



概述
Java集合框架由Java类库的一系列接口、抽象类以及具体实现类组成。我们这里所说的集合就是把一组对象组织到一起,然后再根据不同的需求操纵这些数据。集合类型就是容纳这些对象的一个容器。也就是说,最基本的集合特性就是把一组对象放一起集中管理。根据集合中是否允许有重复的对象、对象组织在一起是否按某种顺序等标准来划分的话,集合类型又可以细分为许多种不同的子类型。
Java集合框架为我们提供了一组基本机制以及这些机制的参考实现,其中基本的集合接口是Collection接口,其他相关的接口还有Iterator接口、RandomAccess接口等。这些集合框架中的接口定义了一个集合类型应该实现的基本机制,Java类库为我们提供了一些具体集合类型的参考实现,根据对数据组织及使用的不同需求,只需要实现不同的接口即可。Java类库还为我们提供了一些抽象类,提供了集合类型功能的部分实现,我们也可以在这个基础上去进一步实现自己的集合类型。
Collection接口
迭代器
我们先来看下这个接口的定义:
public interface Collection<E> extends Iterable<E>
首先,它使用了一个类型参数;其次,它实现了Iterable1a4db2c2c2313771e5742b6debf617a1接口,我们再来看下Iterable1a4db2c2c2313771e5742b6debf617a1接口的定义:
public interface Iterable<T> {
Iterator<T> iterator();
}我们可以看到这个接口只定义了一个方法,这个方法要求我们返回一个实现了Iterator8742468051c85b06f0a0af9e3e506b5c类型的对象,所以我们看下Iterator8742468051c85b06f0a0af9e3e506b5c的定义:
public interface Iterator<E> {
boolean hasNext();
E next();
void remove();
}说到这里,我们简单地说一下迭代器(Iterator)这个东西。上面我们一共提到了两个和迭代器相关的接口:Iterable1a4db2c2c2313771e5742b6debf617a1接口和Iterator1a4db2c2c2313771e5742b6debf617a1接口,从字面意义上来看,前者的意思是“可迭代的”,后者的意思是“迭代器。所以我们可以这么理解这两个接口:实现了Iterable1a4db2c2c2313771e5742b6debf617a1接口的类是可迭代的;实现了Iterator1a4db2c2c2313771e5742b6debf617a1接口的类是一个迭代器。
迭代器就是一个我们用来遍历集合中的对象的东西。也就是说,对于集合,我们不是像对原始类型数组那样通过数组索引来直接访问相应位置的元素,而是通过迭代器来遍历。这么做的好处是将对于集合类型的遍历行为与被遍历的集合对象分离,这样一来我们无需关心该集合类型的具体实现是怎样的。只要获取这个集合对象的迭代器, 便可以遍历这个集合中的对象了。而像遍历对象的顺序这些细节,全部由它的迭代器来处理。现在我们来梳理一下前面提到的这些东西:首先,Collection接口实现了Iterable1a4db2c2c2313771e5742b6debf617a1接口,这意味着所有实现了Collection接口的具体集合类都是可迭代的。那么既然要迭代,我们就需要一个迭代器来遍历相应集合中的对象,所以Iterable1a4db2c2c2313771e5742b6debf617a1接口要求我们实现iterator方法,这个方法要返回一个迭代器对象。一个迭代器对象也就是实现了Iterator1a4db2c2c2313771e5742b6debf617a1接口的对象,这个接口要求我们实现hasNext()、next()、remove()这三个方法。其中hasNext方法判断是否还有下一个元素(即是否遍历完对象了),next方法会返回下一个元素(若没有下一个元素了调用它会引起抛出一个NoSuchElementException异常),remove方法用于移除最近一次调用next方法返回的元素(若没有调用next方法而直接调用remove方法会报错)。我们可以想象在开始对集合进行迭代前,有个指针指向集合第一个元素的前面,第一次调用next方法后,这个指针会”扫过”第一个元素并返回它,调用hasNext方法就是看这个指针后面还有没有元素了。也就是说这个指针始终指向刚遍历过的元素和下一个待遍历的元素之间。通常,迭代一个集合对象的代码是这个样子的:
Collection<String> c = ...;
Iterator<String> iter = c.iterator();
while (iter.hasNext()) {
String element = iter.next();
//do something with element
}从Java SE 5.0开始,我们可以使用与以上代码段等价但是更加简洁的版本:
for (String element : c) {
//do something with element
}上面我们提到过Iterator接口的remove方法必须在next方法返回一个元素后才能调用,这对Java类库中为我们提供的实现了Collection接口的类来说是这样的。当然我们可以通过自己定义一个实现Collection接口的集合类来改变这一默认行为(除非有充足的理由,否则最好不要这样做)。
Collection接口
我们先来看一下它的官方定义:
The root interface in the collection hierarchy. A collection represents a group of objects, known as its elements. Some collections allow duplicate elements and others do not. Some are ordered and others unordered. The JDK does not provide any direct implementations of this interface: it provides implementations of more specific subinterfaces like Set
and List.
大概的意思就是:Collection接口是集合层级结构的根接口。一个集合代表了一组对象,这组对象被称为集合的元素。一些集合允许重复的元素而其他不允许;一些是有序的而一些是无序的。Java类库中并未提供任何对这个接口的直接实现,而是提供了对于它的更具体的子接口的实现(比如Set接口和List接口)。
我们知道,接口是一组对需求的描述,那么让我们看看Collection接口提出了哪些需求。Collection接口中定义了以下方法:
boolean add(E e) //向集合中添加一个元素,若添加元素后集合发生了变化就返回true,若没有发生变化,就返回false。(optional operation). boolean addAll(Collection<? extends E> c) //添加给定集合c中的所有元素到该集合中(optional operation). void clear() //(optional operation). boolean contains(Object o) //判断该集合中是否包含指定对象 boolean containsAll(Collection<?> c) boolean equals(Object o) int hashCode() boolean isEmpty() Iterator<E> iterator() boolean remove(Object o) //移除给定对象的一个实例(有的具体集合类型允许重复元素) (optional operation). boolean removeAll(Collection<?> c) //(optional operation). boolean retainAll(Collection<?> c) //仅保留给定集合c中的元素(optional operation). int size() Object[] toArray() <T> T[] toArray(T[] a)
我们注意到有些方法后面注释中标注了“optional operation”,意思是Collection接口的实现类究竟需不需要实现这个方法视具体情况而定。比如有些具体的集合类型不允许向其中添加对象,那么它就无需实现add方法。我们可以看到,Collection对象必须实现的方法有:contains方法、containsAll方法、isEmpty方法、iterator方法、size方法、两个toArray方法以及equals方法、hashCode方法,其中最后两个方法继承自Object类。
我们来说一下两个toArray方法,它们的功能都是都是返回这个集合的对象数组。第二个方法接收一个arrayToFill参数,当这个参数数组足够大时,就把集合中的元素都填入这个数组(多余空间填null);当arrayToFill不够大时,就会创建一个大小与集合相同,类型与arrayToFill相同的数组,并填入集合元素。
Collection接口的直接子接口主要有三个:List接口、Set接口和Queue接口。下面我们对它们进行逐一介绍。
List接口
我们同样先看下它的官方定义:
An ordered collection (also known as a sequence). The user of this interface has precise control over where in the list each element is inserted. The user can access elements by their integer index (position in the list), and search for elements in the list.Unlike sets, lists typically allow duplicate elements. More formally, lists typically allow pairs of elements e1 and e2 such that e1.equals(e2), and they typically allow multiple null elements if they allow null elements at all.
大概意思是:List是一个有序的集合类型(也被称作序列)。使用List接口可以精确控制每个元素被插入的位置,并且可以通过元素在列表中的索引来访问它。列表允许重复的元素,并且在允许null元素的情况下也允许多个null元素。
我们再来看下它定义了哪些方法:
ListIterator<E> listIterator(); void add(int i, E element); E remove(int i); E get(int i); E set(int i, E element); int indexOf(Object element);
我们可以看到,列表支持对指定位置元素的读写与移除。我们注意到,上面有一个listIterator方法,它返回一个列表迭代器。我们来看一看ListIterator1a4db2c2c2313771e5742b6debf617a1接口都定义了哪些方法:
void add(E e) //在当前位置添加一个元素 boolean hasNext() //返回ture如果还有下个元素(在正向遍历列表时使用) boolean hasPrevious() //反向遍历列表时使用 E next() //返回下一个元素并将cursor(也就是我们上文提到的”指针“)前移一个位置 int nextIndex() //返回下一次调用next方法将返回的元素的索引 E previous() //返回前一个元素并将cursor向前移动一个位置 int previousIndex() //返回下一次调用previous方法将返回的元素的索引void remove() //从列表中移除最近一次调用next方法或previous方法返回的元素 void set(E e) //用e替换最近依次调用next或previous方法返回的元素
ListIterator1a4db2c2c2313771e5742b6debf617a1是Iterator1a4db2c2c2313771e5742b6debf617a1的子接口,它支持像双向迭代这样更加特殊化的操作。综合以上,我们可以看到,List接口支持两种访问元素的方式:使用列表迭代器顺序访问或者使用get/set方法随机访问。
Java类库中常见的实现了List1a4db2c2c2313771e5742b6debf617a1接口的类有:ArrayList, LinkedList,Stack,Vector,AbstractList,AbstractSequentialList等等。
ArrayList
ArrayList是一个可动态调整大小的数组,允许null类型的元素。我们知道,Java中的数组大小在初始化时就必须确定下来,而且一旦确定就不能改变,这会使得在很多场景下不够灵活。ArrayList很好地帮我们解决了这个问题,当我们需要一个能根据包含元素的多少来动态调整大小的数组时,那么ArrayList正是我们所需要的。
我们先来看看这个类的常用方法:
boolean add(E e) //添加一个元素到数组末尾 void add(int index, E element) //添加一个元素到指定位置 void clear() boolean contains(Object o) void ensureCapacity(int minCapacity) //确保ArrayList至少能容纳参数指定数目的对象,若有需要会增加ArrayList实例的容量。 E get(int index) //返回指定位置的元素 int indexOf(Object o) boolean isEmpty() Iterator<E> iterator() ListIterator<E> listIterator() E remove(int index) boolean remove(Object o) E set(int index, E element) int size()
当我们插入了比较多的元素,导致ArrayList快要装满时,它会自动增长容量。ArrayList内部使用一个Object数组来存储元素,自动增长容量是通过创建一个新的容量更大的Object数组,并将元素从原Object数组复制到新Object数组来实现的。若要想避免这种开销,在知道大概会容纳多少数据时,我们可以在构造时指定好它的大小以尽量避免它自动增长的发生;我们也可以调用ensureCapacity方法来增加ArrayList对象的容量到我们指定的大小。ArrayList有以下三个构造器:
ArrayList() ArrayList(Collection<? extends E> c) ArrayList(int initialCapacity) //指定初始capacity,即内部Object数组的初始大小
LinkedList类
LinkedList类代表了一个双向链表,允许null元素。这个类同ArrayList一样,不是线程安全的。
这个类中主要有以下的方法:
void addFirst(E element); void addLast(E element); E getFirst(); E getLast(); E removeFirst(); E removeLast();
这些方法的含义正如它们的名字所示。LinkedList作为List接口的实现类,自然包含了List接口中定义的add等方法。LinkedList的add方法实现有以下两种:
boolean add(E e) //把元素e添加到链表末尾 void add(int index, E element) //在指定索引处添加元素
LinkedList的一个缺陷在于它不支持对元素的高效随机访问,要想随机访问其中的元素,需要逐个扫描直到遇到符合条件的元素。只有当我们需要减少在列表中间添加或删除元素操作的代价时,可以考虑使用LinkedList。
Set接口
Set接口与List接口的重要区别就是它不支持重复的元素,至多可以包含一个null类型元素。Set接口定义的是数学意义上的“集合”概念。
Set接口主要定义了以下方法:
boolean add(E e) void clear() boolean contains(Object o) boolean isEmpty() boolean equals(Object obj) Iterator<E> iterator() boolean remove(Object o) boolean removeAll(Collection<?> c) int size() Object[] toArray() <T> T[] toArray(T[] a)
Set接口并没有显式要求其中的元素是有序或是无序的,它有一个叫做SortedSet的子接口,这个接口可以用来实现对Set元素的排序,SortedSet还有叫做NavigableSet的子接口,这个接口定义的方法可以在有序Set中进行查找和遍历。Java类库中实现了Set接口的类主要有:AbstractSet,HashSet,TreeSet,EnumSet,LinkedHashSet等等。其中,HashSet与TreeSet都是AbstractSet的子类。那么,为什么Java类库要提供AbstractSet这个抽象类呢?答案是为了让我们在自定义实现Set接口的类时不必“从零开始”,AbstractSet这个抽象类已经为我们实现了Set接口中的一些常规方法,而一些灵活性比较强的方法可以由我们自己来定义,我们只需要继承AbstractSet这个抽象类即可。类似的抽象类还有很多,比如我们上面提到的实现了List接口的AbstractList抽象类就是LinkedList和ArrayList的父类。Java官方文档中提到,HashSet和TreeSet分别基于HashMap和TreeMap实现(我们在后面会简单介绍HashMap和TreeMap),他们的区别在于Set1a4db2c2c2313771e5742b6debf617a1接口是一个对象的集(数学意义上的”集合“),Mapb56561a2c0bc639cf0044c0859afb88f是一个键值对的集合。而且由于它们分别是对Set1a4db2c2c2313771e5742b6debf617a1和Mapb56561a2c0bc639cf0044c0859afb88f接口的实现,相应添加与删除元素的方法也取决于具体接口的定义。
Queue接口
Queue接口是对队列这种数据结构的抽象。一般的队列实现允许我们高效的在队尾添加元素,在队列头部删除元素(First in, First out)。Queue1a4db2c2c2313771e5742b6debf617a1接口还有一个名为Deque的子接口,它允许我们高效的在队头或队尾添加/删除元素,实现了Deque1a4db2c2c2313771e5742b6debf617a1的接口的集合类即为双端队列的一种实现(比如LinkedList就实现了Deque接口)。Queue接口定义了以下方法:
boolean add(E e) //添加一个元素到队列中,若队列已满会抛出一个IllegalStateException异常 E element() //获取队头元素 boolean offer(E e) //添加一个元素到队列中,若队列已满返回false E peek() //获取队头元素,若队列为空返回null E poll() //返回并移除队头元素,若队列为空返回null E remove() //返回并移除队头元素
我们注意观察下上面的方法:add与offer,element与peek,remove与poll看似是三对儿功能相同的方法。它们之间的重要区别在于前者若操作失败会抛出一个异常,后者若操作失败会从返回值体现出来(比如返回false或null),我们可以根据具体需求调用它们中的前者或后者。
实现Queue接口的类主要有:AbstractQueue, ArrayDeque, LinkedList,PriorityQueue,DelayQueue等等。关于它们具体的介绍可参考官方文档或相关的文章。
Map接口
我们先来看下它的定义:
An object that maps keys to values. A map cannot contain duplicate keys; each key can map to at most one value.The Map
interface provides three collection views, which allow a map’s contents to be viewed as a set of keys, collection of values, or set of key-value mappings. The order of a map is defined as the order in which the iterators on the map’s collection views return their elements. Some map implementations, like the TreeMap
class, make specific guarantees as to their order; others, like the HashMap
class, do not.
大概意思是这样的:一个把键映射到值的对象被称作一个Map对象。映射表不能包含重复的键,每个键至多可以与一个值关联。Map接口提供了三个集合视图(关于集合视图的概念我们下面会提到):键的集合视图、值的集合视图以及键值对的集合视图。一个映射表的顺序取决于它的集合视图的迭代器返回元素的顺序。一些Map接口的具体实现(比如TreeMap)保证元素有一定的顺序,其它一些实现(比如HashMap)则不保证元素在其内部有序。
也就是说,Map接口定义了一个类似于“字典”的规范,让我们能够根据键快速检索到它所关联的值。我们先来看看Map接口定义了哪些方法:
void clear() boolean containsKey(Object key) //判断是否包含指定键 boolean containsValue(Object value) //判断是否包含指定值 boolean isEmpty() V get(Object key) //返回指定键映射的值 V put(K key, V value) //放入指定的键值对 V remove(Object key) int size() Set<Map.Entry<K,V>> entrySet() Set<K> keySet() Collection<V> values()
后三个方法在我们下面介绍集合视图时会具体讲解。
Map接口的具体实现类主要有:AbstractMap,EnumMap,HashMap,LinkedHashMap,TreeMap。HashTable。
HashMap
我们看一下HashMap的官方定义:
HashMapb56561a2c0bc639cf0044c0859afb88f是基于哈希表这个数据结构的Map接口具体实现,允许null键和null值。这个类与HashTable近似等价,区别在于HashMap不是线程安全的并且允许null键和null值。由于基于哈希表实现,所以HashMap内部的元素是无序的。HashMap对与get与put操作的时间复杂度是常数级别的(在散列均匀的前提下)。对HashMap的集合视图进行迭代所需时间与HashMap的capacity(bucket的数量)加上HashMap的尺寸(键值对的数量)成正比。因此,若迭代操作的性能很重要,不要把初始capacity设的过高(不要把load factor设的过低)。
有两个因素会影响一个HashMap对象的性能:intial capacity(初始容量)和load factor(负载因子)。intial capacity就是HashMap对象刚创建时其内部的哈希表的“桶”的数量(请参考哈希表的定义)。load factor等于maxSize / capacity,也就是HashMap所允许的最大键值对数与桶数的比值。增大load factor可以节省空间但查找一个元素的时间会增加,减小load factor会占用更多的存储空间,但是get与put的操作会更快。当HashMap中的键值对数量超过了maxSize(即load factor与capacity的乘积),它会再散列,再散列会重建内部数据结构,桶数(capacity)大约会增加到原来的两倍。
HashMap默认的load factor大小为0.75,这个数值在时间与空间上做了很好的权衡。当我们清楚自己将要大概存放多少数据时,也可以自定义load factor的大小。
HashMap的构造器如下:
HashMap() HashMap(int initialCapacity) HashMap(int initialCapacity, float loadFactor) HashMap(Map<? extends K,? extends V> m) //创建一个新的HashMap,用m的数据填充
常用方法如下:
void clear() boolean containsKey(Object key) boolean containsValue(Object value) V get(Object key) V put(K key, V value) boolean isEmpty() V remove(Object key) int size() Collection<V> values() Set<Map.Entry<K,V>> entrySet() Set<K> keySet()
它们的功能都很直观,更多的使用细节可以参考Java官方文档,这里就不贴上来了。这里简单地提一下WeakHashMap,它与HashMap的区别在于,存储在其中的key是“弱引用”的,也就是说,当不再存在对WeakHashMap中的键的外部引用时,相应的键值对就会被回收。关于WeakHashMap和其他类的具体使用方法及注意事项,大家可以参考官方文档。下面我们来简单地介绍下另一个Map接口的具体实现——TreeMap。
TreeMap
它的官方定义是这样的:
TreeMapb56561a2c0bc639cf0044c0859afb88f一个基于红黑树的Map接口实现。TreeMap中的元素的有序的,排序的依据是存储在其中的键的natural ordering(自然序,也就是数字从小到大,字母的话按照字典序)或者根据在创建TreeMap时提供的Comparator对象,这取决于使用了哪个构造器。TreeMap的containsKey, get, put和remove操作的时间复杂度均为log(n)。
TreeMap有以下构造器:
TreeMap() //使用自然序对其元素进行排序 TreeMap(Comparator<? super K> comparator) //使用一个比较器对其元素进行排序 TreeMap(Map<? extends K,? extends V> m) //构造一个与映射表m含有相同元素的TreeMap,用自然序进行排列 TreeMap(SortedMap<K,? extends V> m) //构造一个与有序映射表m含有相同元素及元素顺序的TreeMap
它的常见方法如下:
Map.Entry<K,V> ceilingEntry(K key) //返回一个最接近且大于等于指定key的键值对。 K ceilingKey(K key) void clear() Comparator<? super K> comparator() //返回使用的比较器,若按自然序则返回null boolean containsKey(Object key) boolean containsValue(Object value) NavigableSet<K> descendingKeySet() //返回一个包含在TreeMap中的键的逆序的NavigableSet视图 NavigableMap<K,V> descendingMap() Set<Map.Entry<K,V>> entrySet() Map.Entry<K,V> firstEntry() //返回键最小的键值对 Map.Entry<K,V> floorEntry(K key) //返回一个最接近指定key且小于等于它的键对应的键值对 K floorKey(K key) V get(Object key) Set<K> keySet() Map.Entry<K,V> lastEntry() //返回与最大的键相关联的键值对 K lastKey()
建议大家先了解下红黑树这个数据结构的原理及实现(可参考算法(第4版) (豆瓣)),然后再去看官方文档中关于这个类的介绍,这样学起来会事半功倍。
最后再简单地介绍下NavigableMapb56561a2c0bc639cf0044c0859afb88f这个接口:
实现了这个接口的类支持一些navigation methods,比如lowerEntry(返回小于指定键的最大键所关联的键值对),floorEntry(返回小于等于指定键的最大键所关联的键值对),ceilingEntry(返回大于等于指定键的最小键所关联的键值对)和higerEntry(返回大于指定键的最小键所关联的键值对)。一个NavigableMap支持对其中存储的键按键的递增顺序或递减顺序的遍历或访问。NavigableMapb56561a2c0bc639cf0044c0859afb88f接口还定义了firstEntry、pollFirstEntry、lastEntry和pollLastEntry等方法,以准确获取指定位置的键值对。
总的来说,NavigableMapb56561a2c0bc639cf0044c0859afb88f接口正如它的名字所示,支持我们在映射表中”自由的航行“,正向或者反向迭代其中的元素并获取我们需要的指定位置的元素。TreeMap实现了这个接口。
视图(View)与包装器
下面我们来解决一个上面遗留的问题,也就是介绍一下集合视图的概念。Java中的集合视图是用来查看集合中全部或部分数据的一个”窗口“,只不过通过视图我们不仅能查看相应集合中的元素,对视图的操作还可能会影响到相应的集合。通过使用视图可以获得其他的实现了Map接口或Collection接口的对象。比如我们上面提到的TreeMap和HashMap的keySet()方法就会返回一个相应映射表对象的视图。也就是说,keySet方法返回的视图是一个实现了Set接口的对象,这个对象中又包含了一系列键对象。
轻量级包装器
Arrays.asList会发挥一个包装了Java数组的集合视图(实现了List接口)。请看以下代码:
public static void main(String[] args) {
String[] strings = {"first", "second", "third"};
List<String> stringList = Arrays.asList(strings);
String s1 = stringList.get(0);
System.out.println(s1);
stringList.add(0, "new first");
}以上代码会编译成功,但是在运行时会抛出一个UnsupportedOperationException异常,原因是调用了改变列表大小的add方法。Arrays.asList方法返回的封装了底层数组的集合视图不支持对改变数组大小的方法(如add方法和remove方法)的调用(但是可以改变数组中的元素)。实际上,这个方法调用了以下方法:
Collections.nCopies(n, anObject);
这个方法会返回一个实现了List接口的不可修改的对象。这个对象包含了n个元素(anObject)。
子范围
我们可以为很多集合类型建立一个称为子范围(subrange)的集合视图。例如以下代码抽出group中的第10到19个元素(从0开始计数)组成一个子范围:
List subgroup = group.subList(10, 20); //group为一个实现了List接口的列表类型
List接口所定义的操作都可以应用于子范围,包括那些会改变列表大小的方法,比如以下方法会把subgroup列表清空,同时group中相应的元素也会从列表中移除:
subgroup.clear();
对于实现了SortedSet1a4db2c2c2313771e5742b6debf617a1接口的有序集或是实现了SortedMapb56561a2c0bc639cf0044c0859afb88f接口的有序映射表,我们也可以为他们创建子范围。SortedSet接口定义了以下三个方法:
SortedSet<E> subSet(E from, E to); SortedSet<E> headSet(E to); SortedSet<E> tailSet(E from);
SortedMap也定义了类似的方法:
SortedMap<K, V> subMap(K from, K to); SortedMap<K, V> headMap(K to); SortedMap<K, V> tailMap(K from);
不可修改的视图
Collections类中的一些方法可以返回不可修改视图(unmodifiable views):
Collections.unmodifiableCollection Collections.unmodifiableList Collections.unmodifiableSet Collections.unmodifiableSortedSet Collections.unmodifiableMap Collections.unmodifiableSortedMap
同步视图
若集合可能被多个线程并发访问,那么我们就需要确保集合中的数据不会被破坏。Java类库的设计者使用视图机制来确保常规集合的线程安全。比如,我们可以调用以下方法将任意一个实现了Map接口的集合变为线程安全的:
Map<String, Integer> map = Collections.synchronizedMap(new HashMap<String, Integer>());
被检验视图
我们先看一下这段代码:
ArrayList<String> strings = new ArrayList<String>(); ArrayList rawList = strings; rawList.add(new Date());
在以上代码的第二行,我们把泛型数组赋值给了一个原始类型数组,这通常只会产生一个警告。而第三行我们往rawList中添加一个Date对象时,并不会产生任何错误。因为rawList内部存储的实际上是Object对象,而任何对象都可以转换为Object对象。那么我们怎么避免这一问题呢,请看以下代码:
ArrayList<String> strings = new ArrayList<String>(); List<String> safeStrings = Collections.checkedList(strings, String.class); ArrayList rawList = safeStrings; rawList.add(new Date()); //Checked list throws a ClassCastException
在上面,我们通过包装strings得到一个被检验视图safeStrings。这样在尝试添加非String对象时,便会抛出一个ClassCastException异常。
集合视图的本质
集合视图本身不包含任何数据,它只是对相应接口的包装。集合视图所支持的所有操作都是通过访问它所关联的集合类实例来实现的。我们来看看HashMap的keySet方法的源码:
public Set<K> keySet() {
Set<K> ks;
return (ks = keySet) == null ? (keySet = new KeySet()) : ks;
}
final class KeySet extends AbstractSet<K> {
public final int size() {
return size;
}
public final void clear() {
HashMap.this.clear();
}
public final Iterator<K> iterator() {
return new KeyIterator();
}
public final boolean contains(Object o) {
return containsKey(o);
}
public final boolean remove(Object key) {
return removeNode(hash(key), key, null, false, true) != null;
}
public final Spliterator<K> spliterator() {
return new KeySpliterator<>(HashMap.this, 0, -1, 0, 0);
}
public final void forEach(Consumer<? super K> action) {
Node<K,V>[] tab;
if (action == null) throw new NullPointerException();
if (size > 0 && (tab = table) != null) {
int mc = modCount;
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next)
action.accept(e.key);
}
if (modCount != mc) throw new ConcurrentModificationException();
}
}
}我们可以看到,实际上keySet()方法返回一个内部final类KeySet的实例。我们可以看到KeySet类本身没有任何实例变量。我们再看KeySet类定义的size()实例方法,它的实现就是通过直接返回HashMap的实例变量size。还有clear方法,实际上调用的就是HashMap对象的clear方法。
keySet方法能够让你直接访问到Map的键集,而不需要复制数据或者创建一个新的数据结构,这样做往往比复制数据到一个新的数据结构更加高效。考虑这样一个场景:你需要把一个之前创建的数组传递给一个接收List参数的方法,那么你可以使用Arrays.asList方法返回一个包装了数组的视图(这需要的空间复杂度是常数级别的),而不用创建一个新的ArrayList再把原数组中的数据复制过去。
Collections类
我们要注意到Collections类与Collection接口的区别:Collection是一个接口,而Collections是一个类(可以看做一个静态方法库)。下面我们看一下官方文档对Collections的描述:
Collections类包含了大量用于操作或返回集合的静态方法。它包含操作集合的多态算法,还有包装集合的包装器方法等等。这个类中的所有方法在集合或类对象为空时均会抛出一个NullPointerException。
关于Collections类中的常用方法,我们上面已经做了一些介绍,更加详细的介绍大家可以参考Java官方文档。
总结
关于Java集合框架,我们首先应该把握住几个核心的接口,请看下图(下图中LinkList拼写有误,应为LinkedList):
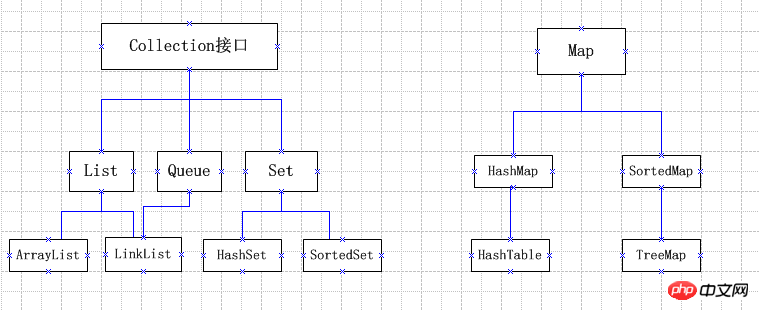
我们还要了解到这些接口描述了一组什么样的机制,然后以此作为出发点,去了解具体哪些类实现了哪些机制。像这样自顶向下的学习,我们很快就能掌握常见集合类的用法。对于一些我们平常经常使用的类,我们还可以阅读一下它的源码,了解它的实现细节,这样我们以后使用起来会更加得心应手。不过阅读一些集合类(比如TreeMap、HashMap)的源码需要我们具备一定的数据结构与算法的基础知识,这方面推荐阅读 算法(第4版) (豆瓣)。
以上是Java核心技术点之集合框架的详细介绍的详细内容。更多信息请关注PHP中文网其他相关文章!

 如何将Maven或Gradle用于高级Java项目管理,构建自动化和依赖性解决方案?Mar 17, 2025 pm 05:46 PM
如何将Maven或Gradle用于高级Java项目管理,构建自动化和依赖性解决方案?Mar 17, 2025 pm 05:46 PM本文讨论了使用Maven和Gradle进行Java项目管理,构建自动化和依赖性解决方案,以比较其方法和优化策略。
 如何使用适当的版本控制和依赖项管理创建和使用自定义Java库(JAR文件)?Mar 17, 2025 pm 05:45 PM
如何使用适当的版本控制和依赖项管理创建和使用自定义Java库(JAR文件)?Mar 17, 2025 pm 05:45 PM本文使用Maven和Gradle之类的工具讨论了具有适当的版本控制和依赖关系管理的自定义Java库(JAR文件)的创建和使用。
 如何使用咖啡因或Guava Cache等库在Java应用程序中实现多层缓存?Mar 17, 2025 pm 05:44 PM
如何使用咖啡因或Guava Cache等库在Java应用程序中实现多层缓存?Mar 17, 2025 pm 05:44 PM本文讨论了使用咖啡因和Guava缓存在Java中实施多层缓存以提高应用程序性能。它涵盖设置,集成和绩效优势,以及配置和驱逐政策管理最佳PRA
 如何将JPA(Java持久性API)用于具有高级功能(例如缓存和懒惰加载)的对象相关映射?Mar 17, 2025 pm 05:43 PM
如何将JPA(Java持久性API)用于具有高级功能(例如缓存和懒惰加载)的对象相关映射?Mar 17, 2025 pm 05:43 PM本文讨论了使用JPA进行对象相关映射,并具有高级功能,例如缓存和懒惰加载。它涵盖了设置,实体映射和优化性能的最佳实践,同时突出潜在的陷阱。[159个字符]
 Java的类负载机制如何起作用,包括不同的类载荷及其委托模型?Mar 17, 2025 pm 05:35 PM
Java的类负载机制如何起作用,包括不同的类载荷及其委托模型?Mar 17, 2025 pm 05:35 PMJava的类上载涉及使用带有引导,扩展程序和应用程序类负载器的分层系统加载,链接和初始化类。父代授权模型确保首先加载核心类别,从而影响自定义类LOA


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

Dreamweaver Mac版
视觉化网页开发工具

EditPlus 中文破解版
体积小,语法高亮,不支持代码提示功能

Atom编辑器mac版下载
最流行的的开源编辑器

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

