



由于爬虫抓取的数据不断增多,这两天在不断对数据库以及查询语句进行优化,其中一个表结构如下:
CREATE TABLE `newspaper_article` ( `id` varchar(50) NOT NULL COMMENT '编号', `title` varchar(190) NOT NULL COMMENT '标题', `author` varchar(255) DEFAULT NULL COMMENT '作者', `date` date NULL DEFAULT NULL COMMENT '发表时间', `content` longtext COMMENT '正文', `status` tinyint(4) DEFAULT '0', PRIMARY KEY (`id`), KEY `idx_status_date` (`status`,`date`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='文章表';
根据业务需要,添加了 idx_status_date 索引,在执行下面这个 SQL 时特别耗时:
SELECT id, title, status, date FROM article WHERE status > -2 AND date = '2016-01-07';
根据观察,每天新增的数据大概在2500条以内,本以为这里指定了具体某天的日期 '2016-01-07' ,实际需要扫描的数据量应该在2500条以内才对,但实际并非如此:
实际共扫描了185589条数据,远远高于预估的2500条,且实际执行时间都将近3秒钟:

这是为什么呢?
解决方案
将 idx_status_date (status, date) 改为 idx_status (status) 后,查看 MySQL 执行计划:

可以看到将多列索引改为单列索引后,执行计划要扫描的数据总量没有任何变化。结合多列索引遵循最左前缀原则,推测上面的查询语句只使用了 idx_status_date 最左边的 status 的索引。
翻了下《高性能MySQL》找到了下面这段话,证实了我的想法:
如果查询中有某个列的范围查询,则其右边所有列都无法使用索引优化查找。例如有查询
WHERE last_name = 'Smith' AND first_name LIKE 'J%' AND dob = '1976-12-23',这个查询只能使用索引的前两列,因为这里LIKE是一个范围条件(但是服务器可以把其余列用于其他目的)。如果范围查询列值的数量有限,那么可以通过使用多个等于条件来代替范围条件。
因此,这里解决思路有两种:
可以通过使用多个等于条件来代替范围条件
修改
idx_status_date (status, date)为索引idx_date_status (date, status),并新建一个idx_status索引,即可达到同样的效果。
优化后的执行计划:

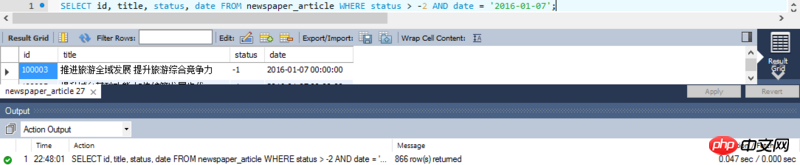
实际执行结果:
总结
当人们谈论索引的时候,如果没有特别指明类型,那么多半说的是 B-Tree 索引,它使用 B-Tree 数据结构来存储数据。我们使用术语“B-Tree”,是因为 MySQL 在 CREATE TABLE 和其他语句中也使用该关键字。不过,底层的存储引擎也可能使用不同的存储结构。InnoDB使用的是B+Tree。
假如有如下数据表:
CREATE TABLE People ( last_name varchar(50) not null, first_name varchar(50) not null, dob date not null, gender enum('m', 'f') not null, key(last_name, first_name, dob) );
B-Tree 索引对如下类型的查询有效
全值匹配
全值匹配指的是和索引中的所有列进行匹配,例如上表的索引可用于查找姓名为 Cuba Allen 、出生于 1960-01-01 的人。匹配最左前缀
上表中的索引可用于查找所有姓为 Allen 的人,即只使用索引的第一列。匹配列前缀
只匹配某一列的值的开头部分。例如上表的索引可用于查找所有以 J 开头的姓的人。这里也只使用了索引的第一列。匹配范围值
例如上表中的索引可用于查找姓在 Allen 和 Barrymore 之间的人。这里也只使用了索引的第一列。精确匹配某一列并范围匹配另外一列
上表的索引也可用于查找所有姓为 Allen ,并且名字是字母 K 开头(比如 Kim 、 Karl 等)的人。即第一列 last_name 全匹配,第二列 first_name 范围匹配。只访问索引的查询
B-Tree 通常可以支持“只访问索引的查询”,即查询只需要访问索引,而无须访问数据行。
B-Tree 索引的一些限制
如果不是按照索引的最左列开始查找,则无法使用索引。例如上表的索引无法用于查找名字为 Bill 的人,也无法查找某个特定生日的人,因为这两列都不是最左数据列。类似地,也无法查找姓氏以某个字母结尾的人。
不能跳过索引中列。也就是说,上表的索引无法用于查找姓氏为 Smith 并且在某个特定日期出生的人。如果不指定名(first_name),则 MySQL 只能使用索引的第一列。
如果查询中有某个列的范围查询,则其右边所有列都无法使用索引优化查找。例如有查询
WHERE last_name = 'Smith' AND first_name LIKE 'J%' AND dob = '1976-12-23',这个查询只能使用索引的前两列,因为这里LIKE是一个范围条件(但是服务器可以把其余列用于其他目的)。如果范围查询列值的数量有限,那么可以通过使用多个等于条件来代替范围条件。
以上是分享一个MySQL 多列索引优化实例代码的详细内容。更多信息请关注PHP中文网其他相关文章!

 MySQL:初学者的基本技能Apr 18, 2025 am 12:24 AM
MySQL:初学者的基本技能Apr 18, 2025 am 12:24 AMMySQL适合初学者学习数据库技能。1.安装MySQL服务器和客户端工具。2.理解基本SQL查询,如SELECT。3.掌握数据操作:创建表、插入、更新、删除数据。4.学习高级技巧:子查询和窗口函数。5.调试和优化:检查语法、使用索引、避免SELECT*,并使用LIMIT。
 MySQL:结构化数据和关系数据库Apr 18, 2025 am 12:22 AM
MySQL:结构化数据和关系数据库Apr 18, 2025 am 12:22 AMMySQL通过表结构和SQL查询高效管理结构化数据,并通过外键实现表间关系。1.创建表时定义数据格式和类型。2.使用外键建立表间关系。3.通过索引和查询优化提高性能。4.定期备份和监控数据库确保数据安全和性能优化。
 MySQL:解释的关键功能和功能Apr 18, 2025 am 12:17 AM
MySQL:解释的关键功能和功能Apr 18, 2025 am 12:17 AMMySQL是一个开源的关系型数据库管理系统,广泛应用于Web开发。它的关键特性包括:1.支持多种存储引擎,如InnoDB和MyISAM,适用于不同场景;2.提供主从复制功能,利于负载均衡和数据备份;3.通过查询优化和索引使用提高查询效率。
 SQL的目的:与MySQL数据库进行交互Apr 18, 2025 am 12:12 AM
SQL的目的:与MySQL数据库进行交互Apr 18, 2025 am 12:12 AMSQL用于与MySQL数据库交互,实现数据的增、删、改、查及数据库设计。1)SQL通过SELECT、INSERT、UPDATE、DELETE语句进行数据操作;2)使用CREATE、ALTER、DROP语句进行数据库设计和管理;3)复杂查询和数据分析通过SQL实现,提升业务决策效率。
 初学者的MySQL:开始数据库管理Apr 18, 2025 am 12:10 AM
初学者的MySQL:开始数据库管理Apr 18, 2025 am 12:10 AMMySQL的基本操作包括创建数据库、表格,及使用SQL进行数据的CRUD操作。1.创建数据库:CREATEDATABASEmy_first_db;2.创建表格:CREATETABLEbooks(idINTAUTO_INCREMENTPRIMARYKEY,titleVARCHAR(100)NOTNULL,authorVARCHAR(100)NOTNULL,published_yearINT);3.插入数据:INSERTINTObooks(title,author,published_year)VA
 MySQL的角色:Web应用程序中的数据库Apr 17, 2025 am 12:23 AM
MySQL的角色:Web应用程序中的数据库Apr 17, 2025 am 12:23 AMMySQL在Web应用中的主要作用是存储和管理数据。1.MySQL高效处理用户信息、产品目录和交易记录等数据。2.通过SQL查询,开发者能从数据库提取信息生成动态内容。3.MySQL基于客户端-服务器模型工作,确保查询速度可接受。
 mysql:构建您的第一个数据库Apr 17, 2025 am 12:22 AM
mysql:构建您的第一个数据库Apr 17, 2025 am 12:22 AM构建MySQL数据库的步骤包括:1.创建数据库和表,2.插入数据,3.进行查询。首先,使用CREATEDATABASE和CREATETABLE语句创建数据库和表,然后用INSERTINTO语句插入数据,最后用SELECT语句查询数据。
 MySQL:一种对数据存储的初学者友好方法Apr 17, 2025 am 12:21 AM
MySQL:一种对数据存储的初学者友好方法Apr 17, 2025 am 12:21 AMMySQL适合初学者,因为它易用且功能强大。1.MySQL是关系型数据库,使用SQL进行CRUD操作。2.安装简单,需配置root用户密码。3.使用INSERT、UPDATE、DELETE、SELECT进行数据操作。4.复杂查询可使用ORDERBY、WHERE和JOIN。5.调试需检查语法,使用EXPLAIN分析查询。6.优化建议包括使用索引、选择合适数据类型和良好编程习惯。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

