



前言
时代变了。
以往数据更多的通过人工录入,从专用网络协议的终端转移到“玻璃房子”里的大铁盒子,现在信息无所不在、无时不在,不过不一定都会汇总到您公司里,很多时候大家是在一个“平”的世界里分享数据,信息来源的渠道多了、信息本身的变化也更加频繁。不仅如此随着Web 2.0、Enterprise 2.0和Internet Service Bus等一系列概念的出现,您发现单单从自己的“玻璃房子”里找供货商提供的仓库地址远不如Google Map方便。
似乎以往桎梏数据的各种枷锁在互联网下被一一打破,但作为IT从业者,我们的工作是为用户提供它们所需的数据和他们希望获取信息的手段,因此应用必须能够经得起各种变化,包括以往我们关心的用户界面的变化、应用间调用的变化、应用内部逻辑的变化,还有步伐越来越快但又是最根本变化——数据自身的变化。
关系模型告诉我们要用二维表格描述信息世界,但这是太“不”自然不过了,看看手边的一本书或是家里的装修计划、马上要开工项目的任务分解,好像套到一个二维表格里总不合适,而且即便通过“实体——关系”生硬的削足适履后,在快速变化的环境下又总是要牵涉到“数据——应用——前端交互”一系列变动,而且经常是牵一发动全身。
似乎很多新一代应用已经找到了更适合新趋势的方案——XML,用一种更贴近我们自己思维的方式组织应用、组织用户体验。那么对于企业而言,组织数据这种相对基础性的工作是否也可以用XML的思维进行呢?应该可以。
应对数据实体自身的变化
数据实体以往总是被假设为应用中最为稳定的部分,无论我们用设计模式还是采用各种开源的开发框架(包括这些框架本身)都是尽量在适应应用本身变化的问题,那么现实的情况如何呢?
l 我们需要交换的数据实体经常要根据自身、合作方的需要变化;
l 合作方给我们的数据实体也常常变化;
l 随着SOA和Enterprise 2.0概念的推出,数据实体本身从多个源mash up出来,同时数据实体本身也被反复的拼装和组合;
l 随着业务的细化,我们自己的员工总是希望获取越来越丰富,同时也越来越详尽的信息;
因此,以往视需求也好、设计也好认为可以最早固定下来的数据实体在愈发敏捷的技术和业务现状前需要不断调整。为了适应这个要求我们可以自顶向下入手,不断调整应用自身的柔性;另一个方式是从“根”上处理这个问题,采用自身就可以不断适应这些变化的新数据模型,例如:XML数据模型和XML相关技术家族。
例如,定义用户实体的时候,最初下面的信息就够了,其中ICustomer是应用会使用的用户接口,而CUSTOMER为关系数据库方式下的表示,
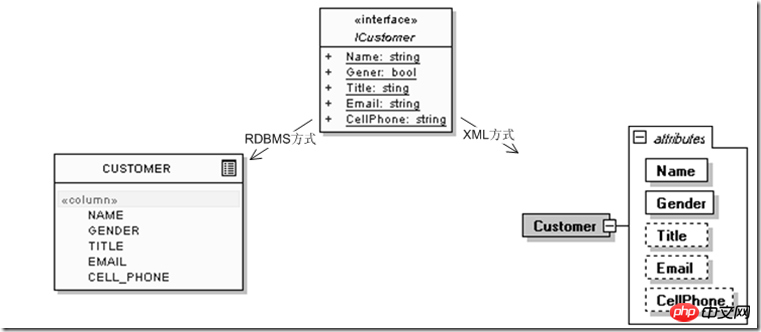
不过紧接着我们就发现这个实体设计有些问题,因为还要增加用户的办公室电话、住宅电话,还有可能1、2个电子邮件,他的MSN或Skype号码等。不考虑其他问题,仅仅从关系模型范1的要求,那么RDBMS和XML两个模型发展的结果就成了:
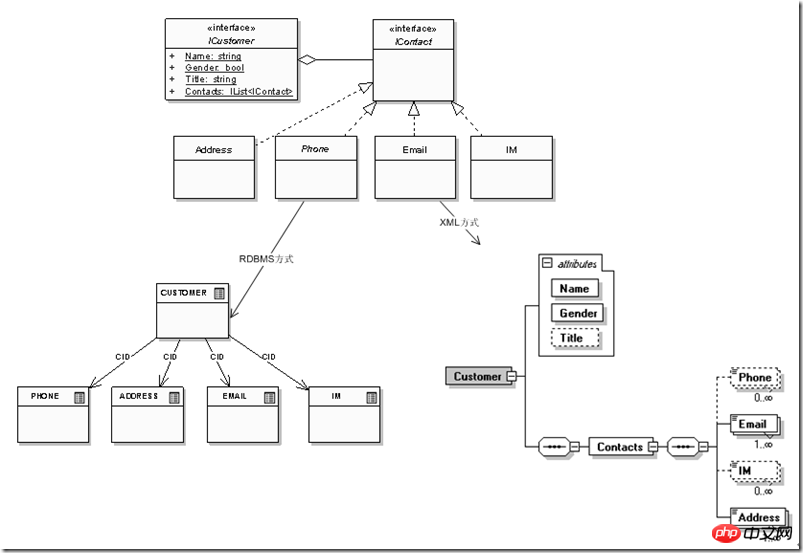
不难看出,虽然仅仅只是“客户”数据实体末节“联系信息”的一个变化,关系模型和XML模型在适应性方面就有非常大的区别,关系模型需要不断扩展出新的关系用来描述不断细化的数据实体,而XML模型自身的层次性可以提供变化条件下,自身的不断延伸和扩展。实际项目中,“学历情况”、“工作经验情况”等信息也存在类似的问题,关系模型下即便某位客户希望把某阶段工作情况的“借调”方式补充进去,也会发现因为设计上没有预留相应的字段,因此只好把它作为字符串“揉”在“工作单位”字段里,后面补充个“(借调)”,这等于僵化的数据模型本身抹杀了数据的业务语义中包括的信息;而层次模型可以把它作为一个子节点或属性来描述,这样不仅可以把关系模型下需要多个关系(客户、学历情况、工作经验、联系信息)集中在一个数据实体内部,而且可以把每个实体自身的扩展信息(例如“工作模式”:借调、交流、短期集中)等也描述在数据实体内部,同时从外部应用看“客户”实体本身依然是一个实体,这样用更贴近现实业务情景的数据实体才能更有效的适应外部变化。
上面我们讨论的仅仅是一个数据实体,进一步发展到具体业务领域模型模型的时候,往往需要同时综合多个数据实体协作完成业务功能,这时候情形又如何呢?比如:保单需要客户提供除了上述信息外的个人健康信息,子女、父母、伴侣家庭主要成员信息,同时会从其他从业机构获取用户的信用信息等,而且不同的数据实体组合主要用于企业内部的各异的应用领域,因此从数据使用角度看为了尽量让应用部分稳定,最好是数据实体稳定,但仅仅用户信息的联系方式部分就可能会反复的变化,如果让应用完全依赖这些变化因素组合后的结果,那么应用的稳定性确实难以保证,那么从源头上第一步先尽量保证不同应用尽量仅依赖于具体一个实体也许是有效改进的第一步,这时候XML的层次特性优势又显示出来了,比如我们可以根据不同的应用主题,自由组合这些信息:
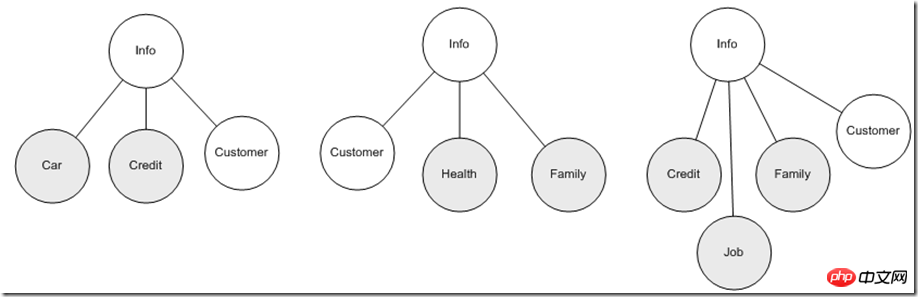
这样应用面对的就是一个统一的
应对数据和内容的集成
上面提的数据实体更多是在一个已经集中后的语境下讨论的,但除了概念上的设计外,使用中还有一个具体的问题就是如何如何把他们“聚集”到一起,这个一般通过数据集成实现。
(不过就像“架构”一词被过度滥用一样,“数据集成”同样被各个厂家根据自己的产品特征被定义成不同概念的组合,比如BI厂商力图把它描绘成ETL的代名词、提供数据交换平台的厂商描述为实现BizTalk Framework的产品、对于SOA产品公司而言,数据集成则更多在于如何保证在有效治理的前提下提供数据服务,另外对于一些厂商而已,数据集成还包括业务语义组合等。)
但作为用户,数据集成我们要着重关心什么问题呢?
l 数据实体的映射关系;
l 数据源的在各种交换协议、行业数据标准、安全控制约束下的互联;
l 数据交换过程的编排;
l 数据实体的验证和重构;
l 数据介质、数据载体的转换;
虽然理论上这些工作用编码完成不成问题,但随着企业集成逻辑越来越复杂且变化越来越快,修改代码即便可以应付一下1:N的集成,但如果经常是M:N的情况,那么就显得力不从心了。是否可以有更简化的办法呢?仅从“映射”的逻辑层次说:
l 面向对象思想告诉我们依赖倒置,要尽量依赖于抽象而不是具体,比如依赖于接口而非实体类型;
l 设计模式告诉我们,不兼容接口间适配器(Adapter)是个不错的途径;
那么数据领域是否也有类似的技术呢?XML Schema + XSLT也许就是个选择。
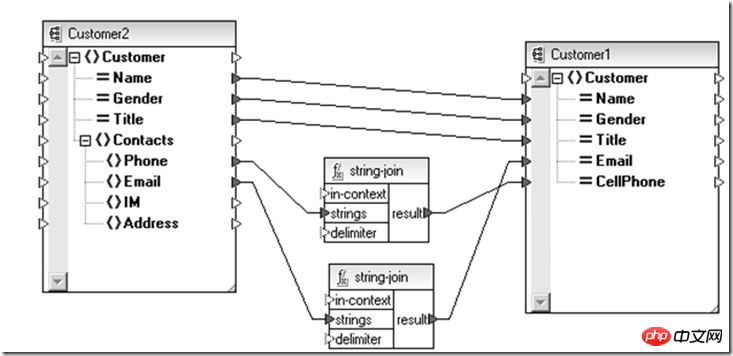
上面是为了兼容新、老用户实体做的转换,同样的如果需要进行上部分针对不同主体的数据实体聚合操作也完全可以借助在抽象数据定义(Schema)层次通过XSLT(Schema间的适配关系)完成。
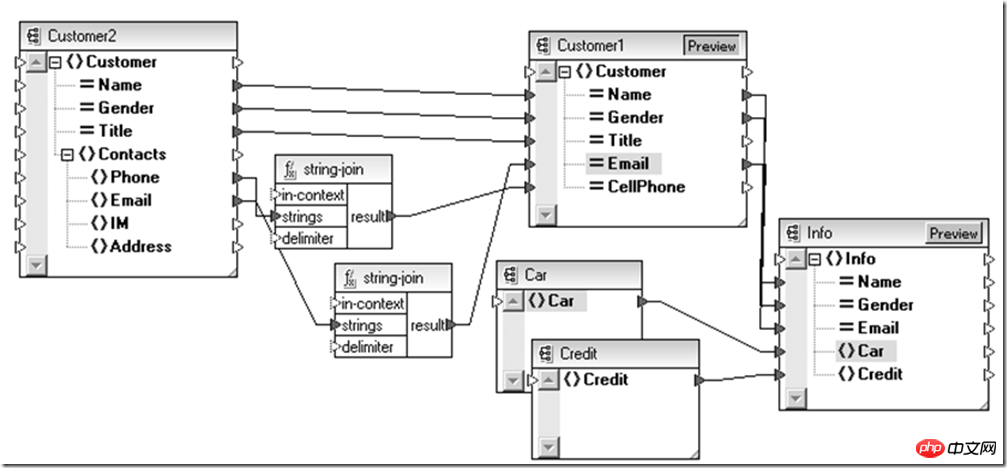
这样,我们可以在数据实体层次看到数据是如何聚合在一起的,但之前还需要解决一个问题:车辆信息、信用信息还有遗留系统的客户信息都是分别保存在关系数据库和合作方的Web Service中,如何连接起这个数据渠道呢?从现在看XML还是不错的选择。
不同数据介质上的数据可以以他们本源的形式提取,比如平文本、关系数据库、EDI报文或者是SOAP消息,通过不同的信息渠道传递到数据集成的汇聚点,然后根据目的数据源的需要,通过一个适配器转换异构的数据源。
这时候如果为每两种类型都设计一个点对点的适配器,整体规模将沿着N^2级的趋势发展,为此不妨先把他们统一为兼容这些信息的XML,然后用上面介绍的XSLT技术进行数据实体间的映射后,接着把XML再转换成目标数据源所需的形式,这样整个适配体系复杂度降为N级。
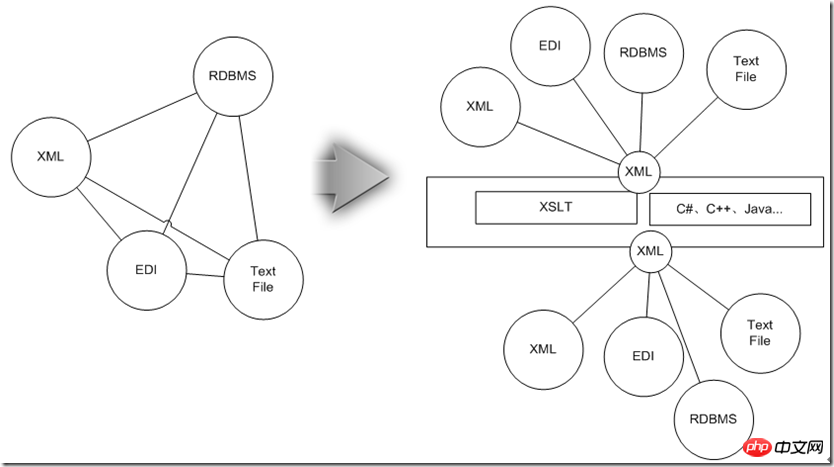
接着,我们看看XML技术如何满足只前提的那些数据集成要求:
l 数据实体的映射、数据介质、数据载体的转换、数据实体的验证和重构:
如上,先把数据统一转换为XML,然后通过XML层次型优势,结合XML专用技术进行处理。
l 数据源的在各种交换协议、行业数据标准、安全控制约束下的互联;
XML数据不仅可以跨越网络、防火墙,而且可以很容易的用于互联网环境(,不过您依然可以用消息队列方式把他们定义为报文),数据本身不会因为特殊的二进制操作需要受到交换协议的限制。当前,各个行业标准基本上都在使用XML描述自己的行业DM(Data Modal),即便您企业内部的系统本身数据实体由于数据库设计、历史遗留等问题,本身不是符合这些DM的数据,但各种XML数据统一治理的协议和标准可以比较方便的实现转换。对于安全性,似乎还有没比基于WS-*相关协议更适合于互联网环境下的安全标准家族,其中所有的标准无一例外都可以用XML实体定义数据和额外安全机制间的组合关系。
l 数据交换过程的编排;
对于同构系统环境,或者是仅仅基于兼容中间件系统的平台,可以采用遗留的工作流机制实现数据交换过程的编排,但为了适应服务化的时代,可以采用更通用的BPEL标准,此时XML不仅仅是数据,同时他也作为执行指令的形态出现,相比较一直标榜跨平台的Java技术而言,采用XML定义的交换过程更是跨语言的。
似乎集成已经解决了很大的问题,但一个显而易见的问题是所有的工作我们可能都要自己做一些实现,一步步告诉应用怎么做,那么当我们不再把Web仅仅当成“新鲜事物”,而把它考虑成一个服务于我们信息内容,并且可以交互的系统时,如何把这些散落的服务能力呈递给我们自己呢?这时候也许XML开放的元数据定义的优势才真正体现出来。
应对语义网络的复杂性
除去各种语义算法以外,如何让分散的各种繁多的服务聚合在一起为我们提供服务,其中XML一个非常关键的因素就是找到数据线索的主干,而且明确这条主干上实体间的关联关系及其逐步分解细化的过程。这个层次的数据不仅是被动由应用调用的对象,他们本身为应用共了进一步推断的支持。例如:
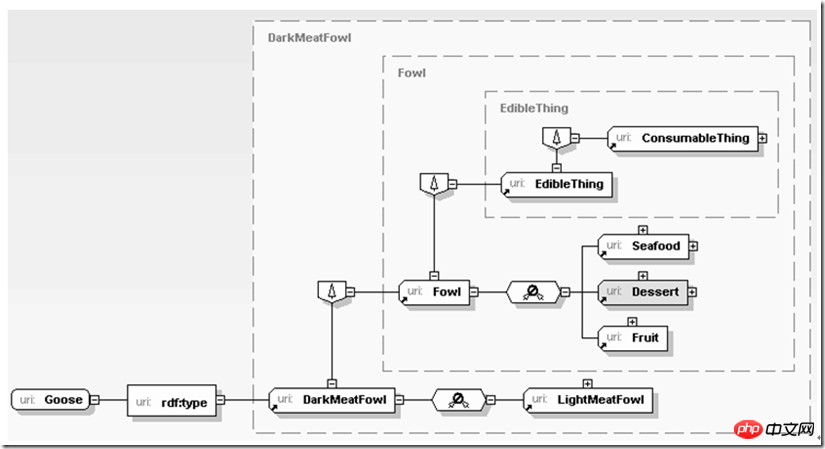
这里首先应用了解到当前处理的这个对象是鹅肉,由于鹅肉是一种黑肉,而黑肉是某种禽肉(fowl),禽肉可以食用,因此应用可以逐步推断鹅肉可以食用。上面的推断过程并不复杂,但如果用关系数据库实现却相对比较复杂,用平文本书写那就更难于实现了,试想一下如果同时把禽肉与蔬菜、甜点、海产品间的关系全部用关系数据库或文本书写,那实在太“难为”应用了。而XML不同,它可以很自然的贴近我们思维的习惯,以一种开放但又交织的办法描述我们熟悉的语义,无论是企业ERP环境的生产材料准备过程,还是为了一次生日Party准备自己下厨的采购计划,亦然。
小结
也许受限于二维格子的约束太久,我们对于应用的设计和想法越来越桎梏于计算机的处理本身,但随着业务环境的变化,从业务需求发生到应用实现并上线的间隔越发短促,我们要更多把自己的思维重新从计算机中抽回来,这时候采用一种更开放并贴近我们发散型思维的数据技术似乎更可取。对于数据落地后的组织,我们可以继续采用各种成熟的技术完成,但在更贴近业务的层面、贴近这种更易变的环境下,似乎XML柔性和力道都不错。
以上是详细介绍使用XML化的思维组织数据(图)的详细内容。更多信息请关注PHP中文网其他相关文章!

 RSS文档格式:探索RSS 2.0及以后Apr 26, 2025 am 12:22 AM
RSS文档格式:探索RSS 2.0及以后Apr 26, 2025 am 12:22 AMRSS2.0是一种开放标准,允许内容发布者以结构化的方式分发内容。它包含了丰富的元数据,如标题、链接、描述、发布日期等,使得订阅者能够快速浏览和访问内容。RSS2.0的优势在于其简洁和扩展性。例如,它允许自定义元素,这意味着开发者可以根据需求添加额外的信息,如作者、分类等。
 理解RSS:XML观点Apr 25, 2025 am 12:14 AM
理解RSS:XML观点Apr 25, 2025 am 12:14 AMRSS是一种基于XML的格式,用于发布经常更新的内容。1.RSSfeed通过XML结构化组织信息,包括标题、链接、描述等。2.创建RSSfeed需按照XML结构编写,添加元数据如语言和发布日期。3.高级用法可包含多媒体文件和分类信息。4.调试时使用XML验证工具,确保必需元素存在且编码正确。5.优化RSSfeed可通过分页、缓存和保持结构简洁来实现。通过理解和应用这些知识,可以有效管理和分发内容。
 XML中的RSS:解码标签,属性和结构Apr 24, 2025 am 12:09 AM
XML中的RSS:解码标签,属性和结构Apr 24, 2025 am 12:09 AMRSS是一种基于XML的格式,用于发布和订阅内容。RSS文件的XML结构包括根元素、元素和多个元素,每个代表一个内容条目。通过XML解析器读取和解析RSS文件,用户可以订阅并获取最新内容。
 XML在RSS中的优势:技术深度潜水Apr 23, 2025 am 12:02 AM
XML在RSS中的优势:技术深度潜水Apr 23, 2025 am 12:02 AMXML在RSS中具有结构化数据、可扩展性、跨平台兼容性和解析验证的优势。1)结构化数据确保内容的一致性和可靠性;2)可扩展性允许添加自定义标签以适应内容需求;3)跨平台兼容性使其在不同设备上无缝工作;4)解析和验证工具确保Feed的质量和完整性。
 XML中的RSS:揭示内容联合的核心Apr 22, 2025 am 12:08 AM
XML中的RSS:揭示内容联合的核心Apr 22, 2025 am 12:08 AMRSS在XML中的实现方式是通过结构化的XML格式来组织内容。1)RSS使用XML作为数据交换格式,包含频道信息和项目列表等元素。2)生成RSS文件需按规范组织内容,发布到服务器供订阅。3)RSS文件可通过阅读器或插件订阅,实现内容自动更新。
 超越基础:高级RSS文档功能Apr 21, 2025 am 12:03 AM
超越基础:高级RSS文档功能Apr 21, 2025 am 12:03 AMRSS的高级功能包括内容命名空间、扩展模块和条件订阅。1)内容命名空间扩展RSS功能,2)扩展模块如DublinCore或iTunes添加元数据,3)条件订阅根据特定条件筛选条目。这些功能通过添加XML元素和属性实现,提升信息获取效率。
 XML主链:RSS提要如何结构Apr 20, 2025 am 12:02 AM
XML主链:RSS提要如何结构Apr 20, 2025 am 12:02 AMrssfeedsusexmltoStructureContentUpdates.1)xmlProvidesHierarchicalStructurefordata.2)theelementDefinestHefEed'sIdentityAndContainsElements.3)ElementsRementsRementsRepresSentividividividualContentpieces.4)rsssissisexisextensible,允许custemements.5)5)
 RSS和XML:了解Web内容的动态二重奏Apr 19, 2025 am 12:03 AM
RSS和XML:了解Web内容的动态二重奏Apr 19, 2025 am 12:03 AMRSS和XML是用于网络内容管理的工具。RSS用于发布和订阅内容,XML用于存储和传输数据。它们的工作原理包括内容发布、订阅和更新推送。使用示例包括RSS发布博客文章和XML存储书籍信息。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

SublimeText3 Linux新版
SublimeText3 Linux最新版

MinGW - 适用于 Windows 的极简 GNU
这个项目正在迁移到osdn.net/projects/mingw的过程中,你可以继续在那里关注我们。MinGW:GNU编译器集合(GCC)的本地Windows移植版本,可自由分发的导入库和用于构建本地Windows应用程序的头文件;包括对MSVC运行时的扩展,以支持C99功能。MinGW的所有软件都可以在64位Windows平台上运行。

Atom编辑器mac版下载
最流行的的开源编辑器

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

