


这篇文章主要介绍了python数据清洗之字符串处理的相关资料,需要的朋友可以参考下
前言
数据清洗是一项复杂且繁琐(kubi)的工作,同时也是整个数据分析过程中最为重要的环节。有人说一个分析项目80%的时间都是在清洗数据,这听起来有些匪夷所思,但在实际的工作中确实如此。数据清洗的目的有两个,第一是通过清洗让数据可用。第二是让数据变的更适合进行后续的分析工作。换句话说就是有”脏”数据要洗,干净的数据也要洗。
在数据分析中,特别是文本分析中,字符处理需要耗费极大的精力,因而了解字符处理对于数据分析而言,也是一项很重要的能力。
字符串处理方法
首先我们先了解下都有哪些基础方法
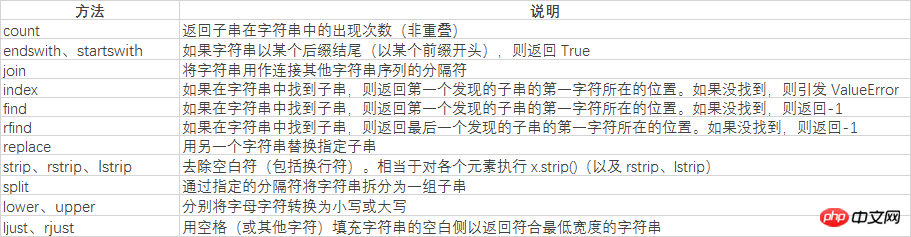
首先我们了解下字符串的拆分split方法
str='i like apple,i like bananer' print(str.split(','))
对字符str用逗号进行拆分的结果:
['i like apple', 'i like bananer']
print(str.split(' '))
根据空格拆分的结果:
['i', 'like', 'apple,i', 'like', 'bananer']
print(str.index(',')) print(str.find(','))
两个查找结果都为:
12
找不到的情况下index返回错误,find返回-1
print(str.count('i'))
结果为:
4
connt用于统计目标字符串的频率
print(str.replace(',', ' ').split(' '))
结果为:
['i', 'like', 'apple', 'i', 'like', 'bananer']
这里replace把逗号替换为空格后,在用空格对字符串进行分割,刚好能把每个单词取出来。
除了常规的方法以外,更强大的字符处理工具费正则表达式莫属了。
正则表达式
在使用正则表达式前我们还要先了解下,正则表达式中的诸多方法。

下面我来看下个方法的使用,首先了解下match和search方法的区别
str = "Cats are smarter than dogs" pattern=re.compile(r'(.*) are (.*?) .*') result=re.match(pattern,str) for i in range(len(result.groups())+1): print(result.group(i))
结果为:
Cats are smarter than dogs
Cats
smarter
这种形式的pettern匹配规则下,match和search方法的的返回结果是一样的
此时如果把pattern改为
pattern=re.compile(r'are (.*?) .*')
match则返回none,search返回结果为:
are smarter than dogs
smarter
接下来我们了解下其他方法的使用
str = "138-9592-5592 # number" pattern=re.compile(r'#.*$') number=re.sub(pattern,'',str) print(number)
结果为:
138-9592-5592
以上是通过把#号后面的内容替换为空实现提取号码的目的。
我们还可以进一步对号码的横杆进行替换
print(re.sub(r'-*','',number))
结果为:
13895925592
我们还可以用find的方法把找到的字符串打印出来
str = "138-9592-5592 # number" pattern=re.compile(r'5') print(pattern.findall(str))
结果为:
['5', '5', '5']
正则表达式的整体内容比较多,需要我们对匹配的字符串的规则有足够的了解,下面是具体的匹配规则。

矢量化字符串函数
清理待分析的散乱数据时,常常需要做一些字符串规整化工作。
data = pd.Series({'li': '120@qq.com','wang':'5632@qq.com',
'chen': '8622@xinlang.com','zhao':np.nan,'sun':'5243@gmail.com'})
print(data)结果为:

可以通过规整合的一些方法对数据做初步的判断,比如用contains 判断每个数据中是否含有关键词
print(data.str.contains('@'))
结果为:

也可以对字符串进行分拆,把需要的字符串提取出来
data = pd.Series({'li': '120@qq.com','wang':'5632@qq.com',
'chen': '8622@xinlang.com','zhao':np.nan,'sun':'5243@gmail.com'})
pattern=re.compile(r'(\d*)@([a-z]+)\.([a-z]{2,4})')
result=data.str.match(pattern) #这里用fillall的方法也可以result=data.str.findall(pattern)
print(result)结果为:
chen [(8622, xinlang, com)]
li [(120, qq, com)]
sun [(5243, gmail, com)]
wang [(5632, qq, com)]
zhao NaN
dtype: object
此时加入我们需要提取邮箱前面的名称
print(result.str.get(0))
结果为:

或者需要邮箱所属的域名
print(result.str.get(1))
结果为:

当然也可以用切片的方式进行提取,不过提取的数据准确性不高
data = pd.Series({'li': '120@qq.com','wang':'5632@qq.com',
'chen': '8622@xinlang.com','zhao':np.nan,'sun':'5243@gmail.com'})
print(data.str[:6])结果为:

最后我们了解下矢量化的字符串方法

总结
【相关推荐】
1. Python免费视频教程
3. Python基础入门教程
以上是python清洗字符串的实例详解的详细内容。更多信息请关注PHP中文网其他相关文章!

 Python:自动化,脚本和任务管理Apr 16, 2025 am 12:14 AM
Python:自动化,脚本和任务管理Apr 16, 2025 am 12:14 AMPython在自动化、脚本编写和任务管理中表现出色。1)自动化:通过标准库如os、shutil实现文件备份。2)脚本编写:使用psutil库监控系统资源。3)任务管理:利用schedule库调度任务。Python的易用性和丰富库支持使其在这些领域中成为首选工具。
 Python和时间:充分利用您的学习时间Apr 14, 2025 am 12:02 AM
Python和时间:充分利用您的学习时间Apr 14, 2025 am 12:02 AM要在有限的时间内最大化学习Python的效率,可以使用Python的datetime、time和schedule模块。1.datetime模块用于记录和规划学习时间。2.time模块帮助设置学习和休息时间。3.schedule模块自动化安排每周学习任务。
 Python:游戏,Guis等Apr 13, 2025 am 12:14 AM
Python:游戏,Guis等Apr 13, 2025 am 12:14 AMPython在游戏和GUI开发中表现出色。1)游戏开发使用Pygame,提供绘图、音频等功能,适合创建2D游戏。2)GUI开发可选择Tkinter或PyQt,Tkinter简单易用,PyQt功能丰富,适合专业开发。
 Python vs.C:申请和用例Apr 12, 2025 am 12:01 AM
Python vs.C:申请和用例Apr 12, 2025 am 12:01 AMPython适合数据科学、Web开发和自动化任务,而C 适用于系统编程、游戏开发和嵌入式系统。 Python以简洁和强大的生态系统着称,C 则以高性能和底层控制能力闻名。
 2小时的Python计划:一种现实的方法Apr 11, 2025 am 12:04 AM
2小时的Python计划:一种现实的方法Apr 11, 2025 am 12:04 AM2小时内可以学会Python的基本编程概念和技能。1.学习变量和数据类型,2.掌握控制流(条件语句和循环),3.理解函数的定义和使用,4.通过简单示例和代码片段快速上手Python编程。
 Python:探索其主要应用程序Apr 10, 2025 am 09:41 AM
Python:探索其主要应用程序Apr 10, 2025 am 09:41 AMPython在web开发、数据科学、机器学习、自动化和脚本编写等领域有广泛应用。1)在web开发中,Django和Flask框架简化了开发过程。2)数据科学和机器学习领域,NumPy、Pandas、Scikit-learn和TensorFlow库提供了强大支持。3)自动化和脚本编写方面,Python适用于自动化测试和系统管理等任务。
 您可以在2小时内学到多少python?Apr 09, 2025 pm 04:33 PM
您可以在2小时内学到多少python?Apr 09, 2025 pm 04:33 PM两小时内可以学到Python的基础知识。1.学习变量和数据类型,2.掌握控制结构如if语句和循环,3.了解函数的定义和使用。这些将帮助你开始编写简单的Python程序。
 如何在10小时内通过项目和问题驱动的方式教计算机小白编程基础?Apr 02, 2025 am 07:18 AM
如何在10小时内通过项目和问题驱动的方式教计算机小白编程基础?Apr 02, 2025 am 07:18 AM如何在10小时内教计算机小白编程基础?如果你只有10个小时来教计算机小白一些编程知识,你会选择教些什么�...


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

Atom编辑器mac版下载
最流行的的开源编辑器

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

PhpStorm Mac 版本
最新(2018.2.1 )专业的PHP集成开发工具

WebStorm Mac版
好用的JavaScript开发工具

