
Python对杂乱文本数据进行处理实例

- PHP中文网原创
- 2017-06-20 16:34:565634浏览
一、运行环境
1、python版本 2.7.13 博客代码均是这个版本
2、系统环境:win7 64位系统
二、需求 对杂乱文本数据进行处理
部分数据截图如下,第一个字段是原字段,后面3个是清洗出的字段,从数据库中聚合字段观察,乍一看数据比较规律,类似(币种 金额 万元)这样,我想着用sql写条件判断,统一转换为‘万元人民币’ 单位,用sql脚本进行字符串截取即可完成,但是后面发现数据并不规则,条件判断太多清洗质量也不一定,有的前面不是左括号,有的字段里面没有币种,有的数字并不是整数,有的没有万字,这样如果存储成数字和‘万元人民币’单位两个字段写sql脚本复杂了,mysql我也没找到能从文本中提取数字的函数,正则表达式常用于where条件中好像,如果谁知道mysql有类似从文本中过滤文本提取数字的函数,可以告诉我哈,这样就不用费这么多功夫,用kettle一个工具即可,工具活学活用最好。
结合用python的经验,python对字符串过滤有许多函数稍后代码中就是用了这样的办法去过滤文本。
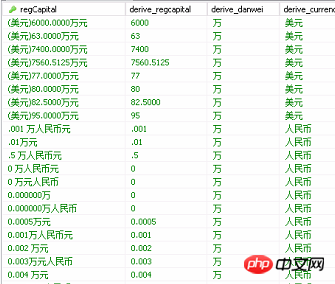
三、对数据处理的宏观逻辑思考
拿到数据,先不要着急写代码,先思考清洗的逻辑,这点很关键,方向对了事半功倍,剩下的时间就是代码实现逻辑和调试代码的过程。
3.1思考过程 不写代码:
我想实现的最终的数据清洗是将资金字段换算成【金额+单位+各币种】的组合形式或者【金额+单位+统一的人民币币种】(币种进行汇率换算),分两步或者三步都可以
3.1.1拆分出三个字段,数字,单位,币种
(单元分为万和不含万,币种分为人民币和具体的外币)
3.1.2将单位统一换为万为单位
第一步中单位不是万的 数字部分/10000,是万的数字部分保持不变
3.1.3将币种统一为人民币
币种是人民币的前两个字段都不变,不是的数字部分变为数字*各外币兑换人民币的汇率,单位不变依旧是第二步统一的‘万’
3.2期望各步骤清洗效果 数据列举:
从这个结果着手我们步步拆解,先梳理 清洗逻辑部分
3.2.1第一次清洗期望效果 拆分出三个字段 数字 单位 币种:
①字段值=“2000元人民币”,第一次清洗2000 不含万 人民币
②字段值=“2000万元人民币”,第一次清洗2000 万 人民币
③字段值=“2000万元外币”, 第一次清洗2000 万 外币
3.2.2第二次清洗期望效果 将单位 统一归为万:
#二次处理条件case when 单位=‘万’ then 金额 else 金额/10000 end as 第二次金额
①字段值=“2000元人民币”0.2 万 人民币
②字段值=“2000万元人民币”2000 万 人民币
③字段值=“2000万元外币”2000 万 外币
注意:如果上面达到需求 则清洗完毕,如果想将单位换成人民币就进行下面三次清洗
3.2.3第三次清洗期望效果:单位 币种都统一为万+人民币
如果最后需求是换算成币种统一人民币,那么我们就在二次清洗后的基础上再写条件就好,
#三次处理条件case when 币种=‘人民币’ then 金额 else 金额*币种和人民币的换算汇率 end as 第三次金额
①字段值=“2000元人民币”0.2 万 人民币
②字段值=“2000万元人民币”2000 万 人民币
③字段值=“2000万元外币”2000*外币兑换人民币汇率 万 人民币
四、对具体代码的宏观逻辑思考
币种和单位这两个就2种情况,很好写
4.1、币种部分
这个条件简单,如果币种的值在字符中出现就让新字段等于这个币种的值即可。
4.2、单位(万为单位)
这个条件也简单,万字出现在字符中 单位这个变量=‘万’ 没出现就让单位变量等于‘不含万’,这样写是为了方便下一步对数字进行二次处理的时候写条件判断了。
4.3、数字部分 确保清洗后和原值逻辑上一样 做些判断
确保清洗后和原值逻辑上一样意思是假如有这样字段300.0100万清洗后变成300.01 万 人民币 也是正确的。
filter(str.isdigit,字段的值)这个代码我首先知道可以将文本中数字取出,同过对字段group by 聚合以后知道有小数点的字段,取出的值不再带有小数点,如‘20.01万’,filter(str.isdigit,‘20.01万’)取出的数字就是2001,显然这个数字是不正确,因此就需要考虑有无小数点的情况,有小数点的做到和原字段一样
四、第一次清洗主要代码,先不读取数据库数据
从数据库中抽异常值10个左右做测试,info是regCapital字段的值
#带小数点的以小数点分割 取出小数点前后部分进行拼接if '.' in info and int(filter(str.isdigit,info.split('.')[1]))>0:
derive_regcapital=filter(str.isdigit,info.split('.')[0])+'.'+filter(str.isdigit,info.split('.')[1])
elif '.' in info and int(filter(str.isdigit,info.split('.')[1]))==0:
derive_regcapital = filter(str.isdigit, info.split('.')[0])
elif filter(str.isdigit,info)=='':
derive_regcapital='0'else:
derive_regcapital=filter(str.isdigit,info)#单位 以万和不含万 为统一if '万' in info:
derive_danwei='万'else:
derive_danwei='不含万' #币种 第一次清洗 外币保留外币字段 聚合大量数据 发现数据中含有外币的情况大致有下面这些情况 如果有新外币出现 进行数据的update操作即可if '美元' in info:
derive_currency='美元'
elif '港币' in info:
derive_currency = '港币'
elif '阿富汗尼' in info:
derive_currency = '阿富汗尼'
elif '澳元' in info:
derive_currency = '澳元'
elif '英镑' in info:
derive_currency = '英镑'
elif '加拿大元' in info:
derive_currency = '加拿大元'
elif '日元' in info:
derive_currency = '日元'
elif '港币' in info:
derive_currency = '港币'
elif '法郎' in info:
derive_currency = '法郎'
elif '欧元' in info:
derive_currency = '欧元'
elif '新加坡' in info:
derive_currency = '新加坡元'else:
derive_currency = '人民币'五、全部代码:读取数据库数据 进行全量清洗
第四步我是将部分数据做了测试,验证代码无误,此时逻辑上应再从宏观上再拓展,将info变量动态变为数据库中所有的值,进行全量清洗
#coding:utf-8from class_mysql import Mysql
project=Mysql('s_58infor_data',[],0,conn_type='local')
p2=Mysql('etl1_58infor_data',[],24,conn_type='local')
field_list=p2.select_fields(db='local_db',table='etl1_58infor_data')print field_list
project2=Mysql('etl1_58infor_data',field_list=field_list,field_num=26,conn_type='local')#以上部分 看不懂没关系 由于我有两套数据库环境,测试和生产#不同的数据库连接和网段,因此要传递不同的参数进行切换数据库和数据连接 如果一套环境 连接一次数据库即可 数据处理需要经常做测试 方便自己调用
data_tuple=project.select(db='local_db',id=0)#data_tuple 是我实例化自己写的操作数据库的类对数据库数据进行全字段进行读取,返回值是一个不可变的对象元组tuple,清洗需要保留旧表全部字段,同时增加3个清洗后的数据字段
data_tuple=project.select(db='local_db',id=0)#遍历元组 用字典去存储每个字段的值 插入到增加3个清洗字段的表 etl1_58infor_datafor data in data_tuple:
item={}#old_data不取最后一个字段 是因为那个字段我想用当前处理的时间
#这样可以计算数据总量运行的时间 来调整二次清洗的时间去和和kettle定时任务对接#元组转换为列表 转换的原因是因为元组为不可变类型 如果有数据中有null值 遍历转换为字符串会报错
old_data=list(data[:-1])if data[-2]:if len(data[-2]) >0 :
info=data[-2].encode('utf-8')else:
info=''if '.' in info and int(filter(str.isdigit,info.split('.')[1]))>0:
derive_regcapital=filter(str.isdigit,info.split('.')[0])+'.'+filter(str.isdigit,info.split('.')[1])elif '.' in info and int(filter(str.isdigit,info.split('.')[1]))==0:
derive_regcapital = filter(str.isdigit, info.split('.')[0])elif filter(str.isdigit,info)=='':
derive_regcapital='0'else:
derive_regcapital=filter(str.isdigit,info)if '万' in info:
derive_danwei='万'else:
derive_danwei='不含万'if '美元' in info:
derive_currency='美元'elif '港币' in info:
derive_currency = '港币'elif '阿富汗尼' in info:
derive_currency = '阿富汗尼'elif '澳元' in info:
derive_currency = '澳元'elif '英镑' in info:
derive_currency = '英镑'elif '加拿大元' in info:
derive_currency = '加拿大元'elif '日元' in info:
derive_currency = '日元'elif '港币' in info:
derive_currency = '港币'elif '法郎' in info:
derive_currency = '法郎'elif '欧元' in info:
derive_currency = '欧元'elif '新加坡' in info:
derive_currency = '新加坡元'else:
derive_currency = '人民币'
time_58infor_data = p2.create_time()
old_data.append(time_58infor_data)
old_data.append(derive_regcapital)
old_data.append(derive_danwei)
old_data.append(derive_currency)#print len(old_data)for i in range(len(old_data)):if not old_data[i] :
old_data[i]=''else:pass
data2=old_data[i].replace('"','')
item[i+1]=data2print item[1] #插入测试环境 的表
project2.insert(item=item,db='local_db')六、代码运行情况
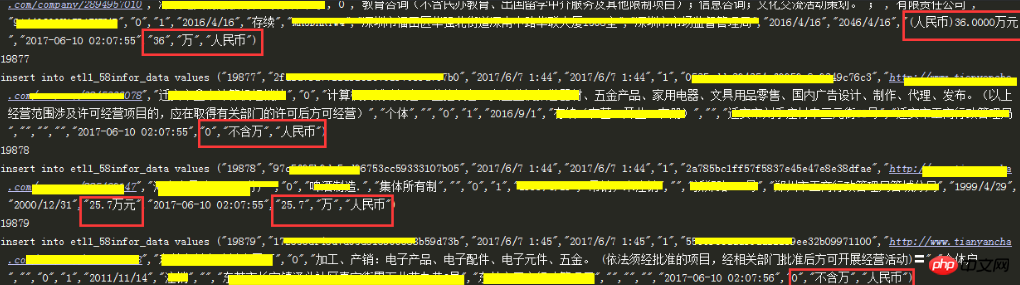
6.1读取数据库原表数据和新表创建的字段

6.2 插入新表 并进行第一次数据清洗
红框部分为清洗部分,其他数据做了脱敏处理
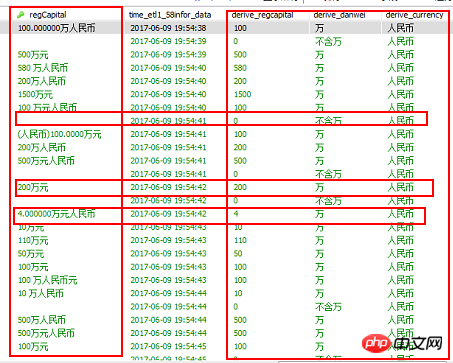
6.3 数据表数据清洗结果
七、增量数据处理
由于每天数据有增量进入,因此第一次执行完初始话之后,我们要根据表中的时间戳字段进行判断,读取昨日新的数据进行清洗插入,这部分留到下篇博客。
初步计划用下面函数 作为参数 判断增量 create_time 是爬虫脚本执行时候写入的时间,yesterday是昨日时间,在where条件里加以限制,取出昨天进入数据库的数据 进行执行 win7系统支持定时任务
import datetimefrom datetime import datetime as dt#%进行转义使用%%来转义#主要构造sql中条件“where create_time like %s%%“ % yesterday#写入脚本运行的当前时间
def create_time(self):
create_time = dt.now().strftime('%Y-%m-%d %H:%M:%S')return create_timedef yesterday(self):
yestoday= datetime.date.today()-datetime.timedelta(days=1)return yestoday以上是Python对杂乱文本数据进行处理实例的详细内容。更多信息请关注PHP中文网其他相关文章!