


第一次学习Node.js爬虫,所以这时一个简单的爬虫,Node.js的好处就是可以并发的执行
这个爬虫主要就是获取慕课网的课程信息,并把获得的信息存储到一个文件中,其中要用到cheerio库,它可以让我们方便的操作HTML,就像是用jQ一样
开始前,记得
npm install cheerio
为了能够并发的进行爬取,用到了Promise对象
//接受一个url爬取整个网页,返回一个Promise对象function getPageAsync(url){return new Promise((resolve,reject)=>{
console.log(`正在爬取${url}的内容`);
http.get(url,function(res){
let html = '';
res.on('data',function(data){
html += data;
});
res.on('end',function(){
resolve(html);
});
res.on('error',function(err){
reject(err);
console.log('错误信息:' + err);
})
});
})
}
在慕课网中,每个课程都有一个ID,我们事先要把想要获取课程的ID写到一个数组中,而且每个课程的地址都是一个相同的地址加上ID,所以我们只要把地址和ID拼接起来就是课程的地址
const baseUrl = 'http://www.imooc.com/learn/'; const baseNuUrl = 'http://www.imooc.com/course/AjaxCourseMembers?ids=';//获取课程的IDconst videosId = [773,371];
为了使获取每个课程内容时并发执行,要使用Promise中的all方法
Promise//当所有网页的内容爬取完毕 .all(courseArray)
.then((pages)=>{//所有页面需要的内容let courseData = [];//遍历每个网页提取出所需要的内容pages.forEach((html)=>{
let courses = filterChapter(html);
courseData.push(courses);
});//给每个courseMenners.number赋值for(let i=0;i<videosId.length;i++){for(let j=0;j<videosId.length;j++){if(courseMembers[i].id +'' == videosId[j]){
courseData[j].number = courseMembers[i].numbers;
}
}
}//对所需要的内容进行排序courseData.sort((a,b)=>{return a.number > b.number;
});//在重新将爬取内容写入文件中前,清空文件fs.writeFileSync(outputFile,'###爬取慕课网课程信息###',(err)=>{if(err){
console.log(err)
}
});
printfData(courseData);
});
在then方法中,pages是每个课程的HTML页面,我们还得从中提取出我们需要的信息,需要使用下面的函数
//接受一个爬取下来的网页内容,查找网页中需要的信息function filterChapter(html){
const $ = cheerio.load(html);//所有章const chapters = $('.chapter');//课程的标题和学习人数let title = $('.hd>h2').text();
let number = 0;//最后返回的数据//每个网页需要的内容的结构let courseData = {'title':title,'number':number,'videos':[]
};
chapters.each(function(item){
let chapter = $(this);//文章标题let chapterTitle = Trim(chapter.find('strong').text(),'g');//每个章节的结构let chapterdata = {'chapterTitle':chapterTitle,'video':[]
};//一个网页中的所有视频let videos = chapter.find('.video').children('li');
videos.each(function(item){//视频标题let videoTitle = Trim($(this).find('a.J-media-item').text(),'g');//视频IDlet id = $(this).find('a').attr('href').split('video/')[1];
chapterdata.video.push({'title':videoTitle,'id':id
})
});
courseData.videos.push(chapterdata);
});return courseData;
}注意:在上面中将课程的学习人数设置为了0是因为学习课程人数是用Ajax动态获取,所以我在后面写了方法专门获取学习课程人数,其中用到的Trim()方法是去除文本中的空格
获取学习课程的人数:
//获取上课人数function getNumber(url){
let datas = '';
http.get(url,(res)=>{
res.on('data',(chunk)=>{
datas += chunk;
});
res.on('end',()=>{
datas = JSON.parse(datas);
courseMembers.push({'id':datas.data[0].id,'numbers':parseInt(datas.data[0].numbers,10)});
});
});
}这样就将想获取课程的学习人数都添加到了courseMembers数组中,在最后将学习课程的人数在赋值给相对应的课程
//给每个courseMenners.number赋值for(let i=0;i<videosId.length;i++){for(let j=0;j<videosId.length;j++){if(courseMembers[i].id +'' == videosId[j]){
courseData[j].number = courseMembers[i].numbers;
}
}
}
我们获取到了数据,就要把它按照一定的格式存到一个文件中
//写入文件function writeFile(file,string) {
fs.appendFileSync(file,string,(err)=>{if(err){
console.log(err);
}
})
}//打印信息function printfData(coursesData){
coursesData.forEach((courseData)=>{ // console.log(`${courseData.number}人学习过${courseData.title}\n`); writeFile(outputFile,`\n\n${courseData.number}人学习过${courseData.title}\n\n`);
courseData.videos.forEach(function(item){
let chapterTitle = item.chapterTitle;// console.log(chapterTitle + '\n'); writeFile(outputFile,`\n ${chapterTitle}\n`);
item.video.forEach(function(item){// console.log(' 【' + item.id + '】' + item.title + '\n'); writeFile(outputFile,` 【${item.id}】 ${item.title}\n`);
})
});
});
}
最后获取到的数据:
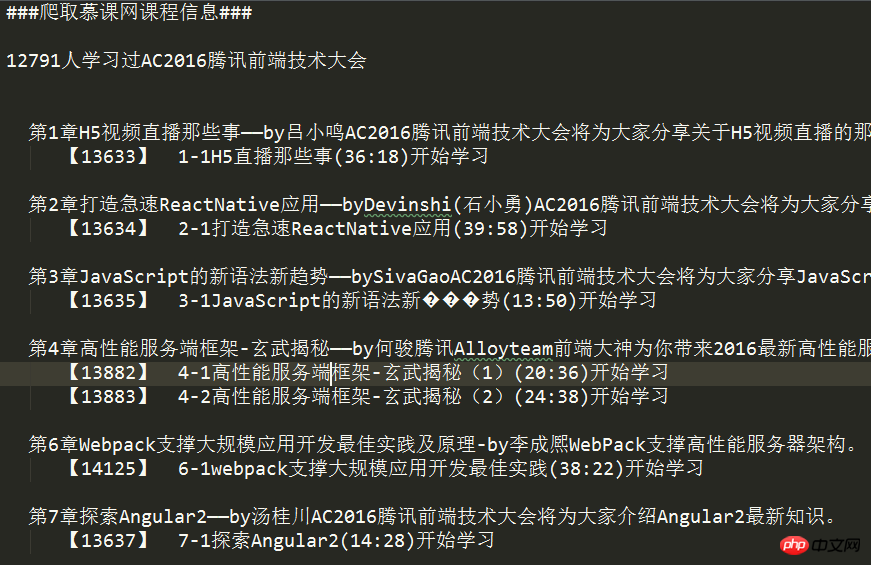
源码:
/**
* Created by hp-pc on 2017/6/7 0007. */const http = require('http');
const fs = require('fs');
const cheerio = require('cheerio');
const baseUrl = 'http://www.imooc.com/learn/';
const baseNuUrl = 'http://www.imooc.com/course/AjaxCourseMembers?ids=';//获取课程的IDconst videosId = [773,371];//输出的文件const outputFile = 'test.txt';//记录学习课程的人数let courseMembers = [];//去除字符串中的空格function Trim(str,is_global)
{
let result;
result = str.replace(/(^\s+)|(\s+$)/g,"");if(is_global.toLowerCase()=="g")
{
result = result.replace(/\s/g,"");
}return result;
}//接受一个url爬取整个网页,返回一个Promise对象function getPageAsync(url){return new Promise((resolve,reject)=>{
console.log(`正在爬取${url}的内容`);
http.get(url,function(res){
let html = '';
res.on('data',function(data){
html += data;
});
res.on('end',function(){
resolve(html);
});
res.on('error',function(err){
reject(err);
console.log('错误信息:' + err);
})
});
})
}//接受一个爬取下来的网页内容,查找网页中需要的信息function filterChapter(html){
const $ = cheerio.load(html);//所有章const chapters = $('.chapter');//课程的标题和学习人数let title = $('.hd>h2').text();
let number = 0;//最后返回的数据//每个网页需要的内容的结构let courseData = {'title':title,'number':number,'videos':[]
};
chapters.each(function(item){
let chapter = $(this);//文章标题let chapterTitle = Trim(chapter.find('strong').text(),'g');//每个章节的结构let chapterdata = {'chapterTitle':chapterTitle,'video':[]
};//一个网页中的所有视频let videos = chapter.find('.video').children('li');
videos.each(function(item){//视频标题let videoTitle = Trim($(this).find('a.J-media-item').text(),'g');//视频IDlet id = $(this).find('a').attr('href').split('video/')[1];
chapterdata.video.push({'title':videoTitle,'id':id
})
});
courseData.videos.push(chapterdata);
});return courseData;
}//获取上课人数function getNumber(url){
let datas = '';
http.get(url,(res)=>{
res.on('data',(chunk)=>{
datas += chunk;
});
res.on('end',()=>{
datas = JSON.parse(datas);
courseMembers.push({'id':datas.data[0].id,'numbers':parseInt(datas.data[0].numbers,10)});
});
});
}//写入文件function writeFile(file,string) {
fs.appendFileSync(file,string,(err)=>{if(err){
console.log(err);
}
})
}//打印信息function printfData(coursesData){
coursesData.forEach((courseData)=>{ // console.log(`${courseData.number}人学习过${courseData.title}\n`); writeFile(outputFile,`\n\n${courseData.number}人学习过${courseData.title}\n\n`);
courseData.videos.forEach(function(item){
let chapterTitle = item.chapterTitle;// console.log(chapterTitle + '\n'); writeFile(outputFile,`\n ${chapterTitle}\n`);
item.video.forEach(function(item){// console.log(' 【' + item.id + '】' + item.title + '\n'); writeFile(outputFile,` 【${item.id}】 ${item.title}\n`);
})
});
});
}//所有页面爬取完后返回的Promise数组let courseArray = [];//循环所有的videosId,和baseUrl进行字符串拼接,爬取网页内容videosId.forEach((id)=>{//将爬取网页完毕后返回的Promise对象加入数组courseArray.push(getPageAsync(baseUrl + id));//获取学习的人数getNumber(baseNuUrl + id);
});
Promise//当所有网页的内容爬取完毕 .all(courseArray)
.then((pages)=>{//所有页面需要的内容let courseData = [];//遍历每个网页提取出所需要的内容pages.forEach((html)=>{
let courses = filterChapter(html);
courseData.push(courses);
});//给每个courseMenners.number赋值for(let i=0;i<videosId.length;i++){for(let j=0;j<videosId.length;j++){if(courseMembers[i].id +'' == videosId[j]){
courseData[j].number = courseMembers[i].numbers;
}
}
}//对所需要的内容进行排序courseData.sort((a,b)=>{return a.number > b.number;
});//在重新将爬取内容写入文件中前,清空文件fs.writeFileSync(outputFile,'###爬取慕课网课程信息###',(err)=>{if(err){
console.log(err)
}
});
printfData(courseData);
});
以上是爬取慕课网课程信息实例教程的详细内容。更多信息请关注PHP中文网其他相关文章!

 JavaScript的角色:使网络交互和动态Apr 24, 2025 am 12:12 AM
JavaScript的角色:使网络交互和动态Apr 24, 2025 am 12:12 AMJavaScript是现代网站的核心,因为它增强了网页的交互性和动态性。1)它允许在不刷新页面的情况下改变内容,2)通过DOMAPI操作网页,3)支持复杂的交互效果如动画和拖放,4)优化性能和最佳实践提高用户体验。
 C和JavaScript:连接解释Apr 23, 2025 am 12:07 AM
C和JavaScript:连接解释Apr 23, 2025 am 12:07 AMC 和JavaScript通过WebAssembly实现互操作性。1)C 代码编译成WebAssembly模块,引入到JavaScript环境中,增强计算能力。2)在游戏开发中,C 处理物理引擎和图形渲染,JavaScript负责游戏逻辑和用户界面。
 从网站到应用程序:JavaScript的不同应用Apr 22, 2025 am 12:02 AM
从网站到应用程序:JavaScript的不同应用Apr 22, 2025 am 12:02 AMJavaScript在网站、移动应用、桌面应用和服务器端编程中均有广泛应用。1)在网站开发中,JavaScript与HTML、CSS一起操作DOM,实现动态效果,并支持如jQuery、React等框架。2)通过ReactNative和Ionic,JavaScript用于开发跨平台移动应用。3)Electron框架使JavaScript能构建桌面应用。4)Node.js让JavaScript在服务器端运行,支持高并发请求。
 Python vs. JavaScript:比较用例和应用程序Apr 21, 2025 am 12:01 AM
Python vs. JavaScript:比较用例和应用程序Apr 21, 2025 am 12:01 AMPython更适合数据科学和自动化,JavaScript更适合前端和全栈开发。1.Python在数据科学和机器学习中表现出色,使用NumPy、Pandas等库进行数据处理和建模。2.Python在自动化和脚本编写方面简洁高效。3.JavaScript在前端开发中不可或缺,用于构建动态网页和单页面应用。4.JavaScript通过Node.js在后端开发中发挥作用,支持全栈开发。
 C/C在JavaScript口译员和编译器中的作用Apr 20, 2025 am 12:01 AM
C/C在JavaScript口译员和编译器中的作用Apr 20, 2025 am 12:01 AMC和C 在JavaScript引擎中扮演了至关重要的角色,主要用于实现解释器和JIT编译器。 1)C 用于解析JavaScript源码并生成抽象语法树。 2)C 负责生成和执行字节码。 3)C 实现JIT编译器,在运行时优化和编译热点代码,显着提高JavaScript的执行效率。
 JavaScript在行动中:现实世界中的示例和项目Apr 19, 2025 am 12:13 AM
JavaScript在行动中:现实世界中的示例和项目Apr 19, 2025 am 12:13 AMJavaScript在现实世界中的应用包括前端和后端开发。1)通过构建TODO列表应用展示前端应用,涉及DOM操作和事件处理。2)通过Node.js和Express构建RESTfulAPI展示后端应用。
 JavaScript和Web:核心功能和用例Apr 18, 2025 am 12:19 AM
JavaScript和Web:核心功能和用例Apr 18, 2025 am 12:19 AMJavaScript在Web开发中的主要用途包括客户端交互、表单验证和异步通信。1)通过DOM操作实现动态内容更新和用户交互;2)在用户提交数据前进行客户端验证,提高用户体验;3)通过AJAX技术实现与服务器的无刷新通信。
 了解JavaScript引擎:实施详细信息Apr 17, 2025 am 12:05 AM
了解JavaScript引擎:实施详细信息Apr 17, 2025 am 12:05 AM理解JavaScript引擎内部工作原理对开发者重要,因为它能帮助编写更高效的代码并理解性能瓶颈和优化策略。1)引擎的工作流程包括解析、编译和执行三个阶段;2)执行过程中,引擎会进行动态优化,如内联缓存和隐藏类;3)最佳实践包括避免全局变量、优化循环、使用const和let,以及避免过度使用闭包。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

Atom编辑器mac版下载
最流行的的开源编辑器

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

SublimeText3汉化版
中文版,非常好用

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

