



总体介绍
如果你已看过前面关于HashSet和HashMap,以及TreeSet和TreeMap的讲解,一定能够想到本文将要讲解的LinkedHashSet和LinkedHashMap其实也是一回事。LinkedHashSet和LinkedHashMap在Java里也有着相同的实现,前者仅仅是对后者做了一层包装,也就是说LinkedHashSet里面有一个LinkedHashMap(适配器模式)。因此本文将重点分析LinkedHashMap。
LinkedHashMap实现了Map接口,即允许放入key为null的元素,也允许插入value为null的元素。从名字上可以看出该容器是linked list和HashMap的混合体,也就是说它同时满足HashMap和linked list的某些特性。可将LinkedHashMap看作采用linked list增强的HashMap。
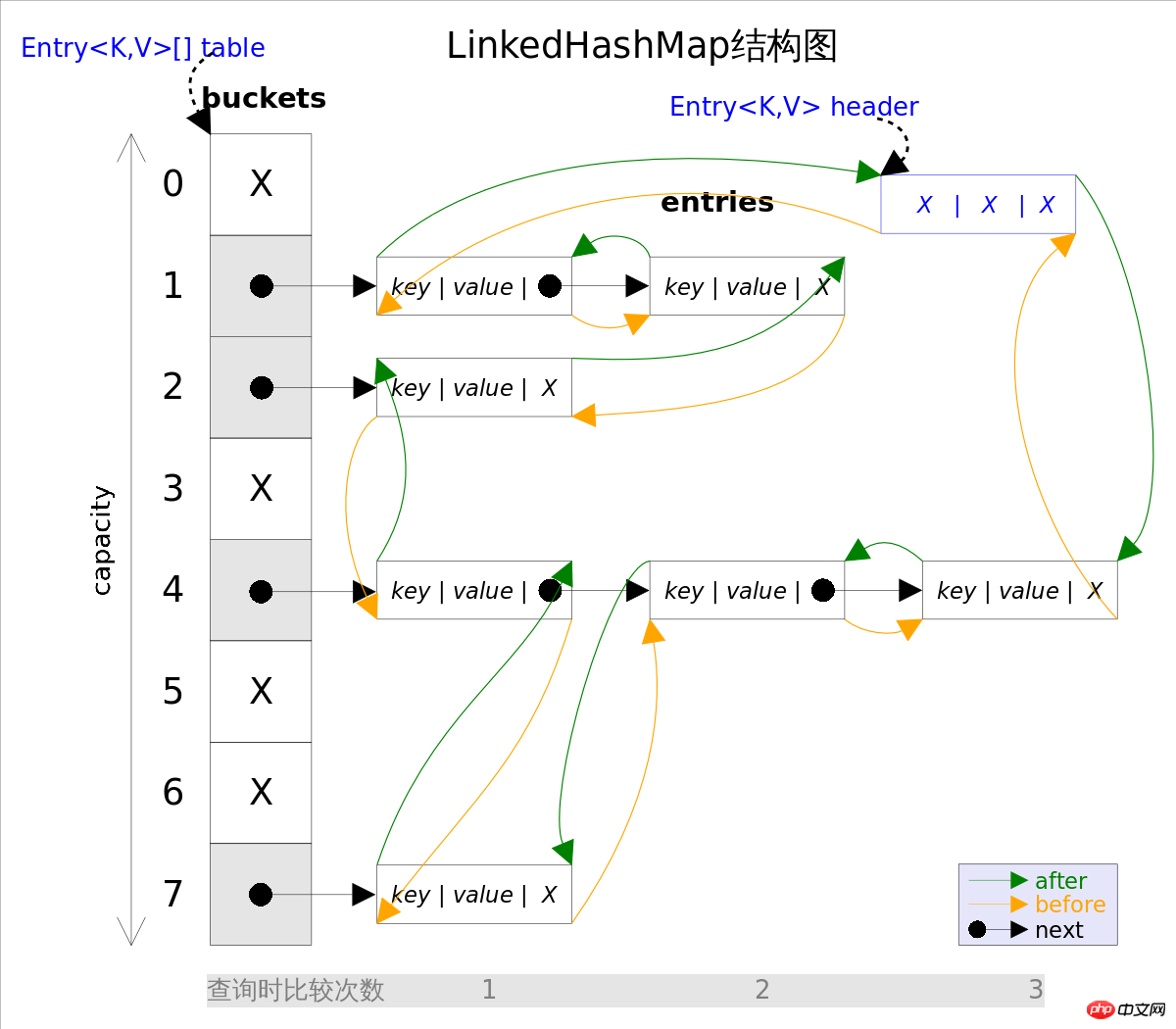
事实上LinkedHashMap是HashMap的直接子类,二者唯一的区别是LinkedHashMap在HashMap的基础上,采用双向链表(doubly-linked list)的形式将所有entry连接起来,这样是为保证元素的迭代顺序跟插入顺序相同。上图给出了LinkedHashMap的结构图,主体部分跟HashMap完全一样,多了header指向双向链表的头部(是一个哑元),该双向链表的迭代顺序就是entry的插入顺序。
除了可以保迭代历顺序,这种结构还有一个好处:迭代LinkedHashMap时不需要像HashMap那样遍历整个table,而只需要直接遍历header指向的双向链表即可,也就是说LinkedHashMap的迭代时间就只跟entry的个数相关,而跟table的大小无关。
有两个参数可以影响LinkedHashMap的性能:初始容量(inital capacity)和负载系数(load factor)。初始容量指定了初始table的大小,负载系数用来指定自动扩容的临界值。当entry的数量超过capacity*load_factor时,容器将自动扩容并重新哈希。对于插入元素较多的场景,将初始容量设大可以减少重新哈希的次数。
将对象放入到LinkedHashMap或LinkedHashSet中时,有两个方法需要特别关心:hashCode()和equals()。hashCode()方法决定了对象会被放到哪个bucket里,当多个对象的哈希值冲突时,equals()方法决定了这些对象是否是“同一个对象”。所以,如果要将自定义的对象放入到LinkedHashMap或LinkedHashSet中,需要*@Override*hashCode()和equals()方法。
通过如下方式可以得到一个跟源Map迭代顺序一样的LinkedHashMap:
void foo(Map m) {
Map copy = new LinkedHashMap(m);
}出于性能原因,LinkedHashMap是非同步的(not synchronized),如果需要在多线程环境使用,需要程序员手动同步;或者通过如下方式将LinkedHashMap包装成(wrapped)同步的:
Map m = Collections.synchronizedMap(new LinkedHashMap(...));
方法剖析
get()
get(<a href="http://www.php.cn/wiki/60.html" target="_blank">Object</a> key)方法根据指定的key值返回对应的value。该方法跟HashMap.get()方法的流程几乎完全一样,读者可自行参考前文,这里不再赘述。
put()
put(K key, V value)方法是将指定的key, value对添加到map里。该方法首先会对map做一次查找,看是否包含该元组,如果已经包含则直接返回,查找过程类似于get()方法;如果没有找到,则会通过addEntry(int hash, K key, V value, int bucketIndex)方法插入新的entry。
注意,这里的插入有两重含义:
从
table的角度看,新的entry需要插入到对应的bucket里,当有哈希冲突时,采用头插法将新的entry插入到冲突链表的头部。从
header的角度看,新的entry需要插入到双向链表的尾部。
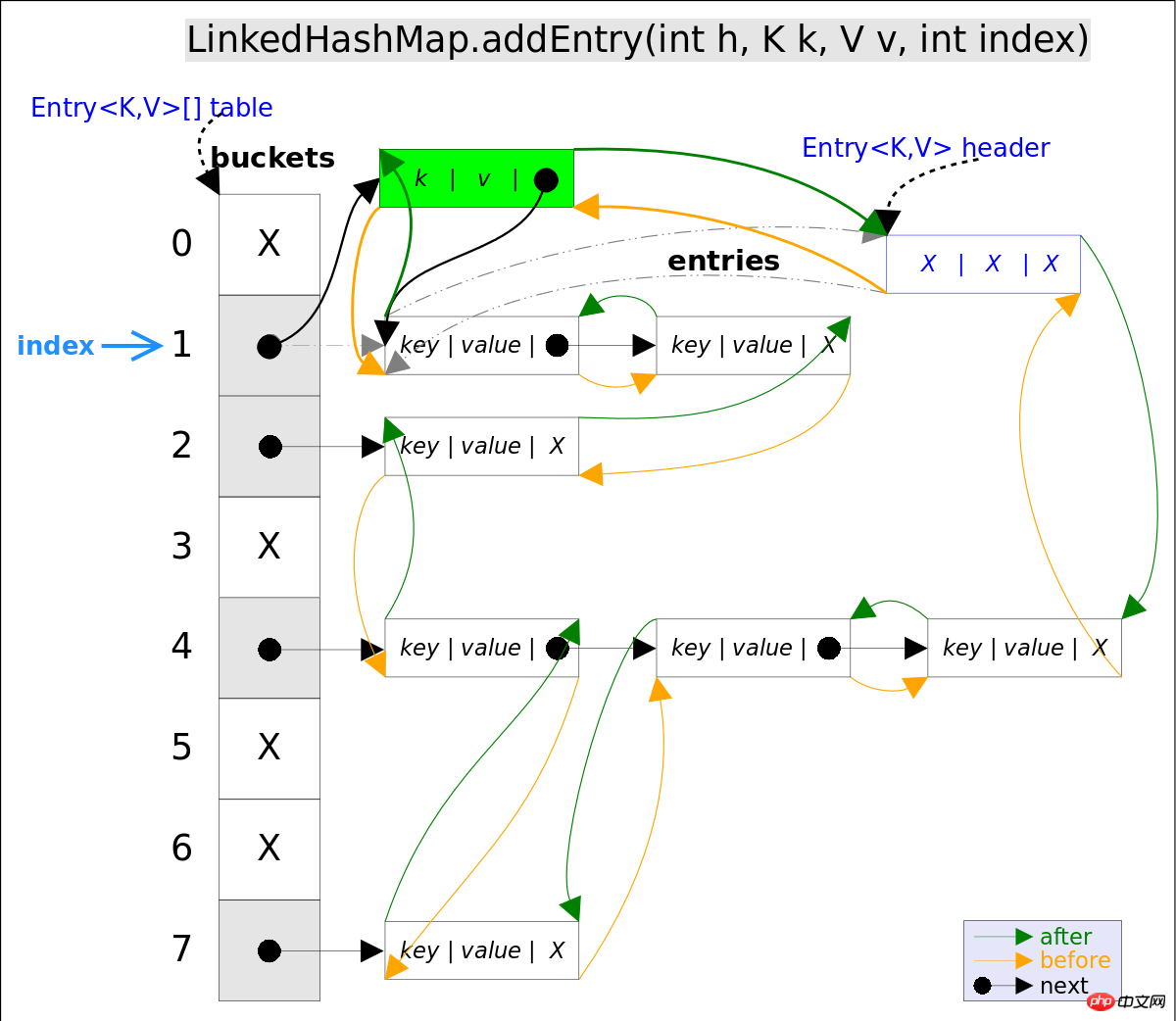
addEntry()代码如下:
// LinkedHashMap.addEntry()
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);// 自动扩容,并重新哈希
hash = (null != key) ? hash(key) : 0;
bucketIndex = hash & (table.length-1);// hash%table.length
}
// 1.在冲突链表头部插入新的entry
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<>(hash, key, value, old);
table[bucketIndex] = e;
// 2.在双向链表的尾部插入新的entry
e.addBefore(header);
size++;
}上述代码中用到了addBefore()方法将新entry e插入到双向链表头引用header的前面,这样e就成为双向链表中的最后一个元素。addBefore()的代码如下:
// LinkedHashMap.Entry.addBefor(),将this插入到existingEntry的前面
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}上述代码只是简单修改相关entry的引用而已。
remove()
remove(Object key)的作用是删除key值对应的entry,该方法的具体逻辑是在removeEntryForKey(Object key)里实现的。removeEntryForKey()方法会首先找到key值对应的entry,然后删除该entry(修改链表的相应引用)。查找过程跟get()方法类似。
注意,这里的删除也有两重含义:
从
table的角度看,需要将该entry从对应的bucket里删除,如果对应的冲突链表不空,需要修改冲突链表的相应引用。从
header的角度来看,需要将该entry从双向链表中删除,同时修改链表中前面以及后面元素的相应引用。

removeEntryForKey()对应的代码如下:
// LinkedHashMap.removeEntryForKey(),删除key值对应的entry
final Entry<K,V> removeEntryForKey(Object key) {
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);// hash&(table.length-1)
Entry<K,V> prev = table[i];// 得到冲突链表
Entry<K,V> e = prev;
while (e != null) {// 遍历冲突链表
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {// 找到要删除的entry
modCount++; size--;
// 1. 将e从对应bucket的冲突链表中删除
if (prev == e) table[i] = next;
else prev.next = next;
// 2. 将e从双向链表中删除
e.before.after = e.after;
e.after.before = e.before;
return e;
}
prev = e; e = next;
}
return e;
}LinkedHashSet
前面已经说过LinkedHashSet是对LinkedHashMap的简单包装,对LinkedHashSet的函数调用都会转换成合适的LinkedHashMap方法,因此LinkedHashSet的实现非常简单,这里不再赘述。
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
// LinkedHashSet里面有一个LinkedHashMap
public LinkedHashSet(int initialCapacity, float loadFactor) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
public boolean add(E e) {//简单的方法转换
return map.put(e, PRESENT)==null;
}
}以上是详解Java集合框架LinkedHashSet和LinkedHashMap源码剖析(图)的详细内容。更多信息请关注PHP中文网其他相关文章!

 在平台独立性的平台独立性上使用字节码优于本机代码的优点是什么?Apr 30, 2025 am 12:24 AM
在平台独立性的平台独立性上使用字节码优于本机代码的优点是什么?Apr 30, 2025 am 12:24 AMByteCodeachievesPlatFormIndenceByByByByByByExecutedBoviratualMachine(VM),允许CodetorunonanyplatformwithTheApprepreprepvm.Forexample,Javabytecodecodecodecodecanrunonanydevicewithajvm
 Java真的100%独立于平台吗?为什么或为什么不呢?Apr 30, 2025 am 12:18 AM
Java真的100%独立于平台吗?为什么或为什么不呢?Apr 30, 2025 am 12:18 AMJava不能做到100%的平台独立性,但其平台独立性通过JVM和字节码实现,确保代码在不同平台上运行。具体实现包括:1.编译成字节码;2.JVM的解释执行;3.标准库的一致性。然而,JVM实现差异、操作系统和硬件差异以及第三方库的兼容性可能影响其平台独立性。
 Java的平台独立性如何支持代码可维护性?Apr 30, 2025 am 12:15 AM
Java的平台独立性如何支持代码可维护性?Apr 30, 2025 am 12:15 AMJava通过“一次编写,到处运行”实现平台独立性,提升代码可维护性:1.代码重用性高,减少重复开发;2.维护成本低,只需一处修改;3.团队协作效率高,方便知识共享。
 为新平台创建JVM面临哪些挑战?Apr 30, 2025 am 12:15 AM
为新平台创建JVM面临哪些挑战?Apr 30, 2025 am 12:15 AM在新平台上创建JVM面临的主要挑战包括硬件兼容性、操作系统兼容性和性能优化。1.硬件兼容性:需要确保JVM能正确使用新平台的处理器指令集,如RISC-V。2.操作系统兼容性:JVM需正确调用新平台的系统API,如Linux。3.性能优化:需进行性能测试和调优,调整垃圾回收策略以适应新平台的内存特性。
 Javafx库如何试图解决GUI开发中的平台不一致?Apr 30, 2025 am 12:01 AM
Javafx库如何试图解决GUI开发中的平台不一致?Apr 30, 2025 am 12:01 AMjavafxeffectife addressEddressEndressInconSiscies uningies uningusing inaplatform-agnosticsCenegraphandCssStyling.1)itabstractsplactsplatsplatsplatsplatformsthercensthascenegenceenceNaSceneGraph,确保ConsistSistEntertRenderingRenderingRenderingRenderingAccomWindows,MacOs,MacOS,MacOS,andlinux.2)
 说明JVM如何充当Java代码和基础操作系统之间的中介。Apr 29, 2025 am 12:23 AM
说明JVM如何充当Java代码和基础操作系统之间的中介。Apr 29, 2025 am 12:23 AMJVM的工作原理是将Java代码转换为机器码并管理资源。1)类加载:加载.class文件到内存。2)运行时数据区:管理内存区域。3)执行引擎:解释或编译执行字节码。4)本地方法接口:通过JNI与操作系统交互。
 解释Java虚拟机(JVM)在Java平台独立性中的作用。Apr 29, 2025 am 12:21 AM
解释Java虚拟机(JVM)在Java平台独立性中的作用。Apr 29, 2025 am 12:21 AMJVM使Java实现跨平台运行。1)JVM加载、验证和执行字节码。2)JVM的工作包括类加载、字节码验证、解释执行和内存管理。3)JVM支持高级功能如动态类加载和反射。
 您将采取哪些步骤来确保Java应用程序在不同的操作系统上正确运行?Apr 29, 2025 am 12:11 AM
您将采取哪些步骤来确保Java应用程序在不同的操作系统上正确运行?Apr 29, 2025 am 12:11 AMJava应用可通过以下步骤在不同操作系统上运行:1)使用File或Paths类处理文件路径;2)通过System.getenv()设置和获取环境变量;3)利用Maven或Gradle管理依赖并测试。Java的跨平台能力依赖于JVM的抽象层,但仍需手动处理某些操作系统特定的功能。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

MinGW - 适用于 Windows 的极简 GNU
这个项目正在迁移到osdn.net/projects/mingw的过程中,你可以继续在那里关注我们。MinGW:GNU编译器集合(GCC)的本地Windows移植版本,可自由分发的导入库和用于构建本地Windows应用程序的头文件;包括对MSVC运行时的扩展,以支持C99功能。MinGW的所有软件都可以在64位Windows平台上运行。

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

禅工作室 13.0.1
功能强大的PHP集成开发环境

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

