



一:前言
本次爬取的是喜马拉雅的热门栏目下全部电台的每个频道的信息和频道中的每个音频数据的各种信息,然后把爬取的数据保存到mongodb以备后续使用。这次数据量在70万左右。音频数据包括音频下载地址,频道信息,简介等等,非常多。
昨天进行了人生中第一次面试,对方是一家人工智能大数据公司,我准备在这大二的暑假去实习,他们就要求有爬取过音频数据,所以我就来分析一下喜马拉雅的音频数据爬下来。目前我还在等待三面中,或者是通知最终面试消息。 (因为能得到一定肯定,不管成功与否都很开心)
二:运行环境
IDE:Pycharm 2017
Python3.6
pymongo 3.4.0
requests 2.14.2
lxml 3.7.2
BeautifulSoup 4.5.3
三:实例分析
1.首先进入这次爬取的主页面 ,可以看到每页12个频道,每个频道下面有很多的音频,有的频道中还有很多分页。抓取计划:循环84个页面,对每个页面解析后抓取每个频道的名称,图片链接,频道链接保存到mongodb。
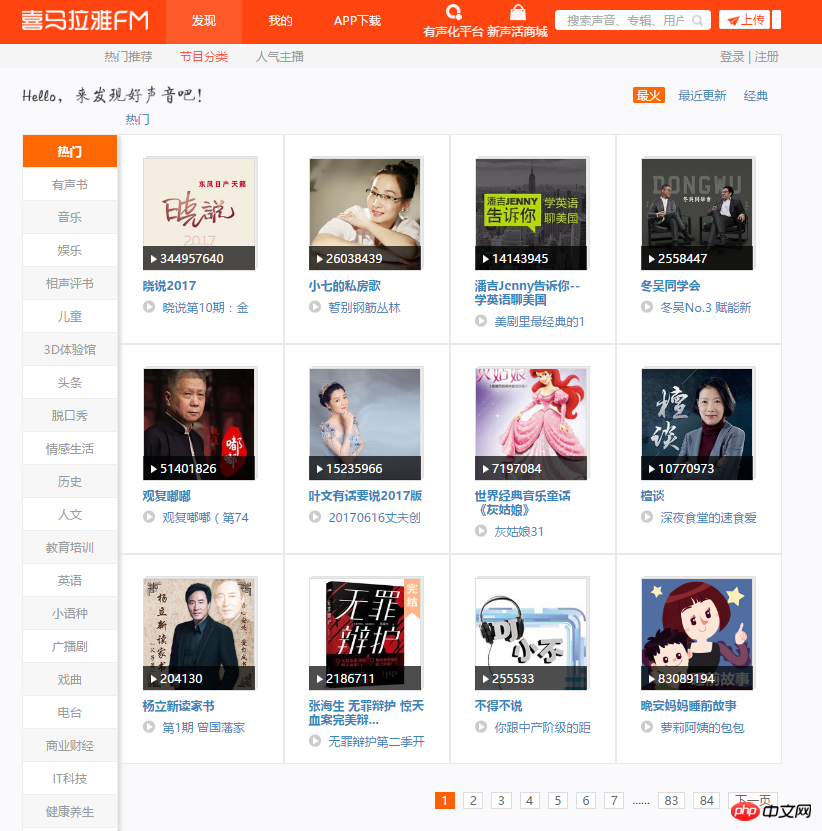
2.打开开发者模式,分析页面,很快就可以得到想要的数据的位置。下面的代码就实现了抓取全部热门频道的信息,就可以保存到mongodb中。
start_urls = ['http://www.ximalaya.com/dq/all/{}'.format(num) for num in range(1, 85)]for start_url in start_urls:html = requests.get(start_url, headers=headers1).text
soup = BeautifulSoup(html, 'lxml')for item in soup.find_all(class_="albumfaceOutter"):content = {'href': item.a['href'],'title': item.img['alt'],'img_url': item.img['src']
}
print(content)
3.下面就是开始获取每个频道中的全部音频数据了,前面通过解析页面获取到了美国频道的链接。比如我们进入 这个链接后分析页面结构。可以看出每个音频都有特定的ID,这个ID可以在一个div中的属性中获取。使用split()和int()来转换为单独的ID。
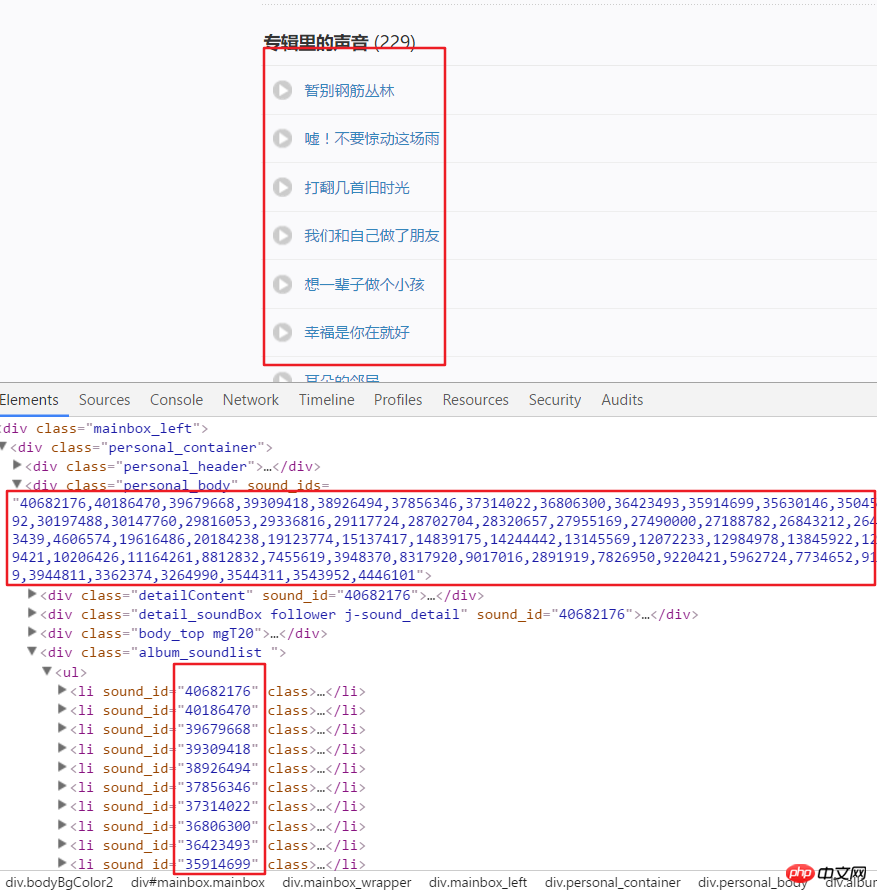
4.接着点击一个音频链接,进入开发者模式后刷新页面然后点击XHR,再点击一个json链接可以看到这个就包括这个音频的全部详细信息。
html = requests.get(url, headers=headers2).text
numlist = etree.HTML(html).xpath('//div[@class="personal_body"]/@sound_ids')[0].split(',')for i in numlist:
murl = 'http://www.ximalaya.com/tracks/{}.json'.format(i)html = requests.get(murl, headers=headers1).text
dic = json.loads(html)
5.上面只是对一个频道的主页面解析全部音频信息,但是实际上频道的音频链接是有很多分页的。
html = requests.get(url, headers=headers2).text
ifanother = etree.HTML(html).xpath('//div[@class="pagingBar_wrapper"]/a[last()-1]/@data-page')if len(ifanother):num = ifanother[0]
print('本频道资源存在' + num + '个页面')for n in range(1, int(num)):
print('开始解析{}个中的第{}个页面'.format(num, n))
url2 = url + '?page={}'.format(n)# 之后就接解析音频页函数就行,后面有完整代码说明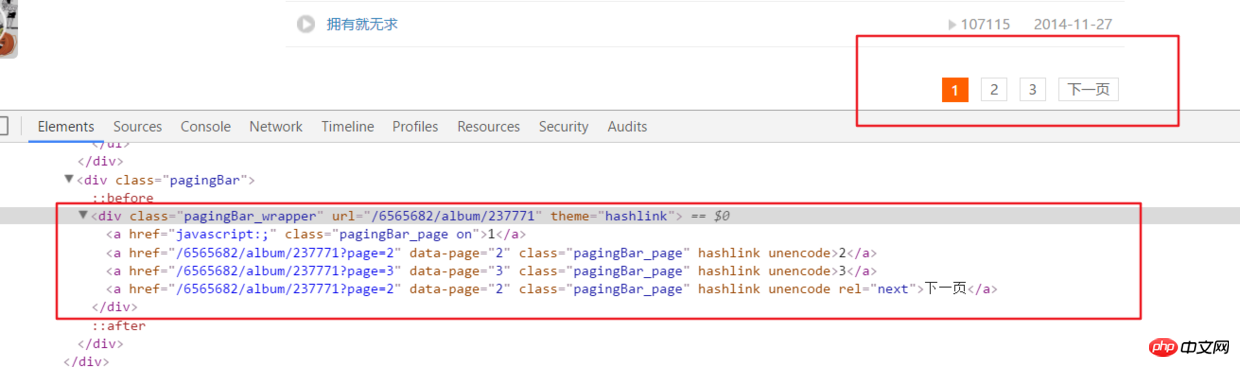
6.全部代码
完整代码地址github.com/rieuse/learnPython
__author__ = '布咯咯_rieuse'import jsonimport randomimport timeimport pymongoimport requestsfrom bs4 import BeautifulSoupfrom lxml import etree
clients = pymongo.MongoClient('localhost')
db = clients["XiMaLaYa"]
col1 = db["album"]
col2 = db["detaile"]
UA_LIST = [] # 很多User-Agent用来随机使用可以防ban,显示不方便不贴出来了
headers1 = {} # 访问网页的headers,这里显示不方便我就不贴出来了
headers2 = {} # 访问网页的headers这里显示不方便我就不贴出来了def get_url():
start_urls = ['http://www.ximalaya.com/dq/all/{}'.format(num) for num in range(1, 85)]for start_url in start_urls:
html = requests.get(start_url, headers=headers1).text
soup = BeautifulSoup(html, 'lxml')for item in soup.find_all(class_="albumfaceOutter"):
content = {'href': item.a['href'],'title': item.img['alt'],'img_url': item.img['src']
}
col1.insert(content)
print('写入一个频道' + item.a['href'])
print(content)
another(item.a['href'])
time.sleep(1)def another(url):
html = requests.get(url, headers=headers2).text
ifanother = etree.HTML(html).xpath('//div[@class="pagingBar_wrapper"]/a[last()-1]/@data-page')if len(ifanother):
num = ifanother[0]
print('本频道资源存在' + num + '个页面')for n in range(1, int(num)):
print('开始解析{}个中的第{}个页面'.format(num, n))
url2 = url + '?page={}'.format(n)
get_m4a(url2)
get_m4a(url)def get_m4a(url):
time.sleep(1)
html = requests.get(url, headers=headers2).text
numlist = etree.HTML(html).xpath('//div[@class="personal_body"]/@sound_ids')[0].split(',')for i in numlist:
murl = 'http://www.ximalaya.com/tracks/{}.json'.format(i)
html = requests.get(murl, headers=headers1).text
dic = json.loads(html)
col2.insert(dic)
print(murl + '中的数据已被成功插入mongodb')if __name__ == '__main__':
get_url()7.如果改成异步的形式可以快一点,只需要修改成下面这样就行了。我试了每分钟要比普通的多获取近100条数据。这个源代码也在github中。
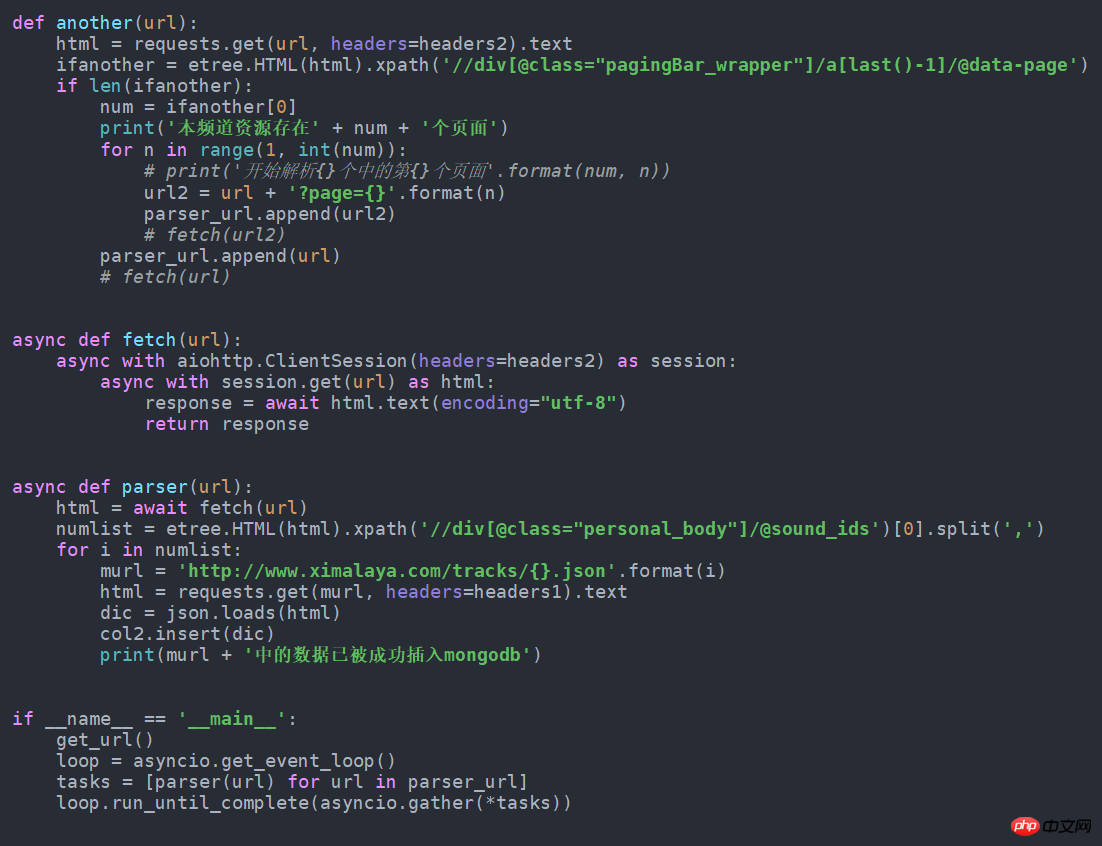
以上是Python爬虫之音频数据实例的详细内容。更多信息请关注PHP中文网其他相关文章!

 Python vs. C:了解关键差异Apr 21, 2025 am 12:18 AM
Python vs. C:了解关键差异Apr 21, 2025 am 12:18 AMPython和C 各有优势,选择应基于项目需求。1)Python适合快速开发和数据处理,因其简洁语法和动态类型。2)C 适用于高性能和系统编程,因其静态类型和手动内存管理。
 Python vs.C:您的项目选择哪种语言?Apr 21, 2025 am 12:17 AM
Python vs.C:您的项目选择哪种语言?Apr 21, 2025 am 12:17 AM选择Python还是C 取决于项目需求:1)如果需要快速开发、数据处理和原型设计,选择Python;2)如果需要高性能、低延迟和接近硬件的控制,选择C 。
 达到python目标:每天2小时的力量Apr 20, 2025 am 12:21 AM
达到python目标:每天2小时的力量Apr 20, 2025 am 12:21 AM通过每天投入2小时的Python学习,可以有效提升编程技能。1.学习新知识:阅读文档或观看教程。2.实践:编写代码和完成练习。3.复习:巩固所学内容。4.项目实践:应用所学于实际项目中。这样的结构化学习计划能帮助你系统掌握Python并实现职业目标。
 最大化2小时:有效的Python学习策略Apr 20, 2025 am 12:20 AM
最大化2小时:有效的Python学习策略Apr 20, 2025 am 12:20 AM在两小时内高效学习Python的方法包括:1.回顾基础知识,确保熟悉Python的安装和基本语法;2.理解Python的核心概念,如变量、列表、函数等;3.通过使用示例掌握基本和高级用法;4.学习常见错误与调试技巧;5.应用性能优化与最佳实践,如使用列表推导式和遵循PEP8风格指南。
 在Python和C之间进行选择:适合您的语言Apr 20, 2025 am 12:20 AM
在Python和C之间进行选择:适合您的语言Apr 20, 2025 am 12:20 AMPython适合初学者和数据科学,C 适用于系统编程和游戏开发。1.Python简洁易用,适用于数据科学和Web开发。2.C 提供高性能和控制力,适用于游戏开发和系统编程。选择应基于项目需求和个人兴趣。
 Python与C:编程语言的比较分析Apr 20, 2025 am 12:14 AM
Python与C:编程语言的比较分析Apr 20, 2025 am 12:14 AMPython更适合数据科学和快速开发,C 更适合高性能和系统编程。1.Python语法简洁,易于学习,适用于数据处理和科学计算。2.C 语法复杂,但性能优越,常用于游戏开发和系统编程。
 每天2小时:Python学习的潜力Apr 20, 2025 am 12:14 AM
每天2小时:Python学习的潜力Apr 20, 2025 am 12:14 AM每天投入两小时学习Python是可行的。1.学习新知识:用一小时学习新概念,如列表和字典。2.实践和练习:用一小时进行编程练习,如编写小程序。通过合理规划和坚持不懈,你可以在短时间内掌握Python的核心概念。
 Python与C:学习曲线和易用性Apr 19, 2025 am 12:20 AM
Python与C:学习曲线和易用性Apr 19, 2025 am 12:20 AMPython更易学且易用,C 则更强大但复杂。1.Python语法简洁,适合初学者,动态类型和自动内存管理使其易用,但可能导致运行时错误。2.C 提供低级控制和高级特性,适合高性能应用,但学习门槛高,需手动管理内存和类型安全。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

记事本++7.3.1
好用且免费的代码编辑器

PhpStorm Mac 版本
最新(2018.2.1 )专业的PHP集成开发工具

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

