



Java Web开发实战经典
在项目开发中,HTML的主要功能是进行数据展示,而要进行数据存储结构的规范化就需要使用XML。XML有自己的语法,而且所有的标记元素都可以由用户任意定义。
1、认识XML
XML(eXtended Markup Language,可扩展的标记性语言)提供了一套跨平台、跨网络、跨程序的语言的数据描述方式,使用XML可以方便地实现数据交换、系统配置、内容管理等常见功能。
XML与HTML类似,都属于标记性语言。最大的不同时HTML中的元素都是固定的,且以显示为主,而XML语言中的标记都是由用户自定义的,主要以数据保存为主。
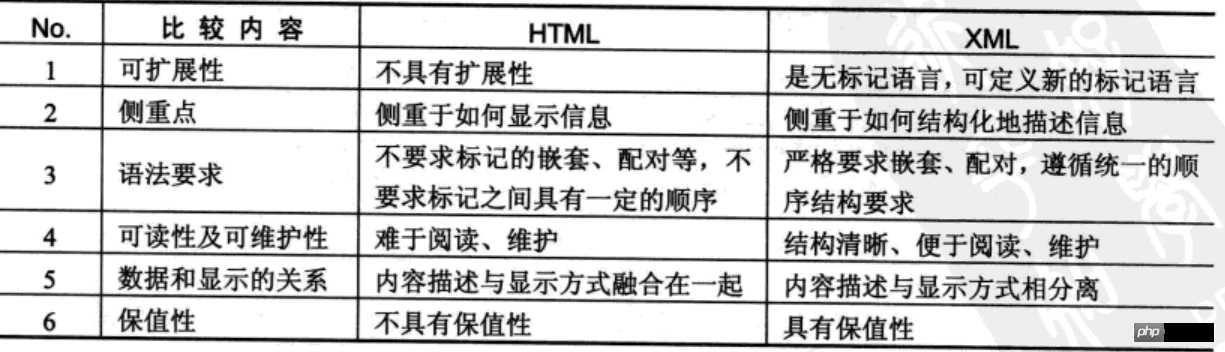
XML和HTML的比较
实际上所有的XML文件都由前导区和数据区两部分组成。
前导区:规定出XML页面的一些属性,有以下3个属性:
version:表示使用的XML版本,现在是1.0。
encoding:页面中使用的文字编码,如果有中文,则一定要指定编码。
standalone:此XML文件是否是独立运行,如果需要进行显示可以使用CSS或XSL控制。
属性出现的顺序是固定的,version、encoding、standalone,一旦顺序不对,XML将出现错误。
<?xml version="1.0" encoding="GB2312" standalone="no"?>数据区:所有的数据区必须有一个根元素,一个根元素下可以存放多个子元素,但是要求每一个元素必须完结,每一个标记都是区分大小写的。
XML语言中提供了CDATA标记来标识文件数据,当XML解析器处理到CDATA标记时,它不会解析该段数据中的任何符号或标记,只是将原数据原封不动的传递给应用程序。
CDATA语法格式:
<![CDATA[] 不解析内容 ]>
2、XML解析
在XML文件中由于更多的是描述信息的内容,所以在得到一个XML文档后用该利用程序按照其中元素的定义名称取出对应的内容,这样的操作就称为XML解析。
在XML解析中W3C定义了SAX和DOM两种解析方式,这两种解析方式的程序操作如下:
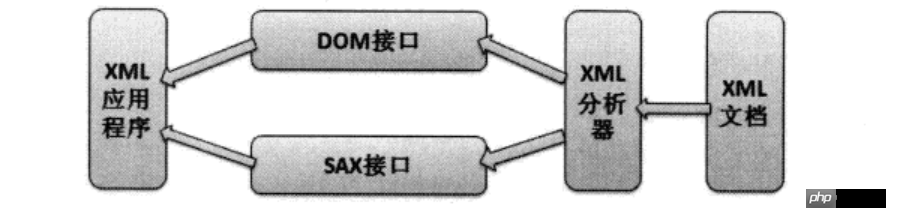
XML解析操作
可以看出,应用程序不是直接对XML文档进行操作的,而是首先由XML分析器对XML文档进行分析,然后应用程序通过XML分析器所提供的DOM接口或SAX接口对分析结构进行操作,从而间接地实现了对XML文档的访问。
2.1、DOM解析操作
在应用程序中,基于DOM (Document Object Model,文档对象模型)的XML分析器将一个XML文档转换成一个对象模型的集合(通常称为DOM树),应用程勋正是通过对这个对象模型的操作,来实现对XML文档数据的操作。通过DOM接口,应用程序可以在任何时候访问XML文档中的任何一部分数据,因此,这种这种利用DOM接口的机制也被称作随机访问机制。
由于DOM分析器把整个XML文档转化成DOM树放在了内存中,因此,当文档比较大或者结构比较复杂时,对内存的需求就比较高,而且对于结构复杂的树的遍历也是一项耗时的操作。
DOM操作会在内存中将所有的XML文件变为DOM树。
在DOM解析中有以下4个核心的操作接口:
Document:此接口代表了整个XML文档,表示整个DOM树的根,提供了对文档中的数据进行访问和操作的入口,通过Document节点可以访问XML文件中所有的元素内容。

Document接口的常用方法
Node:DOM操作的核心接口中有很大一部分是从Node接口继承过来的。例如Document、Element、Attri等接口。在DOM树中,每一个Node接口代表了DOM树中的一个节点。
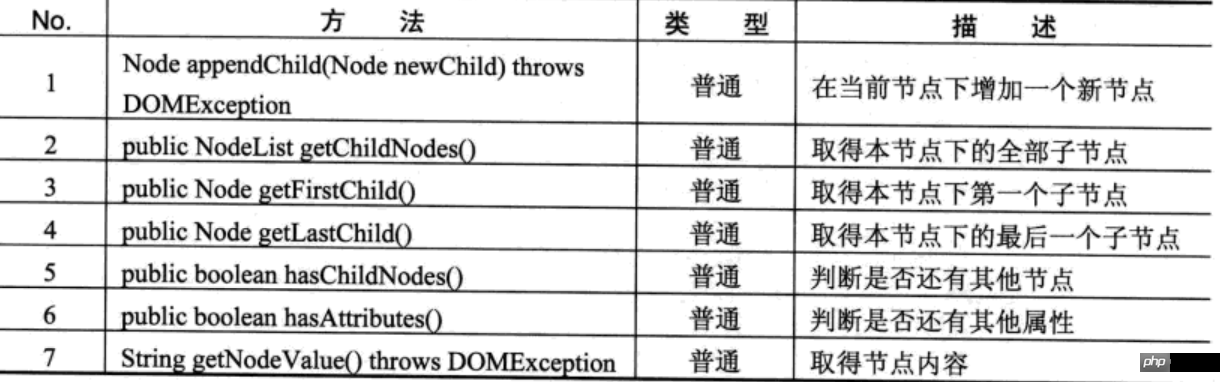
Node接口的常用方法
NodeList:此接口表示一个节点的集合,一般用于表示有顺序关系的一组节点。例如,一个节点的子节点,当文档改变时会直接 影响到NodeList集合。

NodeList接口的常用方法
NameNodeMap:此接口表示一组节点和其唯一名称对应的一一对应关系,主要用于属性节点的表示。
出以上4个核心接口外,如果一个程序需要进行DOM解析读操作,则需要按如下步骤进行:
(1)建立DocumentBuilderFactory:DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
(2)建立DocumentBuilder:DocumentBuilder builder = factory.newDocumentBuilder();
(3)建立Document:Document doc= builder.parse("要读取的文件路径");
(4)建立NodeList:NodeList nl = doc.getElementsByTagName("读取节点");
(5)进行XML信息读取。
// xml_demo.xml <?xml version="1.0" encoding="GBK"?> <addresslist> <linkman> <name>小明</name> <email>asaasa@163.com</email> </linkman> <linkman> <name>小张</name> <email>xiaoli@163.com</email> </linkman> </addresslist>
DOM完成XML的读取。
package com.demo;
import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class XmlDomDemo {
public static void main(String[] args) {
// (1)建立DocumentBuilderFactory,以用于取得DocumentBuilder
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// (2)通过DocumentBuilderFactory,取得DocumentBuilder
DocumentBuilder builder = null;
try {
builder = factory.newDocumentBuilder();
} catch (ParserConfigurationException e) {
e.printStackTrace();
}
// (3)定义Document接口对象,通过DocumentBuilder类进行DOM树是转换操作
Document doc = null;
try {
// 读取指定路径的XML文件,读取到内存中
doc = builder.parse("xml_demo.xml");
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
// (4)查找linkman节点
NodeList nl = doc.getElementsByTagName("linkman");
// (5)输出NodeList中第一个子节点中文本节点的内容
for (int i = 0; i < nl.getLength(); i++) {
// 取出每一个元素
Element element = (Element) nl.item(i);
System.out.println("姓名:" + element.getElementsByTagName("name").item(0).getFirstChild().getNodeValue());
System.out.println("邮箱:" + element.getElementsByTagName("email").item(0).getFirstChild().getNodeValue());
}
}
}DOM完成XML的文件输出。
此时就需要使用DOM操作中提供的各个接口(如Element接口)并手工设置各个节点的关系,同时在创建Document对象时就必须使用newDocument()方法建立一个新的DOM树。
如果现在需要将XML文件保存在硬盘上,则需要使用TransformerFactory、Transformer、DOMSource、StreamResult 4个类完成。
TransformerFactory类:取得一个Transformer类的实例对象。
DOMSource类:接收Document对象。
StreamResult 类:指定要使用的输出流对象(可以向文件输出,也可以向指定的输出流输出)。
Transformer类:通过该类完成内容的输出。

StreamResult类的构造方法
package com.demo;
import java.io.File;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.OutputKeys;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
public class XmlDemoWrite {
public static void main(String[] args) {
// (1)建立DocumentBuilderFactory,以用于取得DocumentBuilder
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// (2)通过DocumentBuilderFactory,取得DocumentBuilder
DocumentBuilder builder = null;
try {
builder = factory.newDocumentBuilder();
} catch (ParserConfigurationException e) {
e.printStackTrace();
}
// (3)定义Document接口对象,通过DocumentBuilder类进行DOM树是转换操作
Document doc = null;
// 创建一个新的文档
doc = builder.newDocument();
// (4)建立各个操作节点
Element addresslist = doc.createElement("addresslist");
Element linkman = doc.createElement("linkman");
Element name = doc.createElement("name");
Element email = doc.createElement("email");
// (5)设置节点的文本内容,即为每一个节点添加文本节点
name.appendChild(doc.createTextNode("小明"));
email.appendChild(doc.createTextNode("xiaoming@163.com"));
// (6)设置节点关系
linkman.appendChild(name);
linkman.appendChild(email);
addresslist.appendChild(linkman);
doc.appendChild(addresslist);
// (7)输出文档到文件中
TransformerFactory tf = TransformerFactory.newInstance();
Transformer t = null;
try {
t = tf.newTransformer();
} catch (TransformerConfigurationException e) {
e.printStackTrace();
}
// 设置编码
t.setOutputProperty(OutputKeys.ENCODING, "GBK");
// 输出文档
DOMSource source = new DOMSource(doc);
// 指定输出位置
StreamResult result = new StreamResult(new File("xml_wirte.xml"));
try {
// 输出
t.transform(source, result);
System.out.println("yes");
} catch (TransformerException e) {
e.printStackTrace();
}
}
}生成文档:
//xml_write.xml <?xml version="1.0" encoding="GBK" standalone="no"?> <addresslist> <linkman> <name>小明</name> <email>xiaoming@163.com</email> </linkman> </addresslist>
2.2、SAX解析操作
SAX(Simple APIs for XML,操作XML的简单接口)与DOM操作不同的是,SAX采用的是一种顺序的模式进行访问,是一种快速读取XML数据的方式。
当使用SAX 解析器进行操作时会触发一系列的事件。
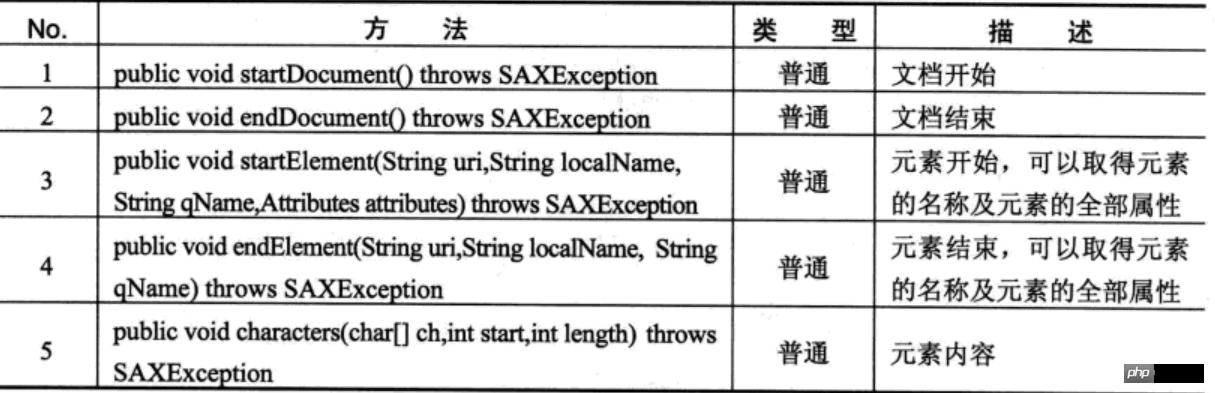
SAX主要事件
当扫描到文档(Document)开始与结束、元素(Element)开始与结束时都会调用相关的处理方法,并由这些操作方法做出相应的操作,直到整个文档扫描结束。
如果在开发中想要使用SAX解析,则首先应该编写一个SAX解析器,再直接定义一个类,并使该类继承自DefaultHandler类,同时覆写上述的表中的方法即可。
package com.sax.demo;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class XmlSax extends DefaultHandler {
@Override
public void startDocument() throws SAXException {
System.out.println("<?xml version=\"1.0\" encoding=\"GBK\"?>");
}
@Override
public void endDocument() throws SAXException {
System.out.println("\n 文档读取结束。。。");
}
@Override
public void startElement(String url, String localName, String name,
Attributes attributes) throws SAXException {
System.out.print("<");
System.out.print(name);
if (attributes != null) {
for (int x = 0; x < attributes.getLength(); x++) {
System.out.print("" + attributes.getQName(x) + "=\"" + attributes.getValue(x) + "\"");
}
}
System.out.print(">");
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
System.out.print(new String(ch, start, length));
}
@Override
public void endElement(String url, String localName, String name)
throws SAXException {
System.out.print("</");
System.out.print(name);
System.out.print(">");
}
}
建荔湾SAX解析器后,还需要建立SAXParserFactory和SAXParser对象,之后通过SAXPaeser的parse()方法指定要解析的XML文件和指定的SAX解析器。
建立要读取的文件:sax_demo.xml
<?xml version="1.0" encoding="GBK"?> <addresslist> <linkman id="xm"> <name>小明</name> <email>xiaoming@163.com</email> </linkman> <linkman id="xl"> <name>小李</name> <email>xiaoli@163.com</email> </linkman> </addresslist>
使用SAX解析器
package com.sax.demo;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
public class SaxTest {
public static void main(String[] args) throws Exception {
//(1)建立SAX解析工厂
SAXParserFactory factory = SAXParserFactory.newInstance();
//(2)构造解析器
SAXParser parser = factory.newSAXParser();
//(3)解析XML使用handler
parser.parse("sax_demo.xml", new XmlSax());
}
}
通过上面的程序可以发现,使用SAX解析比使用DOM解析更加容易。
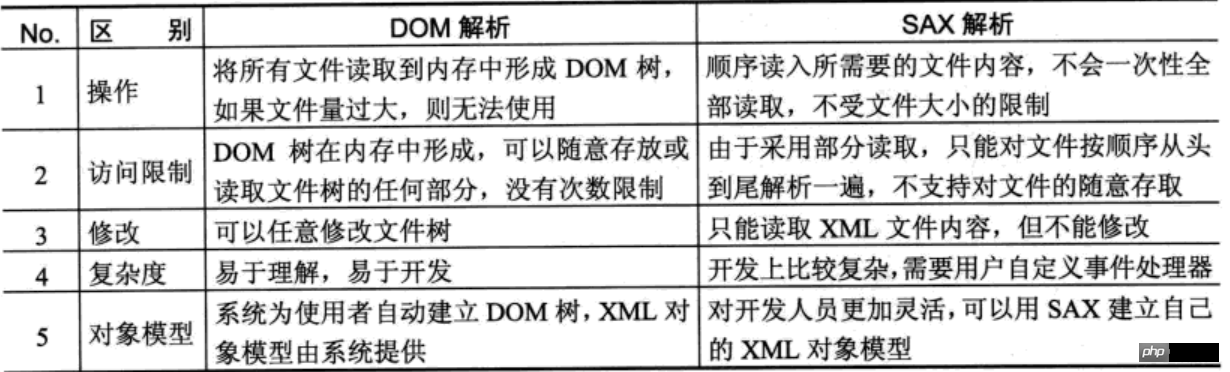
DOM解析与SAX解析的区别
有两者的特点可以发现两者的区别:
DOM解析适合于对文件进行修改和随机存取的操作,但是不适合于大型文件的操作。
SAX采用部分读取的方式,所以可以处理大型文件,而且只需要从文件中读取特定内容。SAX解析可以由用户自己建立自己的对象模型。
2.3、XML解析的好帮手:jdom
jdom是使用Java编写的,用于读、写、操作XML的一套组件。
jdom = dom 修改文件的有点 + SAX读取快速的优点

jdom的主要操作类
使用jdom生成XML文件
package com.jdom.demo;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import org.jdom.Attribute;
import org.jdom.Document;
import org.jdom.Element;
import org.jdom.output.XMLOutputter;
public class WriteXml {
public static void main(String[] args) {
// 定义节点
Element addresslist = new Element("addresslist");
Element linkman = new Element("linkman");
Element name = new Element("name");
Element email = new Element("email");
// 定义属性
Attribute id = new Attribute("id", "xm");
// 声明一个Document对象
Document doc = new Document(addresslist);
// 设置元素的内容
name.setText("小明");
email.setText("xiaoming@163.com");
name.setAttribute(id);
// 设置子节点
linkman.addContent(name);
linkman.addContent(email);
// 将linkman加入根子节点
addresslist.addContent(linkman);
// 用来输出XML文件
XMLOutputter out = new XMLOutputter();
// 设置输出编码
out.setFormat(out.getFormat().setEncoding("GBK"));
// 输出XML文件
try {
out.output(doc, new FileOutputStream("jdom_write.xml"));
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
// jdom_write.xml <?xml version="1.0" encoding="GBK"?> <addresslist> <linkman> <name id="xm">小明</name> <email>xiaoming@163.com</email> </linkman> </addresslist>
使用jdom读取XML文件
package com.jdom.demo;
import java.io.IOException;
import java.util.List;
import org.jdom.Document;
import org.jdom.Element;
import org.jdom.JDOMException;
import org.jdom.input.SAXBuilder;
public class ReadXml {
public static void main(String[] args) throws JDOMException, IOException {
//建立SAX解析
SAXBuilder builder = new SAXBuilder();
//找到Document
Document readDoc = builder.build("jdom_write.xml");
//读取根元素
Element stu = readDoc.getRootElement();
//得到全部linkman子元素
List list = stu.getChildren("linkman");
for (int i = 0; i < list.size(); i++) {
Element e = (Element) list.get(i);
String name = e.getChildText("name");
String id = e.getChild("name").getAttribute("id").getValue();
String email = e.getChildText("email");
System.out.println("----联系人----");
System.out.println("姓名:" + name + "编号:" + id);
System.out.println("Email:" + email);
}
}
}
jdom是一种常见的操作组件
在实际的开发中使用非常广泛。
2.4、解析工具:dom4j
dom4j也是一组XML操作组件包,主要用来读写XML文件,由于dom4j性能优异、功能强大,且具有易用性,所以现在已经被广泛地应用开来。如,Hibernate、Spring框架中都使用了dom4j进行XML的解析操作。
开发时需要引入的jar包:dom4j-1.6.1.jar、lib/jaxen-1.1-beta-6.jar
dom4j中的所用操作接口都在org.dom4j包中定义。其他包根据需要把选择使用。
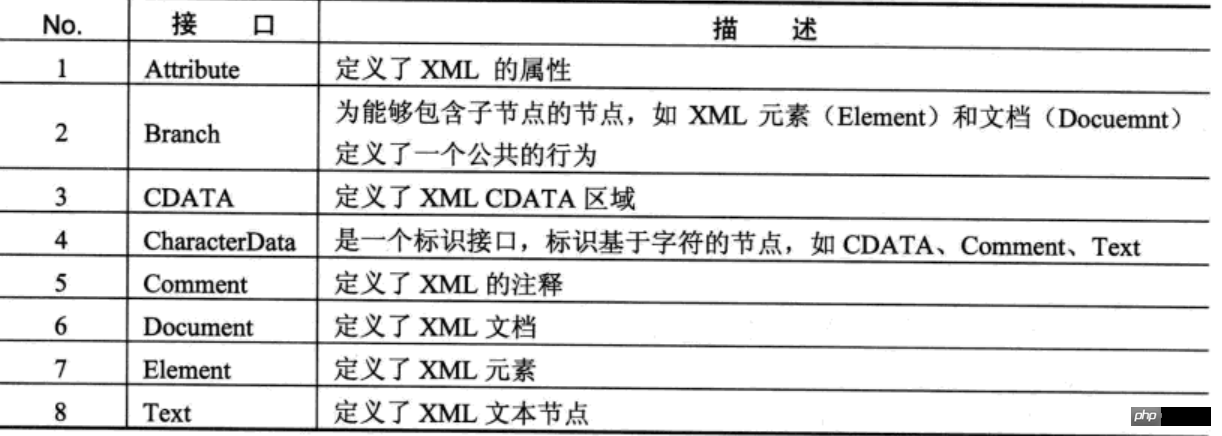
dom4j的主要接口
用dom4j生成XML文件:
package com.dom4j.demo;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.XMLWriter;
public class Dom4jWrite {
public static void main(String[] args) {
// 创建文档
Document doc = DocumentHelper.createDocument();
// 定义个节点
Element addresslist = doc.addElement("addresslist");
Element linkman = addresslist.addElement("linkman");
Element name = linkman.addElement("name");
Element email = linkman.addElement("email");
// 设置节点内容
name.setText("小明");
email.setText("xiaoming@163.com");
// 设置输出格式
OutputFormat format = OutputFormat.createPrettyPrint();
// 指定输出编码
format.setEncoding("GBK");
try {
XMLWriter writer = new XMLWriter(new FileOutputStream(new File(
"dom4j_demo.xml")), format);
writer.write(doc);
writer.close();
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
// dom4j_demo.xml <?xml version="1.0" encoding="GBK"?> <addresslist> <linkman> <name>小明</name> <email>xiaoming@163.com</email> </linkman> </addresslist>
用dom4j读取XML文件:
package com.dom4j.demo;
import java.io.File;
import java.util.Iterator;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class Dom4jRead {
public static void main(String[] args) {
//读取文件
File file = new File("dom4j_demo.xml");
//建立SAX解析读取
SAXReader reader = new SAXReader();
Document doc = null;
try {
//读取文档
doc = reader.read(file);
} catch (DocumentException e) {
e.printStackTrace();
}
//取得根元素
Element root = doc.getRootElement();
//取得全部的子节点
Iterator iter = root.elementIterator();
while (iter.hasNext()) {
//取得每一个linkman
Element linkman = (Element) iter.next();
System.out.println("姓名:"+linkman.elementText("name"));
System.out.println("邮件地址:"+linkman.elementText("email"));
}
}
}
小结
XML主要用于数据交换,而HTML则用于显示。
-
Java直接提供的XML解析方式分为两种,即DOM和SAX。这两种解析的区别如下:
DOM解析是将所有内容读取到内存中,并形成内存树,如果文件量较大则无法使用,但是DOM解析可以进行文件的修改
SAX解析是采用顺序的方式读取XML文件中,不受文件大小限制,但是不允许修改。
XML解析可以使用jdom和dom4j第三方工具包,以提升开发效率。
以上是XML解析基础的详细内容。更多信息请关注PHP中文网其他相关文章!

 RSS提要:探索XML的作用和目的Apr 28, 2025 am 12:06 AM
RSS提要:探索XML的作用和目的Apr 28, 2025 am 12:06 AMXML在RSSFeed中的作用是结构化数据、标准化和提供可扩展性。1.XML使得RSSFeed的数据结构化,便于解析和处理。2.XML提供了一种标准化的方式来定义RSSFeed的格式。3.XML的可扩展性使得RSSFeed可以根据需要添加新的标签和属性。
 缩放XML/RSS处理:性能优化技术Apr 27, 2025 am 12:28 AM
缩放XML/RSS处理:性能优化技术Apr 27, 2025 am 12:28 AM处理XML和RSS数据时,可以通过以下步骤优化性能:1)使用高效的解析器如lxml提升解析速度;2)采用SAX解析器减少内存使用;3)利用XPath表达式提高数据提取效率;4)实施多进程并行处理提升处理速度。
 RSS文档格式:探索RSS 2.0及以后Apr 26, 2025 am 12:22 AM
RSS文档格式:探索RSS 2.0及以后Apr 26, 2025 am 12:22 AMRSS2.0是一种开放标准,允许内容发布者以结构化的方式分发内容。它包含了丰富的元数据,如标题、链接、描述、发布日期等,使得订阅者能够快速浏览和访问内容。RSS2.0的优势在于其简洁和扩展性。例如,它允许自定义元素,这意味着开发者可以根据需求添加额外的信息,如作者、分类等。
 理解RSS:XML观点Apr 25, 2025 am 12:14 AM
理解RSS:XML观点Apr 25, 2025 am 12:14 AMRSS是一种基于XML的格式,用于发布经常更新的内容。1.RSSfeed通过XML结构化组织信息,包括标题、链接、描述等。2.创建RSSfeed需按照XML结构编写,添加元数据如语言和发布日期。3.高级用法可包含多媒体文件和分类信息。4.调试时使用XML验证工具,确保必需元素存在且编码正确。5.优化RSSfeed可通过分页、缓存和保持结构简洁来实现。通过理解和应用这些知识,可以有效管理和分发内容。
 XML中的RSS:解码标签,属性和结构Apr 24, 2025 am 12:09 AM
XML中的RSS:解码标签,属性和结构Apr 24, 2025 am 12:09 AMRSS是一种基于XML的格式,用于发布和订阅内容。RSS文件的XML结构包括根元素、元素和多个元素,每个代表一个内容条目。通过XML解析器读取和解析RSS文件,用户可以订阅并获取最新内容。
 XML在RSS中的优势:技术深度潜水Apr 23, 2025 am 12:02 AM
XML在RSS中的优势:技术深度潜水Apr 23, 2025 am 12:02 AMXML在RSS中具有结构化数据、可扩展性、跨平台兼容性和解析验证的优势。1)结构化数据确保内容的一致性和可靠性;2)可扩展性允许添加自定义标签以适应内容需求;3)跨平台兼容性使其在不同设备上无缝工作;4)解析和验证工具确保Feed的质量和完整性。
 XML中的RSS:揭示内容联合的核心Apr 22, 2025 am 12:08 AM
XML中的RSS:揭示内容联合的核心Apr 22, 2025 am 12:08 AMRSS在XML中的实现方式是通过结构化的XML格式来组织内容。1)RSS使用XML作为数据交换格式,包含频道信息和项目列表等元素。2)生成RSS文件需按规范组织内容,发布到服务器供订阅。3)RSS文件可通过阅读器或插件订阅,实现内容自动更新。
 超越基础:高级RSS文档功能Apr 21, 2025 am 12:03 AM
超越基础:高级RSS文档功能Apr 21, 2025 am 12:03 AMRSS的高级功能包括内容命名空间、扩展模块和条件订阅。1)内容命名空间扩展RSS功能,2)扩展模块如DublinCore或iTunes添加元数据,3)条件订阅根据特定条件筛选条目。这些功能通过添加XML元素和属性实现,提升信息获取效率。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

DVWA
Damn Vulnerable Web App (DVWA) 是一个PHP/MySQL的Web应用程序,非常容易受到攻击。它的主要目标是成为安全专业人员在合法环境中测试自己的技能和工具的辅助工具,帮助Web开发人员更好地理解保护Web应用程序的过程,并帮助教师/学生在课堂环境中教授/学习Web应用程序安全。DVWA的目标是通过简单直接的界面练习一些最常见的Web漏洞,难度各不相同。请注意,该软件中

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

