


本文主要介绍了Python爬虫:通过关键字爬取百度图片的方法。具有很好的参考价值,下面跟着小编一起来看下吧
使用工具:Python2.7 点我下载
scrapy框架
sublime text3
一。搭建python(Windows版本)
1.安装python2.7 ---然后在cmd当中输入python,界面如下则安装成功

2.集成Scrapy框架----输入命令行:pip install Scrapy

安装成功界面如下:
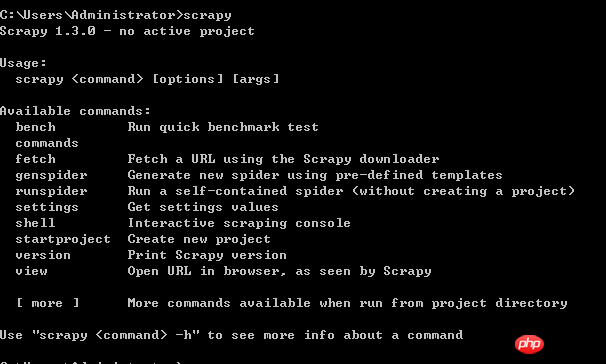
失败的情况很多,举例一种:
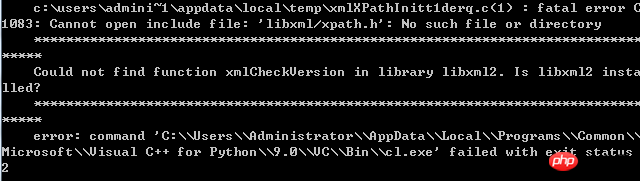
解决方案:
其余错误可百度搜索。
二。开始编程。
1.爬取无反爬虫措施的静态网站。例如百度贴吧,豆瓣读书。
例如-《桌面吧》的一个帖子tieba.baidu.com/p/2460150866?red_tag=3569129009
python代码如下:
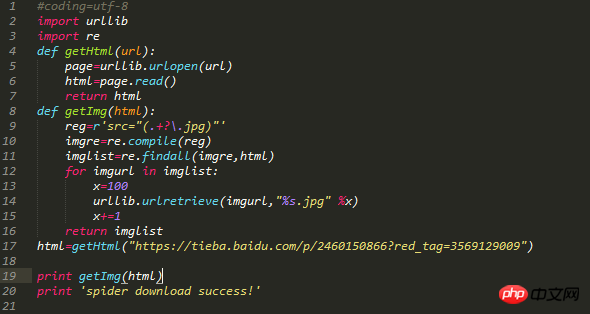
代码注释:引入了两个模块urllib,re。定义两个函数,第一个函数是获取整个目标网页数据,第二个函数是在目标网页中获取目标图片,遍历网页,并且给获取的图片按照0开始排序。
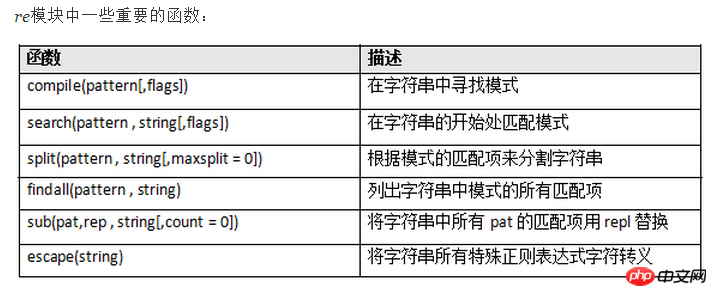
注:re模块知识点:
爬取图片效果图:
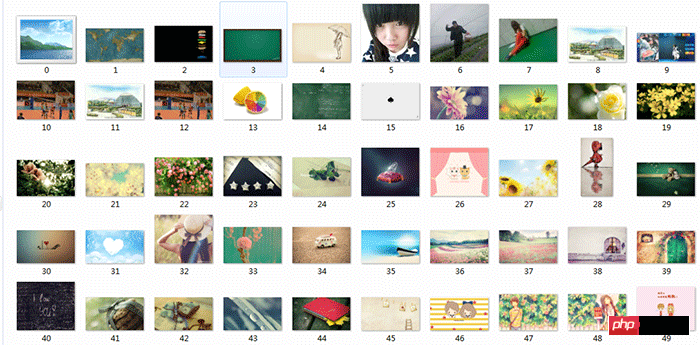
图片保存路径默认在建立的.py同目录文件下。
2.爬取有反爬虫措施的百度图片。如百度图片等。
例如关键字搜索“表情包”https://image.baidu.com/search/index?tn=baiduimage&ct=201326592&lm=-1&cl=2&ie=gbk&word=%B1%ED%C7%E9%B0%FC&fr=ala&ori_query=%E8%A1%A8%E6%83%85%E5%8C%85&ala=0&alatpl=sp&pos=0&hs=2&xthttps=111111
图片采用滚动式加载,先爬取最优先的30张。
代码如下:
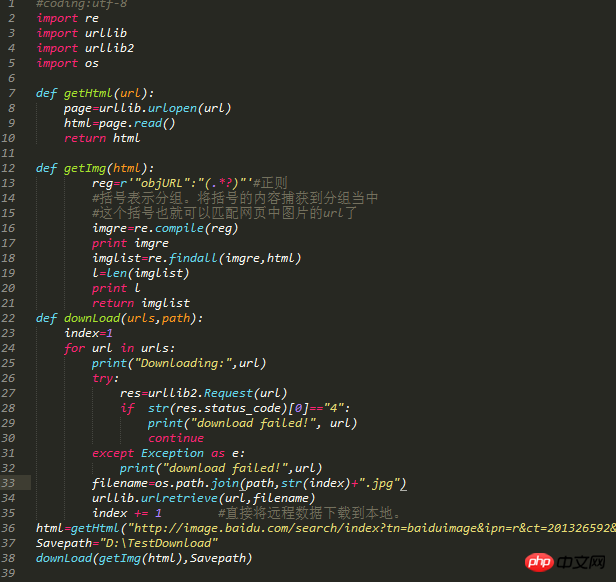
代码注释:导入4个模块,os模块用于指定保存路径。前两个函数同上。第三个函数使用了if语句,并tryException异常。
爬取过程如下:
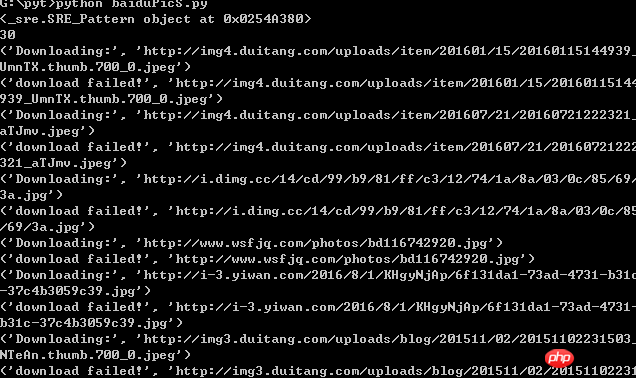
爬取结果:

注:编写python代码注重对齐,and不能混用Tab和空格,易报错。
【相关推荐】
1. Python免费视频教程
2. Python学习手册
以上是教你如何通过关键字爬取网页图片的详细内容。更多信息请关注PHP中文网其他相关文章!

 列表和阵列之间的选择如何影响涉及大型数据集的Python应用程序的整体性能?May 03, 2025 am 12:11 AM
列表和阵列之间的选择如何影响涉及大型数据集的Python应用程序的整体性能?May 03, 2025 am 12:11 AMForhandlinglargedatasetsinPython,useNumPyarraysforbetterperformance.1)NumPyarraysarememory-efficientandfasterfornumericaloperations.2)Avoidunnecessarytypeconversions.3)Leveragevectorizationforreducedtimecomplexity.4)Managememoryusagewithefficientdata
 说明如何将内存分配给Python中的列表与数组。May 03, 2025 am 12:10 AM
说明如何将内存分配给Python中的列表与数组。May 03, 2025 am 12:10 AMInpython,ListSusedynamicMemoryAllocationWithOver-Asalose,而alenumpyArraySallaySallocateFixedMemory.1)listssallocatemoremoremoremorythanneededinentientary上,respizeTized.2)numpyarsallaysallaysallocateAllocateAllocateAlcocateExactMemoryForements,OfferingPrediCtableSageButlessemageButlesseflextlessibility。
 您如何在Python数组中指定元素的数据类型?May 03, 2025 am 12:06 AM
您如何在Python数组中指定元素的数据类型?May 03, 2025 am 12:06 AMInpython,YouCansspecthedatatAtatatPeyFelemereModeRernSpant.1)Usenpynernrump.1)Usenpynyp.dloatp.dloatp.ploatm64,formor professisconsiscontrolatatypes。
 什么是Numpy,为什么对于Python中的数值计算很重要?May 03, 2025 am 12:03 AM
什么是Numpy,为什么对于Python中的数值计算很重要?May 03, 2025 am 12:03 AMNumPyisessentialfornumericalcomputinginPythonduetoitsspeed,memoryefficiency,andcomprehensivemathematicalfunctions.1)It'sfastbecauseitperformsoperationsinC.2)NumPyarraysaremorememory-efficientthanPythonlists.3)Itoffersawiderangeofmathematicaloperation
 讨论'连续内存分配”的概念及其对数组的重要性。May 03, 2025 am 12:01 AM
讨论'连续内存分配”的概念及其对数组的重要性。May 03, 2025 am 12:01 AMContiguousmemoryallocationiscrucialforarraysbecauseitallowsforefficientandfastelementaccess.1)Itenablesconstanttimeaccess,O(1),duetodirectaddresscalculation.2)Itimprovescacheefficiencybyallowingmultipleelementfetchespercacheline.3)Itsimplifiesmemorym
 您如何切成python列表?May 02, 2025 am 12:14 AM
您如何切成python列表?May 02, 2025 am 12:14 AMSlicingaPythonlistisdoneusingthesyntaxlist[start:stop:step].Here'showitworks:1)Startistheindexofthefirstelementtoinclude.2)Stopistheindexofthefirstelementtoexclude.3)Stepistheincrementbetweenelements.It'susefulforextractingportionsoflistsandcanuseneg
 在Numpy阵列上可以执行哪些常见操作?May 02, 2025 am 12:09 AM
在Numpy阵列上可以执行哪些常见操作?May 02, 2025 am 12:09 AMnumpyallowsforvariousoperationsonArrays:1)basicarithmeticlikeaddition,减法,乘法和division; 2)evationAperationssuchasmatrixmultiplication; 3)element-wiseOperations wiseOperationswithOutexpliitloops; 4)
 Python的数据分析中如何使用阵列?May 02, 2025 am 12:09 AM
Python的数据分析中如何使用阵列?May 02, 2025 am 12:09 AMArresinpython,尤其是Throughnumpyandpandas,weessentialFordataAnalysis,offeringSpeedAndeffied.1)NumpyArseNable efflaysenable efficefliceHandlingAtaSetSetSetSetSetSetSetSetSetSetSetsetSetSetSetSetsopplexoperationslikemovingaverages.2)


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

WebStorm Mac版
好用的JavaScript开发工具

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

Dreamweaver Mac版
视觉化网页开发工具

