


前同天和同事在讨论xml里的encoding属性和文件格式的关系,终于彻底的弄清楚了。
以前理解的是,xml里的encoding里定义必须与文件格式相匹配。即有这样的xml Introduction,那么,文件格式必须是一个utf-8文件,即文件的前两个字节要是一个utf-8头FF FE。(后来才弄清楚,FF FE不是utf-8的BOM。。就是说我的错误理解持续了相当长一段时间。。)
下面把讨论的几个阶段大概说一下。
刚开始讨论时,我很肯定的告诉他,encoding的值必须和文件格式(即BOM,BOM就是 byte order mark的缩写)相匹配,不然在解析XML时,可能会出现(比如文档含有某个UNICODE字符,而encoding或BOM指定的格式不匹配,就会出错,当时我是这样的意思),然后他又告诉我,好像不是这样,我用DELPHI创建的XML文件,没有BOM,XML里面有中文内容,encoding里指定的是UTF-8,用IE可以正常打开啊。
他在发现他所创建的XML文件没有BOM时,有个有趣的地方,就是用UE打开这类含有UNICODE字符的文件时,UE会自动在文件前面加上FF FE,使得文件可以正常显示,所以原本没有BOM的文件,在UE下的十六进制下浏览,会看到多了个BOM,这个功能可以在UE的OPTIONS里去掉的,想知道的可以自己去找找。
然后我有点大头了,怎么会这样呢,然后想啊想,突然他发了一条信息过来,内容如下:
W3C定义了三条XML解析器如何正确读取XML文件的编码的规则:
1,如果文挡有BOM(字节顺序标记,一般来说,如果保存为unicode格式,则包含BOM,ANSI则无),就定义了文件编码
2,如果没有BOM,就查看XML声明的编码属性
3,如果上述两个都没有,就假定XML文挡采用UTF-8编码
有了这三条规则,那这个规则就清楚多了。
首先,XML解析器根据文件的BOM来解析文件;如果没找到BOM,由用XML里的encoding属性指定的编码;如果xml里encoding没指定的话,就默认用utf-8来解析文档。然后又可以推出,BOM和ENCODING都有的话,则以BOM指定的为准。
啊!突然觉得有标准文档多好!虽然是那么的理所当然。
至此,终于把xml里的encoding和文件格式的关系弄懂了。虽然这篇记录只有那几百个字内容,但是我们当时在讨论的时候,总时间差不多花了2个小时。
以上是关于xml里的encoding的详解的详细内容。更多信息请关注PHP中文网其他相关文章!

 XML外部实体注入漏洞的示例分析May 11, 2023 pm 04:55 PM
XML外部实体注入漏洞的示例分析May 11, 2023 pm 04:55 PM一、XML外部实体注入XML外部实体注入漏洞也就是我们常说的XXE漏洞。XML作为一种使用较为广泛的数据传输格式,很多应用程序都包含有处理xml数据的代码,默认情况下,许多过时的或配置不当的XML处理器都会对外部实体进行引用。如果攻击者可以上传XML文档或者在XML文档中添加恶意内容,通过易受攻击的代码、依赖项或集成,就能够攻击包含缺陷的XML处理器。XXE漏洞的出现和开发语言无关,只要是应用程序中对xml数据做了解析,而这些数据又受用户控制,那么应用程序都可能受到XXE攻击。本篇文章以java
 如何用PHP和XML实现网站的分页和导航Jul 28, 2023 pm 12:31 PM
如何用PHP和XML实现网站的分页和导航Jul 28, 2023 pm 12:31 PM如何用PHP和XML实现网站的分页和导航导言:在开发一个网站时,分页和导航功能是很常见的需求。本文将介绍如何使用PHP和XML来实现网站的分页和导航功能。我们会先讨论分页的实现,然后再介绍导航的实现。一、分页的实现准备工作在开始实现分页之前,需要准备一个XML文件,用来存储网站的内容。XML文件的结构如下:<articles><art
 php如何将xml转为json格式?3种方法分享Mar 22, 2023 am 10:38 AM
php如何将xml转为json格式?3种方法分享Mar 22, 2023 am 10:38 AM当我们处理数据时经常会遇到将XML格式转换为JSON格式的需求。PHP有许多内置函数可以帮助我们执行这个操作。在本文中,我们将讨论将XML格式转换为JSON格式的不同方法。
 Python中怎么对XML文件的编码进行转换May 21, 2023 pm 12:22 PM
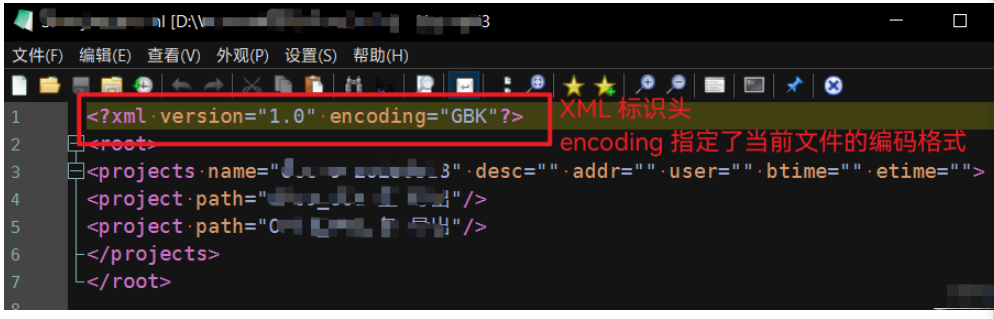
Python中怎么对XML文件的编码进行转换May 21, 2023 pm 12:22 PM1.在Python中XML文件的编码问题1.Python使用的xml.etree.ElementTree库只支持解析和生成标准的UTF-8格式的编码2.常见GBK或GB2312等中文编码的XML文件,用以在老旧系统中保证XML对中文字符的记录能力3.XML文件开头有标识头,标识头指定了程序处理XML时应该使用的编码4.要修改编码,不仅要修改文件整体的编码,还要将标识头中encoding部分的值修改2.处理PythonXML文件的思路1.读取&解码:使用二进制模式读取XML文件,将文件变为
 Python中xmltodict对xml的操作方式是什么May 04, 2023 pm 06:04 PM
Python中xmltodict对xml的操作方式是什么May 04, 2023 pm 06:04 PMPythonxmltodict对xml的操作xmltodict是另一个简易的库,它致力于将XML变得像JSON.下面是一个简单的示例XML文件:elementsmoreelementselementaswell这是第三方包,在处理前先用pip来安装pipinstallxmltodict可以像下面这样访问里面的元素,属性及值:importxmltodictwithopen("test.xml")asfd:#将XML文件装载到dict里面doc=xmltodict.parse(f
 使用nmap-converter将nmap扫描结果XML转化为XLS实战的示例分析May 17, 2023 pm 01:04 PM
使用nmap-converter将nmap扫描结果XML转化为XLS实战的示例分析May 17, 2023 pm 01:04 PM使用nmap-converter将nmap扫描结果XML转化为XLS实战1、前言作为网络安全从业人员,有时候需要使用端口扫描利器nmap进行大批量端口扫描,但Nmap的输出结果为.nmap、.xml和.gnmap三种格式,还有夹杂很多不需要的信息,处理起来十分不方便,而将输出结果转换为Excel表格,方面处理后期输出。因此,有技术大牛分享了将nmap报告转换为XLS的Python脚本。2、nmap-converter1)项目地址:https://github.com/mrschyte/nmap-
 xml中node和element的区别是什么Apr 19, 2022 pm 06:06 PM
xml中node和element的区别是什么Apr 19, 2022 pm 06:06 PMxml中node和element的区别是:Element是元素,是一个小范围的定义,是数据的组成部分之一,必须是包含完整信息的结点才是元素;而Node是节点,是相对于TREE数据结构而言的,一个结点不一定是一个元素,一个元素一定是一个结点。
 深度使用Scrapy:如何爬取HTML、XML、JSON数据?Jun 22, 2023 pm 05:58 PM
深度使用Scrapy:如何爬取HTML、XML、JSON数据?Jun 22, 2023 pm 05:58 PMScrapy是一款强大的Python爬虫框架,可以帮助我们快速、灵活地获取互联网上的数据。在实际爬取过程中,我们会经常遇到HTML、XML、JSON等各种数据格式。在这篇文章中,我们将介绍如何使用Scrapy分别爬取这三种数据格式的方法。一、爬取HTML数据创建Scrapy项目首先,我们需要创建一个Scrapy项目。打开命令行,输入以下命令:scrapys


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

Dreamweaver Mac版
视觉化网页开发工具

SecLists
SecLists是最终安全测试人员的伙伴。它是一个包含各种类型列表的集合,这些列表在安全评估过程中经常使用,都在一个地方。SecLists通过方便地提供安全测试人员可能需要的所有列表,帮助提高安全测试的效率和生产力。列表类型包括用户名、密码、URL、模糊测试有效载荷、敏感数据模式、Web shell等等。测试人员只需将此存储库拉到新的测试机上,他就可以访问到所需的每种类型的列表。

SublimeText3 Linux新版
SublimeText3 Linux最新版

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

