
详解PHP中的那些哈希表
- 巴扎黑原创
- 2017-05-27 10:38:084180浏览
在PHP内核中,其中一个很重要的数据结构就是HashTable。我们常用的数组,在内核中就是用HashTable来实现。那么,PHP的HashTable是怎么实现的呢?最近在看HashTable的数据结构,但是算法书籍里面没有具体的实现算法,刚好最近也在阅读PHP的源码,于是参考PHP的HashTable的实现,自己实现了一个简易版的HashTable,总结了一些心得,下面给大家分享一下。
笔者github上有一个简易版的HashTable的实现:HashTable实现
另外,我在github有对PHP源码更详细的注解。感兴趣的可以围观一下,给个star。PHP5.4源码注解。可以通过commit记录查看已添加的注解。
HashTable的介绍
哈希表是实现字典操作的一种有效数据结构。
定义
简单地说,HashTable(哈希表)就是一种键值对的数据结构。支持插入,查找,删除等操作。在一些合理的假设下,在哈希表中的所有操作的时间复杂度是O(1)(对相关证明感兴趣的可以自行查阅)。
实现哈希表的关键
在哈希表中,不是使用关键字做下标,而是通过哈希函数计算出key的哈希值作为下标,然后查找/删除时再计算出key的哈希值,从而快速定位元素保存的位置。
在一个哈希表中,不同的关键字可能会计算得到相同的哈希值,这叫做“哈希冲突”,就是处理两个或多个键的哈希值相同的情况。解决哈希冲突的方法有很多,开放寻址法,拉链法等等。
因此,实现一个好的哈希表的关键就是一个好的哈希函数和处理哈希冲突的方法。
Hash函数
判断一个哈希算法的好坏有以下四个定义: > * 一致性,等价的键必然产生相等的哈希值; > * 高效性,计算简便; > * 均匀性,均匀地对所有的键进行哈希。
哈希函数建立了关键值与哈希值的对应关系,即:h = hash_func(key)。对应关系见下图:

设计一个完美的哈希函数就交由专家去做吧,我们只管用已有的较成熟的哈希函数就好了。PHP内核使用的哈希函数是time33函数,又叫DJBX33A,其实现如下:
static inline ulong zend_inline_hash_func(const char *arKey, uint nKeyLength)
{
register ulong hash = 5381;
/* variant with the hash unrolled eight times */
for (; nKeyLength >= 8; nKeyLength -= 8) {
hash = ((hash << 5) + hash) + *arKey++;
hash = ((hash << 5) + hash) + *arKey++;
hash = ((hash << 5) + hash) + *arKey++;
hash = ((hash << 5) + hash) + *arKey++;
hash = ((hash << 5) + hash) + *arKey++;
hash = ((hash << 5) + hash) + *arKey++;
hash = ((hash << 5) + hash) + *arKey++;
hash = ((hash << 5) + hash) + *arKey++;
}
switch (nKeyLength) {
case 7: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */
case 6: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */
case 5: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */
case 4: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */
case 3: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */
case 2: hash = ((hash << 5) + hash) + *arKey++; /* fallthrough... */
case 1: hash = ((hash << 5) + hash) + *arKey++; break;
case 0: break;
EMPTY_SWITCH_DEFAULT_CASE()
}
return hash;
}
注:函数使用了一个8次循环+switch来实现,是对for循环的优化,减少循环的运行次数,然后在switch里面执行剩下的没有遍历到的元素。
拉链法
将所有具有相同哈希值的元素都保存在一条链表中的方法叫拉链法。查找的时候通过先计算key对应的哈希值,然后根据哈希值找到对应的链表,最后沿着链表顺序查找相应的值。 具体保存后的结构图如下:
PHP的HashTable结构
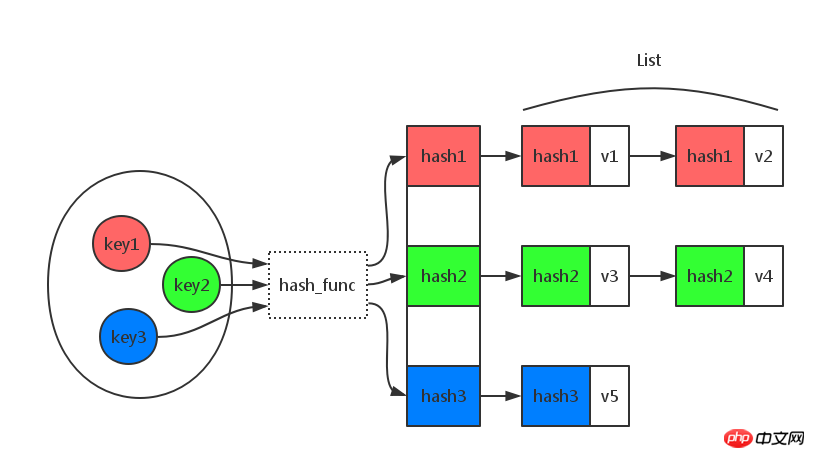
简单地介绍了哈希表的数据结构之后,继续看看PHP中是如何实现哈希表的。
(图片源自网络,侵权即删)
PHP内核hashtable的定义:
typedef struct _hashtable {
uint nTableSize;
uint nTableMask;
uint nNumOfElements;
ulong nNextFreeElement;
Bucket *pInternalPointer;
Bucket *pListHead;
Bucket *pListTail;
Bucket **arBuckets;
dtor_func_t pDestructor;
zend_bool persistent;
unsigned char nApplyCount;
zend_bool bApplyProtection;
#if ZEND_DEBUG
int inconsistent;
#endif
} HashTable;nTableSize,HashTable的大小,以2的倍数增长
nTableMask,用在与哈希值做与运算获得该哈希值的索引取值,arBuckets初始化后永远是nTableSize-1
nNumOfElements,HashTable当前拥有的元素个数,count函数直接返回这个值
nNextFreeElement,表示数字键值数组中下一个数字索引的位置
pInternalPointer,内部指针,指向当前成员,用于遍历元素
pListHead,指向HashTable的第一个元素,也是数组的第一个元素
pListTail,指向HashTable的最后一个元素,也是数组的最后一个元素。与上面的指针结合,在遍历数组时非常方便,比如reset和endAPI
arBuckets,包含bucket组成的双向链表的数组,索引用key的哈希值和nTableMask做与运算生成
pDestructor,删除哈希表中的元素使用的析构函数
persistent,标识内存分配函数,如果是TRUE,则使用操作系统本身的内存分配函数,否则使用PHP的内存分配函数
nApplyCount,保存当前bucket被递归访问的次数,防止多次递归
bApplyProtection,标识哈希表是否要使用递归保护,默认是1,要使用
举一个哈希与mask结合的例子:
例如,”foo”真正的哈希值(使用DJBX33A哈希函数)是193491849。如果我们现在有64容量的哈希表,我们明显不能使用它作为数组的下标。取而代之的是通过应用哈希表的mask,然后只取哈希表的低位。
hash | 193491849 | 0b1011100010000111001110001001 & mask | & 63 | & 0b0000000000000000000000111111 ---------------------------------------------------------------------- = index | = 9 | = 0b0000000000000000000000001001
因此,在哈希表中,foo是保存在arBuckets中下标为9的bucket向量中。
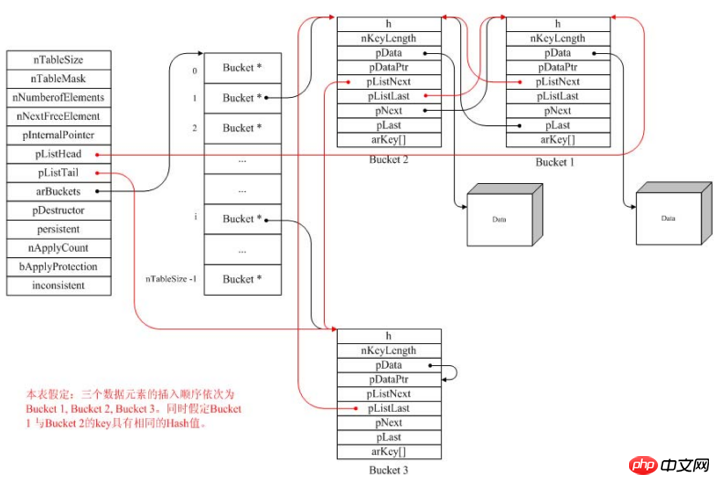
bucket结构体的定义
typedef struct bucket {
ulong h;
uint nKeyLength;
void *pData;
void *pDataPtr;
struct bucket *pListNext;
struct bucket *pListLast;
struct bucket *pNext;
struct bucket *pLast;
const char *arKey;
} Bucket;h,哈希值(或数字键值的key
nKeyLength,key的长度
pData,指向数据的指针
pDataPtr,指针数据
pListNext,指向HashTable中的arBuckets链表中的下一个元素
pListLast,指向HashTable中的arBuckets链表中的上一个元素
pNext,指向具有相同hash值的bucket链表中的下一个元素
pLast,指向具有相同hash值的bucket链表中的上一个元素
arKey,key的名称
PHP中的HashTable是采用了向量加双向链表的实现方式,向量在arBuckets变量保存,向量包含多个bucket的指针,每个指针指向由多个bucket组成的双向链表,新元素的加入使用前插法,即新元素总是在bucket的第一个位置。由上面可以看到,PHP的哈希表实现相当复杂。这是它使用超灵活的数组类型要付出的代价。
一个PHP中的HashTable的示例图如下所示:
HashTable相关API
zend_hash_init
zend_hash_add_or_update
zend_hash_find
zend_hash_del_key_or_index
zend_hash_init
函数执行步骤
设置哈希表大小
设置结构体其他成员变量的初始值 (包括释放内存用的析构函数pDescructor)
详细代码注解点击:zend_hash_init源码
注:
1、pHashFunction在此处并没有用到,php的哈希函数使用的是内部的zend_inline_hash_func
2、zend_hash_init执行之后并没有真正地为arBuckets分配内存和计算出nTableMask的大小,真正分配内存和计算nTableMask是在插入元素时进行CHECK_INIT检查初始化时进行。
zend_hash_add_or_update
函数执行步骤
检查键的长度
检查初始化
计算哈希值和下标
遍历哈希值所在的bucket,如果找到相同的key且值需要更新,则更新数据,否则继续指向bucket的下一个元素,直到指向bucket的最后一个位置
为新加入的元素分配bucket,设置新的bucket的属性值,然后添加到哈希表中
如果哈希表空间满了,则重新调整哈希表的大小
函数执行流程图
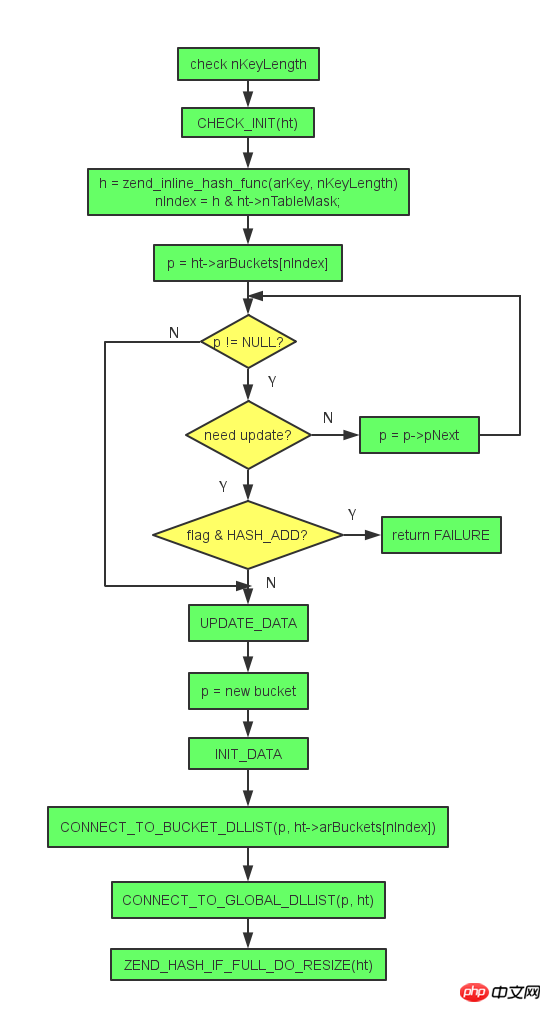
CONNECT_TO_BUCKET_DLLIST是将新元素添加到具有相同hash值的bucket链表。
CONNECT_TO_GLOBAL_DLLIST是将新元素添加到HashTable的双向链表。
详细代码和注解请点击:zend_hash_add_or_update代码注解。
zend_hash_find
函数执行步骤
计算哈希值和下标
遍历哈希值所在的bucket,如果找到key所在的bucket,则返回值,否则,指向下一个bucket,直到指向bucket链表中的最后一个位置
详细代码和注解请点击:zend_hash_find代码注解。
zend_hash_del_key_or_index
函数执行步骤
计算key的哈希值和下标
遍历哈希值所在的bucket,如果找到key所在的bucket,则进行第三步,否则,指向下一个bucket,直到指向bucket链表中的最后一个位置
如果要删除的是第一个元素,直接将arBucket[nIndex]指向第二个元素;其余的操作是将当前指针的last的next执行当前的next
调整相关指针
释放数据内存和bucket结构体内存
详细代码和注解请点击:zend_hash_del_key_or_index代码注解。
性能分析
PHP的哈希表的优点:PHP的HashTable为数组的操作提供了很大的方便,无论是数组的创建和新增元素或删除元素等操作,哈希表都提供了很好的性能,但其不足在数据量大的时候比较明显,从时间复杂度和空间复杂度看看其不足。
不足如下:
保存数据的结构体zval需要单独分配内存,需要管理这个额外的内存,每个zval占用了16bytes的内存;
在新增bucket时,bucket也是额外分配,也需要16bytes的内存;
为了能进行顺序遍历,使用双向链表连接整个HashTable,多出了很多的指针,每个指针也要16bytes的内存;
在遍历时,如果元素位于bucket链表的尾部,也需要遍历完整个bucket链表才能找到所要查找的值
PHP的HashTable的不足主要是其双向链表多出的指针及zval和bucket需要额外分配内存,因此导致占用了很多内存空间及查找时多出了不少时间的消耗。
后续
上面提到的不足,在PHP7中都很好地解决了,PHP7对内核中的数据结构做了一个大改造,使得PHP的效率高了很多,因此,推荐PHP开发者都将开发和部署版本更新吧。看看下面这段PHP代码:
<?php
$size = pow(2, 16);
$startTime = microtime(true);
$array = array();
for ($key = 0, $maxKey = ($size - 1) * $size; $key <= $maxKey; $key += $size) {
$array[$key] = 0;
}
$endTime = microtime(true);
echo '插入 ', $size, ' 个恶意的元素需要 ', $endTime - $startTime, ' 秒', "\n";
$startTime = microtime(true);
$array = array();
for ($key = 0, $maxKey = $size - 1; $key <= $maxKey; ++$key) {
$array[$key] = 0;
}
$endTime = microtime(true);
echo '插入 ', $size, ' 个普通元素需要 ', $endTime - $startTime, ' 秒', "\n";上面这个demo是有多个hash冲突时和无冲突时的时间消耗比较。笔者在PHP5.4下运行这段代码,结果如下
插入 65536 个恶意的元素需要 43.72204709053 秒
插入 65536 个普通元素需要 0.009843111038208 秒
而在PHP7上运行的结果:
插入 65536 个恶意的元素需要 4.4028408527374 秒
插入 65536 个普通元素需要 0.0018510818481445 秒
可见不论在有冲突和无冲突的数组操作,PHP7的性能都提升了不少,当然,有冲突的性能提升更为明显。至于为什么PHP7的性能提高了这么多,值得继续深究。
最后,笔者github上有一个简易版的HashTable的实现:HashTable实现
另外,我在github有对PHP源码更详细的注解。感兴趣的可以围观一下,给个star。PHP5.4源码注解。可以通过commit记录查看已添加的注解。
以上是详解PHP中的那些哈希表的详细内容。更多信息请关注PHP中文网其他相关文章!