
如何抓取斗图网的最新表情图?

- PHP中文网原创
- 2017-06-20 14:29:442235浏览
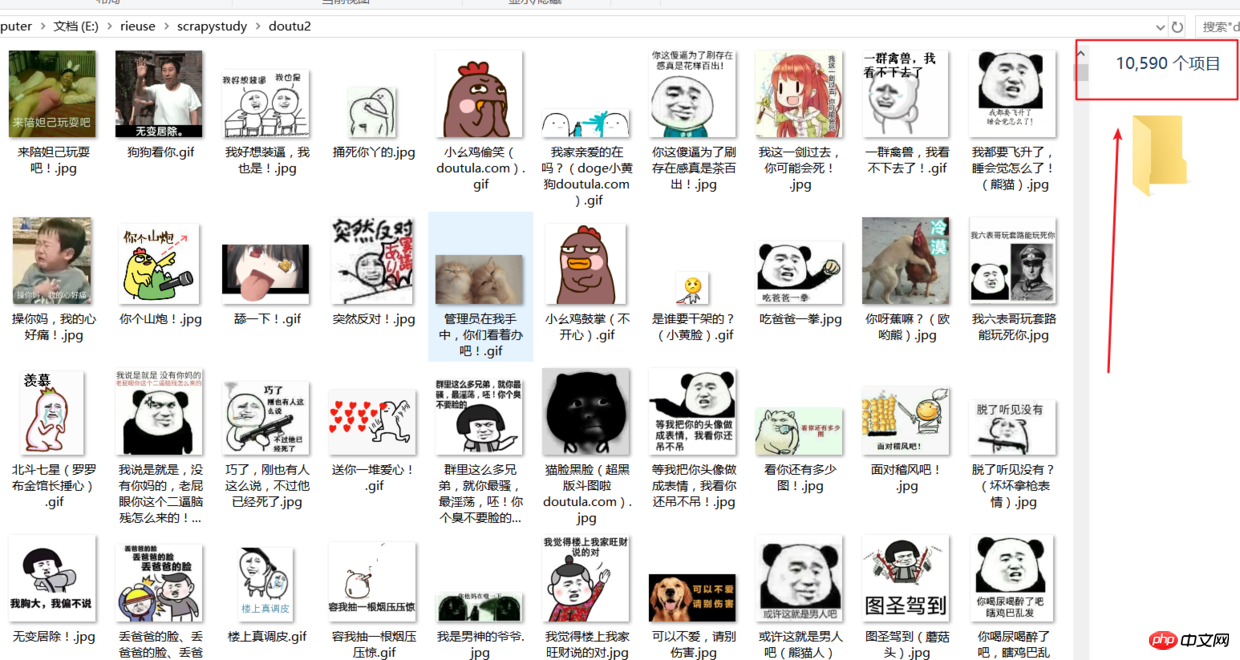
一:目标
第一次使用Scrapy框架遇到很多坑,坚持去搜索,修改代码就可以解决问题。这次爬取的是一个斗图网站的最新表情图片www.doutula.com/photo/list,练习使用Scrapy框架并且使用的随机user agent防止被ban,斗图表情包每日更新,一共可以抓取5万张左右的表情到硬盘中。为了节省时间我就抓取了1万多张。
二:Scrapy简介
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
使用过程
创建一个Scrapy项目
定义提取的Item
编写爬取网站的 spider 并提取 Item
编写 Item Pipeline 来存储提取到的Item(即数据)
接下来的图表展现了Scrapy的架构,包括组件及在系统中发生的数据流的概览(绿色箭头所示)。 下面对每个组件都做了简单介绍,并给出了详细内容的链接。数据流如下所描述
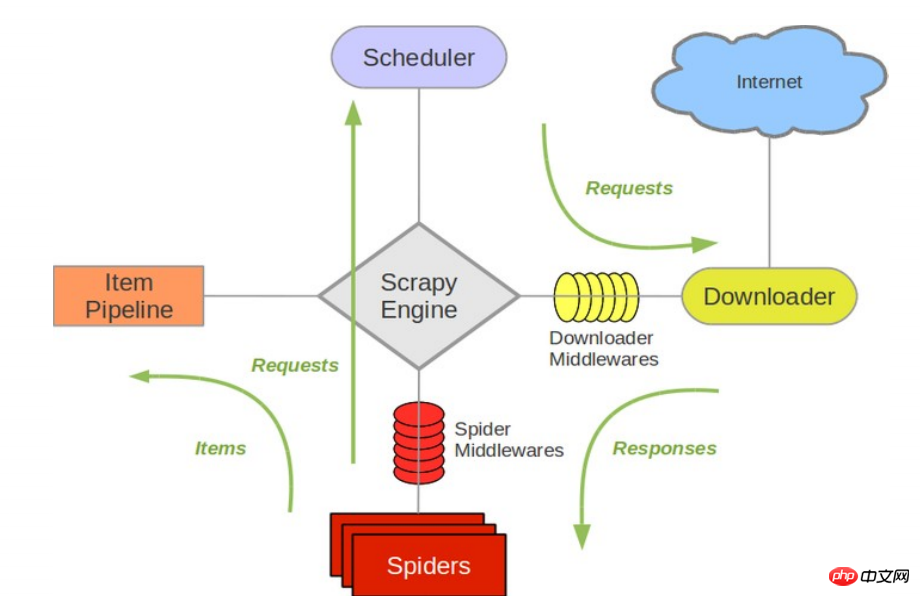
组件
Scrapy Engine
引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。 详细内容查看下面的数据流(Data Flow)部分。调度器(Scheduler)
调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎。下载器(Downloader)
下载器负责获取页面数据并提供给引擎,而后提供给spider。Spiders
Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。 更多内容请看 Spiders 。Item Pipeline
Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库中)。 更多内容查看 Item Pipeline 。下载器中间件(Downloader middlewares)
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。更多内容请看 下载器中间件(Downloader Middleware) 。Spider中间件(Spider middlewares)
Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。更多内容请看 Spider中间件(Middleware) 。
三:实例分析
1.从网站的主页进入最新斗图表情后网址是 ,点击第二页后看到网址变成了 ,那我们就知道了网址的构成最后的page就是不同的页数。那么spider中的start_urls开始入口就如下定义,爬取1到20页的图片表情。想下载更多表情页数你可以再增加。
start_urls = ['https://www.doutula.com/photo/list/?page={}'.format(i) for i in range(1, 20)]2.进入开发者模式分析网页结构,可以看到如下结构。右击复制一下xpath地址即可得到全部的表情所在的a标签内容。a[1]表示第一个a,去掉[1]就是全部的a。
//*[@id="pic-detail"]/div/div[1]/div[2]/a
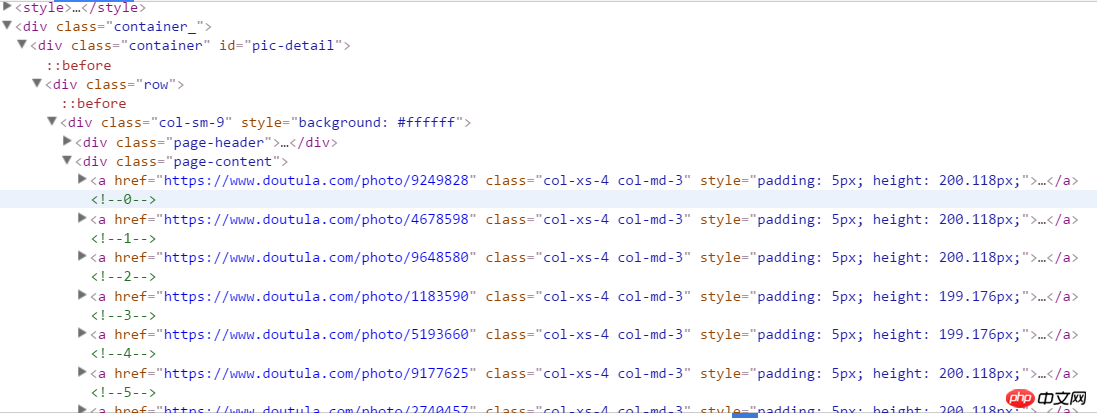
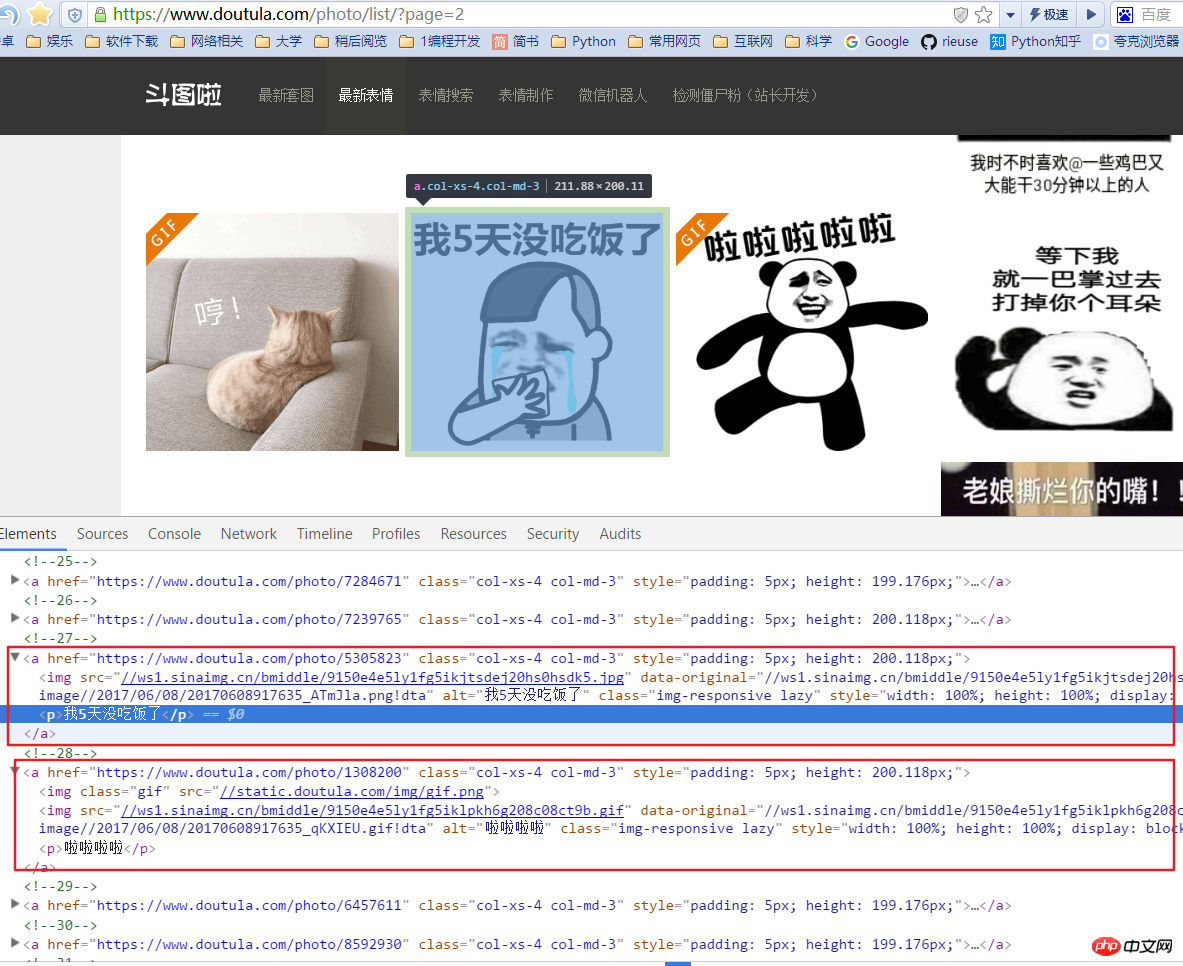
值得注意的是这里的表情有两种:一个jpg,一个gif动图。如果获取图片地址时只抓取a标签下面第一个img的src就会出错,所以我们要抓取img中的含有data-original的值。这里a标签下面还一个p标签是图片简介,我们也抓取下来作为图片文件的名称。
图片的连接是 'http:' + content.xpath('//img/@data-original') 图片的名称是 content.xpath('//p/text()')
四:实战代码
完整代码地址 github.com/rieuse/learnPython
1.首先使用命令行工具输入代码创建一个新的Scrapy项目,之后创建一个爬虫。
scrapy startproject ScrapyDoutu cd ScrapyDoutu\ScrapyDoutu\spidersscrapy genspider doutula doutula.com
2.打开Doutu文件夹中的items.py,改为以下代码,定义我们爬取的项目。
import scrapyclass DoutuItem(scrapy.Item):
img_url = scrapy.Field()
name = scrapy.Field()3.打开spiders文件夹中的doutula.py,改为以下代码,这个是爬虫主程序。
# -*- coding: utf-8 -*-
import os
import scrapy
import requestsfrom ScrapyDoutu.items import DoutuItems
class Doutu(scrapy.Spider):
name = "doutu"
allowed_domains = ["doutula.com", "sinaimg.cn"]
start_urls = ['https://www.doutula.com/photo/list/?page={}'.format(i) for i in range(1, 40)] # 我们暂且爬取40页图片
def parse(self, response):
i = 0for content in response.xpath('//*[@id="pic-detail"]/div/div[1]/div[2]/a'):
i += 1item = DoutuItems()item['img_url'] = 'http:' + content.xpath('//img/@data-original').extract()[i]item['name'] = content.xpath('//p/text()').extract()[i]try:if not os.path.exists('doutu'):
os.makedirs('doutu')
r = requests.get(item['img_url'])
filename = 'doutu\\{}'.format(item['name']) + item['img_url'][-4:]with open(filename, 'wb') as fo:
fo.write(r.content)
except:
print('Error')
yield item3.这里面有很多值得注意的部分:
因为图片的地址是放在sinaimg.cn中,所以要加入allowed_domains的列表中
content.xpath('//img/@data-original').extract()[i]中extract()用来返回一个list(就是系统自带的那个) 里面是一些你提取的内容,[i]是结合前面的i的循环每次获取下一个标签内容,如果不这样设置,就会把全部的标签内容放入一个字典的值中。filename = 'doutu\{}'.format(item['name']) + item['img_url'][-4:]是用来获取图片的名称,最后item['img_url'][-4:]是获取图片地址的最后四位这样就可以保证不同的文件格式使用各自的后缀。最后一点就是如果xpath没有正确匹配,则会出现64d8292994d119f5f1f87748047c90da (referer: None)
4.配置settings.py,如果想抓取快一点CONCURRENT_REQUESTS设置大一些,DOWNLOAD_DELAY设置小一些,或者为0.
# -*- coding: utf-8 -*-BOT_NAME = 'ScrapyDoutu'SPIDER_MODULES = ['ScrapyDoutu.spiders']NEWSPIDER_MODULE = 'ScrapyDoutu.spiders'DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
'ScrapyDoutu.middlewares.RotateUserAgentMiddleware': 400,
}ROBOTSTXT_OBEY = False # 不遵循网站的robots.txt策略CONCURRENT_REQUESTS = 16 #Scrapy downloader 并发请求(concurrent requests)的最大值DOWNLOAD_DELAY = 0.2 # 下载同一个网站页面前等待的时间,可以用来限制爬取速度减轻服务器压力。COOKIES_ENABLED = False # 关闭cookies5.配置middleware.py配合settings中的UA设置可以在下载中随机选择UA有一定的反ban效果,在原有代码基础上加入下面代码。这里的user_agent_list可以加入更多。
import randomfrom scrapy.downloadermiddlewares.useragent import UserAgentMiddlewareclass RotateUserAgentMiddleware(UserAgentMiddleware):
def __init__(self, user_agent=''):
self.user_agent = user_agent
def process_request(self, request, spider):
ua = random.choice(self.user_agent_list)
if ua:
print(ua)
request.headers.setdefault('User-Agent', ua)
user_agent_list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]6.到现在为止,代码都已经完成了。那么开始执行吧!scrapy crawl doutu
之后可以看到一边下载,一边修改User Agent。
五:总结
学习使用Scrapy遇到很多坑,但是强大的搜索系统不会让我感觉孤单。所以感觉Scrapy还是很强大的也很意思,后面继续学习Scrapy的其他方面内容。
以上是如何抓取斗图网的最新表情图?的详细内容。更多信息请关注PHP中文网其他相关文章!