



关键字:Java解析xml、解析xml四种方法、DOM、SAX、JDOM、DOM4j、XPath
【引言】
目前在Java中用于解析XML的技术很多,主流的有DOM、SAX、JDOM、DOM4j,下文主要介绍这4种解析XML文档技术的使用、优缺点及性能测试。
一、【基础知识——扫盲】
sax、dom是两种对xml文档进行解析的方法(没有具体实现,只是接口),所以只有它们是无法解析xml文档的;jaxp只是api,它进一步封装了sax、dom两种接口,并且提供了DomcumentBuilderFactory/DomcumentBuilder和SAXParserFactory/SAXParser(默认使用xerces解释器)。
二、【DOM、SAX、JDOM、DOM4j简单使用介绍】
1、【DOM(Document Object Model) 】
由W3C提供的接口,它将整个XML文档读入内存,构建一个DOM树来对各个节点(Node)进行操作。
示例代码:
<?xml version="1.0" encoding="UTF-8"?>
<university name="pku">
<college name="c1">
<class name="class1">
<student name="stu1" sex='male' age="21" />
<student name="stu2" sex='female' age="20" />
<student name="stu3" sex='female' age="20" />
</class>
<class name="class2">
<student name="stu4" sex='male' age="19" />
<student name="stu5" sex='female' age="20" />
<student name="stu6" sex='female' age="21" />
</class>
</college>
<college name="c2">
<class name="class3">
<student name="stu7" sex='male' age="20" />
</class>
</college>
<college name="c3">
</college>
</university>后文代码中有使用到text.xml(该文档放在src路径下,既编译后在classes路径下),都是指该xml文档。
package test.xml;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.w3c.dom.Text;
import org.xml.sax.SAXException;
/**
* dom读写xml
* @author whwang
*/
public class TestDom {
public static void main(String[] args) {
read();
//write();
}
public static void read() {
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
try {
DocumentBuilder builder = dbf.newDocumentBuilder();
InputStream in = TestDom.class.getClassLoader().getResourceAsStream("test.xml");
Document doc = builder.parse(in);
// root <university>
Element root = doc.getDocumentElement();
if (root == null) return;
System.err.println(root.getAttribute("name"));
// all college node
NodeList collegeNodes = root.getChildNodes();
if (collegeNodes == null) return;
for(int i = 0; i < collegeNodes.getLength(); i++) {
Node college = collegeNodes.item(i);
if (college != null && college.getNodeType() == Node.ELEMENT_NODE) {
System.err.println("\t" + college.getAttributes().getNamedItem("name").getNodeValue());
// all class node
NodeList classNodes = college.getChildNodes();
if (classNodes == null) continue;
for (int j = 0; j < classNodes.getLength(); j++) {
Node clazz = classNodes.item(j);
if (clazz != null && clazz.getNodeType() == Node.ELEMENT_NODE) {
System.err.println("\t\t" + clazz.getAttributes().getNamedItem("name").getNodeValue());
// all student node
NodeList studentNodes = clazz.getChildNodes();
if (studentNodes == null) continue;
for (int k = 0; k < studentNodes.getLength(); k++) {
Node student = studentNodes.item(k);
if (student != null && student.getNodeType() == Node.ELEMENT_NODE) {
System.err.print("\t\t\t" + student.getAttributes().getNamedItem("name").getNodeValue());
System.err.print(" " + student.getAttributes().getNamedItem("sex").getNodeValue());
System.err.println(" " + student.getAttributes().getNamedItem("age").getNodeValue());
}
}
}
}
}
}
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void write() {
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
try {
DocumentBuilder builder = dbf.newDocumentBuilder();
InputStream in = TestDom.class.getClassLoader().getResourceAsStream("test.xml");
Document doc = builder.parse(in);
// root <university>
Element root = doc.getDocumentElement();
if (root == null) return;
// 修改属性
root.setAttribute("name", "tsu");
NodeList collegeNodes = root.getChildNodes();
if (collegeNodes != null) {
for (int i = 0; i <collegeNodes.getLength() - 1; i++) {
// 删除节点
Node college = collegeNodes.item(i);
if (college.getNodeType() == Node.ELEMENT_NODE) {
String collegeName = college.getAttributes().getNamedItem("name").getNodeValue();
if ("c1".equals(collegeName) || "c2".equals(collegeName)) {
root.removeChild(college);
} else if ("c3".equals(collegeName)) {
Element newChild = doc.createElement("class");
newChild.setAttribute("name", "c4");
college.appendChild(newChild);
}
}
}
}
// 新增节点
Element addCollege = doc.createElement("college");
addCollege.setAttribute("name", "c5");
root.appendChild(addCollege);
Text text = doc.createTextNode("text");
addCollege.appendChild(text);
// 将修改后的文档保存到文件
TransformerFactory transFactory = TransformerFactory.newInstance();
Transformer transFormer = transFactory.newTransformer();
DOMSource domSource = new DOMSource(doc);
File file = new File("src/dom-modify.xml");
if (file.exists()) {
file.delete();
}
file.createNewFile();
FileOutputStream out = new FileOutputStream(file);
StreamResult xmlResult = new StreamResult(out);
transFormer.transform(domSource, xmlResult);
System.out.println(file.getAbsolutePath());
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (TransformerConfigurationException e) {
e.printStackTrace();
} catch (TransformerException e) {
e.printStackTrace();
}
}
}
该代码只要稍做修改,即可变得更加简洁,无需一直写if来判断是否有子节点。
2、【SAX (Simple API for XML) 】
SAX不用将整个文档加载到内存,基于事件驱动的API(Observer模式),用户只需要注册自己感兴趣的事件即可。SAX提供EntityResolver, DTDHandler, ContentHandler, ErrorHandler接口,分别用于监听解析实体事件、DTD处理事件、正文处理事件和处理出错事件,与AWT类似,SAX还提供了一个对这4个接口默认的类DefaultHandler(这里的默认实现,其实就是一个空方法),一般只要继承DefaultHandler,重写自己感兴趣的事件即可。
示例代码:
package test.xml;
import java.io.IOException;
import java.io.InputStream;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.InputSource;
import org.xml.sax.Locator;
import org.xml.sax.SAXException;
import org.xml.sax.SAXParseException;
import org.xml.sax.helpers.DefaultHandler;
/**
*
* @author whwang
*/
public class TestSAX {
public static void main(String[] args) {
read();
write();
}
public static void read() {
try {
SAXParserFactory factory = SAXParserFactory.newInstance();
SAXParser parser = factory.newSAXParser();
InputStream in = TestSAX.class.getClassLoader().getResourceAsStream("test.xml");
parser.parse(in, new MyHandler());
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void write() {
System.err.println("纯SAX对于写操作无能为力");
}
}
// 重写对自己感兴趣的事件处理方法
class MyHandler extends DefaultHandler {
@Override
public InputSource resolveEntity(String publicId, String systemId)
throws IOException, SAXException {
return super.resolveEntity(publicId, systemId);
}
@Override
public void notationDecl(String name, String publicId, String systemId)
throws SAXException {
super.notationDecl(name, publicId, systemId);
}
@Override
public void unparsedEntityDecl(String name, String publicId,
String systemId, String notationName) throws SAXException {
super.unparsedEntityDecl(name, publicId, systemId, notationName);
}
@Override
public void setDocumentLocator(Locator locator) {
super.setDocumentLocator(locator);
}
@Override
public void startDocument() throws SAXException {
System.err.println("开始解析文档");
}
@Override
public void endDocument() throws SAXException {
System.err.println("解析结束");
}
@Override
public void startPrefixMapping(String prefix, String uri)
throws SAXException {
super.startPrefixMapping(prefix, uri);
}
@Override
public void endPrefixMapping(String prefix) throws SAXException {
super.endPrefixMapping(prefix);
}
@Override
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
System.err.print("Element: " + qName + ", attr: ");
print(attributes);
}
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
super.endElement(uri, localName, qName);
}
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
super.characters(ch, start, length);
}
@Override
public void ignorableWhitespace(char[] ch, int start, int length)
throws SAXException {
super.ignorableWhitespace(ch, start, length);
}
@Override
public void processingInstruction(String target, String data)
throws SAXException {
super.processingInstruction(target, data);
}
@Override
public void skippedEntity(String name) throws SAXException {
super.skippedEntity(name);
}
@Override
public void warning(SAXParseException e) throws SAXException {
super.warning(e);
}
@Override
public void error(SAXParseException e) throws SAXException {
super.error(e);
}
@Override
public void fatalError(SAXParseException e) throws SAXException {
super.fatalError(e);
}
private void print(Attributes attrs) {
if (attrs == null) return;
System.err.print("[");
for (int i = 0; i < attrs.getLength(); i++) {
System.err.print(attrs.getQName(i) + " = " + attrs.getValue(i));
if (i != attrs.getLength() - 1) {
System.err.print(", ");
}
}
System.err.println("]");
}
}3、【JDOM】
JDOM与DOM非常类似,它是处理XML的纯JAVA API,API大量使用了Collections类,且JDOM仅使用具体类而不使用接口。 JDOM 它自身不包含解析器。它通常使用 SAX2 解析器来解析和验证输入 XML 文档(尽管它还可以将以前构造的 DOM 表示作为输入)。它包含一些转换器以将 JDOM 表示输出成 SAX2 事件流、DOM 模型或 XML 文本文档
示例代码:
package test.xml;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.List;
import org.jdom.Attribute;
import org.jdom.Document;
import org.jdom.Element;
import org.jdom.JDOMException;
import org.jdom.input.SAXBuilder;
import org.jdom.output.XMLOutputter;
/**
* JDom读写xml
* @author whwang
*/
public class TestJDom {
public static void main(String[] args) {
//read();
write();
}
public static void read() {
try {
boolean validate = false;
SAXBuilder builder = new SAXBuilder(validate);
InputStream in = TestJDom.class.getClassLoader().getResourceAsStream("test.xml");
Document doc = builder.build(in);
// 获取根节点 <university>
Element root = doc.getRootElement();
readNode(root, "");
} catch (JDOMException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
@SuppressWarnings("unchecked")
public static void readNode(Element root, String prefix) {
if (root == null) return;
// 获取属性
List<Attribute> attrs = root.getAttributes();
if (attrs != null && attrs.size() > 0) {
System.err.print(prefix);
for (Attribute attr : attrs) {
System.err.print(attr.getValue() + " ");
}
System.err.println();
}
// 获取他的子节点
List<Element> childNodes = root.getChildren();
prefix += "\t";
for (Element e : childNodes) {
readNode(e, prefix);
}
}
public static void write() {
boolean validate = false;
try {
SAXBuilder builder = new SAXBuilder(validate);
InputStream in = TestJDom.class.getClassLoader().getResourceAsStream("test.xml");
Document doc = builder.build(in);
// 获取根节点 <university>
Element root = doc.getRootElement();
// 修改属性
root.setAttribute("name", "tsu");
// 删除
boolean isRemoved = root.removeChildren("college");
System.err.println(isRemoved);
// 新增
Element newCollege = new Element("college");
newCollege.setAttribute("name", "new_college");
Element newClass = new Element("class");
newClass.setAttribute("name", "ccccc");
newCollege.addContent(newClass);
root.addContent(newCollege);
XMLOutputter out = new XMLOutputter();
File file = new File("src/jdom-modify.xml");
if (file.exists()) {
file.delete();
}
file.createNewFile();
FileOutputStream fos = new FileOutputStream(file);
out.output(doc, fos);
} catch (JDOMException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}4、【DOM4j】
dom4j是目前在xml解析方面是最优秀的(Hibernate、Sun的JAXM也都使用dom4j来解析XML),它合并了许多超出基本 XML 文档表示的功能,包括集成的 XPath 支持、XML Schema 支持以及用于大文档或流化文档的基于事件的处理
示例代码:
package test.xml;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStream;
import java.util.List;
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.ProcessingInstruction;
import org.dom4j.VisitorSupport;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
/**
* Dom4j读写xml
* @author whwang
*/
public class TestDom4j {
public static void main(String[] args) {
read1();
//read2();
//write();
}
public static void read1() {
try {
SAXReader reader = new SAXReader();
InputStream in = TestDom4j.class.getClassLoader().getResourceAsStream("test.xml");
Document doc = reader.read(in);
Element root = doc.getRootElement();
readNode(root, "");
} catch (DocumentException e) {
e.printStackTrace();
}
}
@SuppressWarnings("unchecked")
public static void readNode(Element root, String prefix) {
if (root == null) return;
// 获取属性
List<Attribute> attrs = root.attributes();
if (attrs != null && attrs.size() > 0) {
System.err.print(prefix);
for (Attribute attr : attrs) {
System.err.print(attr.getValue() + " ");
}
System.err.println();
}
// 获取他的子节点
List<Element> childNodes = root.elements();
prefix += "\t";
for (Element e : childNodes) {
readNode(e, prefix);
}
}
public static void read2() {
try {
SAXReader reader = new SAXReader();
InputStream in = TestDom4j.class.getClassLoader().getResourceAsStream("test.xml");
Document doc = reader.read(in);
doc.accept(new MyVistor());
} catch (DocumentException e) {
e.printStackTrace();
}
}
public static void write() {
try {
// 创建一个xml文档
Document doc = DocumentHelper.createDocument();
Element university = doc.addElement("university");
university.addAttribute("name", "tsu");
// 注释
university.addComment("这个是根节点");
Element college = university.addElement("college");
college.addAttribute("name", "cccccc");
college.setText("text");
File file = new File("src/dom4j-modify.xml");
if (file.exists()) {
file.delete();
}
file.createNewFile();
XMLWriter out = new XMLWriter(new FileWriter(file));
out.write(doc);
out.flush();
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
class MyVistor extends VisitorSupport {
public void visit(Attribute node) {
System.out.println("Attibute: " + node.getName() + "="
+ node.getValue());
}
public void visit(Element node) {
if (node.isTextOnly()) {
System.out.println("Element: " + node.getName() + "="
+ node.getText());
} else {
System.out.println(node.getName());
}
}
@Override
public void visit(ProcessingInstruction node) {
System.out.println("PI:" + node.getTarget() + " " + node.getText());
}
}
三、【性能测试】
环境:AMD4400+ 2.0+GHz主频 JDK6.0
运行参数:-Xms400m -Xmx400m
xml文件大小:10.7M
结果:
DOM: >581297ms
SAX: 8829ms
JDOM: 581297ms
DOM4j: 5309ms
时间包括IO的,只是进行了简单的测试,仅供参考!!!!
四、【对比】
1、【DOM】
DOM是基于树的结构,通常需要加载整文档和构造DOM树,然后才能开始工作。
优点:
a、由于整棵树在内存中,因此可以对xml文档随机访问
b、可以对xml文档进行修改操作
c、较sax,dom使用也更简单。
缺点:
a、整个文档必须一次性解析完
a、由于整个文档都需要载入内存,对于大文档成本高
2、【SAX】
SAX类似流媒体,它基于事件驱动的,因此无需将整个文档载入内存,使用者只需要监听自己感兴趣的事件即可。
优点:
a、无需将整个xml文档载入内存,因此消耗内存少
b、可以注册多个ContentHandler
缺点:
a、不能随机的访问xml中的节点
b、不能修改文档
3、【JDOM】
JDOM是纯Java的处理XML的API,其API中大量使用Collections类,
优点:
a、DOM方式的优点
b、具有SAX的Java规则
缺点
a、DOM方式的缺点
4、【DOM4J】
这4中xml解析方式中,最优秀的一个,集易用和性能于一身。
五、【小插曲XPath】
XPath 是一门在 XML 文档中查找信息的语言, 可用来在 XML 文档中对元素和属性进行遍历。XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 同时被构建于 XPath 表达之上。因此,对 XPath 的理解是很多高级 XML 应用的基础。
XPath非常类似对数据库操作的SQL语言,或者说JQuery,它可以方便开发者抓起文档中需要的东西。(dom4j也支持xpath)
示例代码:
package test.xml;
import java.io.IOException;
import java.io.InputStream;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.xpath.XPath;
import javax.xml.xpath.XPathConstants;
import javax.xml.xpath.XPathExpression;
import javax.xml.xpath.XPathExpressionException;
import javax.xml.xpath.XPathFactory;
import org.w3c.dom.Document;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
public class TestXPath {
public static void main(String[] args) {
read();
}
public static void read() {
try {
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = dbf.newDocumentBuilder();
InputStream in = TestXPath.class.getClassLoader().getResourceAsStream("test.xml");
Document doc = builder.parse(in);
XPathFactory factory = XPathFactory.newInstance();
XPath xpath = factory.newXPath();
// 选取所有class元素的name属性
// XPath语法介绍: http://w3school.com.cn/xpath/
XPathExpression expr = xpath.compile("//class/@name");
NodeList nodes = (NodeList) expr.evaluate(doc, XPathConstants.NODESET);
for (int i = 0; i < nodes.getLength(); i++) {
System.out.println("name = " + nodes.item(i).getNodeValue());
}
} catch (XPathExpressionException e) {
e.printStackTrace();
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
六、【补充】
注意4种解析方法对TextNode(文本节点)的处理:
1、在使用DOM时,调用node.getChildNodes()获取该节点的子节点,文本节点也会被当作一个Node来返回,如:
<?xml version="1.0" encoding="UTF-8"?>
<university name="pku">
<college name="c1">
<class name="class1">
<student name="stu1" sex='male' age="21" />
<student name="stu2" sex='female' age="20" />
<student name="stu3" sex='female' age="20" />
</class>
</college>
</university>package test.xml;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
import java.util.Arrays;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
/**
* dom读写xml
* @author whwang
*/
public class TestDom2 {
public static void main(String[] args) {
read();
}
public static void read() {
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
try {
DocumentBuilder builder = dbf.newDocumentBuilder();
InputStream in = TestDom2.class.getClassLoader().getResourceAsStream("test.xml");
Document doc = builder.parse(in);
// root <university>
Element root = doc.getDocumentElement();
if (root == null) return;
// System.err.println(root.getAttribute("name"));
// all college node
NodeList collegeNodes = root.getChildNodes();
if (collegeNodes == null) return;
System.err.println("university子节点数:" + collegeNodes.getLength());
System.err.println("子节点如下:");
for(int i = 0; i < collegeNodes.getLength(); i++) {
Node college = collegeNodes.item(i);
if (college == null) continue;
if (college.getNodeType() == Node.ELEMENT_NODE) {
System.err.println("\t元素节点:" + college.getNodeName());
} else if (college.getNodeType() == Node.TEXT_NODE) {
System.err.println("\t文本节点:" + Arrays.toString(college.getTextContent().getBytes()));
}
}
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
输出的结果是:
university子节点数:3
子节点如下:
文本节点:[10, 9]
元素节点:college
文本节点:[10]其中\n的ASCII码为10,\t的ASCII码为9。结果让人大吃一惊,university的子节点数不是1,也不是2,而是3,这3个子节点都是谁呢?为了看得更清楚点,把xml文档改为:
<?xml version="1.0" encoding="UTF-8"?>
<university name="pku">11
<college name="c1">
<class name="class1">
<student name="stu1" sex='male' age="21" />
<student name="stu2" sex='female' age="20" />
<student name="stu3" sex='female' age="20" />
</class>
</college>22
</university>还是上面的程序,输出结果为:
university子节点数:3
子节点如下:
文本节点:[49, 49, 10, 9]
元素节点:college
文本节点:[50, 50, 10]
其中数字1的ASCII码为49,数字2的ASCII码为50。
2、使用SAX来解析同DOM,当你重写它的public void characters(char[] ch, int start, int length)方法时,你就能看到。
3、JDOM,调用node.getChildren()只返回子节点,不包括TextNode节点(不管该节点是否有Text信息)。如果要获取该节点的Text信息,可以调用node.getText()方法,该方法返回节点的Text信息,也包括\n\t等特殊字符。
4、DOM4j同JDOM
以上是详细介绍解析Xml四种方法的示例代码的详细内容。更多信息请关注PHP中文网其他相关文章!

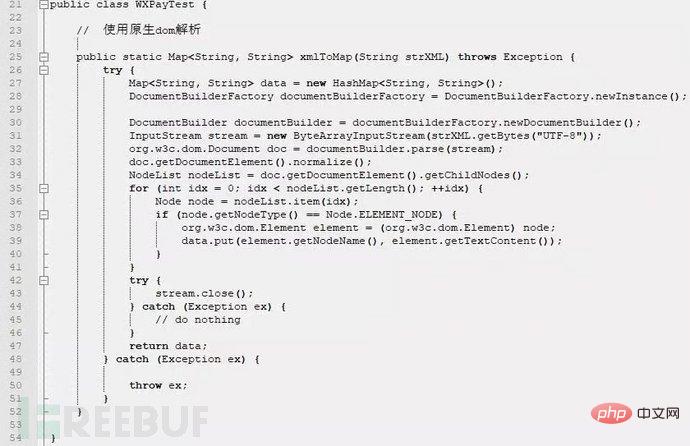 XML外部实体注入漏洞的示例分析May 11, 2023 pm 04:55 PM
XML外部实体注入漏洞的示例分析May 11, 2023 pm 04:55 PM一、XML外部实体注入XML外部实体注入漏洞也就是我们常说的XXE漏洞。XML作为一种使用较为广泛的数据传输格式,很多应用程序都包含有处理xml数据的代码,默认情况下,许多过时的或配置不当的XML处理器都会对外部实体进行引用。如果攻击者可以上传XML文档或者在XML文档中添加恶意内容,通过易受攻击的代码、依赖项或集成,就能够攻击包含缺陷的XML处理器。XXE漏洞的出现和开发语言无关,只要是应用程序中对xml数据做了解析,而这些数据又受用户控制,那么应用程序都可能受到XXE攻击。本篇文章以java
 如何用PHP和XML实现网站的分页和导航Jul 28, 2023 pm 12:31 PM
如何用PHP和XML实现网站的分页和导航Jul 28, 2023 pm 12:31 PM如何用PHP和XML实现网站的分页和导航导言:在开发一个网站时,分页和导航功能是很常见的需求。本文将介绍如何使用PHP和XML来实现网站的分页和导航功能。我们会先讨论分页的实现,然后再介绍导航的实现。一、分页的实现准备工作在开始实现分页之前,需要准备一个XML文件,用来存储网站的内容。XML文件的结构如下:<articles><art
 php如何将xml转为json格式?3种方法分享Mar 22, 2023 am 10:38 AM
php如何将xml转为json格式?3种方法分享Mar 22, 2023 am 10:38 AM当我们处理数据时经常会遇到将XML格式转换为JSON格式的需求。PHP有许多内置函数可以帮助我们执行这个操作。在本文中,我们将讨论将XML格式转换为JSON格式的不同方法。
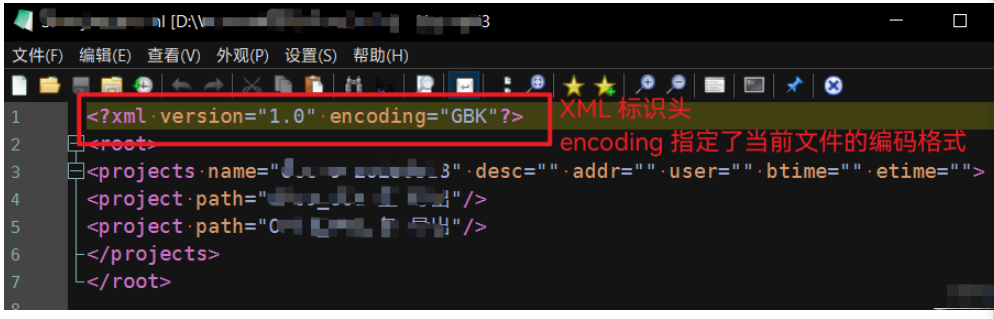 Python中怎么对XML文件的编码进行转换May 21, 2023 pm 12:22 PM
Python中怎么对XML文件的编码进行转换May 21, 2023 pm 12:22 PM1.在Python中XML文件的编码问题1.Python使用的xml.etree.ElementTree库只支持解析和生成标准的UTF-8格式的编码2.常见GBK或GB2312等中文编码的XML文件,用以在老旧系统中保证XML对中文字符的记录能力3.XML文件开头有标识头,标识头指定了程序处理XML时应该使用的编码4.要修改编码,不仅要修改文件整体的编码,还要将标识头中encoding部分的值修改2.处理PythonXML文件的思路1.读取&解码:使用二进制模式读取XML文件,将文件变为
 使用nmap-converter将nmap扫描结果XML转化为XLS实战的示例分析May 17, 2023 pm 01:04 PM
使用nmap-converter将nmap扫描结果XML转化为XLS实战的示例分析May 17, 2023 pm 01:04 PM使用nmap-converter将nmap扫描结果XML转化为XLS实战1、前言作为网络安全从业人员,有时候需要使用端口扫描利器nmap进行大批量端口扫描,但Nmap的输出结果为.nmap、.xml和.gnmap三种格式,还有夹杂很多不需要的信息,处理起来十分不方便,而将输出结果转换为Excel表格,方面处理后期输出。因此,有技术大牛分享了将nmap报告转换为XLS的Python脚本。2、nmap-converter1)项目地址:https://github.com/mrschyte/nmap-
 Python中xmltodict对xml的操作方式是什么May 04, 2023 pm 06:04 PM
Python中xmltodict对xml的操作方式是什么May 04, 2023 pm 06:04 PMPythonxmltodict对xml的操作xmltodict是另一个简易的库,它致力于将XML变得像JSON.下面是一个简单的示例XML文件:elementsmoreelementselementaswell这是第三方包,在处理前先用pip来安装pipinstallxmltodict可以像下面这样访问里面的元素,属性及值:importxmltodictwithopen("test.xml")asfd:#将XML文件装载到dict里面doc=xmltodict.parse(f
 xml中node和element的区别是什么Apr 19, 2022 pm 06:06 PM
xml中node和element的区别是什么Apr 19, 2022 pm 06:06 PMxml中node和element的区别是:Element是元素,是一个小范围的定义,是数据的组成部分之一,必须是包含完整信息的结点才是元素;而Node是节点,是相对于TREE数据结构而言的,一个结点不一定是一个元素,一个元素一定是一个结点。
 深度使用Scrapy:如何爬取HTML、XML、JSON数据?Jun 22, 2023 pm 05:58 PM
深度使用Scrapy:如何爬取HTML、XML、JSON数据?Jun 22, 2023 pm 05:58 PMScrapy是一款强大的Python爬虫框架,可以帮助我们快速、灵活地获取互联网上的数据。在实际爬取过程中,我们会经常遇到HTML、XML、JSON等各种数据格式。在这篇文章中,我们将介绍如何使用Scrapy分别爬取这三种数据格式的方法。一、爬取HTML数据创建Scrapy项目首先,我们需要创建一个Scrapy项目。打开命令行,输入以下命令:scrapys


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

PhpStorm Mac 版本
最新(2018.2.1 )专业的PHP集成开发工具

WebStorm Mac版
好用的JavaScript开发工具

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

MinGW - 适用于 Windows 的极简 GNU
这个项目正在迁移到osdn.net/projects/mingw的过程中,你可以继续在那里关注我们。MinGW:GNU编译器集合(GCC)的本地Windows移植版本,可自由分发的导入库和用于构建本地Windows应用程序的头文件;包括对MSVC运行时的扩展,以支持C99功能。MinGW的所有软件都可以在64位Windows平台上运行。

