



如果说这是一篇关于正则表达式的小结,我更愿意把它当做一个手册。
RegExp 三大方法
本文的RegExp采用直接量语法表示:/pattern/attributes。attributes有三个选择,i、m和g,m(多行匹配)不常用直接省略,所以一个pattern(匹配模式)可以表示如下:
var pattern = /hello/ig;
i(ignore)表示不区分大小写(地搜索匹配),比较简单,以下例子中不加述说;g(global)表示全局(搜索匹配),即找到一个后继续找下去,相对复杂,以下各种方法中会特别介绍。
既然是RegExp的三大方法,所以都是pattern.test/exec/complie的格式。
test
主要功能:检测指定字符串是否含有某个子串(或者匹配模式),返回true或者false。
示例如下:
var s = 'you love me and I love you'; var pattern = /you/; var ans = pattern.test(s); console.log(ans); // true
如果attributes用了g,则可以继续找下去,其中还会涉及lastIndex属性(参照exec中搭配g的介绍)。
exec
主要功能:提取指定字符串中的符合要求的子串(或者匹配模式),返回一个数组存放匹配结果;如果没有,则返回null。(也可自己写方法循环提取所有或者指定index的数据)
exec可以说是test的升级版本,因为它不仅可以检测,而且检测到了可以直接提取结果。
示例如下:
var s = 'you love me and I love you'; var pattern = /you/; var ans = pattern.exec(s); console.log(ans); // ["you", index: 0, input: "you love me and I love you"] console.log(ans.index); // 0 console.log(ans.input); // you love me and I love you
输出的东西很有意思。此数组的第 0 个元素是与正则表达式相匹配的文本,第 1 个元素是与 RegExpObject 的第 1 个子表达式相匹配的文本(如果有的话),第 2 个元素是与 RegExpObject 的第 2 个子表达式相匹配的文本(如果有的话),以此类推。
啥叫“与子表达式相匹配的文本”?看下面的例子:
var s = 'you love me and I love you'; var pattern = /y(o?)u/; var ans = pattern.exec(s); console.log(ans); // ["you", "o", index: 0, input: "you love me and I love you"] console.log(ans.length) // 2
所谓的子表达式就是pattern里()内的东西(具体可以参考下文对子表达式的介绍)。再看上面例子的数组长度,是2!!index和input只是数组属性(chrome中以上的输出可能会让人误会)。
除了数组元素和 length 属性之外,exec() 方法还返回两个属性。index 属性声明的是匹配文本的第一个字符的位置。input 属性则存放的是被检索的字符串 string。我们可以看得出,在调用非全局的 RegExp 对象的 exec() 方法时,返回的数组与调用方法 String.match() 返回的数组是相同的。
如果使用 “g” 参数,exec() 的工作原理如下(还是以上的例子 ps:如果test使用g参数类似):
找到第一个 “you”,并存储其位置
如果再次运行 exec(),则从存储的位置(lastIndex)开始检索,并找到下一个 “you”,并存储其位置
当 RegExpObject 是一个全局正则表达式时,exec() 的行为就稍微复杂一些。它会在 RegExpObject 的 lastIndex 属性指定的字符处开始检索字符串 string。当 exec() 找到了与表达式相匹配的文本时,在匹配后,它将把 RegExpObject 的 lastIndex 属性设置为匹配文本的最后一个字符的下一个位置。这就是说,我们可以通过反复调用 exec() 方法来遍历字符串中的所有匹配文本。当 exec() 再也找不到匹配的文本时,它将返回 null,并把 lastIndex 属性重置为 0。这里引入lastIndex属性,这货只有跟g和test(或者g和exec)三者搭配时才有作用。它是pattern的一个属性,一个整数,标示开始下一次匹配的字符位置。
实例如下:
var s = 'you love me and I love you';
var pattern = /you/g;
var ans;
do {
ans = pattern.exec(s);
console.log(ans);
console.log(pattern.lastIndex);
}
while (ans !== null)结果如下:

应该还容易理解,当第三次循环时,找不到“you”了,于是返回null,lastIndex值也变成0了。
如果在一个字符串中完成了一次模式匹配之后要开始检索新的字符串(仍然使用旧的pattern),就必须手动地把 lastIndex 属性重置为 0。
compile
主要功能:改变当前匹配模式(pattern)
这货是改变匹配模式时用的,用处不大,略过。详见JavaScript compile() 方法
String 四大护法
和RegExp三大方法分庭抗礼的是String的四大护法,四大护法有些和RegExp三大方法类似,有的更胜一筹。
既然是String家族下的四大护法,所以肯定是string在前,即str.search/match/replace/split形式。
既然是String的方法,当然参数可以只用字符串而不用pattern。
search
主要功能:搜索指定字符串中是否含有某子串(或者匹配模式),如有,返回子串在原串中的初始位置,如没有,返回-1。
是不是和test类似呢?test只能判断有木有,search还能返回位置!当然test()如果有需要能继续找下去,而search则会自动忽略g(如果有的话)。实例如下:
var s = 'you love me and I love you'; var pattern = /you/; var ans = s.search(pattern); console.log(ans); // 0
话说和String的indexOf方法有点相似,不同的是indexOf方法可以从指定位置开始查找,但是不支持正则。
match
主要功能:和exec类似,从指定字符串中查找子串或者匹配模式,找到返回数组,没找到返回null
match是exec的轻量版,当不使用全局模式匹配时,match和exec返回结果一致;当使用全局模式匹配时,match直接返回一个字符串数组,获得的信息远没有exec多,但是使用方式简单。
实例如下:
var s = 'you love me and I love you'; console.log(s.match(/you/)); // ["you", index: 0, input: "you love me and I love you"] console.log(s.match(/you/g)); // ["you", "you"]
replace
主要功能:用另一个子串替换指定字符串中的某子串(或者匹配模式),返回替换后的新的字符串 str.replace(‘搜索模式’,'替换的内容’) 如果用的是pattern并且带g,则全部替换;否则替换第一处。
实例如下:
var s = 'you love me and I love you'; console.log(s.replace('you', 'zichi')); // zichi love me and I love you console.log(s.replace(/you/, 'zichi')); // zichi love me and I love you console.log(s.replace(/you/g, 'zichi')); // zichi love me and I love zichi
如果需要替代的内容不是指定的字符串,而是跟匹配模式或者原字符串有关,那么就要用到$了(记住这些和$符号有关的东东只和replace有关哦)。

怎么用?看个例子就明白了。
var s = 'I love you'; var pattern = /love/; var ans = s.replace(pattern, '$`' + '$&' + "$'"); console.log(ans); // I I love you you
没错,’$`’ + ‘$&’ + “$’”其实就相当于原串了!
replace的第二个参数还能是函数,看具体例子前先看一段介绍:
注意:第一个参数是匹配到的子串,接下去是子表达式匹配的值,如果要用子表达式参数,则必须要有第一个参数(表示匹配到的串),也就是说,如果要用第n个参数代表的值,则左边参数都必须写出来。最后两个参数跟exec后返回的数组的两个属性差不多。
var s = 'I love you';
var pattern = /love/;
var ans = s.replace(pattern, function(a) { // 只有一个参数,默认为匹配到的串(如还有参数,则按序表示子表达式和其他两个参数)
return a.toUpperCase();
});
console.log(ans); // I LOVE yousplit
主要功能:分割字符串
字符串分割成字符串数组的方法(另有数组变成字符串的join方法)。直接看以下例子:
var s = 'you love me and I love you'; var pattern = 'and'; var ans = s.split(pattern); console.log(ans); // ["you love me ", " I love you"]
如果你嫌得到的数组会过于庞大,也可以自己定义数组大小,加个参数即可:
var s = 'you love me and I love you'; var pattern = /and/; var ans = s.split(pattern, 1); console.log(ans); // ["you love me "]
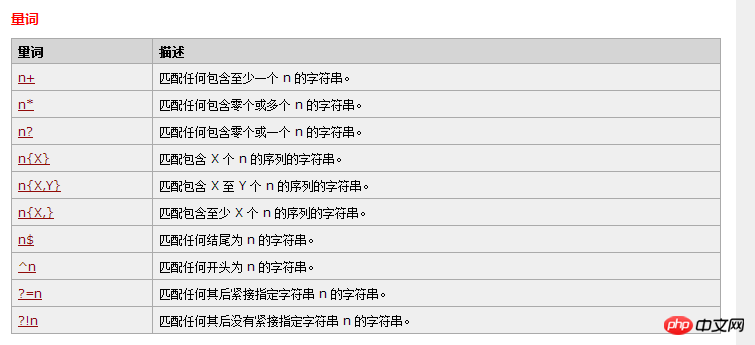
RegExp 字符
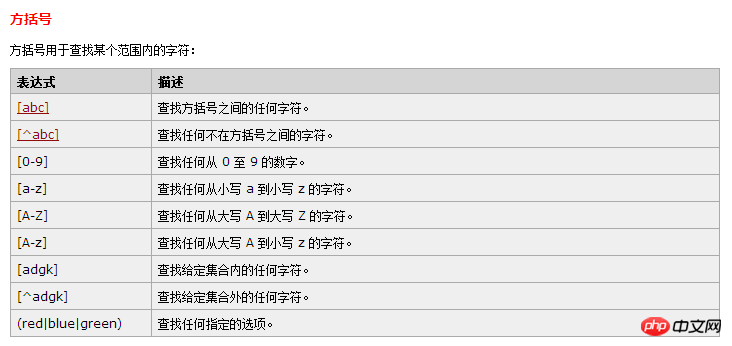
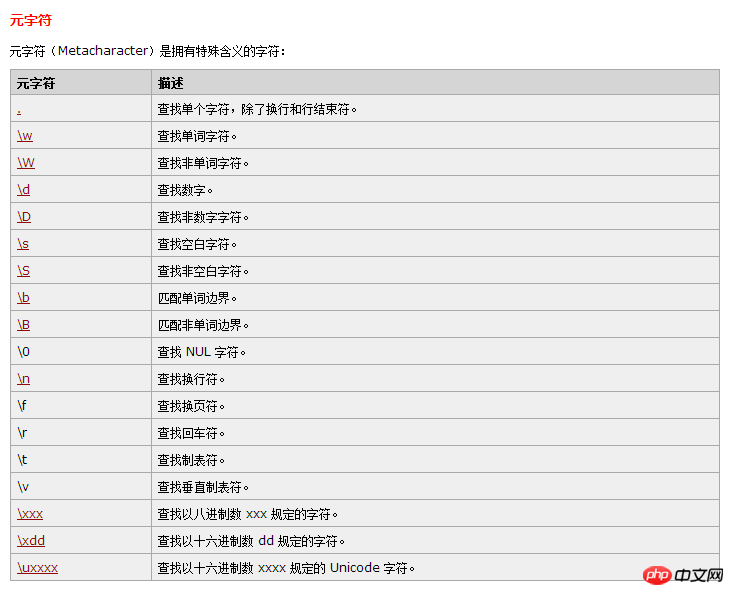
\s 任意空白字符 \S相反 空白字符可以是: 空格符 (space character) 制表符 (tab character) 回车符 (carriage return character) 换行符 (new line character) 垂直换行符 (vertical tab character) 换页符 (form feed character)
\b是正则表达式规定的一个特殊代码,代表着单词的开头或结尾,也就是单词的分界处。虽然通常英文的单词是由空格,标点符号或者换行来分隔的,但是\b并不匹配这些单词分隔字符中的任何一个,它只匹配一个位置。(和^ $ 以及零宽断言类似)
\w 匹配字母或数字或下划线 [a-z0-9A-Z_]完全等同于\w
贪婪匹配和懒惰匹配
什么是贪婪匹配?贪婪匹配就是在正则表达式的匹配过程中,默认会使得匹配长度越大越好。
var s = 'hello world welcome to my world'; var pattern = /hello.*world/; var ans = pattern.exec(s); console.log(ans) // ["hello world welcome to my world", index: 0, input: "hello world welcome to my world"]
以上例子不会匹配最前面的Hello World,而是一直贪心的往后匹配。
那么我需要最短的匹配怎么办?很简单,加个‘?’即可,这就是传说中的懒惰匹配,即匹配到了,就不往后找了。
var s = 'hello world welcome to my world'; var pattern = /hello.*?world/; var ans = pattern.exec(s); console.log(ans) // ["hello world", index: 0, input: "hello world welcome to my world"]
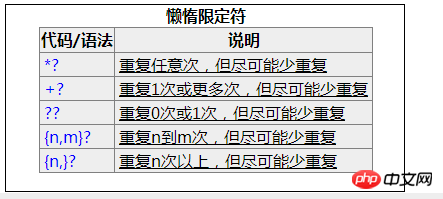
懒惰限定符(?)添加的场景如下:
子表达式
表示方式
用一个小括号指定:
var s = 'hello world'; var pattern = /(hello)/; var ans = pattern.exec(s); console.log(ans);
子表达式出现场景
在exec中数组输出子表达式所匹配的值:
var s = 'hello world'; var pattern = /(h(e)llo)/; var ans = pattern.exec(s); console.log(ans); // ["hello", "hello", "e", index: 0, input: "hello world"]
在replace中作为替换值引用:
var s = 'hello world'; var pattern = /(h\w*o)\s*(w\w*d)/; var ans = s.replace(pattern, '$2 $1') console.log(ans); // world hello
后向引用 & 零宽断言
子表达式的序号问题
简单地说:从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推。
复杂地说:分组0对应整个正则表达式实际上组号分配过程是要从左向右扫描两遍的:第一遍只给未命名组分配,第二遍只给命名组分配--因此所有命名组的组号都大于未命名的组号。可以使用(?:exp)这样的语法来剥夺一个分组对组号分配的参与权.
后向引用
如果我们要找连续两个一样的字符,比如要找两个连续的c,可以这样/c{2}/,如果要找两个连续的单词hello,可以这样/(hello){2}/,但是要在一个字符串中找连续两个相同的任意单词呢,比如一个字符串hellohellochinaworldworld,我要找的是hello和world,怎么找?
这时候就要用后向引用。看具体例子:
var s = 'hellohellochinaworldworld'; var pattern = /(\w+)\1/g; var a = s.match(pattern); console.log(a); // ["hellohello", "worldworld"]
这里的\1就表示和匹配模式中的第一个子表达式(分组)一样的内容,\2表示和第二个子表达式(如果有的话)一样的内容,\3 \4 以此类推。(也可以自己命名,详见参考文献)
或许你觉得数组里两个hello两个world太多了,我只要一个就够了,就又要用到子表达式了。因为match方法里是不能引用子表达式的值的,我们回顾下哪些方法是可以的?没错,exec和replace是可以的!
exec方式:
var s = 'hellohellochinaworldworld';
var pattern = /(\w+)\1/g;
var ans;
do {
ans = pattern.exec(s);
console.log(ans);
} while(ans !== null);
// result
// ["hellohello", "hello", index: 0, input: "hellohellochinaworldworld"] index.html:69
// ["worldworld", "world", index: 15, input: "hellohellochinaworldworld"] index.html:69
// null如果输出只要hello和world,console.log(ans[1])即可。
replace方式:
var s = 'hellohellochinaworldworld';
var pattern = /(\w+)\1/g;
var ans = [];
s.replace(pattern, function(a, b) {
ans.push(b);
});
console.log(ans); // ["hello", "world"]如果要找连续n个相同的串,比如说要找出一个字符串中出现最多的字符:
String.prototype.getMost = function() {
var a = this.split('');
a.sort();
var s = a.join('');
var pattern = /(\w)\1*/g;
var a = s.match(pattern);
a.sort(function(a, b) {
return a.length < b.length;
});
var letter = a[0][0];
var num = a[0].length;
return letter + ': ' + num;
}
var s = 'aaabbbcccaaabbbcccccc';
console.log(s.getMost()); // c: 9如果需要引用某个子表达式(分组),请认准后向引用!
零宽断言
别被名词吓坏了,其实解释很简单。
它们用于查找在某些内容(但并不包括这些内容)之后的东西,也就是说它们像\b,^,$那样用于指定一个位置,这个位置应该满足一定的条件(即断言)
(?=exp)
零宽度正预测先行断言,它断言自身出现的位置的后面能匹配表达式exp。
// 获取字符串中以ing结尾的单词的前半部分 var s = 'I love dancing but he likes singing'; var pattern = /\b\w+(?=ing\b)/g; var ans = s.match(pattern); console.log(ans); // ["danc", "sing"]
(?!exp)
零宽度负预测先行断言,断言此位置的后面不能匹配表达式exp
// 获取第五位不是i的单词的前四位
var s = 'I love dancing but he likes singing';
var pattern = /\b\w{4}(?!i)/g;
var ans = s.match(pattern);
console.log(ans); // ["love", "like"]javascript正则只支持前瞻,不支持后瞻((?<=exp)和(?
关于零宽断言的具体应用可以参考综合应用一节给字符串加千分符。
其他
字符转义
因为某些字符已经被正则表达式用掉了,比如. * ( ) / \ [],所以需要使用它们(作为字符)时,需要用\转义
var s = 'http://www.cnblogs.com/zichi/'; var pattern = /http:\/\/www\.cnblogs\.com\/zichi\//; var ans = pattern.exec(s); console.log(ans); // ["http://www.cnblogs.com/zichi/", index: 0, input: "http://www.cnblogs.com/zichi/"]
分支条件
如果需要匹配abc里的任意字母,可以用[abc],但是如果不是单个字母那么简单,就要用到分支条件。
分支条件很简单,就是用|表示符合其中任意一种规则。
var s = "I don't like you but I love you"; var pattern = /I.*(like|love).*you/g; var ans = s.match(pattern); console.log(ans); // ["I don't like you but I love you"]
答案执行了贪婪匹配,如果需要懒惰匹配,则:
var s = "I don't like you but I love you"; var pattern = /I.*?(like|love).*?you/g; var ans = s.match(pattern); console.log(ans); // ["I don't like you", "I love you"]
综合应用
去除字符串首尾空格(replace)
String.prototype.trim = function() {
return this.replace(/(^\s*)|(\s*$)/g, "");
};
var s = ' hello world ';
var ans = s.trim();
console.log(ans.length); // 12给字符串加千分符(零宽断言)
String.prototype.getAns = function() {
var pattern = /(?=((?!\b)\d{3})+$)/g;
return this.replace(pattern, ',');
}
var s = '123456789';
console.log(s.getAns()); // 123,456,789找出字符串中出现最多的字符(后向引用)
String.prototype.getMost = function() {
var a = this.split('');
a.sort();
var s = a.join('');
var pattern = /(\w)\1*/g;
var a = s.match(pattern);
a.sort(function(a, b) {
return a.length < b.length;
});
var letter = a[0][0];
var num = a[0].length;
return letter + ': ' + num;
}
var s = 'aaabbbcccaaabbbcccccc';
console.log(s.getMost()); // c: 9常用匹配模式(持续更新)
只能输入汉字:/^[\u4e00-\u9fa5]{0,}$/
总结
test:检查指定字符串中有没有某子串(或某匹配模式),返回true或者false;如有必要可以进行全局模式搜索。
exec:检查指定字符串中有没有某子串(或者匹配模式),如有返回数组(数组信息丰富,可参考上文介绍),如没有返回null;如有必要可以进行全局搜索找出所有子串(或者匹配模式)的信息,信息中含有匹配模式中子表达式所对应的字符串。
compile:修改正则表达式中的pattern
search:检查指定字符串中有没有某子串(或者匹配模式),如有返回子串(或者匹配模式)在原串中的开始位置,如没有返回-1。不能进行全局搜索。
match:检查指定字符串中有没有某子串(或者匹配模式),非全局模式下返回信息和exec一致;如进行全局搜索,直接返回字符串数组。(如不需要关于每个匹配的更多信息,推荐用match而不是exec)
replace:检查指定字符串中有没有某子串(或者匹配模式),并用另一个子串代替(该子串可以跟原字符串或者搜索到的子串有关);如启动g,则全局替换,否则只替换第一个。replace方法可以引用子表达式所对应的值。
split:用特定模式分割字符串,返回一个字符串数组;与Array的join方法正好相反。
子表达式:用括号括起来的正则匹配表达式,用后向引用可以对其进行引用;也可以和exec或者replace搭配获取其真实匹配值。
后向引用 :对子表达式所在分组进行引用。
零宽断言:和\b ^ 以及$类似的某个位置概念。
以上是大家都认识的JavaScript正则表达式详解的详细内容。更多信息请关注PHP中文网其他相关文章!

 Python vs. JavaScript:社区,图书馆和资源Apr 15, 2025 am 12:16 AM
Python vs. JavaScript:社区,图书馆和资源Apr 15, 2025 am 12:16 AMPython和JavaScript在社区、库和资源方面的对比各有优劣。1)Python社区友好,适合初学者,但前端开发资源不如JavaScript丰富。2)Python在数据科学和机器学习库方面强大,JavaScript则在前端开发库和框架上更胜一筹。3)两者的学习资源都丰富,但Python适合从官方文档开始,JavaScript则以MDNWebDocs为佳。选择应基于项目需求和个人兴趣。
 从C/C到JavaScript:所有工作方式Apr 14, 2025 am 12:05 AM
从C/C到JavaScript:所有工作方式Apr 14, 2025 am 12:05 AM从C/C 转向JavaScript需要适应动态类型、垃圾回收和异步编程等特点。1)C/C 是静态类型语言,需手动管理内存,而JavaScript是动态类型,垃圾回收自动处理。2)C/C 需编译成机器码,JavaScript则为解释型语言。3)JavaScript引入闭包、原型链和Promise等概念,增强了灵活性和异步编程能力。
 JavaScript引擎:比较实施Apr 13, 2025 am 12:05 AM
JavaScript引擎:比较实施Apr 13, 2025 am 12:05 AM不同JavaScript引擎在解析和执行JavaScript代码时,效果会有所不同,因为每个引擎的实现原理和优化策略各有差异。1.词法分析:将源码转换为词法单元。2.语法分析:生成抽象语法树。3.优化和编译:通过JIT编译器生成机器码。4.执行:运行机器码。V8引擎通过即时编译和隐藏类优化,SpiderMonkey使用类型推断系统,导致在相同代码上的性能表现不同。
 超越浏览器:现实世界中的JavaScriptApr 12, 2025 am 12:06 AM
超越浏览器:现实世界中的JavaScriptApr 12, 2025 am 12:06 AMJavaScript在现实世界中的应用包括服务器端编程、移动应用开发和物联网控制:1.通过Node.js实现服务器端编程,适用于高并发请求处理。2.通过ReactNative进行移动应用开发,支持跨平台部署。3.通过Johnny-Five库用于物联网设备控制,适用于硬件交互。
 使用Next.js(后端集成)构建多租户SaaS应用程序Apr 11, 2025 am 08:23 AM
使用Next.js(后端集成)构建多租户SaaS应用程序Apr 11, 2025 am 08:23 AM我使用您的日常技术工具构建了功能性的多租户SaaS应用程序(一个Edtech应用程序),您可以做同样的事情。 首先,什么是多租户SaaS应用程序? 多租户SaaS应用程序可让您从唱歌中为多个客户提供服务
 如何使用Next.js(前端集成)构建多租户SaaS应用程序Apr 11, 2025 am 08:22 AM
如何使用Next.js(前端集成)构建多租户SaaS应用程序Apr 11, 2025 am 08:22 AM本文展示了与许可证确保的后端的前端集成,并使用Next.js构建功能性Edtech SaaS应用程序。 前端获取用户权限以控制UI的可见性并确保API要求遵守角色库
 JavaScript:探索网络语言的多功能性Apr 11, 2025 am 12:01 AM
JavaScript:探索网络语言的多功能性Apr 11, 2025 am 12:01 AMJavaScript是现代Web开发的核心语言,因其多样性和灵活性而广泛应用。1)前端开发:通过DOM操作和现代框架(如React、Vue.js、Angular)构建动态网页和单页面应用。2)服务器端开发:Node.js利用非阻塞I/O模型处理高并发和实时应用。3)移动和桌面应用开发:通过ReactNative和Electron实现跨平台开发,提高开发效率。
 JavaScript的演变:当前的趋势和未来前景Apr 10, 2025 am 09:33 AM
JavaScript的演变:当前的趋势和未来前景Apr 10, 2025 am 09:33 AMJavaScript的最新趋势包括TypeScript的崛起、现代框架和库的流行以及WebAssembly的应用。未来前景涵盖更强大的类型系统、服务器端JavaScript的发展、人工智能和机器学习的扩展以及物联网和边缘计算的潜力。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

SublimeText3 英文版
推荐:为Win版本,支持代码提示!

安全考试浏览器
Safe Exam Browser是一个安全的浏览器环境,用于安全地进行在线考试。该软件将任何计算机变成一个安全的工作站。它控制对任何实用工具的访问,并防止学生使用未经授权的资源。

ZendStudio 13.5.1 Mac
功能强大的PHP集成开发环境

Dreamweaver Mac版
视觉化网页开发工具

Dreamweaver CS6
视觉化网页开发工具

