new_data): 6 if new_data is None: 7 return 8 self.datas.append(new_data) 9 def output_html(self):10 fout = open('output1.html', 'w', encoding = 'utf-8')11 fout.write('<html>')12 fout.write('<head><meta charset="utf-8"></head>')13 fout.write('<body>')14 fout.write('<table>')15 for data in self.datas:16 fout.write('<tr>')17 fout.write('<td>%s</td>' % data['url'])18 fout.write('<td>%s</td>' % data['title'])19 fout.write('<td>%s</td>' % data['summary'])20 fout.write('</tr>')21 fout.write('</table>')22 fout.write('</body>')23 fout.write('</html>')24 fout.close()这里也有两个注意点
1.fout = open('output1.html', 'w', encoding = 'utf-8'),这里的encoding参数一定要加,不然会报错,在windows平台,它默认是使用gbk编码来写文件的。
2.fout.write('
'),这里的meta标签也要加上,因为要告诉浏览器使用什么编码来渲染页面,这里我一开始没加弄了很久,我打开页面的内容,发现里面是中文的,结果浏览器展示的就是乱码。总的来说,因为整个页面采集过程结果好几个模块,所以编码问题要非常小心,不然少不留神就会出错。
最后总结,这段程序还有许多方面可以深入探讨:
1.页面的数据量过小,我尝试了10000个页面的爬取。一旦数据量剧增之后,就会带来一下问题,第一是待爬取url和已爬取url就不能放在set集合中了,要么放到radi缓存服务器里,要么放到mysql数据库中
2.第二,数据也是同样的,字典也满足不了了,需要专门的数据库来存放
3.第三量上去之后,对爬取效率就有要求了,那么多线程就要加进来
4.第四,一旦布置好任务,单台服务器的压力会过大,而且一旦宕机,风险很大,所以分布式的高可用架构也要跟上来
5.一方面是页面的内容过于简单,都是静态页面,不涉及登录,也不涉及ajax动态获取
6.这只是数据采集,后续还有建模,分析…………
综上所述,路还远的很呢,加油!
以上是爬虫问题解决的相关问题的详细内容。更多信息请关注PHP中文网其他相关文章!

 2小时的Python计划:一种现实的方法Apr 11, 2025 am 12:04 AM
2小时的Python计划:一种现实的方法Apr 11, 2025 am 12:04 AM2小时内可以学会Python的基本编程概念和技能。1.学习变量和数据类型,2.掌握控制流(条件语句和循环),3.理解函数的定义和使用,4.通过简单示例和代码片段快速上手Python编程。
 Python:探索其主要应用程序Apr 10, 2025 am 09:41 AM
Python:探索其主要应用程序Apr 10, 2025 am 09:41 AMPython在web开发、数据科学、机器学习、自动化和脚本编写等领域有广泛应用。1)在web开发中,Django和Flask框架简化了开发过程。2)数据科学和机器学习领域,NumPy、Pandas、Scikit-learn和TensorFlow库提供了强大支持。3)自动化和脚本编写方面,Python适用于自动化测试和系统管理等任务。
 您可以在2小时内学到多少python?Apr 09, 2025 pm 04:33 PM
您可以在2小时内学到多少python?Apr 09, 2025 pm 04:33 PM两小时内可以学到Python的基础知识。1.学习变量和数据类型,2.掌握控制结构如if语句和循环,3.了解函数的定义和使用。这些将帮助你开始编写简单的Python程序。
 如何在10小时内通过项目和问题驱动的方式教计算机小白编程基础?Apr 02, 2025 am 07:18 AM
如何在10小时内通过项目和问题驱动的方式教计算机小白编程基础?Apr 02, 2025 am 07:18 AM如何在10小时内教计算机小白编程基础?如果你只有10个小时来教计算机小白一些编程知识,你会选择教些什么�...
 如何在使用 Fiddler Everywhere 进行中间人读取时避免被浏览器检测到?Apr 02, 2025 am 07:15 AM
如何在使用 Fiddler Everywhere 进行中间人读取时避免被浏览器检测到?Apr 02, 2025 am 07:15 AM使用FiddlerEverywhere进行中间人读取时如何避免被检测到当你使用FiddlerEverywhere...
 Python 3.6加载Pickle文件报错"__builtin__"模块未找到怎么办?Apr 02, 2025 am 07:12 AM
Python 3.6加载Pickle文件报错"__builtin__"模块未找到怎么办?Apr 02, 2025 am 07:12 AMPython3.6环境下加载Pickle文件报错:ModuleNotFoundError:Nomodulenamed...
 如何提高jieba分词在景区评论分析中的准确性?Apr 02, 2025 am 07:09 AM
如何提高jieba分词在景区评论分析中的准确性?Apr 02, 2025 am 07:09 AM如何解决jieba分词在景区评论分析中的问题?当我们在进行景区评论分析时,往往会使用jieba分词工具来处理文�...
 如何使用正则表达式匹配到第一个闭合标签就停止?Apr 02, 2025 am 07:06 AM
如何使用正则表达式匹配到第一个闭合标签就停止?Apr 02, 2025 am 07:06 AM如何使用正则表达式匹配到第一个闭合标签就停止?在处理HTML或其他标记语言时,常常需要使用正则表达式来�...


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

MinGW - 适用于 Windows 的极简 GNU
这个项目正在迁移到osdn.net/projects/mingw的过程中,你可以继续在那里关注我们。MinGW:GNU编译器集合(GCC)的本地Windows移植版本,可自由分发的导入库和用于构建本地Windows应用程序的头文件;包括对MSVC运行时的扩展,以支持C99功能。MinGW的所有软件都可以在64位Windows平台上运行。

PhpStorm Mac 版本
最新(2018.2.1 )专业的PHP集成开发工具

SublimeText3汉化版
中文版,非常好用

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

禅工作室 13.0.1
功能强大的PHP集成开发环境

