


在第一部分,有简单的介绍MyCAT的搭建和配置文件的基本情况,这一篇详细介绍schema的一些具体参数,以及实际作用
首先贴上自己测试用的schema文件,双引号之前的反斜杠不会消除,姑且当成不存在吧...
<?xml version=\"1.0\"?>
<!DOCTYPE mycat:schema SYSTEM \"schema.dtd\">
<mycat:schema xmlns:mycat=\"http://org.opencloudb/\">
<schema name=\"mycat\" checkSQLschema=\"false\" sqlMaxLimit=\"100\">
<!-- auto sharding by id (long) -->
<table name=\"students\" dataNode=\"dn1,dn2,dn3,dn4\" rule=\"rule1\" />
<table name=\"log_test\" dataNode=\"dn1,dn2,dn3,dn4\" rule=\"rule2\" />
<!-- global table is auto cloned to all defined data nodes ,so can join
with any table whose sharding node is in the same data node -->
<!--<table name=\"company\" primaryKey=\"ID\" type=\"global\" dataNode=\"dn1,dn2,dn3\" />
<table name=\"goods\" primaryKey=\"ID\" type=\"global\" dataNode=\"dn1,dn2\" />
-->
<table name=\"item_test\" primaryKey=\"ID\" type=\"global\" dataNode=\"dn1,dn2,dn3,dn4\" />
<!-- random sharding using mod sharind rule -->
<!-- <table name=\"hotnews\" primaryKey=\"ID\" dataNode=\"dn1,dn2,dn3\"
rule=\"mod-long\" /> -->
<!--
<table name=\"worker\" primaryKey=\"ID\" dataNode=\"jdbc_dn1,jdbc_dn2,jdbc_dn3\" rule=\"mod-long\" />
-->
<!-- <table name=\"employee\" primaryKey=\"ID\" dataNode=\"dn1,dn2\"
rule=\"sharding-by-intfile\" />
<table name=\"customer\" primaryKey=\"ID\" dataNode=\"dn1,dn2\"
rule=\"sharding-by-intfile\">
<childTable name=\"orders\" primaryKey=\"ID\" joinKey=\"customer_id\"
parentKey=\"id\">
<childTable name=\"order_items\" joinKey=\"order_id\"
parentKey=\"id\" />
<ildTable>
<childTable name=\"customer_addr\" primaryKey=\"ID\" joinKey=\"customer_id\"
parentKey=\"id\" /> -->
</schema>
<!-- <dataNode name=\"dn\" dataHost=\"localhost\" database=\"test\" /> -->
<dataNode name=\"dn1\" dataHost=\"localhost\" database=\"test1\" />
<dataNode name=\"dn2\" dataHost=\"localhost\" database=\"test2\" />
<dataNode name=\"dn3\" dataHost=\"localhost\" database=\"test3\" />
<dataNode name=\"dn4\" dataHost=\"localhost\" database=\"test4\" />
<!--
<dataNode name=\"jdbc_dn1\" dataHost=\"jdbchost\" database=\"db1\" />
<dataNode name=\"jdbc_dn2\" dataHost=\"jdbchost\" database=\"db2\" />
<dataNode name=\"jdbc_dn3\" dataHost=\"jdbchost\" database=\"db3\" />
-->
<dataHost name=\"localhost\" maxCon=\"100\" minCon=\"10\" balance=\"1\"
writeType=\"1\" dbType=\"mysql\" dbDriver=\"native\">
<heartbeat>select user()<beat>
<!-- can have multi write hosts -->
<writeHost host=\"localhost\" url=\"localhost:3306\" user=\"root\" password=\"wangwenan\">
<!-- can have multi read hosts -->
<readHost host=\"hostS1\" url=\"localhost:3307\" user=\"root\" password=\"wangwenan\"/>
</writeHost>
<writeHost host=\"localhost1\" url=\"localhost:3308\" user=\"root\" password=\"wangwenan\">
<!-- can have multi read hosts -->
<readHost host=\"hostS11\" url=\"localhost:3309\" user=\"root\" password=\"wangwenan\"/>
</writeHost>
</dataHost>
<!-- <writeHost host=\"hostM2\" url=\"localhost:3316\" user=\"root\" password=\"123456\"/> -->
<!--
<dataHost name=\"jdbchost\" maxCon=\"1000\" minCon=\"1\" balance=\"0\" writeType=\"0\" dbType=\"mongodb\" dbDriver=\"jdbc\">
<heartbeat>select user()<beat>
<writeHost host=\"hostM\" url=\"mongodb://192.168.0.99/test\" user=\"admin\" password=\"123456\" ></writeHost>
</dataHost>
-->
<!--
<dataHost name=\"jdbchost\" maxCon=\"1000\" minCon=\"10\" balance=\"0\"
dbType=\"mysql\" dbDriver=\"jdbc\">
<heartbeat>select user()<beat>
<writeHost host=\"hostM1\" url=\"jdbc:mysql://localhost:3306\"
user=\"root\" password=\"123456\">
</writeHost>
</dataHost>
-->
</mycat:schema>
第一行参数262e537606e2a5215fd1ebf0c92793dd
在这一行参数里面,schema name定义了可以在MyCAT前端显示的逻辑数据库的名字,
checkSQLschema这个参数为False的时候,表明MyCAT会自动忽略掉表名前的数据库名,比如说mydatabase1.test1,会被当做test1;
sqlMaxLimit指定了SQL语句返回的行数限制;

如截图,这个limit会让MyCAT在分发SQL语句的时候,自动加上一个limit,限制从分库获得的结果的行数,另外,截图右上角可以看到,MyCAT本身也是有缓存的;
那么,如果我们执行的语句要返回较多的数据行,在不修改这个limit的情况下,MyCAT会怎么做?
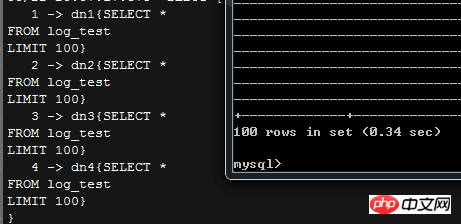
可以从截图看到,MyCAT完全就没搭理前端的实际需求,老老实实返回100条数据,所以如果实际应用里面需要返回大量数据,可能就得手动改逻辑了
MyCAT的1.4版本里面,用户的Limit参数会覆盖掉默认的MyCAT设置
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
77b1ae820cb2419fc4581f8fe17392c0
这一行代表在MyCAT前端会显示哪些表名,类似几行都代表一样的意思,这里强调的是表,而MyCAT并不会在配置文件里面定义表结构
如果在前端使用show create table ,MyCAT会显示正常的表结构信息,观察Debug日志,

可以看到,MyCAT把命令分发给了dn1代表的数据库,然后把dn1的查询结果返回给了前端
可以判断,类似的数据库级别的一些查询指令,有可能是单独分发给某个节点,然后再把某个节点的信息返回给前端;
dataNode的意义很简单,这个逻辑表的数据存储在后端的哪几个数据库里面
rule代表的是这个逻辑表students的具体切分策略,目前MyCAT只支持按照某一个特殊列,遵循一些特殊的规则来切分,如取模,枚举等,具体的留给之后细说
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
7d4277d2e49b845bfe131d19a8dcefd2
这一行代表的是全局表,这意味着,item_test这张表会在四个dataNode里面都保存有完整的数据副本,那么查询的时候还会分发到所有的数据库么?
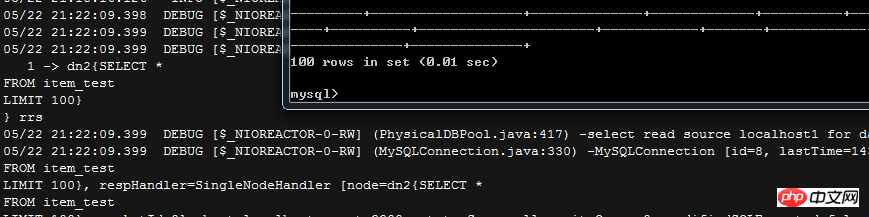
结果如截图,MyCAT依然是规规矩矩的返回了100条数据(╮(╯_╰)╭),而针对全局表的查询,只会分发到某一个节点上
配置的primaryKey没发现作用在哪里,姑且忽略吧,以后发现了再补上
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
childtable我在测试中并没有实际用起来不过在MyCAT的设计文档里面有提到,childtable是一种依赖于父表的结构,
这意味着,childtable的joinkey会按照父表的parentKey的策略一起切分,当父表与子表进行连接,且连接条件是childtable.joinKey=parenttable.parentKey时,不会进行跨库的连接.
PS:具体测试以后再补
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
dataNode的参数在之前的篇章介绍过,这里直接跳过~
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
dataHost配置的是实际的后端数据库集群,大部分参数简单易懂,这里就不一个个介绍了,只介绍比较重要的两个参数,writeType和balance.
writeType和balance是用来控制后端集群的读写分离的关键参数,这里我用了双主双从的集群配置
这里的测试过程比较麻烦,所以直接贴结论:
1.balance=0时,读操作都在localhost上(localhost失败时,后端直接失败)
2.balance=1时,读操作会随机分散在localhost1和两个readhost上面(localhost失败时,写操作会在localhost1,如果localhost1再失败,则无法进行写操作)
3.balance=2时,写操作会在localhost上,读操作会随机分散在localhost1,localhost1和两个readhost上面(同上)
4.writeType=0时,写操作会在localhost上,如果localhost失败,会自动切换到localhost1,localhost恢复以后并不会切换回localhost进行写操作
5.writeType=1时,写操作会随机分布在localhost和localhost1上,单点失败并不会影响集群的写操作,但是后端的从库会无法从挂掉的主库获取更新,会在读数据的时候出现数据不一致
举例:localhost失败了,写操作会在localhost1上面进行,localhost1的主从正常运行,但是localhost的从库无法从localhost获取更新,localhost的从库于其他库出现数据不一致
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
实际上,MyCAT本身的读写分离是基于后端集群的同步来实现的,而MyCAT本身则提供语句的分发功能,当然,那个sqlLimit的限制也使得MyCAT会对前端应用层的逻辑造成一些影响
由schema到table的配置,则显示出MyCAT本身的逻辑结构里面,就包含了分库分表的这种特性(可以指定不同的表存在于不同的数据库中,而不必分到全部数据库)
以上是MySQL分布式集群之MyCAT(二)schema代码详解的详细内容。更多信息请关注PHP中文网其他相关文章!

 图文详解mysql架构原理May 17, 2022 pm 05:54 PM
图文详解mysql架构原理May 17, 2022 pm 05:54 PM本篇文章给大家带来了关于mysql的相关知识,其中主要介绍了关于架构原理的相关内容,MySQL Server架构自顶向下大致可以分网络连接层、服务层、存储引擎层和系统文件层,下面一起来看一下,希望对大家有帮助。
 mysql的msi与zip版本有什么区别May 16, 2022 pm 04:33 PM
mysql的msi与zip版本有什么区别May 16, 2022 pm 04:33 PMmysql的msi与zip版本的区别:1、zip包含的安装程序是一种主动安装,而msi包含的是被installer所用的安装文件以提交请求的方式安装;2、zip是一种数据压缩和文档存储的文件格式,msi是微软格式的安装包。
 mysql怎么去掉第一个字符May 19, 2022 am 10:21 AM
mysql怎么去掉第一个字符May 19, 2022 am 10:21 AM方法:1、利用right函数,语法为“update 表名 set 指定字段 = right(指定字段, length(指定字段)-1)...”;2、利用substring函数,语法为“select substring(指定字段,2)..”。
 mysql怎么替换换行符Apr 18, 2022 pm 03:14 PM
mysql怎么替换换行符Apr 18, 2022 pm 03:14 PM在mysql中,可以利用char()和REPLACE()函数来替换换行符;REPLACE()函数可以用新字符串替换列中的换行符,而换行符可使用“char(13)”来表示,语法为“replace(字段名,char(13),'新字符串') ”。
 mysql怎么将varchar转换为int类型May 12, 2022 pm 04:51 PM
mysql怎么将varchar转换为int类型May 12, 2022 pm 04:51 PM转换方法:1、利用cast函数,语法“select * from 表名 order by cast(字段名 as SIGNED)”;2、利用“select * from 表名 order by CONVERT(字段名,SIGNED)”语句。
 MySQL复制技术之异步复制和半同步复制Apr 25, 2022 pm 07:21 PM
MySQL复制技术之异步复制和半同步复制Apr 25, 2022 pm 07:21 PM本篇文章给大家带来了关于mysql的相关知识,其中主要介绍了关于MySQL复制技术的相关问题,包括了异步复制、半同步复制等等内容,下面一起来看一下,希望对大家有帮助。
 mysql怎么判断是否是数字类型May 16, 2022 am 10:09 AM
mysql怎么判断是否是数字类型May 16, 2022 am 10:09 AM在mysql中,可以利用REGEXP运算符判断数据是否是数字类型,语法为“String REGEXP '[^0-9.]'”;该运算符是正则表达式的缩写,若数据字符中含有数字时,返回的结果是true,反之返回的结果是false。
 mysql怎么删除unique keyMay 12, 2022 pm 03:01 PM
mysql怎么删除unique keyMay 12, 2022 pm 03:01 PM在mysql中,可利用“ALTER TABLE 表名 DROP INDEX unique key名”语句来删除unique key;ALTER TABLE语句用于对数据进行添加、删除或修改操作,DROP INDEX语句用于表示删除约束操作。


热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

VSCode Windows 64位 下载
微软推出的免费、功能强大的一款IDE编辑器

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)

螳螂BT
Mantis是一个易于部署的基于Web的缺陷跟踪工具,用于帮助产品缺陷跟踪。它需要PHP、MySQL和一个Web服务器。请查看我们的演示和托管服务。

记事本++7.3.1
好用且免费的代码编辑器

适用于 Eclipse 的 SAP NetWeaver 服务器适配器
将Eclipse与SAP NetWeaver应用服务器集成。

