


这篇文章主要介绍了关于python利用不到一百行代码实现了一个小siri的相关资料,文中介绍的很详细,对大家具有一定的参考借鉴价值,需要的朋友们下面来一起看看吧。
前言
如果想要容易理解核心的特征计算的话建议先去看看我之前的听歌识曲的文章,传送门:www.jb51.net/article/97305.htm
本文主要是实现了一个简单的命令词识别程序,算法核心一是提取音频特征,二是用DTW算法进行匹配。当然,这样的代码肯定不能用于商业化,大家做出来玩玩娱乐一下还是不错的。
设计思路
就算是个小东西,我们也要先明确思路再做。音频识别,困难不小,其中提取特征的难度在我听歌识曲那篇文章里能看得出来。而语音识别难度更大,因为音乐总是固定的,而人类说话常常是变化的。比如说一个“芝麻开门”,有的人就会说成“芝麻开门”,有的人会说成“芝麻开门”。而且在录音时说话的时间也不一样,可能很紧迫的一开始录音就说话了,也可能不紧不慢的快要录音结束了才把这四个字说出来。这样难度就大了。
算法流程:

特征提取
和之前的听歌识曲一样,同样是将一秒钟分成40块,对每一块进行傅里叶变换,然后取模长。只是这不像之前听歌识曲中进一步进行提取峰值,而是直接当做特征值。
看不懂我在说什么的朋友可以看看下面的源代码,或者看听歌识曲那篇文章。
DTW算法
DTW,Dynamic Time Warping,动态时间归整。算法解决的问题是将不同发音长短和位置进行最适合的匹配。
算法输入两组音频的特征向量: A:[fp1,fp2,fp3,......,fpM1] B:[fp1,fp2,fp3,fp4,.....fpM2]
A组共有M1个特征,B组共有M2个音频。每个特征向量中的元素就是之前我们将每秒切成40块之后FFT求模长的向量。计算每对fp之间的代价采用的是欧氏距离。
设D(fpa,fpb)为两个特征的距离代价。
那么我们可以画出下面这样的图
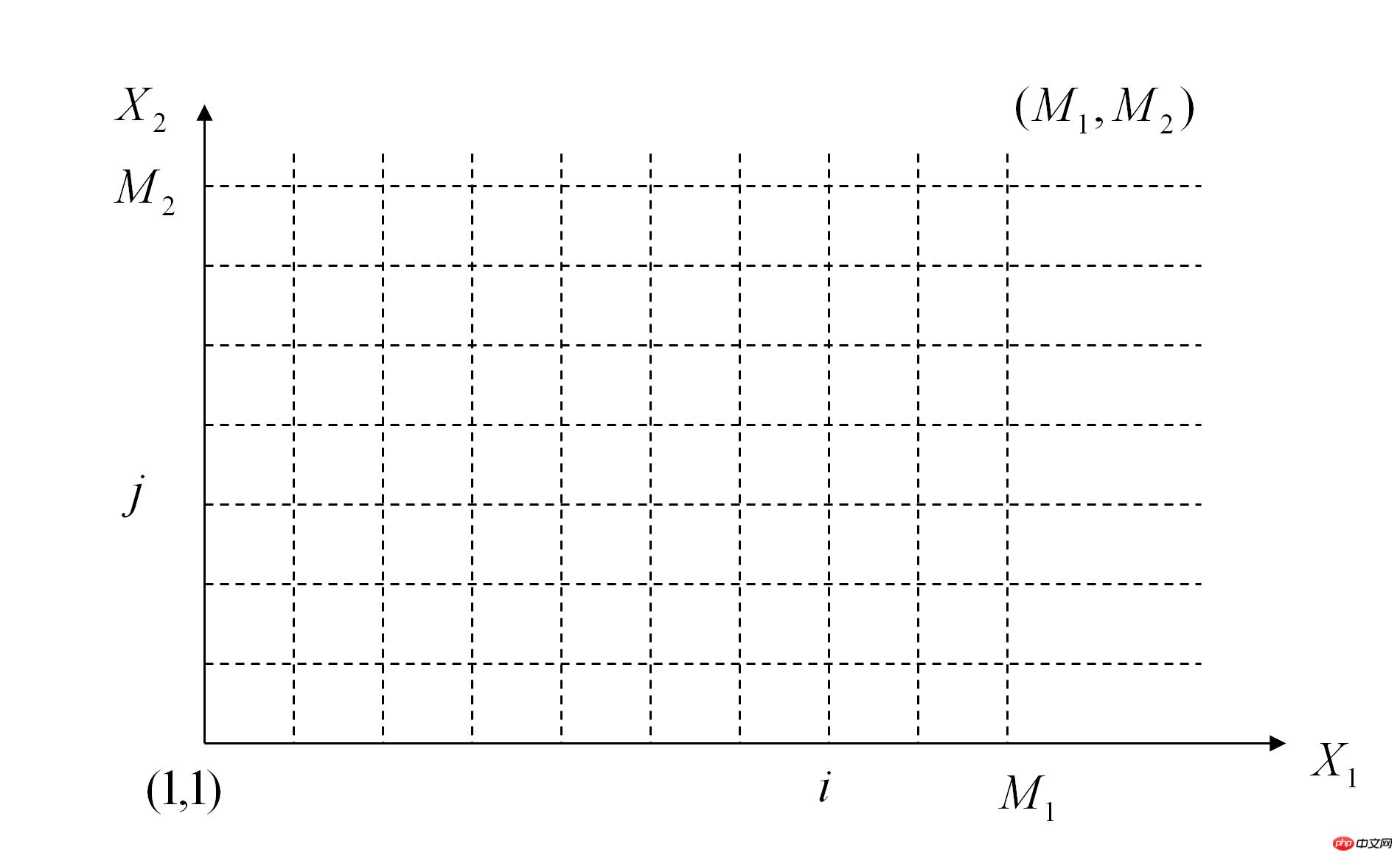
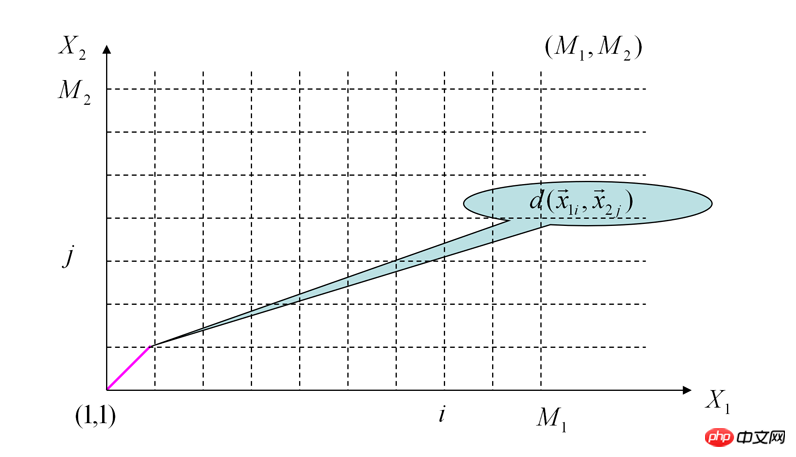
我们需要从(1,1)点走到(M1,M2)点,这会有很多种走法,而每种走法就是一种两个音频位置匹配的方式。但我们的目标是走的总过程中代价最小,这样可以保证这种对齐方式是使我们得到最接近的对齐方式。
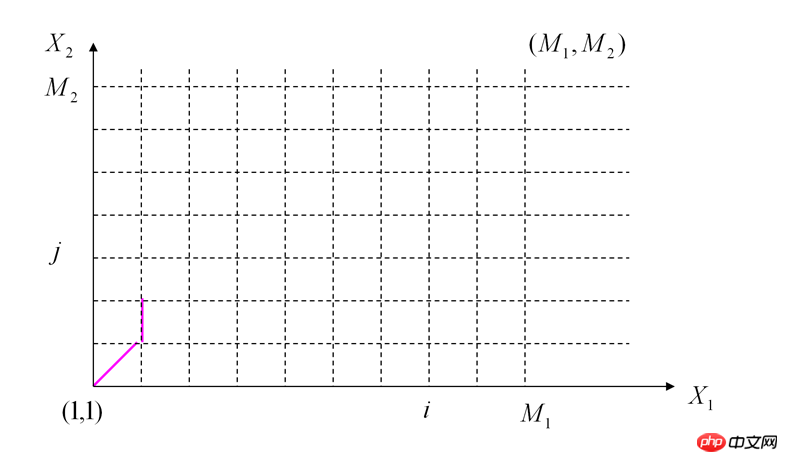
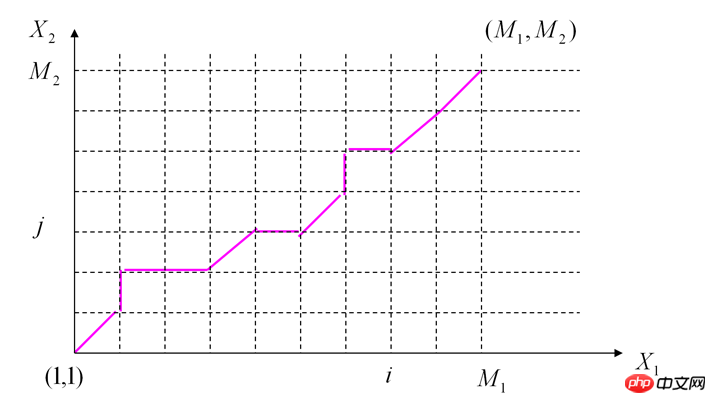
我们这样走:首先两个坐标轴上的各个点都是可以直接计算累加代价和求出的。然后对于中间的点来说D(i,j) = Min{D(i-1,j)+D(fpi,fpj) , D(i,j-1)+D(fpi,fpj) , D(i-1,j-1) + 2 * D(fpi,fpj)}
为什么由(i-1,j-1)直接走到(i,j)这个点需要加上两倍的代价呢?因为别人走正方形的两个直角边,它走的是正方形的对角线啊
按照这个原理选择,一直算到D(M1,M2),这就是两个音频的距离。
源代码和注释
# coding=utf8
import os
import wave
import dtw
import numpy as np
import pyaudio
def compute_distance_vec(vec1, vec2):
return np.linalg.norm(vec1 - vec2) #计算两个特征之间的欧氏距离
class record():
def record(self, CHUNK=44100, FORMAT=pyaudio.paInt16, CHANNELS=2, RATE=44100, RECORD_SECONDS=200,
WAVE_OUTPUT_FILENAME="record.wav"):
#录歌方法
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
frames = []
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
stream.stop_stream()
stream.close()
p.terminate()
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(''.join(frames))
wf.close()
class voice():
def loaddata(self, filepath):
try:
f = wave.open(filepath, 'rb')
params = f.getparams()
self.nchannels, self.sampwidth, self.framerate, self.nframes = params[:4]
str_data = f.readframes(self.nframes)
self.wave_data = np.fromstring(str_data, dtype=np.short)
self.wave_data.shape = -1, self.sampwidth
self.wave_data = self.wave_data.T #存储歌曲原始数组
f.close()
self.name = os.path.basename(filepath) # 记录下文件名
return True
except:
raise IOError, 'File Error'
def fft(self, frames=40):
self.fft_blocks = [] #将音频每秒分成40块,再对每块做傅里叶变换
blocks_size = self.framerate / frames
for i in xrange(0, len(self.wave_data[0]) - blocks_size, blocks_size):
self.fft_blocks.append(np.abs(np.fft.fft(self.wave_data[0][i:i + blocks_size])))
@staticmethod
def play(filepath):
chunk = 1024
wf = wave.open(filepath, 'rb')
p = pyaudio.PyAudio()
# 播放音乐方法
stream = p.open(format=p.get_format_from_width(wf.getsampwidth()),
channels=wf.getnchannels(),
rate=wf.getframerate(),
output=True)
while True:
data = wf.readframes(chunk)
if data == "": break
stream.write(data)
stream.close()
p.terminate()
if name == 'main':
r = record()
r.record(RECORD_SECONDS=3, WAVE_OUTPUT_FILENAME='record.wav')
v = voice()
v.loaddata('record.wav')
v.fft()
file_list = os.listdir(os.getcwd())
res = []
for i in file_list:
if i.split('.')[1] == 'wav' and i.split('.')[0] != 'record':
temp = voice()
temp.loaddata(i)
temp.fft()
res.append((dtw.dtw(v.fft_blocks, temp.fft_blocks, compute_distance_vec)[0],i))
res.sort()
print res
if res[0][1].find('open_qq') != -1:
os.system('C:\program\Tencent\QQ\Bin\QQScLauncher.exe') #我的QQ路径
elif res[0][1].find('zhimakaimen') != -1:
os.system('chrome.exe')#浏览器的路径,之前已经被添加到了Path中了
elif res[0][1].find('play_music') != -1:
voice.play('C:\data\music\\audio\\audio\\ (9).wav') #播放一段音乐
# r = record()
# r.record(RECORD_SECONDS=3,WAVE_OUTPUT_FILENAME='zhimakaimen_09.wav')事先可以先用这里的record方法录制几段命令词,尝试用不同语气说,不同节奏说,这样可以提高准确度。然后设计好文件名,根据匹配到的最接近音频的文件名就可以知道是哪种命令,进而自定义执行不同的任务
这是一段演示视频:www.iqiyi.com/w_19ruisynsd.html
以上是python实现一个简洁siri功能的详细内容。更多信息请关注PHP中文网其他相关文章!

 学习Python:2小时的每日学习是否足够?Apr 18, 2025 am 12:22 AM
学习Python:2小时的每日学习是否足够?Apr 18, 2025 am 12:22 AM每天学习Python两个小时是否足够?这取决于你的目标和学习方法。1)制定清晰的学习计划,2)选择合适的学习资源和方法,3)动手实践和复习巩固,可以在这段时间内逐步掌握Python的基本知识和高级功能。
 Web开发的Python:关键应用程序Apr 18, 2025 am 12:20 AM
Web开发的Python:关键应用程序Apr 18, 2025 am 12:20 AMPython在Web开发中的关键应用包括使用Django和Flask框架、API开发、数据分析与可视化、机器学习与AI、以及性能优化。1.Django和Flask框架:Django适合快速开发复杂应用,Flask适用于小型或高度自定义项目。2.API开发:使用Flask或DjangoRESTFramework构建RESTfulAPI。3.数据分析与可视化:利用Python处理数据并通过Web界面展示。4.机器学习与AI:Python用于构建智能Web应用。5.性能优化:通过异步编程、缓存和代码优
 Python vs.C:探索性能和效率Apr 18, 2025 am 12:20 AM
Python vs.C:探索性能和效率Apr 18, 2025 am 12:20 AMPython在开发效率上优于C ,但C 在执行性能上更高。1.Python的简洁语法和丰富库提高开发效率。2.C 的编译型特性和硬件控制提升执行性能。选择时需根据项目需求权衡开发速度与执行效率。
 python在行动中:现实世界中的例子Apr 18, 2025 am 12:18 AM
python在行动中:现实世界中的例子Apr 18, 2025 am 12:18 AMPython在现实世界中的应用包括数据分析、Web开发、人工智能和自动化。1)在数据分析中,Python使用Pandas和Matplotlib处理和可视化数据。2)Web开发中,Django和Flask框架简化了Web应用的创建。3)人工智能领域,TensorFlow和PyTorch用于构建和训练模型。4)自动化方面,Python脚本可用于复制文件等任务。
 Python的主要用途:综合概述Apr 18, 2025 am 12:18 AM
Python的主要用途:综合概述Apr 18, 2025 am 12:18 AMPython在数据科学、Web开发和自动化脚本领域广泛应用。1)在数据科学中,Python通过NumPy、Pandas等库简化数据处理和分析。2)在Web开发中,Django和Flask框架使开发者能快速构建应用。3)在自动化脚本中,Python的简洁性和标准库使其成为理想选择。
 Python的主要目的:灵活性和易用性Apr 17, 2025 am 12:14 AM
Python的主要目的:灵活性和易用性Apr 17, 2025 am 12:14 AMPython的灵活性体现在多范式支持和动态类型系统,易用性则源于语法简洁和丰富的标准库。1.灵活性:支持面向对象、函数式和过程式编程,动态类型系统提高开发效率。2.易用性:语法接近自然语言,标准库涵盖广泛功能,简化开发过程。
 Python:多功能编程的力量Apr 17, 2025 am 12:09 AM
Python:多功能编程的力量Apr 17, 2025 am 12:09 AMPython因其简洁与强大而备受青睐,适用于从初学者到高级开发者的各种需求。其多功能性体现在:1)易学易用,语法简单;2)丰富的库和框架,如NumPy、Pandas等;3)跨平台支持,可在多种操作系统上运行;4)适合脚本和自动化任务,提升工作效率。
 每天2小时学习Python:实用指南Apr 17, 2025 am 12:05 AM
每天2小时学习Python:实用指南Apr 17, 2025 am 12:05 AM可以,在每天花费两个小时的时间内学会Python。1.制定合理的学习计划,2.选择合适的学习资源,3.通过实践巩固所学知识,这些步骤能帮助你在短时间内掌握Python。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

WebStorm Mac版
好用的JavaScript开发工具

Dreamweaver CS6
视觉化网页开发工具

Atom编辑器mac版下载
最流行的的开源编辑器

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

