



前言:
身为一个java程序员,怎么能不了解JVM呢,倘若想学习JVM,那就又必须要了解Class文件,Class之于虚拟机,就如鱼之于水,虚拟机因为Class而有了生命。《深入理解java虚拟机》中花了一整个章节来讲解Class文件,可是看完后,一直都还是迷迷糊糊,似懂非懂。正好前段时间看见一本书很不错:《自己动手写Java虚拟机》,作者利用go语言实现了一个简单的JVM,虽然没有完整实现JVM的所有功能,但是对于一些对JVM稍感兴趣的人来说,可读性还是很高的。作者讲解的很详细,每个过程都分为了一章,其中一部分就是讲解如何解析Class文件。
这本书不太厚,很快就读完了,读完后,收获颇丰。但是纸上得来终觉浅,绝知此事要躬行,我便尝试着自己解析Class文件。go语言虽然很优秀,但是终究不熟练,尤其是不太习惯其把类型放在变量之后的语法,还是老老实实用java吧。
Class文件
什么是Class文件?
java之所以能够实现跨平台,便在于其编译阶段不是将代码直接编译为平台相关的机器语言,而是先编译成二进制形式的java字节码,放在Class文件之中,虚拟机再加载Class文件,解析出程序运行所需的内容。每个类都会被编译成一个单独的class文件,内部类也会作为一个独立的类,生成自己的class。
基本结构
随便找到一个class文件,用Sublime Text打开是这样的:
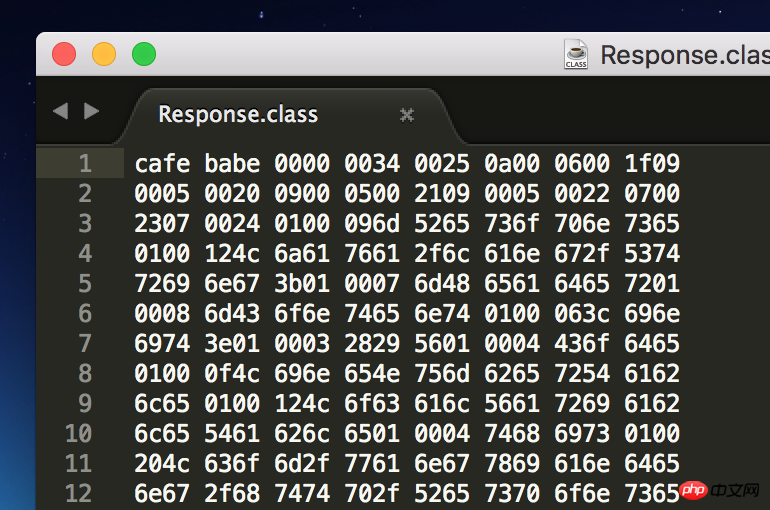
是不是一脸懵逼,不过java虚拟机规范中给出了class文件的基本格式,只要按照这个格式去解析就可以了:
ClassFile {
u4 magic;
u2 minor_version;
u2 major_version;
u2 constant_pool_count;
cp_info constant_pool[constant_pool_count-1];
u2 access_flags;
u2 this_class;
u2 super_class;
u2 interfaces_count;
u2 interfaces[interfaces_count];
u2 fields_count;
field_info fields[fields_count];
u2 methods_count;
method_info methods[methods_count];
u2 attributes_count;
attribute_info attributes[attributes_count];
}ClassFile中的字段类型有u1、u2、u4,这是什么类型呢?其实很简单,就是分别表示1个字节,2个字节和4个字节。
开头四个字节为:Magic,是用来唯一标识文件格式的,一般被称作magic number(魔数),这样虚拟机才能识别出所加载的文件是否是class格式,class文件的魔数为cafebabe。不只是class文件,基本上大部分文件都有魔数,用来标识自己的格式。
接下来的部分主要是class文件的一些信息,如常量池、类访问标志、父类、接口信息、字段、方法等,具体的信息可参考《Java虚拟机规范》。
解析
字段类型
上面说到ClassFile中的字段类型有u1、u2、u4,分别表示1个字节,2个字节和4个字节的无符号整数。java中short、int、long分别为2、4、8个字节的有符号整数,去掉符号位,刚好可以用来表示u1、u2、u4。
public class U1 {
public static short read(InputStream inputStream) {
byte[] bytes = new byte[1];
try {
inputStream.read(bytes);
} catch (IOException e) {
e.printStackTrace();
}
short value = (short) (bytes[0] & 0xFF);
return value;
}
}
public class U2 {
public static int read(InputStream inputStream) {
byte[] bytes = new byte[2];
try {
inputStream.read(bytes);
} catch (IOException e) {
e.printStackTrace();
}
int num = 0;
for (int i= 0; i < bytes.length; i++) {
num <<= 8;
num |= (bytes[i] & 0xff);
}
return num;
}
}
public class U4 {
public static long read(InputStream inputStream) {
byte[] bytes = new byte[4];
try {
inputStream.read(bytes);
} catch (IOException e) {
e.printStackTrace();
}
long num = 0;
for (int i= 0; i < bytes.length; i++) {
num <<= 8;
num |= (bytes[i] & 0xff);
}
return num;
}
}常量池
定义好字段类型后,我们就可以读取class文件了,首先是读取魔数之类的基本信息,这部分很简单:
FileInputStream inputStream = new FileInputStream(file); ClassFile classFile = new ClassFile(); classFile.magic = U4.read(inputStream); classFile.minorVersion = U2.read(inputStream); classFile.majorVersion = U2.read(inputStream);
这部分只是热热身,接下来的大头在于常量池。解析常量池之前,我们先来解释一下常量池是什么。
常量池,顾名思义,存放常量的资源池,这里的常量指的是字面量和符号引用。字面量指的是一些字符串资源,而符号引用分为三类:类符号引用、方法符号引用和字段符号引用。通过将资源放在常量池中,其他项就可以直接定义成常量池中的索引了,避免了空间的浪费,不只是class文件,Android可执行文件dex也是同样如此,将字符串资源等放在DexData中,其他项通过索引定位资源。java虚拟机规范给出了常量池中每一项的格式:
cp_info {
u1 tag;
u1 info[];
}上面的这个格式只是一个通用格式,常量池中真正包含的数据有14种格式,每种格式的tag值不同,具体如下所示:
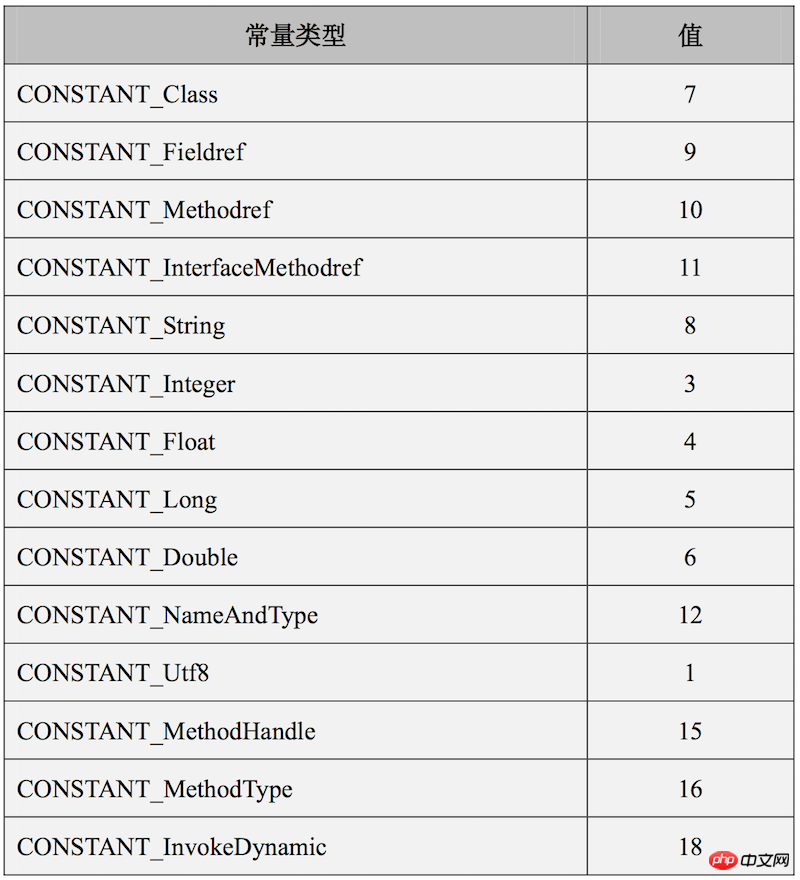
由于格式太多,文章中只挑选一部分讲解:
这里首先读取常量池的大小,初始化常量池:
//解析常量池 int constant_pool_count = U2.read(inputStream); ConstantPool constantPool = new ConstantPool(constant_pool_count); constantPool.read(inputStream);
接下来再逐个读取每项内容,并存储到数组cpInfo中,这里需要注意的是,cpInfo[]下标从1开始,0无效,且真正的常量池大小为constant_pool_count-1。
public class ConstantPool {
public int constant_pool_count;
public ConstantInfo[] cpInfo;
public ConstantPool(int count) {
constant_pool_count = count;
cpInfo = new ConstantInfo[constant_pool_count];
}
public void read(InputStream inputStream) {
for (int i = 1; i < constant_pool_count; i++) {
short tag = U1.read(inputStream);
ConstantInfo constantInfo = ConstantInfo.getConstantInfo(tag);
constantInfo.read(inputStream);
cpInfo[i] = constantInfo;
if (tag == ConstantInfo.CONSTANT_Double || tag == ConstantInfo.CONSTANT_Long) {
i++;
}
}
}
}我们先来看看CONSTANT_Utf8格式,这一项里面存放的是MUTF-8编码的字符串:
CONSTANT_Utf8_info {
u1 tag;
u2 length;
u1 bytes[length];
}那么如何读取这一项呢?
public class ConstantUtf8 extends ConstantInfo {
public String value;
@Override
public void read(InputStream inputStream) {
int length = U2.read(inputStream);
byte[] bytes = new byte[length];
try {
inputStream.read(bytes);
} catch (IOException e) {
e.printStackTrace();
}
try {
value = readUtf8(bytes);
} catch (UTFDataFormatException e) {
e.printStackTrace();
}
}
private String readUtf8(byte[] bytearr) throws UTFDataFormatException {
//copy from java.io.DataInputStream.readUTF()
}
}很简单,首先读取这一项的字节数组长度,接着调用readUtf8(),将字节数组转化为String字符串。
再来看看CONSTANT_Class这一项,这一项存储的是类或者接口的符号引用:
CONSTANT_Class_info {
u1 tag;
u2 name_index;
}注意这里的name_index并不是直接的字符串,而是指向常量池中cpInfo数组的name_index项,且cpInfo[name_index]一定是CONSTANT_Utf8格式。
public class ConstantClass extends ConstantInfo {
public int nameIndex;
@Override
public void read(InputStream inputStream) {
nameIndex = U2.read(inputStream);
}
}常量池解析完毕后,就可以供后面的数据使用了,比方说ClassFile中的this_class指向的就是常量池中格式为CONSTANT_Class的某一项,那么我们就可以读取出类名:
int classIndex = U2.read(inputStream);
ConstantClass clazz = (ConstantClass) constantPool.cpInfo[classIndex];
ConstantUtf8 className = (ConstantUtf8) constantPool.cpInfo[clazz.nameIndex];
classFile.className = className.value;
System.out.print("classname:" + classFile.className + "\n");字节码指令
解析常量池之后还需要接着解析一些类信息,如父类、接口类、字段等,但是相信大家最好奇的还是java指令的存储,大家都知道,我们平时写的java代码会被编译成java字节码,那么这些字节码到底存储在哪呢?别急,讲解指令之前,我们先来了解下ClassFile中的method_info,其格式如下:
method_info {
u2 access_flags;
u2 name_index;
u2 descriptor_index;
u2 attributes_count;
attribute_info attributes[attributes_count];
}method_info里主要是一些方法信息:如访问标志、方法名索引、方法描述符索引及属性数组。这里要强调的是属性数组,因为字节码指令就存储在这个属性数组里。属性有很多种,比如说异常表就是一个属性,而存储字节码指令的属性为CODE属性,看这名字也知道是用来存储代码的了。属性的通用格式为:
attribute_info {
u2 attribute_name_index;
u4 attribute_length;
u1 info[attribute_length];
}根据attribute_name_index可以从常量池中拿到属性名,再根据属性名就可以判断属性种类了。
Code属性的具体格式为:
Code_attribute {
u2 attribute_name_index; u4 attribute_length;
u2 max_stack;
u2 max_locals;
u4 code_length;
u1 code[code_length];
u2 exception_table_length;
{
u2 start_pc;
u2 end_pc;
u2 handler_pc;
u2 catch_type;
} exception_table[exception_table_length];
u2 attributes_count;
attribute_info attributes[attributes_count];
}其中code数组里存储就是字节码指令,那么如何解析呢?每条指令在code[]中都是一个字节,我们平时javap命令反编译看到的指令其实是助记符,只是方便阅读字节码使用的,jvm有一张字节码与助记符的对照表,根据对照表,就可以将指令翻译为可读的助记符了。这里我也是在网上随便找了一个对照表,保存到本地txt文件中,并在使用时解析成HashMap。代码很简单,就不贴了,可以参考我代码中InstructionTable.java。
接下来我们就可以解析字节码了:
for (int j = 0; j < methodInfo.attributesCount; j++) {
if (methodInfo.attributes[j] instanceof CodeAttribute) {
CodeAttribute codeAttribute = (CodeAttribute) methodInfo.attributes[j];
for (int m = 0; m < codeAttribute.codeLength; m++) {
short code = codeAttribute.code[m];
System.out.print(InstructionTable.getInstruction(code) + "\n");
}
}
}运行
整个项目终于写完了,接下来就来看看效果如何,随便找一个class文件解析运行:
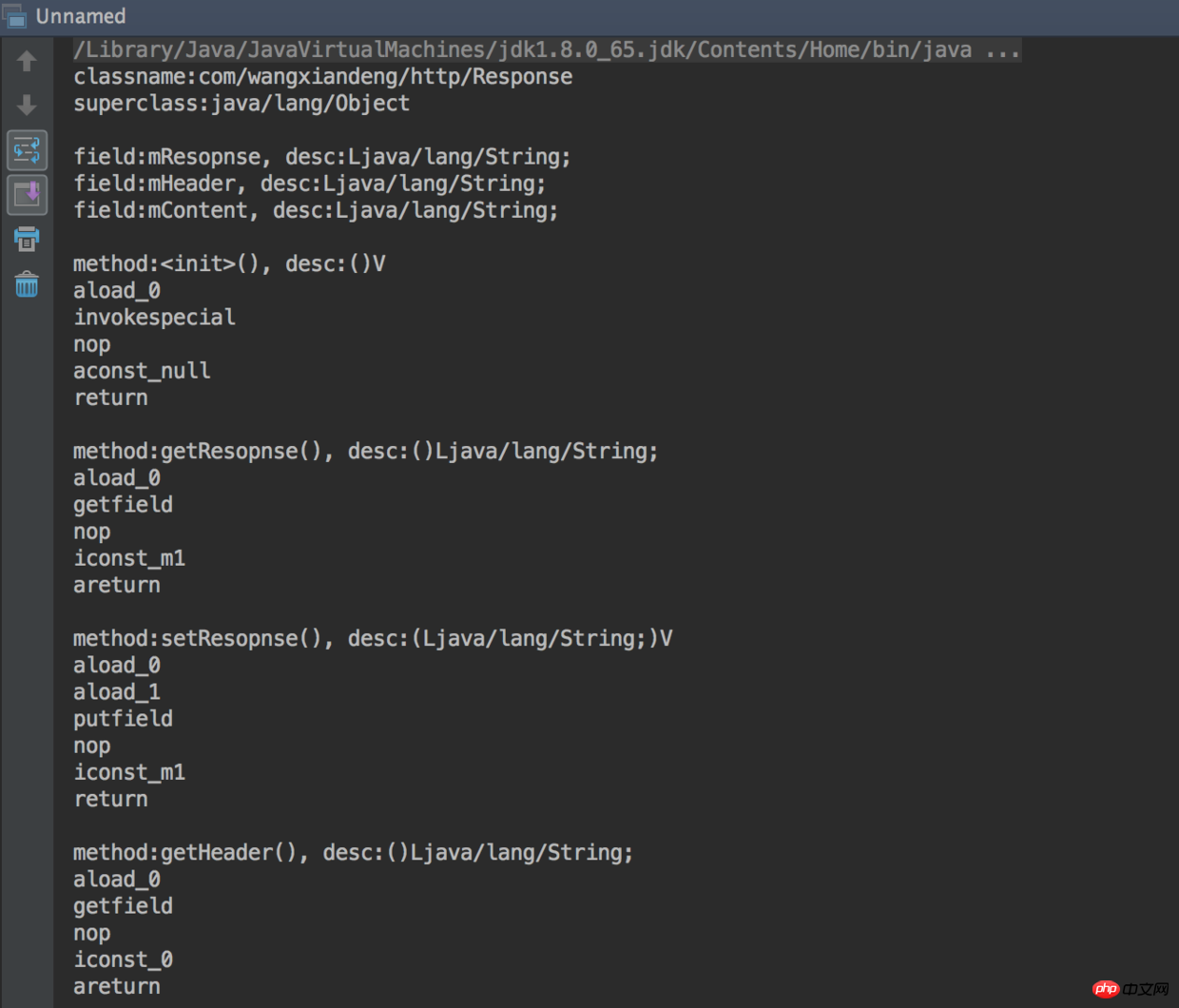
哈哈,是不是很赞!
以上是JVM深入学习-Java解析Class文件过程的示例代码的详细内容。更多信息请关注PHP中文网其他相关文章!

 如何将Maven或Gradle用于高级Java项目管理,构建自动化和依赖性解决方案?Mar 17, 2025 pm 05:46 PM
如何将Maven或Gradle用于高级Java项目管理,构建自动化和依赖性解决方案?Mar 17, 2025 pm 05:46 PM本文讨论了使用Maven和Gradle进行Java项目管理,构建自动化和依赖性解决方案,以比较其方法和优化策略。
 如何使用适当的版本控制和依赖项管理创建和使用自定义Java库(JAR文件)?Mar 17, 2025 pm 05:45 PM
如何使用适当的版本控制和依赖项管理创建和使用自定义Java库(JAR文件)?Mar 17, 2025 pm 05:45 PM本文使用Maven和Gradle之类的工具讨论了具有适当的版本控制和依赖关系管理的自定义Java库(JAR文件)的创建和使用。
 如何使用咖啡因或Guava Cache等库在Java应用程序中实现多层缓存?Mar 17, 2025 pm 05:44 PM
如何使用咖啡因或Guava Cache等库在Java应用程序中实现多层缓存?Mar 17, 2025 pm 05:44 PM本文讨论了使用咖啡因和Guava缓存在Java中实施多层缓存以提高应用程序性能。它涵盖设置,集成和绩效优势,以及配置和驱逐政策管理最佳PRA
 如何将JPA(Java持久性API)用于具有高级功能(例如缓存和懒惰加载)的对象相关映射?Mar 17, 2025 pm 05:43 PM
如何将JPA(Java持久性API)用于具有高级功能(例如缓存和懒惰加载)的对象相关映射?Mar 17, 2025 pm 05:43 PM本文讨论了使用JPA进行对象相关映射,并具有高级功能,例如缓存和懒惰加载。它涵盖了设置,实体映射和优化性能的最佳实践,同时突出潜在的陷阱。[159个字符]
 Java的类负载机制如何起作用,包括不同的类载荷及其委托模型?Mar 17, 2025 pm 05:35 PM
Java的类负载机制如何起作用,包括不同的类载荷及其委托模型?Mar 17, 2025 pm 05:35 PMJava的类上载涉及使用带有引导,扩展程序和应用程序类负载器的分层系统加载,链接和初始化类。父代授权模型确保首先加载核心类别,从而影响自定义类LOA


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

WebStorm Mac版
好用的JavaScript开发工具

SublimeText3汉化版
中文版,非常好用

Dreamweaver Mac版
视觉化网页开发工具

mPDF
mPDF是一个PHP库,可以从UTF-8编码的HTML生成PDF文件。原作者Ian Back编写mPDF以从他的网站上“即时”输出PDF文件,并处理不同的语言。与原始脚本如HTML2FPDF相比,它的速度较慢,并且在使用Unicode字体时生成的文件较大,但支持CSS样式等,并进行了大量增强。支持几乎所有语言,包括RTL(阿拉伯语和希伯来语)和CJK(中日韩)。支持嵌套的块级元素(如P、DIV),

Atom编辑器mac版下载
最流行的的开源编辑器

